第P6周—好莱坞明星识别(1)
一、 前期工作
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms,datasets
import os ,PIL,pathlib,warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import os,PIL,random,pathlib
data_dir = 'D:/P6/48-data/'
data_dir = pathlib.Path(data_dir)
data_path = list(data_dir.glob('*'))
print (data_path)
classname = [str(path).split("\\")[3] for path in data_path]
print(classname)二、数据预处理
2.1 通过图片随机抽样计算 tansforms.Normalize()中红绿蓝通道均值和标准差(以下代码需在独立py文件中运行)
将"D:/P6/48-data/"路径下子文件夹中所有图片复制到D:/all文件夹中
import os
import shutil
# 主数据集根目录
dataset_root = "D:/P6/48-data/"
# 新文件夹的路径
output_dir = "D:/all/"
# 创建新文件夹(如果不存在)
os.makedirs(output_dir, exist_ok=True)
# 遍历主目录下的每个子文件夹
for root, dirs, files in os.walk(dataset_root):
for filename in files:
if filename.endswith(('.jpg', '.jpeg', '.png', '.bmp')): # 过滤出图片文件
image_path = os.path.join(root, filename)
output_path = os.path.join(output_dir, filename)
# 复制图片文件到新文件夹
shutil.copy2(image_path, output_path)
print("图片已复制到新文件夹 'all' 中:", output_dir)
![]()
对all文件夹中图片随机抽样并计算红绿蓝色道均值和标准差
import os
import random
import cv2
import numpy as np
# 数据集根目录
dataset_root = "D:/all/"
# 采样比例
sample_ratio = 0.1 # 10% 的采样率
# 随机选择一部分图片进行采样
all_image_paths = [os.path.join(dataset_root, filename) for filename in os.listdir(dataset_root)]
sample_size = int(len(all_image_paths) * sample_ratio)
sampled_image_paths = random.sample(all_image_paths, sample_size)
# 初始化通道像素值总和和像素数量
total_mean = np.zeros(3)
total_std = np.zeros(3)
total_pixels = 0
# 遍历采样图片并计算通道的均值和标准差
for image_path in sampled_image_paths:
image = cv2.imread(image_path)
image = image.astype(np.float32) / 255.0 # 归一化到 [0, 1]
total_mean += image.mean(axis=(0, 1))
total_std += image.std(axis=(0, 1))
total_pixels += image.size // 3 # 3 通道的像素数量
# 计算平均值和标准差
dataset_mean = total_mean / len(sampled_image_paths)
dataset_std = total_std / len(sampled_image_paths)
print("均值:", dataset_mean)
print("标准差:", dataset_std)

2.2 样本标准化归一化处理
train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.39354826, 0.41713402, 0.48036146],
std = [0.25076334, 0.25809455, 0.28359835]
)
])
total_data = datasets.ImageFolder("D:/P6/48-data/", transform = train_transforms)
print (total_data)在上述代码中,total_data = datasets.ImageFolder("D:/P6/48-data/", transform = train_transforms) 的作用是 对位于 "D:/P6/48-data/" 目录下的图像数据应用 train_transforms 中定义的数据进行转换。 目的是对训练数据进行预处理和数据增强,以提高深度学习模型的性能和泛化能力。

2.3 将数据集中的类别(或标签)映射到相应的整数索引
print(total_data.class_to_idx)![]()
三、划分数据集
3.1 划分数据集
train_size = int(0.8*len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data,[train_size, test_size])
print(train_dataset,test_dataset)3.2 设置数据加载器
batch_size = 32
train_dl =torch.utils.data.DataLoader(train_dataset,
batch_size = batch_size,
shuffle = True,
num_workers = 1)
test_dl =torch.utils.data.DataLoader(test_dataset,
batch_size = batch_size,
shuffle = True,
num_workers = 1)
#当 shuffle=True 时:数据加载器会在每个训练周期之前对数据进行随机洗牌。
# 这意味着每个周期都会以随机顺序提供数据样本,这有助于模型更好地学习数据的分布,
# 减少模型对特定顺序的依赖。这通常是在训练深度学习模型时推荐的做法,
# 特别是当数据集的样本顺序可能影响模型的训练效果时。四、调用VGG-16模型
from torchvision.models import vgg16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device\n".format(device))
''' 调用官方的VGG-16模型 '''
# 加载预训练模型,并且对模型进行微调
model = vgg16(pretrained = True).to(device) # 加载预训练的vgg16模型
for param in model.parameters():
param.requires_grad = False # 冻结模型的参数,这样子在训练的时候只训练最后一层的参数
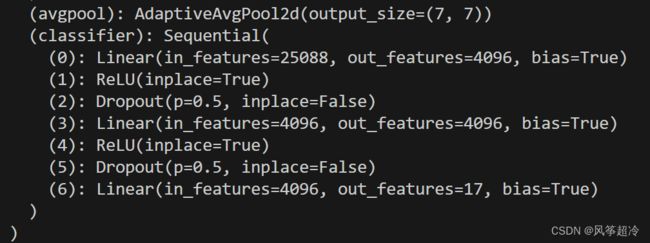
# 修改classifier模块的第6层(即:(6): Linear(in_features=4096, out_features=2, bias=True))
# 注意查看我们下方打印出来的模型
model.classifier._modules['6'] = nn.Linear(4096, 17) # 修改vgg16模型中最后一层全连接层,输出目标类别个数
model.to(device)
print(model)![]()