经典案例复盘——运维专家讲述如何实现K8S落地\n
背景介绍
运满满自开始微服务改造以来,线上线下已有数千个微服务的Java实例在运行中。这些Java实例部署在数百台云服务器或虚机上,除少数访问量较高的关键应用外,大部分实例均混合部署。
这些实例的管理,采用自研平台结合开源软件的方式,已实现通过平台页面按钮菜单执行打包、部署、启动、停止以及回滚指定的版本等基本功能,取得了不错的效果。但仍然存在如下几个痛点:
- 实例间资源隔离,尤其在高峰期或故障期间,单服务器上不同实例间CPU和内存资源的争抢特别明显。
- 线上某个应用实例异常时需要人工干预,导致较长的故障时间。
- 大批服务端应用新版上线后,如网站关键功能故障,需要针对每个应用,选择对应的版本,执行回滚操作,整个过程耗时较长。
- 线下DEV/QA环境频繁发布,每次发布都需要先停止老的版本再发布新的版本,会影响到日常测试。
运满满飞速发展的业务,对系统稳定性的要求越来越高,我们急需解决如上问题。
技术调研、选型
最初吸引我们的是容器技术良好的隔离和水平扩展等特性,而Docker的口碑以及几年前参与的一些Docker项目经验,使得采用Docker容器技术成了我们的不二选择。
但我们仍然需要一套容器编排系统,来实现自动化管理Docker容器,大致了解下来有3个选项:Kubetnetes(K8S)、swarm、mesos
这3个我们都不熟悉,而这个项目的节奏很紧迫,不允许我们对这3个系统深入了解后再做选择。好在Github有一个统计功能,我们在Github上查到了这3个开源项目的一些基本情况,如下图:
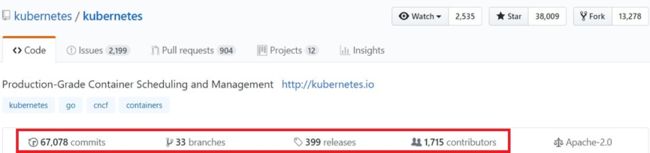


根据这份统计数据,以及拥有Google公司的光环,我们在很短的时间内确定了使用K8S作为容器编排管理系统。K8S,这个开源项目号称可以自动部署、扩展和管理容器应用,并且能解决如下核心问题:
负载均衡 - 一个应用运行多个同样的容器,内部Service提供了统一的访问定义,以负载均衡的方式来提供访问。
服务发现 - Service和Kube-DNS结合,只需要通过固定的Service名称就可以访问到对应的容器,不需要独立寻找使用服务发现组件。
高可用 - K8S会检查服务的健康状态,发现异常时会自动尝试重新启动服务,保障正常运行。
滚动升级 - 在升级过程中K8S会有规划的挨个容器滚动升级,把升级带来的影响降低到最小。
自动伸缩 - 可以配置策略当容器资源使用较高会自动增加新的容器来分担压力,当资源使用率降低会回收容器。
快速部署 - 编写好对应的编排脚本,可以在极短的时间部署一套环境。
资源限制 - 对程序限制最大资源使用量避免抢占资源遇到事故或压力也能从容保障基础服务不受影响。
进一步深入了解K8S之后,我们大致确定了会用到如下组件、相关技术和系统:
- 应用部署 K8S Deployment,HPA;
- 少量基础服务 K8S Daemonset, kube-dns;
- 对外服务暴露 K8S Ingress, Traefik, Service;
- 网络插件 Flannel;
- 监控告警 Heapster, InfluxDB, Grafana, Prometheus;
- 管理界面 Kubectl, Dashboard, 自研发布管理系统;
- 制作镜像 Jenkins, Maven, Docker;
- 镜像仓库 Harbor;
- 日志收集 Filebeat, Kafka, ELK。
难点和基本原则
- 线上服务必须在不间断提供服务的情况下迁移,每个应用按比例切分流量,在确保稳定性的前提下迁移到K8S集群中。
- DEV环境可批量上线,QA和Production环境上线需要考虑各应用的版本依赖关系。
- 初期只上无状态的应用。
- 对研发/QA的影响最小化(尽量不给繁忙的研发/QA同学增加工作量)。
落地过程剖析
Docker化前后应用发布流程对比
从下图中可以看到2个明显的变化:
- 之前部署的是war包、jar包,之后部署的是Docker镜像(镜像中包含war包、jar包)。
- 之前是先停止再启动应用进程,发布过程中服务会中断,之后是先启动新版本容器,再停止旧版本容器,发布过程中应用一直在提供服务。

迁移中的系统架构
当前业务应用主要分为2种,仅供内部应用调用的RPC服务(Pigeon框架)和对外提供服务的REST API,REST API可进一步细分为2种,已接入API网关和未接入API网关。其中RPC服务和已接入API网关的应用均有自己的注册中心,迁移步骤相对简单,在K8S集群中启动对应的应用即可。未接入API网关的应用采用K8S Ingress插件提供对外服务入口,需要一些配置。系统架构如下图,最终目标是要实现将图中下方的两个框内的应用全部迁入K8S集群中。

Master集群的高可用
由于公有云的限制,我们主要结合服务商提供的SLB来实现,示意图如下:

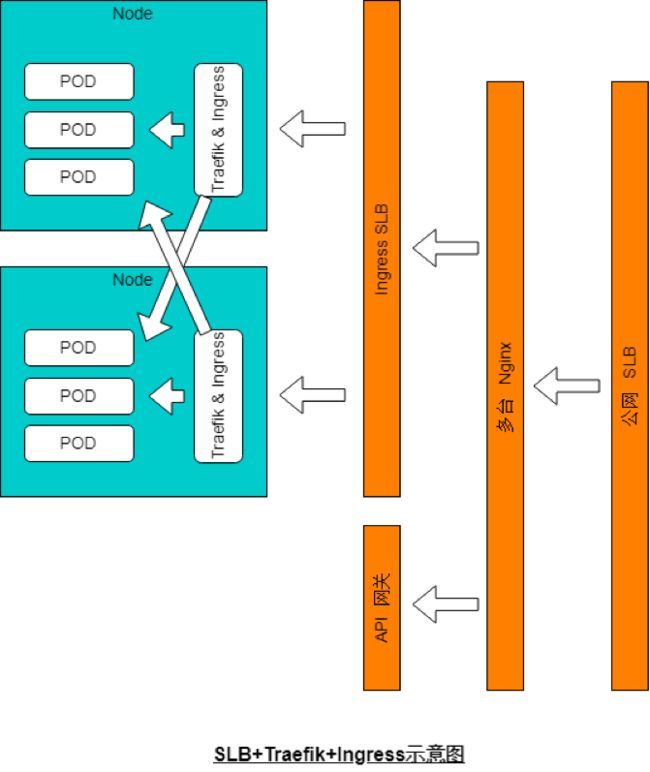
K8S集群内应用对外提供服务
由于集群内POD的IP地址动态变化,我们采用 Traefik+Ingress+Nginx+SLB 的方式,来提供一个对外服务的统一入口。Traefik根据HTTP请求的域名和路径路由到不同的应用服务,Nginx则执行一些复杂的诸如rewrite等操作,SLB提供高可用。架构示意图如下:
容器内应用初始化
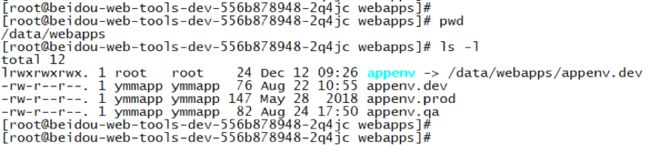
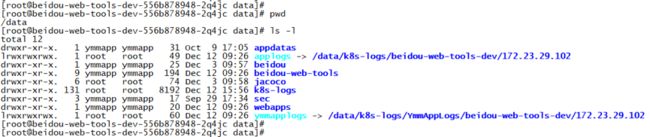
为了实现同一个镜像可以兼容运行在DEV、QA、Production等各种环境,必须编写一个初始化脚本,该脚本被存放在镜像中。当容器启动时,从Env变量中读取当前所在的环境,并创建一系列软链到各环境对应的配置文件以及设置日志目录等其他初始化操作,随后fork一个新进程用于检测和设置该容器内应用是否已完成正常启动(配合容器 readiness 探针使用),同时调用应用启动脚本。
下图为容器内通过软链指向不同的环境配置文件:
下图为容器内通过软链设置日志目录:
K8S 日志收集
当前应用日志均以文件形式存放,且单个实例对应多个日志文件,无法采用K8S官方推荐的日志方案。同时由于容器的无状态化,我们必须另想其他办法保存日志。目前采用的是将Node上的固定目录作为存储卷挂载到容器内,在容器启动时通过初始化脚本按照应用名+容器IP生成该容器特定的日志路径。为了便于查看日志,我们提供3种途径:
- 容器内启用SSH服务端,发布管理系统中实现WEBSSH,正常情况下可通过WEB页面进入容器命令行查看日志,由于其便利性,推荐首选此方式。
- 有些情况下容器会启动失败,此时无法进入命令行,可在发布管理系统中找到日志的链接地址,下载到本机后再查看。
- 此外,我们在所有Node上各运行一个Filebeat容器,将Node上收集到的日志实时发送到Kafka集群中,经过处理后存储到ES集群,以便日后检索。
下图为Node服务器上的日志目录结构:

下图为Node服务器上共享的日志下载路径:
K8S 监控
采用 Heapster+InfluxDB+Grafana 组合,需要注意的是其中InfluxDB用于存放监控数据,需要将数据持久化。在Grafana上制作了不同维度的dashboard,可根据Namespace、Node、应用名进行检索,可按照CPU、内存、网络带宽、硬盘使用量筛选应用,方便故障排查和日常优化。(当然,更好的监控系统是Prometheus,已经在上线的路上。)
下图为监控大盘:
下图为监控菜单:
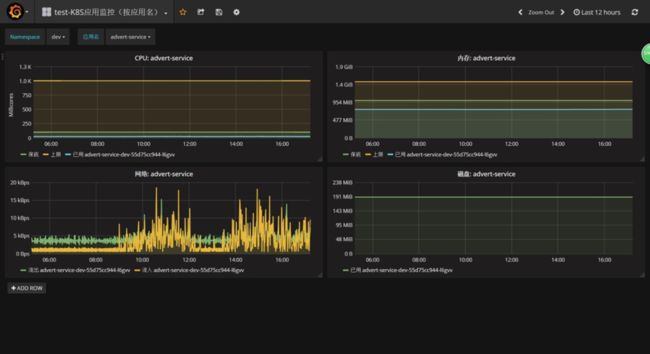
下图为某应用的监控图:
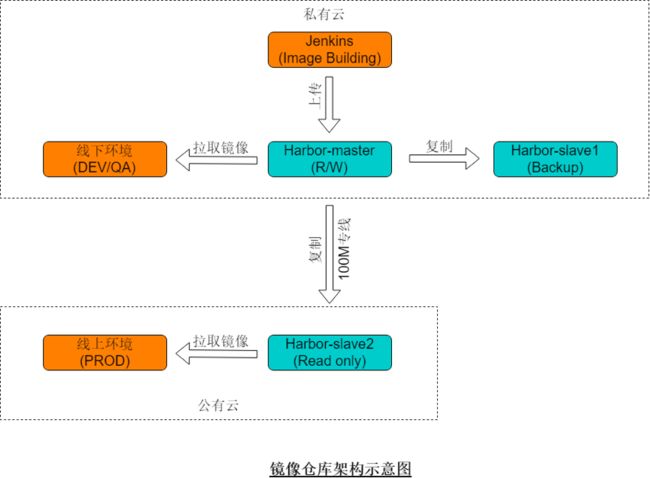
Harbor镜像仓库
Harbor我们目前采用的是一主多从结构,主库与打包Jenkins都在线下网络中,镜像上传到主库后会被自动同步到线下另一个从库以及线上的从库中,如下图所示:
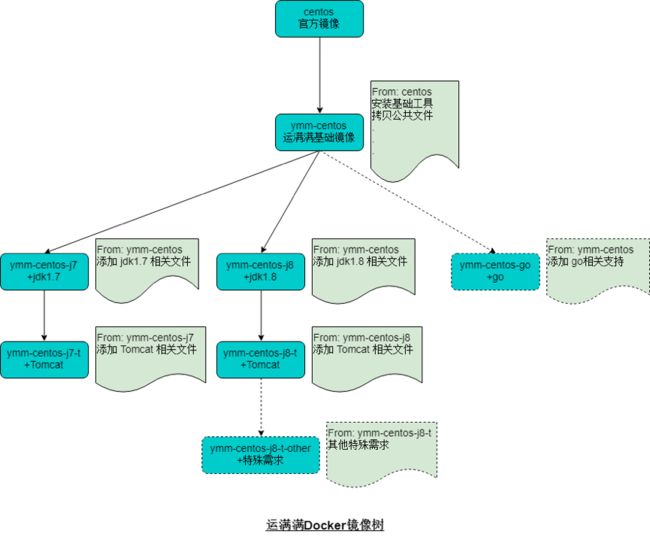
镜像树
我们的规划是构建一颗镜像树,所有的应用都基于这颗树上的基础镜像来构建应用镜像,各应用构建时选择最相似的基础镜像,再增加应用的特殊需求即可。基于此镜像树,我们95%以上的应用均无需在Gitlab里放置Dockerfile,Dockerfile在打包时根据变量自动生成即可,例如:
下图为脚本自动生成的某应用Dockerfile:

镜像树结构示意图如下:
当前状态
容器化:DEV/QA环境的应用已完成Docker化,产品环境中应用约98%已完成Docker化。
系统自愈:应用OOM或其他Crash时,系统能够自动拉起新的节点以替换故障节点,高级健康检查暂未开启(需其他方面配合)。
弹性伸缩:关键应用全部开启弹性伸缩,访问量高峰期观察到的效果很好。
滚动发布:可按指定的比例分批次部署更新应用版本,先更新一批,成功后销毁一批,依次滚动。
快速回滚:当前仅支持单应用快速回滚,后期如需要增加事务级回滚能力,采用K8S的rollout功能可以方便实现。
一些踩过的坑和建议
- 底层操作系统采用CentOS7.x版本,会比较省事。
- 阿里云经典网络中的ECS无法访问容器IP,需要先迁移到VPC环境,其他公有云情况类似,重点是能自主添加路由。
- 如果有应用级监控的话,从容器内部采集到的Memory,Load Average等信息是底层操作系统的,而不是容器的,这些指标可以依赖专门的容器监控系统。
- 要注意ulimit的限制,容器中并没有对它进行隔离,设置过小的话会遇到一些莫名其妙的问题。
- 容器中的root用户用netstat命令可能看不到其他用户所创建的进程的owner,如果有一些老式的脚本可能会遇到类似问题。
- 如果有一些内部系统需要直接访问容器的特定端口,headless service挺好用。
- Zookeeper有一个单IP连接数60的默认限制,如果没修改过该参数的话应用迁移到K8S之后可能会遇到此问题。
- 产品环境中的某个访问量大的应用往K8S迁移时,可以先分配较多数量的容器,确保能吃下所有流量,之后再根据监控,用弹性伸缩功能来减掉多余的容器。
- 如果想提前知道K8S集群的性能,部署好应用之后做一次压测很有必要。
作者简介
王春林,就职于运满满技术保障部,关注容器、DevOPS等领域。