微服务线上问题排查困难?不知道问题出在哪一环?那是你还不会分布式链路追踪
咱们以前单体应用里面有很多的应用和功能,依赖各个功能之间相互调用,使用公共的代码包等等,排查问题,使用类似于 gdb/dlv 工具或者直接查看代码日志,进行定位和分析
但是现在我们基本上都是微服务架构了,将以前的单体架构拆成了一个个独立的微服务,现在就变成了多个微服务之间的相互调用的关系
在一个业务链条中,中间可能涉及到几个,十几个甚至几十个微服务的交互和配合,如果中间某一环出现了问题,那么我们是很难排查的,排查问题耗时耗力,且效率极其低下
服务数量多,链路复杂,排查困难,大佬们就想出了一个办法,使用分布式链路追踪来处理这个问题
本文分别从以下几个方面来聊聊关于分布式链路追踪的技术知识:
- 什么是分布式链路追踪
- 分布式链路追踪的基础原理
- 目前常用的分布式链路追踪组件
- Jaeger 的基本架构和使用演示
✔什么是分布式链路追踪
分布式链路追踪,见名知意,这是用在分布式系统中,用于追踪服务调用链路的
文章开头有说到,微服务架构中,存在大量的微服务,且维护的团队不尽相同,使用的语言也不太一致
线上部署几百上千台服务器,若链路出现了问题,性能出现了瓶颈,我们如何排查, 如何有效的解决呢?
分布式链路追踪他就可以将一次分布式请求还原成调用链路,将一次分布式请求的调用状况集中展示,且他还提供友好的 UI 界面,咱们直接在页面上就能直观的看到每一个服务的耗时请求到具体哪台服务器上以及服务相应的状态等等。
在技术上通常使用
- Tracing 表示链路追踪
主要是用于单个请求的处理流程,包括服务调用和服务处理时长等信息
目前分布式上使用的比较多的是 Jaeger
- Logging 日志记录
主要是用来记录离散的日志事件。可以理解为你程序打印出来的一些日志
对于日志记录,我们一般会使用 ELK ,这是 elastic 公司提供的一套解决方案,其中每一个字母代表一个开源组件
E: Elasticsearch
L: Logstash
K:Kibana
- Metrics 数据聚合
用于聚合数据的,通常是有时间顺序的数据
对于数据聚合和统计系统,我们一般使用 Prometheus 普罗米修斯来进行处理
可以看到上述这三个概念是相辅相成的,仅仅只使用一种方式,是没有办法完全满足我们需求的,在实际生产过程中,会将上述进行两两组合来达到我们期望的效果。
Tracing 与 Logging 组合
既有链路追踪又有日志
那么我们就可以达到的效果是在我们每一个请求阶段,可以看到详细的标签数据对应的日志数据以及错误原因
Tracing 与 Metrics 组合
既有链路追踪,又有数据统计
那我们就可以去做单个请求中的可计量数据,比如说,我们的接口调用次数以及调用时长等等
Logging 与 Metrics 组合
既有日志数据又有数据统计
咱们就可以去做数据聚合事件,去统计某一段时间某一类接口的请求总数,报错次数,成功率等等。
✔分布式链路追踪的基础原理
那知道上述的一些应用场景之后,是否会对分布式链路追踪的技术原理有那么一点兴趣了呢?那么我们开始吧。
无论分布式链路追踪组件有多少,他们都有三个核心的步骤。
- 代码 埋点
- 数据存储
- 查询展示
市面上那么多链路,追踪主线那么自然,是要遵循一个统一的规范的这个规范,就是 OpenTracing
OpenTracing 可以理解为就是一个标准化的库,它位于应用程序和链路追踪程序之间,它解决了分布式追踪 API 不兼容的问题,我们可以理解为是这样的。
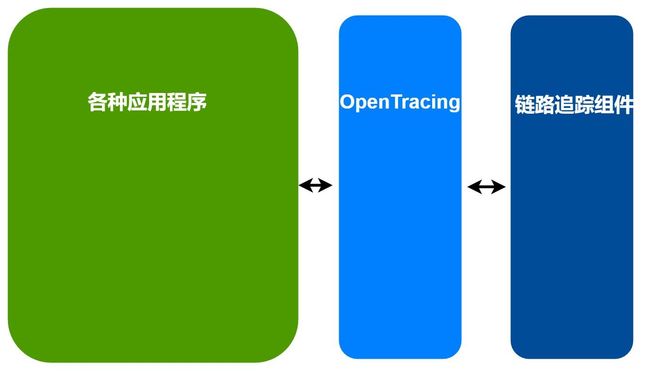
无论哪一种链路追踪组件一定会有如下这样的做法
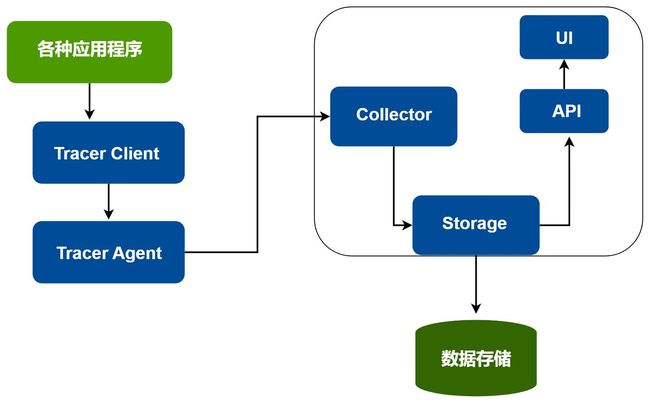
通过上图就可以看到
- 需要在应用程序中做埋点,数据上报到对应的链路追踪组件的收集器上,并对数据存储
- 另外一条路便是前端 UI 来查询数据进行展示
✔链路追踪如何实现?
架构基本上也知道了,那么它具体的实现细节是什么样的呢?
链路追踪中一条链路也就可以理解为是一个 Trace 树,一个树上面有多个 Span 基本单元
Span 基本单元有自己的唯一标识,通常是 UUID,还有其他的一些信息,例如时间戳,键值对,ParentID 以及当前的 SpanID 等等信息。
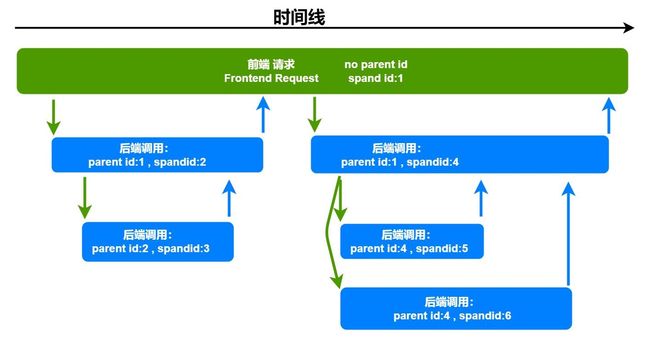
可以看到整个链路,其实就是一个有向无环图。
- 我们可以看到一条调用链的第1 个 Span ,它的 ParentID是空的,这一个 Span 就被称为RootSpan
- 那其他的 Span 自身的 ParentID 就是上一个 SpanID,自己的 SpanID 就是下一个 Span 的 ParentID
✔目前常用的分布式链路追踪组件
目前常用的分布式链路追踪组件有这些
- Twitter Zpikin
- Jaeger
- SkyWalking
- Pinpoint
其中 Twitter Zpikin 的架构和实现相对简单,Jaeger 也是借鉴了google 的 Dapper 论文和 OpenZipkin 的启发
接下来的两个并没有提供 golang 版本的库,因此就不过多赘述了,接下来主要着重介绍的是
- Jaeger
✔Jaeger 的基本架构
Jaeger Uber 开源的分布式链路追踪系统,它用于微服务的监控和排查,并且支持分布式上下文传播和分布式事务的监控,报错分析,服务的调用网络分析,和性能/延迟优化
它的服务端的代码就是 GO 语言实现的,自然也提供了 GO 语言版本的客户端代码库
github.com/uber/jaeger-client-go
Jaeger 的基本架构图是这样的
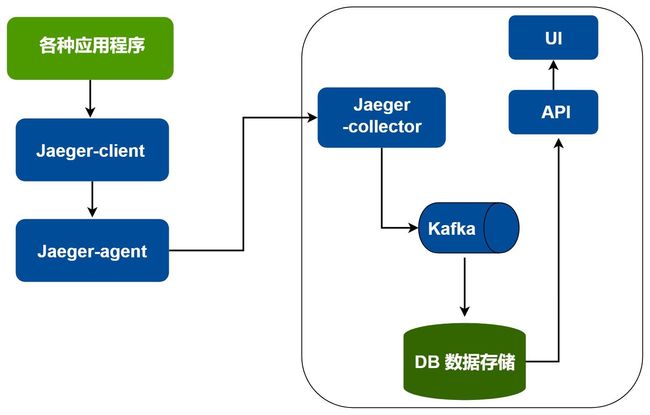
可以看到 Jaeger 的架构图与上述 OpenTracing 的规范大同小异,只不过自身服务端处理的有一些变动,整体方向上按照规范来的
Jaeger 是支持多个存储后端,且原生支持 OpenTracing 规范,拥有可视化友好的UI界面,支持云原生部署,且还能兼容 Zipkin 格式的请求
官方文档上也可以看到关于支持的存储后端有这些:

✔Jaeger 使用
- 现在自己的虚拟机上面装一个 Jaeger 的服务端,官方有提供一键 docker 运行的版本,叫做 All-in-One ,这个仅仅是用来实验,如果是要放在正式环境,请参考官方文档进行环境部署
https://www.jaegertracing.io/docs/1.12/deployment/
$ docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/all-in-one:1.12
安装完毕之后,我们直接访问 Jaeger 的前端即可,前端暴露的端口是 16686 , http://localhost:16686
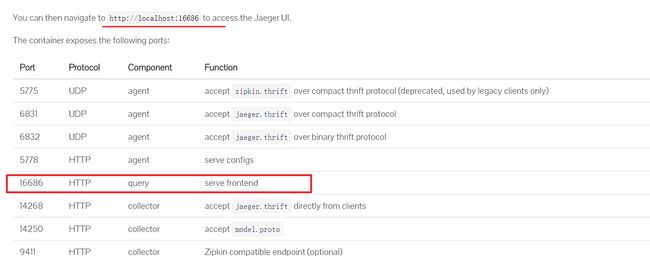
Jaeger demo
咱们简单写一个 Jaeger 的例子,仅仅是在一个应用中,模拟 test1 -> testtest1-1 的一个链路
package main
import (
"log"
"time"
jaegerCfg "github.com/uber/jaeger-client-go/config"
"github.com/opentracing/opentracing-go"
"github.com/uber/jaeger-client-go"
"context"
)
func main() {
// 初始 log 日志
log.SetFlags(log.LstdFlags | log.Lshortfile)
// 配置 Jaeger
cfg := jaegerCfg.Configuration{
Sampler: &jaegerCfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegerCfg.ReporterConfig{
LogSpans: true,
LocalAgentHostPort: "127.0.0.1:6831",
},
}
// 创建一个全局的 Jaeger tracer
closer, err := cfg.InitGlobalTracer(
"testSvr",
)
if err != nil {
log.Printf("InitGlobalTracer error: %s", err.Error())
return
}
var ctx = context.TODO()
span1, ctx := opentracing.StartSpanFromContext(ctx, "test1")
// 模拟业务处理
time.Sleep(time.Second)
span11, _ := opentracing.StartSpanFromContext(ctx, "test1-1")
// 模拟业务处理
time.Sleep(time.Second)
span11.Finish()
span1.Finish()
defer closer.Close()
}
通过程序代码,我们可以知道
- 是给 Jaeger 的 6831 这个端口发送 ****Udp 包
- Jaeger 是 opentracing.StartSpanFromContext ,在上下文上传入我们当前的 operationName 来进行处理的,效果可以见后续的图
运行代码的时候,如果你的环境里面不是 golang 1.18 的话,则会出现这样的报错,此时需要先卸载当前环境中的 golang,再去安装新版本的 golang

如果不是先卸载,再安装,那么会出现一些库报错的问题,例如这样

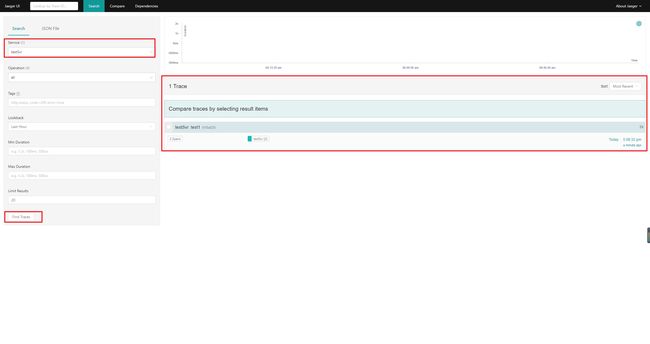
环境 ok 之后,我们直接访问环境地址+上16686端口就可以看到如下页面
- 选择 Service 为 testSvr
- 查看具体的 Trace
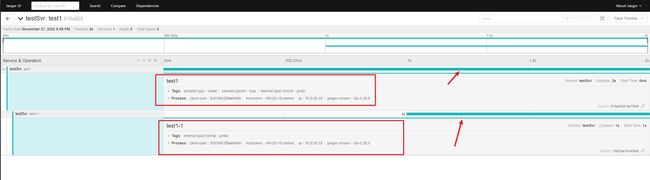
此处可以看到调用关系为 test1 调用了 test1-1,其中 test1 自身处理事项耗时 1s,等待 test1-1 处理事项 1s,因此整个链路耗时 2s
对于链路追踪,咱们需要知道的是原理,知道原理之后,编码都是很简单的事情,上述仅是一个简单的 demo,主要是展示如何去使用这个链路追踪组件
实际业务中,我们会对微服务之间的交互进行链路追踪,并且会从前端请求进来就会开始记录
这个时候,我们涉及到 http 中的代码 埋点,grpc 中的代码埋点,自然 Jaeger 都是有相应的中间件和拦截器来进行使用的,实际上都是对 ctx 上下文上面做文章,这里就不过多赘述了,将 Jaeger 的代码下载到本地,稍微阅读一下就可以知道了
使用链路追踪,我们就可以很清晰的看到一条完整的调用链,每一个环节耗时多少,整体来看性能的瓶颈在哪里就可以做到一清二楚,先用起来了吧,看看源码
会使用到这些库
"github.com/grpc-ecosystem/go-grpc-middleware/tracing/opentracing"
"github.com/uber/jaeger-client-go/config"
"github.com/opentracing/opentracing-go"
"github.com/uber/jaeger-client-go"
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
文中提到的技术点,感兴趣的可以查看这些文章:
- 瞧一瞧 gRPC的拦截器
- 最常用的限流算法以及如何在http中间件中加入流控
- 都在还说链路跟踪,那么 go-zero 的链路跟踪是咋样的
- k8s 服务升级为啥 pod 会部署到我们不期望的节点上??看来你还不懂污点和容忍度
- 【LFU】一文让你弄清 Redis LFU 页面置换算法
- 【LRU】一文让你弄清 Redis LRU 页面置换算法
可以进入地址进行体验和学习:https://xxetb.xet.tech/s/3lucCI