如何在Chatbot中应用深度学习?
编者按:本书节选自图书《深度学习算法实践》,本书以一位软件工程师在工作中遇到的问题为主线,阐述了如何从软件工程思维向算法思维转变、如何将任务分解成算法问题,并结合程序员在工作中经常面临的产品需求,详细阐述了应该怎样从算法的角度看待、分解需求,并结合经典的任务对深度学习算法做了清晰的分析。
公开课福利: CSDN学院邀请到本书作者吴岸城,他将分享的主题为「深度学习中基础模型性能的思考和优化」。报名链接:http://edu.csdn.net/huiyiCourse/detail/536
人类其实从很早以前就开始追求人类和机器之间的对话,早先科学家研发的机器在和人对话时都是采用规则性的回复,比如人提问后,计算机从数据库中找出相关的答案来回复。这种规则性的一对一匹配有很多限制。机器只知道问什么答什么,却不知道举一反三,比如你问它:“今天天气怎么样?”它会机械地把今天的天气告诉你。这不像人与人之间的对话,人是有各种反应的,这类反应的产生是基于人的知识结构和对话场景的。
那么,你觉得这类机器是否真的具有智能了?图灵测试是这样判断机器人是否具有智能的:测试中,一个正常人将尝试通过一连串的问答,把被试的机器与人类区分开来。一般来说,如果正常人无法分辨和自己聊天的是人还是机器人的时候,机器人就算通过测试了。
图灵测试的关键之处在于,没有定义“思维/意识”。只是将机器人作为黑盒,观察输入和输出是否达标。所以说它从一开始就绕开了“机器能思考吗?”这样的问题,而是把它替换成另外一个更具操作性的问题——“机器能做我们这些思考者所做的事吗?”。大家注意这两者其实完全不是一个层次的问题。
然而,“机器能思考吗?”和“机器能做我们这些思考者所做的事吗?”这两个问题真的可以相互替代吗?
比如说,机器能够写诗,甚至比许多资质平庸的人写出的诗更像样子。如果我们人为拟定一套标准,来为机器和人写的诗打分,那么完全有可能设计出一台能够赢过绝大多数诗人的写诗机器。但这真的和人类理解并欣赏一首诗是一回事吗?再比如,人工智能在国际象棋、围棋领域已经比人类更强大,但这真正和人类思考如何下棋是一样的吗?
世界上有这么一个关于图灵测试的奖项——“勒布纳奖”,颁给擅长模仿人类真实对话场景的机器人。然而,这个奖项大多数的获得者都没有看上去那样智能。比如一个人问一台机器“你有多爱我?”,如果它想通过图灵测试,它就不停地顾左右而言他,比如回答“你觉得呢?”事实上大多数问题都可以用反问去替代,说白了这些仅仅是一些对话技巧。而获胜者并没有真正理解“你有多爱我?”这样的问题。
这里有句话,希望大家记住:人工智能的真实使命是塑造智能,而非去刻意打造为了通过某类随机测试的“专业”程序。
所幸到今天为止,很多学者都意识到了图灵测试的局限性,如果我们要发明人工智能,就要真正清楚地定义人工智能。同样如果我们要做智能对话,我们也要清晰地定义智能对话。
在2013年的一次国际会议上,来自多伦多大学的计算机科学家发表了一篇论文,对“图灵测试”提出了批评。他认为类似这样的人机博弈其实并不能真正反映机器的智能水平。对于人工智能来说,真正构成挑战的是这样的问题:
镇上的议员们拒绝给愤怒的游行者提供游行许可——“因为他们担心会发生暴力行为”——是谁在担心暴力行为?
A.镇上的议员们
B.愤怒的游行者
类似这样的问题,机器有没有可能找到正确的答案?要判断“他”究竟指代谁,需要的不是语法书或者百科辞典,而是常识。人工智能如何能够理解一个人会在什么情况下“担心”?这些问题涉及人类语言和社会交往的本质,以及对话的前后语境。这些本质其实是一种规则,而这种规则是在不停变化的。正是在这些方面,目前人工智能还无法与人类相比。
这意味着,制造一台能与人类下棋的机器人很容易,但想要制造一台能理解人类语言的机器人却很难。
为了更好地理解机器对话,英特将现有的对话技术进行总结并画出流程图(见图3-1),这里面涉及的逻辑和模块较多,英特是从模拟人类对话的第一步,即理解人类的语言开始的,当然要做到完全理解人类的语言在目前来讲也不太可能。对于机器人来说,无论何种用途的机器人,首要需要解决的就是理解人类说了些什么,而除了命令句式以外,理解人类说什么就是理解人类提出的各种问题。请移步下一节来看看如何理解人类的提问。
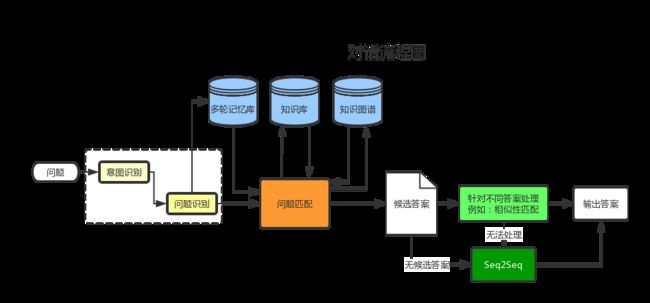
理解人类提问
英特调查后发现对于中文问题来说,无非可以分成以下两类:疑问句和反问句。对于反问句当然没什么好说的,我们来重点看看疑问句。可以分为是非问句、正反问句、特指问句、选择问句,其中特指问句又可以分为人、原因、地点、时间、意见、数量、方式和其余的实体。
对于问题来说,人类也需要首先对句子做一个判断,拿特指问题来说,需要判断到底是问什么?接着将每个问题做一个初步的定位,缩小回答时的搜索范围,最后从知识体系和场景中取得答案。
英特团队按照句式结构找了些例句放进去,为后一步的句式分类准备好训练集。
比如在“特指问句_时间”里放入了如下例句。
中国第一部宪法颁布的时间?
哪天你有空?
演唱会是哪天?
又比如“特指问句_原因”里放入如下例句。
为什么人的面容千差万别?
为什么我感觉不到演员演技的好坏?
为什么不要空腹喝牛奶?
用我们在第2章提到的任意特征提取器、分类模型,我们都能得到一个基本准确的输出,比如问题“还有多久轮到我们”。
Enter the sentence you want to test(“quit” to break):还有多久轮到我们
Sentence Type: 疑问句_特指问句_时间 -- 答案的抽取和选择
在答案的提取阶段,一般的对话像常见的智能对话助手Siri、小冰等,都是有对应的问题答案组(QA)的,这种QA数量一般都接近百万级了。而在现实工作中,没有能力和精力人工组建QA怎么办?这个时候我们可以使用互联网的信息——利用爬虫爬取。
大体过程是这样的:
(1)定义一个爬虫,针对某些问题的特点爬取候选答案