Machine Learning(study notes)
There is no studying without going crazy
Studying alwats drives us crazy
文章目录
- Define
-
- Machine Learning
- Supervised Learning(监督学习)
-
- Regression problem
- Classidication
- Unspervised Learning
-
- Clustering
- Study
-
- Model representation(模型概述)
-
- const function
- How to use and t
- solve problem
- gradient descent
Define
Machine Learning
A computer program is said to learn from experience E with respect to some task T and some performance measure P , if its performance on T, as measued
计算机程序从经验E中学习,解决某一任务T进行某一性能度量P,通过P测定在T上的表现因经验E而提高
realy rhyme
Supervised Learning(监督学习)
right answers given
Regression problem
tring to predict continuios valued ouput
需要预测连续的数值输出
in that problem , you should give its some right valued with different classic and machine learning will learn to predict it

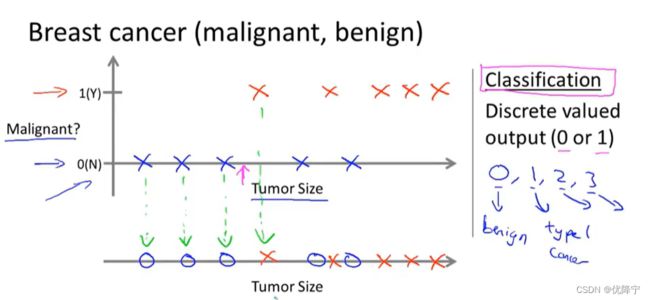
Classidication
discrete valued output (zero or one)
离散取值输出
in that problem, you should give some valued . Different with regression , maybe the type of data
Unspervised Learning
Clustering
maybe using clustring algorithm to break that data into two separate clusters
使用聚类算法将数据分为两簇
do not know what data mean and data features and so on(just about data information),and you know ,machine learning should classification those data into different clusters
the classic problem of that maybe Cocktail party problem algorithm
经典问题就是鸡尾酒派对算法,就是有背景音乐以及人声,能分理分离出两者的声音
Study
Model representation(模型概述)
using this example

And we will give some training set

As you can see , we put
m as number of training examples,
x’s as “input” variable / features ,
y’s as “output” variable / “target” variable ,
(x,y) as one training example ,
(x(i),y(i)) refer to the ith training example.(this superscript i over here , this is not exponentiation.The superscript i in parenthess that’s just an index into my training set)
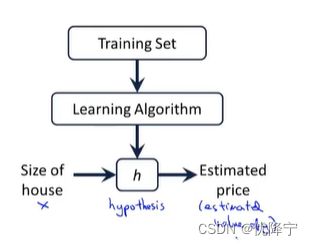
We saw that with the training set like our training set of housing prices and we feed that to our learning algorithm.Is the job of a learning algorithm to then output a function which by convention is usually denoted lowercase h
const function

In this chart , we want the difference between h(x) and y to be small .And one thing I’m gonna do is try to minimize the square difference between the output of the hypoth
How to use and t
solve problem
gradient descent
It turns out gradient descent is a more general algorithm, and is used not only in linear regression. It’s actually used all over the place in machine learning.

Here is the problem setup.
We are going to see that we have some function J of (θ0,θ1). Maybe it is a cost function from linear regression.And we want to come up with an algorithm for minimizing that as a function of J of (θ0,θ1).
For the sake of brevity , for the sake of your succinctness of notation , so we just goingn to pretend that have only two parameters through the rest of this video.
The idea for gradient descent :
What we’re going to do is we are going to strat off with some initial guesses for θ0 and θ1.
What we are going to do in gradient descent is we’ll keep changing θ0 and θ1 a little bit to try to reduce J of (θ0,θ1)