作者:张江
制造出能够像人类一样思考的机器是科学家们最伟大的梦想之中的一个。用智慧的大脑解读智慧必将成为科学发展的终极。
而验证这样的解读的最有效手段,莫过于再造一个智慧大脑——人工智能(Artificial Intelligence,AI)。
人们对人工智能的了解恐怕主要来自于好莱坞的科幻片。
这些荧幕上的机器(见图1-1)要么杀人如麻。如《终结者》《黑客帝国》。要么小巧可爱,如《机器人瓦利》。要么多愁善感,如《人工智能》;还有一些则大音希声、大象无形。如《黑客帝国》中的Matrix网络,以及《超验骇客》《超体》。
全部这些荧幕上的人工智能都具备一些共同特征:异常强大、能力非凡。

然而,现实中的人工智能却与这些荧幕上的机器人相差甚远,但它们的确已经在我们身边。
搜索引擎、邮件过滤器、智能语音助手Siri、二维码扫描器、游戏中的NPC(非玩家扮演角色)都是近60年来人工智能技术有用化的产物。这些人工智能都是一个个单一功能的“裸”程序,没有坚硬的、灵活的躯壳。更没有想象中那么善解人意,甚至不是一个完整的个体。为什么想象与现实存在那么大的差距?这是由于,真正的人工智能的探索之路充满了波折与不确定。
历史上,研究人工智能就像是在坐过山车。忽上忽下。梦想的肥皂泡一次次被冰冷的科学事实戳破,科学家们不得不一次次又一次回到梦的起点。作为一个独立的学科,人工智能的发展非常奇葩。
它不像其它学科那样从分散走向统一,而是从1956年创立以来就不断地分裂,形成了一系列大大小小的子领域。
或许人工智能注定就是大杂烩,或许统一的时刻还未到来。
然而,人们对人工智能的梦想却是永远不会磨灭的。
本章将按历史的顺序介绍人工智能的发展。从早期的哥德尔、图灵等人的研究到“人工智能”一词的提出。再到后期的人工智能三大学派:符号学派、连接学派和行为学派,以及近年来的新进展:贝叶斯网络、深度学习、通用人工智能。最后我们将对未来的人工智能进行展望。
梦的開始(1900—1956)
大卫•希尔伯特

说来奇怪,人工智能之梦開始于一小撮20世纪初期的数学家。这些人真正做到了用方程推动整个世界。
历史的车轮倒回到1900年。世纪之交的数学家大会在巴黎如期召开,德高望重的老数学家大卫•希尔伯特(David Hilbert)庄严地向全世界数学家们宣布了23个未解决的难题。这23道难题道道经典。而当中的第二问题和第十问题则与人工智能密切相关。并终于促成了计算机的发明。
希尔伯特的第二问题来源于一个大胆的想法——运用公理化的方法统一整个数学,并运用严格的数学推理证明数学自身的正确性。这个野心被后人称为希尔伯特纲领,尽管他自己没能证明,但却把这个任务交给了后来的年轻人,这就是希尔伯特第二问题:证明数学系统中应同一时候具备一致性(数学真理不存在矛盾)和完备性(随意真理都能够被描写叙述为数学定理)。
库尔特•哥德尔

希尔伯特的勃勃野心无疑激励着每一位年轻的数学家,当中就包含一个来自捷克的年轻人:库尔特•哥德尔(Kurt Godel)。他起初是希尔伯特的忠实粉丝,并致力于攻克第二问题。然而。他非常快发现,自己之前的努力都是徒劳的。由于希尔伯特第二问题的断言根本就是错的:不论什么足够强大的数学公理系统都存在着瑕疵:一致性和完备性不能同一时候具备。非常快。哥德尔倒戈了,他背叛了希尔伯特,但却推动了整个数学的发展,于1931年提出了被美国《时代周刊》评选为20世纪最有影响力的数学定理:哥德尔不完备性定理。
尽管早在1931年。人工智能学科还没有建立,计算机也没有发明,可是哥德尔定理似乎已经为人工智能提出了警告。
这是由于假设我们把人工智能也看作一个机械化运作的数学公理系统,那么依据哥德尔定理。必定存在着某种人类能够构造、可是机器无法求解的人工智能的“软肋”。
这就好像我们无法揪着自己的脑袋脱离地球,数学无法证明数学本身的正确性,人工智能也无法仅凭自身解决全部问题。所以,存在着人类能够求解可是机器却不能解的问题。人工智能不可能超过人类。
但问题并没有这么简单,上述命题成立的一个前提是人与机器不同,不是一个机械的公理化系统。然而,这个前提是否成立迄今为止我们并不知道,所以这一问题仍在争论之中。
关于此观点的延伸讨论请參见本书第4章。
艾伦•图灵

另外一个与哥德尔年龄相仿的年轻人被希尔伯特的第十问题深深地吸引了。并决定为此奉献一生。这个人就是艾伦•图灵(Alan Turing)。
希尔伯特第十问题的表述是:“是否存在着判定随意一个丢番图方程有解的机械化运算过程。
”这句话的前半句比較晦涩,我们能够先忽略。由于后半句是重点。“机械化运算过程”用今天的话说就是算法。然而,当年。算法这个概念还是相当模糊的。
于是。图灵设想出了一个机器——图灵机。它是计算机的理论原型,圆满地刻画出了机械化运算过程的含义。并终于为计算机的发明铺平了道路。
图灵机模型(见图1-2)形象地模拟了人类进行计算的过程。假如我们希望计算随意两个3位数的加法:139 + 919。我们须要一张足够大的草稿纸以及一支能够在纸上不停地涂涂写写的笔。之后,我们须要从个位到百位一位一位地依照10以内的加法规则完毕加法。
我们还须要考虑进位,比如9 + 9 = 18,这个1就要加在十位上。
我们是通过在草稿纸上记下适当的标记来完毕这样的进位记忆的。
最后,我们把计算的结果输出到了纸上。

图灵机把全部这些过程都模型化了:草稿纸被模型化为一条无限长的纸带,笔被模型化为一个读写头,固定的10以内的运算法则模型化为输入给读写头的程序,对于进位的记忆则被模型化为读写头的内部状态。
于是。设定好纸带上的初始信息,以及读写头的当前内部状态和程序规则,图灵机就能够执行起来了。它在每一时刻读入一格纸带的信息,并依据当前的内部状态,查找对应的程序,从而给出下一时刻的内部状态并输出信息到纸带上。
关于图灵机的详细描写叙述,请參见本书第2章。
图灵机模型一经提出就得到了科学家们的认可,这无疑给了图灵莫大的鼓舞。他開始鼓起勇气。展开想象的翅膀。进一步思考图灵机运算能力的极限。1940年,图灵開始认真地思考机器能否够具备类人的智能。
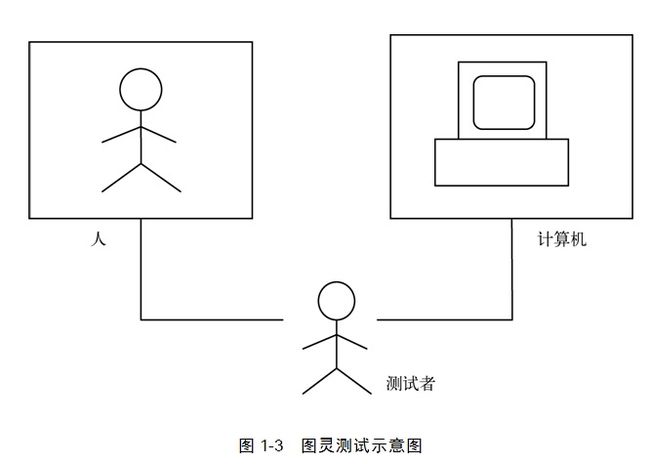
他立即意识到这个问题的要点其实并不在于怎样打造强大的机器,而在于我们人类怎样看待智能。即依据什么标准评价一台机器是否具备智能。于是,图灵在1950年发表了《机器能思考吗?》一文,提出了这样一个标准:假设一台机器通过了“图灵測试”,则我们必须接受这台机器具有智能。那么,图灵測试到底是怎样一种測试呢?
如图1-3所看到的,假设有两间密闭的屋子,当中一间屋子里面关了一个人,还有一间屋子里面关了一台计算机:进行图灵測试的人工智能程序。
然后。屋子外面有一个人作为測试者。測试者仅仅能通过一根导线与屋子里面的人或计算机交流——与它们进行联网聊天。假如測试者在有限的时间内无法推断出这两间屋子里面哪一个关的是人。哪一个是计算机,那么我们就称屋子里面的人工智能程序通过了图灵測试。并具备了智能。其实,图灵当年在《机器能思考吗?》一文中设立的标准相当宽泛:仅仅要有30%的人类測试者在5分钟内无法分辨出被測试对象,就能够觉得程序通过了图灵測试。
2014年6月12日。一个名为“尤金”(Eugene Goostman)的聊天程序(见图1-4)成功地在5分钟内蒙骗了30%的人类測试者,从而达到了图灵当年提出来的标准。
非常多人觉得。这款程序具有划时代的意义,它是自图灵測试提出64年后第一个通过图灵測试的程序。可是。非常快就有人提出这仅仅只是是一个噱头,该程序并没有宣传的那么厉害。比如。谷歌公司的project总监、未来学家雷•库兹韦尔(Ray Kurzweil)就表示。这个聊天机器人号称仅仅有13岁,并使用第二语言来回答问题,这成为了该程序重大缺陷的借口。另外,測试者仅仅有5分钟与之展开互动,这大大添加了他们在短期内被“欺骗”的概率。

由此可见,图灵将智能等同于符号运算的智能表现,而忽略了实现这样的符号智能表现的机器内涵。这样做的优点是能够将所谓的智能本质这一问题绕过去,它的代价是人工智能研制者们会把注意力集中在怎样让程序欺骗人类測试者上,甚至能够不择手段。
所以,对于将图灵測试作为评判机器具备智能的唯一标准,非常多人開始质疑。由于人类智能还包含诸如对复杂形式的推断、创造性地解决这个问题的方法等,而这些特质都无法在图灵測试中体现出来。

总而言之,图灵的研究无疑大大推动了人工智能的进展。
然而。图灵本人却于1954年死于一个被剧毒氰化物注射过的苹果,享年仅仅42岁。
传闻他是一名同性恋,这在当时的英国是非法的。于是英国政府强行给他注射一种药物抑制他的同性恋倾向,这导致他终于在治疗期间痛苦万分地自杀了。据说,苹果公司为了纪念这位计算机科学之父。特意用那个被图灵咬掉一口的苹果作为公司的logo。1966年,美国计算机协会设立了以图灵命名的图灵奖。以专门奖励那些对计算机事业作出重要贡献的人。这相当于计算机领域的诺贝尔奖。
约翰•冯•诺依曼
就在哥德尔绞尽脑汁捉摸希尔伯特第二问题的时候。另外一个来自匈牙利布达佩斯的天才少年也在思考相同的问题,他就是大名鼎鼎的约翰•冯•诺依曼(John von Neumann)。
然而,冯•诺依曼远没有哥德尔走运。到了1931年。冯•诺依曼即将在希尔伯特第二问题上获得突破,却突然得知哥德尔已经发表了哥德尔定理。先他一步。于是。冯•诺依曼一气之下開始转行研究起了量子力学。就在他的量子力学研究即将结出硕果之际,另外一位天才物理学家保罗•狄拉克(Paul Dirac)又一次抢了他的风头,出版了《量子力学原理》,并一举成名。
这比冯•诺依曼的《量子力学的数学基础》整整早了两年。
受到两次打击之后,冯•诺依曼開始把部分注意力从基础数学转向了project应用领域,终于大获成功。1945年,凭借出众的才华,冯•诺依曼在火车上完毕了早期的计算机EDVAC的设计,并提出了我们如今熟知的“冯•诺依曼体系结构”。
冯•诺依曼的计算机与图灵机是一脉相承的,但最大的不同就在于。冯•诺依曼的读写头不再须要一格一格地读写纸带。而是依据指定的地址,随机地跳到对应的位置完毕读写。
这也就是我们今天所说的随机訪问存储器(Random Access Memory,RAM)的前身。关于冯•诺依曼体系结构和现代计算机的工作原理,请參见本书第3章。
冯•诺依曼的计算机终于使得数学家们的研究结出了硕果,也终于推动着人类历史进入了信息时代,使得人工智能之梦成为了可能。
诺伯特•维纳

我们要介绍的最后一位数学家是美国的天才神童诺伯特•维纳(Norbert Wiener)。据说维纳三岁的时候就開始在父亲的影响下读天文学和生物学的图书。七岁的时候他所读的物理学和生物学的知识范围已经超出了他父亲。他年纪轻轻就掌握了拉丁语、希腊语、德语和英语,并且涉猎人类科学的各个领域。后来,他留学欧洲,曾先后拜师于罗素、希尔伯特、哈代等哲学、数学大师。
维纳在他70年的科学生涯中。先后涉足数学、物理学、project学和生物学,共发表240多篇论文。著作14本。
然而。与我们的主题最相关的,则要数维纳于1948年提出来的新兴学科“控制论”(Cybernetics)了。“Cybernetics”一词源于希腊语的“掌舵人”。
在控制论中,维纳深入探讨了机器与人的统一性——人或机器都是通过反馈完毕某种目的的实现。因此他揭示了用机器模拟人的可能性,这为人工智能的提出奠定了重要基础。维纳也是最早注意到心理学、脑科学和project学应相互交叉的人之中的一个。这促使了后来认知科学的发展。
这几位数学大师不满足于“躲进小楼成一统”,埋头解决一两个超级数学难题。他们的思想大胆地拥抱了斑驳复杂的世界。终于用他们的方程推动了社会的进步。开启了人工智能之梦。
梦的延续(1956—1980)
在数学大师们铺平了理论道路,project师们踏平了技术坎坷。计算机已呱呱落地的时候,人工智能终于横空出世了。
而这一历史时刻的到来却是从一个不起眼的会议開始的。
达特茅斯会议
1956年8月,在美国汉诺斯小镇宁静的达特茅斯学院中,约翰•麦卡锡(John McCarthy)、马文•闵斯基(Marvin Minsky,人工智能与认知学专家)、克劳德•香农(Claude Shannon。信息论的创始人)、艾伦•纽厄尔(Allen Newell,计算机科学家)、赫伯特•西蒙(Herbert Simon,诺贝尔经济学奖得主)等科学家正聚在一起,讨论着一个全然不食人间烟火的主题:用机器来模仿人类学习以及其它方面的智能。
会议足足开了两个月的时间。尽管大家没有达成普遍的共识,可是却为会议讨论的内容起了一个名字:人工智能。因此,1956年也就成为了人工智能元年。
黄金时期
达特茅斯会议之后,人工智能获得了井喷式的发展。好消息接踵而至。机器定理证明——用计算机程序取代人类进行自己主动推理来证明数学定理——是最先取得重大突破的领域之中的一个。
在达特茅斯会议上。纽厄尔和西蒙展示了他们的程序:“逻辑理论家”能够独立证明出《数学原理》第二章的38条定理。而到了1963年,该程序已能证明该章的全部52条定理。1958年。美籍华人王浩在IBM704计算机上以3~5分钟的时间证明了《数学原理》中有关命题演算部分的全部220条定理。
而就在这一年。IBM公司还研制出了平面几何的定理证明程序。
1976年,凯尼斯•阿佩尔(Kenneth Appel)和沃夫冈•哈肯(Wolfgang Haken)等人利用人工和计算机混合的方式证明了一个著名的数学猜想:四色猜想(如今称为四色定理)。这个猜想表述起来非常easy易懂:对于随意的地图,我们最少仅用四种颜色就能够染色该地图,并使得随意两个相邻的国家不会重色。然而证明起来却异常烦琐。配合着计算机超强的穷举和计算能力,阿佩尔等人把这个猜想证明了。
还有一方面。机器学习领域也获得了实质的突破,在1956年的达特茅斯会议上,阿瑟•萨缪尔(Arthur Samuel)研制了一个跳棋程序。该程序具有自学习功能,能够从比赛中不断总结经验提高棋艺。1959年,该跳棋程序打败了它的设计者萨缪尔本人,过了3年后,该程序已经能够击败美国一个州的跳棋冠军。
1956年。奥利弗•萨尔夫瑞德(Oliver Selfridge)研制出第一个字符识别程序。开辟了模式识别这一新的领域。
1957年,纽厄尔和西蒙等開始研究一种不依赖于详细领域的通用问题求解器,他们称之为GPS(General Problem Solver)。1963年,詹姆斯•斯拉格(James Slagle)发表了一个符号积分程序SAINT,输入一个函数的表达式,该程序就能自己主动输出这个函数的积分表达式。过了4年后,他们研制出了符号积分运算的升级版SIN,SIN的运算已经能够达到专家级水准。
遇到瓶颈
全部这一切来得太快了。胜利冲昏了人工智能科学家们的头脑,他们開始盲目乐观起来。比如,1958年,纽厄尔和西蒙就自信满满地说,不出10年,计算机将会成为世界象棋冠军,证明重要的数学定理,谱出优美的音乐。照这样的速度发展下去,2000年人工智能就真的能够超过人类了。
然而,历史似乎有益要作弄轻狂无知的人工智能科学家们。
1965年,机器定理证明领域遇到了瓶颈。计算机推了数十万步也无法证明两个连续函数之和仍是连续函数。萨缪尔的跳棋程序也没那么神气了,它停留在了州冠军的层次,无法进一步战胜世界冠军。
最糟糕的事情发生在机器翻译领域。对于人类自然语言的理解是人工智能中的硬骨头。
计算机在自然语言理解与翻译过程中表现得极其差劲。一个最典型的样例就是以下这个著名的英语句子:
The spirit is willing but the flesh is weak. (心有余而力不足。)
当时,人们让机器翻译程序把这句话翻译成俄语。然后再翻译回英语以检验效果,得到的句子居然是:
The wine is good but the meet is spoiled.(酒是好的。肉变质了。)
这简直是驴唇不正确马嘴嘛。
怪不得有人挖苦道,美国政府花了2000万美元为机器翻译挖掘了一座坟墓。有关自然语言理解的很多其它内容。请參见本书第10章。
总而言之,越来越多的不利证据迫使政府和大学削减了人工智能的项目经费,这使得人工智能进入了寒冷的冬天。来自各方的事实证明。人工智能的发展不可能像人们早期设想的那样一帆风顺。人们必须静下心来冷静思考。
知识就是力量
经历了短暂的挫折之后,AI研究者们開始痛定思痛。
爱德华•费根鲍姆(Edward A. Feigenbaum)就是新生力量的佼佼者,他举着“知识就是力量”的大旗,非常快开辟了新的道路。

费根鲍姆分析到,传统的人工智能之所以会陷入僵局,就是由于他们过于强调通用求解方法的作用,而忽略了详细的知识。
细致思考我们人类的求解过程就会发现,知识无时无刻不在起着重要作用。因此。人工智能必须引入知识。
于是,在费根鲍姆的带领下。一个新的领域专家系统诞生了。所谓的专家系统就是利用计算机化的知识进行自己主动推理。从而模仿领域专家解决这个问题。第一个成功的专家系统DENDRAL于1968年问世,它能够依据质谱仪的数据推知物质的分子结构。在这个系统的影响下,各式各样的专家系统非常快陆续涌现,形成了一种软件产业的全新分支:知识产业。1977年,在第五届国际人工智能大会上,费根鲍姆用知识project概括了这个全新的领域。
在知识project的刺激下,日本的第五代计算机计划、英国的阿尔维计划、西欧的尤里卡计划、美国的星计划和中国的863计划陆续推出,尽管这些大的科研计划并不都是针对人工智能的,可是AI都作为这些计划的重要组成部分。
然而。好景不长。在专家系统、知识project获得大量的实践经验之后,弊端開始逐渐显现了出来。这就是知识获取。
面对这个全新的棘手问题。新的“费根鲍姆”没有再次出现。人工智能这个学科却发生了重大转变:它逐渐分化成了几大不同的学派。
群龙问鼎(1980—2010)
专家系统、知识project的运作须要从外界获得大量知识的输入,而这样的输入工作是极其费时费力的,这就是知识获取的瓶颈。于是,在20世纪80年代,机器学习这个原本处于人工智能边缘地区的分支一下子成为了人们关注的焦点。
尽管传统的人工智能研究者也在奋力挣扎,可是人们非常快发现,假设採用全然不同的世界观。即让知识通过自下而上的方式涌现。而不是让专家们自上而下地设计出来。那么机器学习的问题其实能够得到非常好地解决。
这就好比我们教育小孩子,传统人工智能好像填鸭式教学。而新的方法则是启示式教学:让孩子自己来学。
其实,在人工智能界。非常早就有人提出过自下而上的涌现智能的方案,仅仅只是它们从来没有引起大家的注意。一批人觉得能够通过模拟大脑的结构(神经网络)来实现,而还有一批人则觉得能够从那些简单生物体与环境互动的模式中寻找答案。他们分别被称为连接学派和行为学派。与此相对,传统的人工智能则被统称为符号学派。自20世纪80年代開始,到20世纪90年代。这三大学派形成了三足鼎立的局面。
符号学派

作为符号学派的代表,人工智能的创始人之中的一个约翰•麦卡锡在自己的站点上挂了一篇文章《什么是人工智能》,为大家阐明什么是人工智能(依照符号学派的理解)。
(人工智能)是关于怎样制造智能机器,特别是智能的计算机程序的科学和project。
它与使用机器来理解人类智能密切相关,但人工智能的研究并不须要局限于生物学上可观察到的那些方法。
在这里,麦卡锡特意强调人工智能研究并不一定局限于模拟真实的生物智能行为,而是更强调它的智能行为和表现的方面。这一点和图灵測试的想法是一脉相承的。另外。麦卡锡还突出了利用计算机程序来模拟智能的方法。他觉得,智能是一种特殊的软件,与实现它的硬件并没有太大的关系。
纽厄尔和西蒙则把这样的观点概括为“物理符号系统假说”(physical symbolic system hypothesis)。该假说觉得,不论什么能够将物理的某些模式(pattern)或符号进行操作并转化成另外一些模式或符号的系统。就有可能产生智能的行为。
这样的物理符号能够是通过高低电位的组成或者是灯泡的亮灭所形成的霓虹灯图案。当然也能够是人脑神经网络上的电脉冲信号。
这也恰恰是“符号学派”得名的依据。
在“物理符号系统假说”的支持下,符号学派把焦点集中在人类智能的高级行为,如推理、规划、知识表示等方面。这些工作在一些领域获得了空前的成功。
人机大战
计算机博弈(下棋)方面的成功就是符号学派名扬天下的资本。
早在1958年,人工智能的创始人之中的一个西蒙就曾预言。计算机会在10年内成为国际象棋世界冠军。
然而,正如我们前面讨论过的。这样的预測过于乐观了。
事实比西蒙的预言足足晚了40年的时间。
1988年,IBM開始研发能够与人下国际象棋的智能程序“深思”——一个能够以每秒70万步棋的速度进行思考的超级程序。
到了1991年,“深思II”已经能够战平澳大利亚国际象棋冠军达瑞尔•约翰森(Darryl Johansen)。1996年。“深思”的升级版“深蓝”開始挑战著名的人类国际象棋世界冠军加里•卡斯帕罗夫(Garry Kasparov)。却以2:4败下阵来。可是。一年后的5月11日,“深蓝”终于以3.5:2.5的成绩战胜了卡斯帕罗夫(见图1-5),成为了人工智能的一个里程碑。

图片来源:http://cdn.theatlantic.com/static/mt/assets/science/kasparov615.jpg。
人机大战终于以计算机的胜利划上了句号。
那是不是说计算机已经超越了人类了呢?要知道,计算机通过超级强大的搜索能力险胜了人类——当时的“深蓝”已经能够在1秒钟内算两亿步棋。
并且。“深蓝”存储了100年来差点儿全部的国际特级大师的开局和残局下法。另外还有四位国际象棋特级大师亲自“训练”“深蓝”,真可谓是超豪华阵容。所以,终于的结果非常难说是计算机战胜了人,更像是一批人战胜了还有一批人。
最重要的是,国际象棋上的博弈是在一个封闭的棋盘世界中进行的,而人类智能面对的则是一个复杂得多的开放世界。
然而,时隔14年后,另外一场在IBM超级计算机和人类之间的人机大战刷新了记录,也使得我们必须又一次思考机器能否战胜人类这个问题。由于这次的比赛不再是下棋,而是自由的“知识问答”,这样的竞赛环境比国际象棋开放得多。由于提问的知识能够涵盖时事、历史、文学、艺术、流行文化、科学、体育、地理、文字游戏等多个方面。
因此,这次的机器胜利至少证明了计算机相同能够在开放的世界中表现得不逊于人类。
这场人机大战的游戏叫作《危急》(Jeopardy)。是美国一款著名的电视节目。在节目中。主持人通过自然语言给出一系列线索,然后。參赛队员要依据这些线索用最短的时间把主持人描写叙述的人或者事物猜出来,并且以提问的方式回答。比如当节目主持人给出线索“这是一种冷血的无足的冬眠动物”的时候。选手应该回答“什么是蛇?”而不是简单地回答“蛇”。由于问题会涉及各个领域,所以一般知识渊博的人类选手都非常难获胜。
然而。在2011年2月14日到2月16日期间的《危急》比赛中。IBM公司的超级计算机沃森(Watson)却战胜了人类选手(见图1-6)。

图片来源:http://cdn.geekwire.com/wp-content/uploads/IBM-Watson.jpg。
这一次,IBM打造的沃森是一款全然不同于以往的机器。
首先。它必须是一个自然语言处理的高手。由于它必须在短时间内理解主持人的提问。甚至有的时候还必须理解语言中的隐含意思。
而正如我们前文所说,自然语言理解始终是人工智能的最大难题。其次。沃森必须充分了解字谜。要领会双关语,并且脑中还要装满诸如莎士比亚戏剧的独白、全球基本的河流和各国首都等知识。全部这些知识并不限定在某个详细的领域。所以,沃森的胜利的确是人工智能界的一个标志性事件。
能够说,人机大战是人工智能符号学派1980年以来最出风头的应用。
然而。这样的无休止的人机大战也难逃成为噱头的嫌疑。
其实。历史上每次吸引眼球的人机大战似乎都必定伴随着IBM公司的股票大涨,这也就不难理解为什么IBM会花重金开发出一款又一款大型计算机去參加这么多无聊的竞赛,而不是去做一些更有用的东西了。
实际上,20世纪80年代以后,符号学派的发展势头已经远不如当年了。由于人工智能武林霸主的地位非常快就属于其它学派了。
连接学派
我们知道,人类的智慧主要来源于大脑的活动,而大脑则是由一万亿个神经元细胞通过错综复杂的相互连接形成的。于是。人们非常自然地想到,我们能否够通过模拟大量神经元的集体活动来模拟大脑的智力呢?
对照物理符号系统假说,我们不难发现,假设将智力活动比喻成一款软件,那么支撑这些活动的大脑神经网络就是对应的硬件。于是,主张神经网络研究的科学家实际上在强调硬件的作用。觉得高级的智能行为是从大量神经网络的连接中自发出现的,因此,他们又被称为连接学派。
神经网络
连接学派的发展也是一波三折。
其实,最早的神经网络研究能够追溯到1943年计算机发明之前。
当时,沃伦•麦卡洛克(Warren McCulloch)和沃尔特•匹兹 (Walter Pitts)二人提出了一个单个神经元的计算模型。如图1-7所看到的。
在这个模型中,左边的I1, I2, … ,IN为输入单元,能够从其它神经元接受输出。然后将这些信号经过加权(W1, W2, … ,WN)传递给当前的神经元并完毕汇总。假设汇总的输入信息强度超过了一定的阈值(T)。则该神经元就会发放一个信号y给其它神经元或者直接输出到外界。
该模型后来被称为麦卡洛克匹兹模型。能够说它是第一个真实神经元细胞的模型。

1957年,弗兰克•罗森布拉特(Frank Rosenblatt)对麦卡洛克匹兹模型进行了扩充。即在麦卡洛克匹兹神经元上添加了学习算法。扩充的模型有一个响亮的名字:感知机。感知机能够依据模型的输出y与我们希望模型的输出y*之间的误差,调整权重W1, W2, …, WN来完毕学习。
我们能够形象地把感知机模型理解为一个装满了大大小小水龙头(W1, W2, …, WN)的水管网络,学习算法能够调节这些水龙头来控制终于输出的水流。并让它达到我们想要的流量。这就是学习的过程。这样,感知机就好像一个能够学习的小孩,不管什么问题。仅仅要明白了我们想要的输入和输出之间的关系,都可能通过学习得以解决,至少它的拥护者是这样觉得的。
然而,好景不长,1969年,人工智能界的权威人士马文•闵斯基给连接学派带来了致命一击。他通过理论分析指出,感知机并不像它的创立者罗森布拉特宣称的那样能够学习不论什么问题。连一个最简单的问题:推断一个两位的二进制数是否仅包含0或者1(即所谓的XOR问题)都无法完毕。
这一打击是致命的,本来就不是非常热的神经网络研究差点就被闵斯基这一棒子打死了。

多则不同
1974年,人工智能连接学派的救世主杰夫•辛顿(Geoffrey Hinton)终于出现了。
他曾至少两次挽回连接学派的败局。1974年是第一次,第二次会在下文提到。
辛顿的出发点非常easy——“多则不同”:仅仅要把多个感知机连接成一个分层的网络,那么。它就能够圆满地解决闵斯基的问题。如图1-8所看到的,多个感知机连接成为一个四层的网络。最左面为输入层,最右面为输出层,中间的那些神经元位于隐含层,右側的神经元接受左側神经元的输出。

但接下来的问题是,“人多吃得多”,那么多个神经元。可能有几百甚至上千个參数须要调节,我们怎样对这样复杂的网络进行训练呢?辛顿等人发现,採用几年前阿瑟•布赖森(Arthur Bryson)等人提出来的反向传播算法(Back propagation algorithm,简称BP算法)就能够有效解决多层网络的训练问题。
还是以水流管道为例来说明。
当网络执行决策的时候,水从左側的输入节点往右流。直到输出节点将水吐出。而在训练阶段,我们则须要从右往左来一层层地调节各个水龙头。要使水流量达到要求。我们仅仅要让每一层的调节仅仅对它右面一层的节点负责就能够了,这就是反向传播算法。事实证明,多层神经网络装备上反向传播算法之后,能够解决非常多复杂的识别和预測等问题。
差点儿是在同一时间,又有几个不同的神经网络模型先后被提出,这些模型有的能够完毕模式聚类,有的能够模拟联想思维。有的具有深厚的数学物理基础。有的则模仿生物的构造。全部这些大的突破都令连接学派名声大噪,异军突起。
统计学习理论
然而,连接学派的科学家们非常快又陷入了困境。
尽管各种神经网络能够解决这个问题,可是,它们到底为什么会成功以及为什么在有些问题上会屡遭失败。却没有人能说得清楚。对网络执行原理的无知,也使得人们对怎样提高神经网络执行效率的问题无从下手。因此。连接学派须要理论的支持。

2000年左右,弗拉基米尔•万普尼克(Vladimir Naumovich Vapnik)和亚历克塞•泽范兰杰斯(Alexey Yakovlevich Chervonenkis)这两位俄罗斯科学家提出了一整套新的理论:统计学习理论,受到连接学派的顶礼膜拜。
该理论大意可概括为“杀鸡焉用宰牛刀”。我们的模型一定要与待解决的问题相匹配,假设模型过于简单,而问题本身的复杂度非常高。就无法得到预期的精度。反过来,若问题本身简单,而模型过于复杂,那么模型就会比較僵死,无法举一反三,即出现所谓的“过拟合”(overfitting)现象。
实际上。统计学习理论的精神与奥卡姆剃刀原理有着深刻的联系。威廉•奥卡姆(William Occum,1287—1347)是中世纪时期的著名哲学家,他留下的最重要的遗产就是奥卡姆剃刀原理。该原理说,假设对于同一个问题有不同的解决方式,那么我们应该挑选当中最简单的一个。神经网络或者其它机器学习模型也应该遵循相似的原理,仅仅有当模型的复杂度与所解决的问题相匹配的时候。才干让模型更好地发挥作用。
然而,统计学习理论也有非常大的局限性。由于理论的严格分析仅仅限于一类特殊的神经网络模型:支持向量机(Supporting Vector Machine)。而对于更一般的神经网络。人们还未找到统一的分析方法。所以说,连接学派的科学家们尽管会向大脑学习怎样构造神经网络模型。但实际上他们自己也不清楚这些神经网络到底是怎样工作的。只是,他们这样的尴尬局面也是无独有偶,另外一派后起之秀尽管来势汹汹,却也没有解决理论基础问题,这就是行为学派。
行为学派
行为学派的出发点与符号学派和连接学派全然不同,他们并没有把目光聚焦在具有高级智能的人类身上,而是关注比人类低级得多的昆虫。即使这样简单的动物也体现出了非凡的智能,昆虫能够灵活地摆动自己的身体行走。还能够高速地反应。躲避捕食者的攻击。而还有一方面,尽管蚂蚁个体非常easy,可是。当非常多小蚂蚁聚集在一起形成庞大的蚁群的时候,却能表现出非凡的智能。还能形成严密的社会分工组织。
正是受到了自然界中这些相对低等生物的启示,行为学派的科学家们决定从简单的昆虫入手来理解智能的产生。的确,他们取得了不错的成果。
机器昆虫

罗德尼•布鲁克斯(Rodney Brooks)是一名来自美国麻省理工学院的机器人专家。在他的实验室中有大量的机器昆虫(如图1-9所看到的)。相对于那些笨拙的机器人铁家伙来说,这些小昆虫要灵活得多。
这些机器昆虫没有复杂的大脑。也不会依照传统的方式进行复杂的知识表示和推理。
它们甚至不须要大脑的干预,仅凭四肢和关节的协调,就能非常好地适应环境。
当我们把这些机器昆虫放到复杂的地形中的时候。它们能够痛快地爬行,还能聪明地避开障碍物。
它们看起来的智能其实并不来源于自上而下的复杂设计。而是来源于自下而上的与环境的互动。
这就是布鲁克斯所倡导的理念。

假设说符号学派模拟智能软件,连接学派模拟大脑硬件,那么行为学派就算是模拟身体了。并且是简单的、看起来没有什么智能的身体。
比如,行为学派的一个非常成功的应用就是美国波士顿动力公司(Boston Dynamics)研制开发的机器人“大狗② 。如图1-10所看到的,“大狗”是一个四足机器人。它能够在各种复杂的地形中行走、攀爬、奔跑,甚至还能够背负重物。
“大狗”模拟了四足动物的行走行为。能够自适应地依据不同的地形调整行走的模式。推荐感兴趣的读者扫描下方二维码观看视频介绍。
图片来源:http://grant.solarbotics.net/walkman.htm。 BigDog。參见http://www.bostondynamics.com/robot_bigdog.html。

当这仅仅大狗伴随着“沙沙”的机器运作声朝你走来时,你一定会被它的气势所吓到。由于它的样子非常像是一头公牛呢。
进化计算

我们从生物身上学到的东西还不仅仅是这些。从更长的时间尺度看,生物体对环境的适应还会迫使生物进化。从而实现从简单到复杂、从低等到高等的跃迁。
约翰•霍兰(John Holland)是美国密西根大学的心理学、电器project以及计算机的三科教授。他本科毕业于麻省理工学院,后来到了密西根大学师从阿瑟•伯克斯(Arthur Burks。曾是冯•诺依曼的助手)攻读博士学位。
1959年。他拿到了全世界首个计算机科学的博士头衔。别看霍兰个头不高,他的骨子里却有一种离经叛道的气魄。他在读博期间就对怎样用计算机模拟生物进化异常着迷,并终于发表了他的遗传算法。
遗传算法对大自然中的生物进化进行了大胆的抽象,终于提取出两个主要环节:变异(包含基因重组和突变)和选择。
在计算机中。我们能够用一堆二进制串来模拟自然界中的生物体。而大自然的选择作用——生存竞争、优胜劣汰——则被抽象为一个简单的适应度函数。这样,一个超级浓缩版的大自然进化过程就能够搬到计算机中了,这就是遗传算法。
图片来源:http://www.militaryfactory.com/armor/detail.asp?armor_id=184。
遗传算法在刚发表的时候并没有引起多少人的重视。然而,随着时间的推移。当人工智能的焦点转向机器学习时,遗传算法就一下子家喻户晓了。由于它的确是一个非常easy而有效的机器学习算法。与神经网络不同,遗传算法不须要把学习区分成训练和执行两个阶段,它全然能够指导机器在执行中学习,即所谓的做中学(learning by doing)。同一时候,遗传算法比神经网络具有更方便的表达性和简单性。
无独有偶。美国的劳伦斯•福格尔(Lawrence Fogel)、德国的因戈•雷伯格(Ingo Rechenberg)以及汉斯•保罗•施韦费尔(Hans-Paul Schwefel)、霍兰的学生约翰•科扎 (John Koza)等人也先后提出了演化策略、演化编程和遗传编程。
这使得进化计算大家庭的成员更加多样化了。
人工生命
不管是机器昆虫还是进化计算。科学家们关注的焦点都是怎样模仿生物来创造智能的机器或者算法。克里斯托弗•兰顿(Chirstopher Langton)进行了进一步提炼。提出了“人工生命”这一新兴学科。人工生命与人工智能非常接近。可是它的关注点在于怎样用计算的手段来模拟生命这样的更加“低等”的现象。
人工生命觉得。所谓的生命或者智能实际上是从底层单元(能够是大分子化合物。也能够是数字代码)通过相互作用而产生的涌现属性(emergent property)。
“涌现”(emergence)这个词是人工生命研究中使用频率最高的词之中的一个,它强调了一种仅仅有在宏观具备但不能分解还原到微观层次的属性、特征或行为。单个的蛋白质分子不具备生命特征,可是大量的蛋白质分子组合在一起形成细胞的时候,整个系统就具备了“活”性,这就是典型的涌现。相同地,智能则是比生命更高一级(假如我们能够将智能和生命分成不同等级的话)的涌现——在生命系统中又涌现出了一整套神经网络系统,从而使得整个生命体具备了智能属性。
现实世界中的生命是由碳水化合物编织成的一个复杂网络,而人工生命则是寄生于01世界中的复杂有机体。
人工生命的研究思路是通过模拟的形式在计算机数码世界中产生相似现实世界的涌现。因此,从本质上讲,人工生命模拟的就是涌现过程。而不太关心实现这个过程的详细单元。
我们用01数字代表蛋白质分子。并为其设置详细的规则,接下来的事情就是执行这个程序。然后盯着屏幕。喝上一杯咖啡,等待着令人惊讶的“生命现象”在电脑中出现。
模拟群体行为是人工生命的典型应用之中的一个。1983年。计算机图形学家克雷格•雷诺兹(Craig Reynolds)曾开发了一个名为Boid的计算机模拟程序(见图1-11),它能够逼真地模拟鸟群的运动,还能够聪明地躲避障碍物。后来。肯尼迪(Kennedy)等人于1995年扩展了Boid模型。提出了PSO(粒子群优化)算法。成功地通过模拟鸟群的运动来解决函数优化等问题。
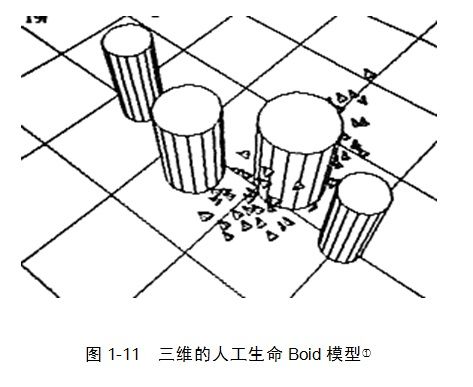
相似地,利用模拟群体行为来实现智能设计的样例还有非常多,比如蚁群算法、免疫算法等,共同特征都是让智能从规则中自下而上地涌现出来,并能解决实际问题。关于人工生命的详细讨论,能够參考本书11~13章。
然而,行为学派带来的问题似乎比提供的解决方法还多。到底在什么情况下能够发生涌现?怎样设计底层规则使得系统能够以我们希望的方式涌现?行为学派、人工生命的研究者们无法回答。更糟糕的是。几十年过去了,人工生命研究似乎仍然仅仅擅长于模拟小虫子、蚂蚁之类的低等生物,高级的智能全然没有像他们预期的那样自然涌现,并且没有丝毫迹象。
图片来源:http://www.red3d.com/cwr/boids/。
三大学派间的关系
正如我们前面提到的。这三个学派大致是从软件、硬件和身体这三个角度来模拟和理解智能的。
可是。这仅仅是一个粗糙的比喻。其实。三大学派之间还存在着非常多微妙的差异和联系。
首先。符号学派的思想和观点直接继承自图灵,他们是直接从功能的角度来理解智能的。
他们把智能理解为一个黑箱,仅仅关心这个黑箱的输入和输出。而不关心黑箱的内部构造。
因此,符号学派利用知识表示和搜索来替代真实人脑的神经网络结构。符号学派假设知识是先验地存储于黑箱之中的,因此,它非常擅长解决利用现有的知识做比較复杂的推理、规划、逻辑运算和推断等问题。
连接学派则显然要把智能系统的黑箱打开。从结构的角度来模拟智能系统的运作,而不单单重现功能。
这样。连接学派看待智能会比符号学派更加底层。
这样做的优点是能够非常好地解决机器学习的问题,并自己主动获取知识;可是弱点是对于知识的表述是隐含而晦涩的。由于全部学习到的知识都变成了连接权重的数值。我们若要读出神经网络中存储的知识,就必须要让这个网络运作起来,而无法直接从模型中读出。
连接学派擅长解决模式识别、聚类、联想等非结构化的问题,但却非常难解决高层次的智能问题(如机器定理证明)。
行为学派则研究更低级的智能行为,它更擅长模拟身体的运作机制。而不是脑。
同一时候,行为学派非常强调进化的作用,他们觉得,人类的智慧也理应是从漫长的进化过程中逐渐演变而来的。行为学派擅长解决适应性、学习、高速行为反应等问题。也能够解决一定的识别、聚类、联想等问题。但在高级智能行为(如问题求解、逻辑演算)上则相形见绌。
有意思的是,连接学派和行为学派似乎更加接近,由于他们都相信智能是自下而上涌现出来的,而非自上而下的设计。但麻烦在于。怎么涌现?涌现的机制是什么?这些深层次问题无法在两大学派内部解决。而必须求助于复杂系统科学。
三大学派分别从高、中、低三个层次来模拟智能,但现实中的智能系统显然是一个完整的总体。
我们应怎样调解、综合这三大学派的观点呢?这是一个未解决的开放问题,并且似乎非常难在短时间内解决。基本的原因在于,不管是在理论指导思想还是计算机模型等方面,三大学派都存在着太大的差异。
分裂与统一
于是,就这样磕磕碰碰地,人工智能走入了新的世纪。到了2000年前后。人工智能的发展非但没有解决这个问题,反而引入了一个又一个新的问题,这些问题似乎变得越来越难以回答。并且所牵扯的理论也越来越深。
于是。非常多人工智能研究者干脆当起了“鸵鸟”。对理论问题不闻不问,而是一心向“应用”看齐。争什么争呀,实践是检验真理的唯一标准。不管是符号、连接、行为。能够解决实际问题的鸟就是好鸟。
群龙无首
在这样一种大背景下。人工智能開始进一步分化。非常多原本隶属于人工智能的领域逐渐独立成为面向详细应用的新兴学科。我们简单罗列例如以下:
自己主动定理证明
模式识别
机器学习
自然语言理解
计算机视觉
自己主动程序设计
每个领域都包含大量详细的技术和专业知识以及特殊的应用背景。不同分支之间也差点儿是老死不相往来,大一统的人工智能之梦仿佛破灭了。于是,计算机视觉专家甚至不愿意承认自己搞的叫人工智能,由于他们觉得,人工智能已经成为了一个仅仅代表传统的符号学派观点的专有名词,大一统的人工智能概念没有不论什么意义。也没有存在的必要。这就是人工智能进入2000年之后的状况。
贝叶斯统计
可是,世界总是那么奇异。少数派总是存在的。当人工智能正面临着土崩瓦解的窘境时,仍然有少数科学家正在逆流而动,试图又一次构建统一的模式。
麻省理工学院的乔希•特南鲍姆(Josh Tenenbaum)以及斯坦福大学的达芙妮•科勒(Daphne Koller)就是这样的少数派。他们的特立独行起源于对概率这个有着几百年历史的数学概念的又一次认识。并利用这样的认识来统一人工智能的各个方面。包含学习、知识表示、推理以及决策。
这样的认识其实能够追溯到一位18世纪的古人,这就是著名的牧师、业余数学家:托马斯•贝叶斯(Thomas Bayes)。与传统的方法不同,贝叶斯将事件的概率视为一种主观的信念,而不是传统意义上的事件发生的频率。因此,概率是一种主观的測度。而非客观的度量。
故而,人们也将贝叶斯对概率的看法称为主观概率学派——这一观点更加明白地凸显出贝叶斯概率与传统概率统计的差别。
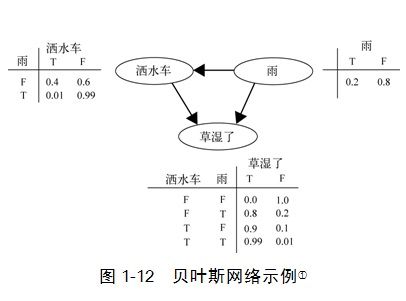
贝叶斯学派的核心就是著名的贝叶斯公式。它表达了智能主体怎样依据搜集到的信息改变对外在事物的看法。因此。贝叶斯公式概括了人们的学习过程。
以贝叶斯公式为基础。人们发展出了一整套称为贝叶斯网络(演示样例见图1-12)的方法。
在这个网络上,研究者能够展开对学习、知识表示和推理的各种人工智能的研究。
随着大数据时代的来临,贝叶斯方法所须要的数据也是唾手可得,这使得贝叶斯网络成为了人们关注的焦点。
图片来源:Wikipedia。
通用人工智能
另外一个尝试统一人工智能的学者是澳大利亚国立大学的马库斯•胡特(Marcus Hutter)。他在2000年的时候就開始尝试建立一个新的学科。并为这个新学科取了一个响当当的名字:通用人工智能(Universal Artificial Intelligence)。

胡特觉得。如今主流的人工智能研究已经严重偏离人工智能这个名称的本意。
我们不应该将智能化分成学习、认知、决策、推理等分立的不同側面。
其实,对于人类来说,全部这些功能都是智能作为一个总体的不同表现。因此,在人工智能中,我们应该始终保持清醒的头脑,将智能看作一个总体。而不是若干分离的子系统。
假设非要坚持统一性和广泛性。那么我们就不得不放弃理论上的有用性,这恰恰正是胡特的策略。
与通常的人工智能研究非常不同,胡特採用的是规范研究方法,即给出所谓的智能程序一个数学上的定义。然后运用严格的数理逻辑讨论它的性质。可是,理论上已证明。胡特定义的智能程序是数学上可构造的,但却是计算机不可计算的——不论什么计算机都无法模拟这样的智能程序——仅仅有上帝能计算出来。
不可计算的智能程序有什么用?相信读者会有这样的疑问。
实际上,假设在20世纪30年代,我们也会对图灵的研究发出相同的疑问。
由于那个时候计算机还没有发明呢,那么图灵机模型有什么用呢?这也仿佛是传说中英国女王对法拉第的诘难:“你研究的这些电磁理论有什么用呢?”法拉第则反问道:“那么。我尊敬的女王陛下,您觉得,您怀中抱着的婴儿有什么用呢?”
胡特的理论尽管还不能与图灵的研究相比,可是,它至少为统一人工智能开辟了新方向,让我们看到了统一的曙光。
我们仅仅有等待历史来揭晓终于的答案。很多其它关于通用人工智能的内容,请參见本书第5章。
梦醒何方(2010至今)
就这样,在争论声中。人工智能走进了21世纪的第二个十年,似乎一切都没有改变。可是。几件事情悄悄地发生了,它们又一次燃起了人们对于人工智能之梦的渴望。
深度学习
21世纪的第二个十年,假设要评选出最惹人注目的人工智能研究,那么一定要数深度学习(Deep Learning)了。
2011年,谷歌X实验室的研究人员从YouTube视频中抽取出1000万张静态图片,把它喂给“谷歌大脑”——一个採用了所谓深度学习技术的大型神经网络模型,在这些图片中寻找反复出现的模式。三天后。这台超级“大脑”在没有人类的帮助下,居然自己从这些图片中发现了“猫”。
2012年11月,微软在中国的一次活动中,展示了他们新研制的一个全自己主动的同声翻译系统——採用了深度学习技术的计算系统。
演讲者用英文演讲,这台机器能实时地完毕语音识别、机器翻译和中文的语音合成。也就是利用深度学习完毕了同声传译。
2013年1月,百度公司成立了百度研究院。当中,深度学习研究所是该研究院旗下的第一个研究所。
……
这些全球顶尖的计算机、互联网公司都不约而同地对深度学习表现出了极大的兴趣。那么到底什么是深度学习呢?
其实,深度学习仍然是一种神经网络模型,仅仅只是这样的神经网络具备了很多其它层次的隐含层节点,同一时候配备了更先进的学习技术。如图1-13所看到的。

然而。当我们将超大规模的训练数据喂给深度学习模型的时候。这些具备深层次结构的神经网络仿佛摇身一变,成为了拥有感知和学习能力的大脑。表现出了远远好于传统神经网络的学习和泛化的能力。
当我们追溯历史。深度学习神经网络其实早在20世纪80年代就出现了。
然而。当时的深度网络并没有表现出不论什么超凡能力。
这是由于。当时的数据资源远没有如今丰富。而深度学习网络恰恰须要大量的数据以提高它的训练实例数量。
到了2000年,当大多数科学家已经对深度学习失去兴趣的时候,又是那个杰夫•辛顿带领他的学生继续在这个冷门的领域里坚持耕耘。起初他们的研究并不顺利。但他们坚信他们的算法必将给世界带来惊奇。
惊奇终于出现了,到了2009年,辛顿小组获得了意外的成功。
他们的深度学习神经网络在语音识别应用中取得了重大的突破,转换精度已经突破了世界纪录,错误率比曾经降低了25%。能够说。辛顿小组的研究让语音识别领域缩短了至少10年的时间。就这样。他们的突破吸引了各大公司的注意。
苹果公司甚至把他们的研究成果应用到了Siri语音识别系统上,使得iPhone 5全球热卖。
从此,深度学习的流行便一发不可收拾。
那么。为什么把网络的深度提高。配合上大数据的训练就能使得网络性能有如此大的改善呢?答案是。由于人脑恰恰就是这样一种多层次的深度神经网络。比如,已有的证据表明。人脑处理视觉信息就是经过多层加工完毕的。所以,深度学习实际上仅仅只是是对大脑的一种模拟。
模式识别问题长久以来是人工智能发展的一个主要瓶颈。
然而。深度学习技术似乎已经突破了这个瓶颈。
有人甚至觉得。深度学习神经网络已经能够达到2岁小孩的识别能力。
有理由相信。深度学习会将人工智能引入全新的发展局面。本书第6章将详细介绍深度学习这一全新技术,第14章将介绍集智俱乐部下的一个研究小组对深度学习技术的应用——彩云天气,用人工智能提供精准的短时间天气预报。
模拟大脑
我们已经看到,深度学习模型成功的秘诀之中的一个就在于它模仿了人类大脑的深层体系结构。
那么,我们为什么不直接模拟人类的大脑呢?其实,科学家们已经行动起来了。
比如,德国海德尔堡大学的FACETS(Fast Analog Computing with Emergent Transient States)计划就是一个利用硬件来模拟大脑部分功能的项目。
他们採用数以千计的芯片。创造出一个包含10亿神经元和1013突触的回路的人工脑(其复杂程度相当于人类大脑的十分之中的一个)。与此对应。由瑞士洛桑理工学院和IBM公司联合发起的蓝色大脑计划则是通过软件来模拟人脑的实践。他们採用逆向project方法,计划2015年开发出一个虚拟的大脑。
然而,这类研究计划也有非常大的局限性。
当中最大的问题就在于:迄今为止,我们对大脑的结构以及动力学的认识还相当0基础,尤其是神经元活动与生物体行为之间的关系还远远没有建立。比如,尽管科学家早在30年前就已经弄清楚了秀丽隐杆线虫(Caenorhabditis elegans)302个神经元之间的连接方式,但到如今仍然不清楚这样的低等生物的生存行为(比如进食和交配)是怎样产生的。尽管科学家已经做过诸多尝试,比方连接组学(Connectomics),也就是全面监測神经元之间的联系(即突触)的学问,可是。正如线虫研究一样,这幅图谱仅仅是个開始,它还不足以解释不断变化的电信号是怎样产生特定认知过程的。
于是,为了进一步深入了解大脑的执行机制,一些“大科学”项目先后启动。2013年,美国奥巴马政府宣布了“脑计划”(Brain Research through Advancing Innovative Neurotechnologies,简称BRAIN)的启动。该计划在2014年的启动资金为1亿多美元,致力于开发能记录大群神经元甚至是整片脑区电活动的新技术。
无独有偶。欧盟也发起了“人类大脑计划”(The Human Brain Project),这一计划为期10年,将耗资16亿美元,致力于构建能真正模拟人脑的超级计算机。
除此之外。中国、日本、以色列也都有雄心勃勃的脑科学研究计划出炉。这似乎让人们想到了第二次世界大战后的情景,各国争相发展“大科学项目”:核武器、太空探索、计算机等。脑科学的时代已经来临。关于人脑与电脑的比較,请參见本书第7章。
“人工”人工智能

2007年,一位谷歌的实习生路易斯•冯•安(Luis von Ahn)开发了一款有趣的程序“ReCapture”,却无意间开创了一个新的人工智能研究方向:人类计算。
ReCapture的初衷非常easy,它希望利用人类高超的模式识别能力,自己主动帮助谷歌公司完毕大量扫描图书的文字识别任务。可是,假设要雇用人力来完毕这个任务则须要花费一大笔开销。于是,冯•安想到,每天都有大量的用户在输入验证码来向机器证明自己是人而不是机器。而输入验证码其实就是在完毕文本识别问题。于是,一方面是有大量的扫描的图书中难以识别的文字须要人来识别;还有一方面是由计算机生成一些扭曲的图片让大量的用户做识别以表明自己的身份。
那么,为什么不把两个方面结合在一起呢?这就是ReCapture的创意(如图1-14所看到的),冯•安聪明地让用户在输入识别码的时候悄悄帮助谷歌完毕了文字识别工作!

这一成功的应用实际上是借助人力完毕了传统的人工智能问题。冯•安把它叫作人类计算(Human Computation),我们则把它形象地称为“人工”人工智能。
除了ReCapture以外,冯•安还开发了非常多相似的程序或系统。比如ESP游戏是让用户通过竞争的方式为图片贴标签,从而完毕“人工”人工分类图片;Duolingo系统则是让用户在学习外语的同一时候,顺便翻译一下互联网。这是“人工”机器翻译。
或许。这样巧妙的人机结合才是人工智能发展的新方向之中的一个。
由于一个全然脱离人类的人工智能程序对于我们没有不论什么独立存在的意义,所以人工智能必定会面临人机交互的问题。
而随着互联网的兴起,人和计算机交互的方式会更加便捷而多样化。因此,这为传统的人工智能问题提供了全新的解决途径。
然而,读者或许会质疑,这样的掺合了人类智能的系统还能叫作纯粹的人工智能吗?这样的质疑其实有一个隐含的前提,就是人工智能是一个独立运作的系统,它与人类环境应相互隔离。但当我们考虑人类智能的时候就会发现,不论什么智能系统都不能与环境绝对隔离,它仅仅有在开放的环境下才干表现出智能。相同的道理。人工智能也必须向人类开放,于是引入人的作用也变成了一种非常自然的事情。关于这个主题,我们将在本书第8章和第9章中进一步讨论。
结语
本章介绍了人工智能近60年所走过的曲折道路。或许,读者所期待的内容,诸如奇点临近、超级智能机器人、人与机器的共生演化等激动人心的内容并没有出现,可是,我能保证的,是一段真实的历史。并力图做到准确无误。
尽管人工智能这条道路蜿蜒曲折,荆棘密布,但至少它在发展并不断壮大。最重要的是,人们对于人工智能的梦想永远没有破灭过。
或许人工智能之梦将无法在你我的有生之年实现。或许人工智能之梦始终无法逾越哥德尔定理那个硕大无朋的“如来佛手掌”,可是。人工智能之梦将永远驱动着我们不断前行。挑战极限。
推荐阅读
关于希尔伯特、图灵、哥德尔的故事和相关研究能够阅读《哥德尔、艾舍尔、巴赫:集异璧之大成》一书。关于冯•诺依曼。能够阅读他的传记:《天才的拓荒者:冯•诺依曼传》。关于维纳,能够參考他的著作《控制论》。
若要全面了解人工智能,给大家推荐两本书:Artificial Intelligence: A Modern Approach和Artificial Intelligence: Structures and Strategies for Complex Problem Solving。了解机器学习以及人工神经网络能够參考Pattern Recognition和Neural Networks and Learning Machines。
关于行为学派和人工生命。能够參考《数字创世纪:人工生命的新科学》以及人工生命的论文集。若要深入了解贝叶斯网络,能够參考Causality: Models, Reasoning, and Inference。深入了解胡特的通用人工智能理论能够阅读Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability。关于深度学习方面的知识可參考站点:http://deeplearning.net/reading-list/。当中有不少综述性的文章。
人类计算方面能够參考冯•安的站点:http://www.cs.cmu.edu/~biglou/。
參考文献
1 候世达,严勇。刘皓. 哥德尔、艾舍尔、巴赫:集异璧之大成. 莫大伟 译. 北京:商务印书馆。1997.
2 诺曼•麦克雷. 天才的拓荒者:冯•诺伊曼传. 范秀华,朱朝辉 译. 上海:上海科技教育出版社,2008.
3 维纳. 控制论:或关于在动物和机器中控制和通信的科学. 郝季仁 译. 北京:北京大学出版社,2007.
4 Luger G F. Artificial intelligence: structures and strategies for complex problem solving (6th Edition). Addison-Wesley, 2008.
5 Russel S K, Norvig P. Artificial Intelligence: A Modern Approach (2nd Edition). Prentice Hall, 2002.
6 Theodoridis S, Koutroumbas K. Pattern Recognition (2nd edition). Academic Press, 2008.
7 Haykin S O. Neural Networks and Learning Machines (3rd Edition). Prentice Hall, 2000.
8 李建会,张江. 数字创世纪:人工生命的新科学. 北京:科学出版社,2006.
9 Pearl J. Causality: models, reasoning, and inference. Cambridge University Press, 2000.
10 Hutter M. Universal Artificial Intelligence:Sequential Decisions based on Algorithmic Probability. Springer, 2005.
本文摘自《科学的极致:漫谈人工智能》