C++面经
1. 语言基础
1.1 C++的四种类型转换:
const_cast=> 用于将const变量转为非const;static_cast=> 用于各种隐式转换,比如非const转const,void*转指针等, static_cast能用于多态向上转化,如果向下转能成功但是不安全,结果未知;dynamic_cast=> 用于动态类型转换( 适用于包含虚函数的类 ) ,适用于指针和引用;reinterpret_cast=> 几乎什么都可以转,比如将int转指针,可能会出问题,尽量少用;- 为什么不用 C 风格的强制类型转换 => C的强制转换表面上看起来功能强大什么都能转,但是转化不够明确,不能进行错误检查,容易出错。
1.2 海伦公式求三角形面积:
已知三角形三边a, b, c
p = a + b + c 2 p = \frac{a + b + c}{2} p=2a+b+c
S = p ( p − a ) ( p − b ) ( p − c ) S = \sqrt{p(p - a)(p-b)(p-c)} S=p(p−a)(p−b)(p−c)
1.3 四种智能指针
auto_ptr(c++98的方案,cpp11已经抛弃) => 采用所有权模式;( 所有权可剥夺 )unique_ptr=> 用于替换auto_ptr=> 占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象shared_ptr=> 引用计数解决方案weak_ptr=> 一种弱引用,不会增加对象的引用计数( 解决 shared_ptr 相互引用问题 )
1.4 fork
- 写时复制;
- 子进程中返回大于0的pid_t,父进程中返回0;
1.5 静态函数和虚函数:
- 静态函数在编译时就确定调用时机;
- 虚函数在运行时动态绑定,因为采用了虚函数表,所以在调用时会增加内存开销。
1.6 const
- 对于局部对象,常量存放在栈区,对于全局对象,常量存放在全局/静态存储区,对于字面值常量,常量存放在常量存储区;
- const 可用于函数重载
- 指向常量的指针,和常量指针:
const char *p1=> p1 可以改变指向,但是不能修改所指的对象char *const p2=> p2 本身是一个常量指针,不可以改变指向
1.7 malloc 和 new
malloc/free是C语言的库函数,需指明申请的空间大小 => 对于类类型,不会调用构造和析构函数;new/delete是C++的关键字,会调用构造和析构函数
1.8 C++ 引用、移动、转发
https://guodong.plus/2020/0307-190855/
2. 数据结构
2.1 红黑树
https://www.jianshu.com/p/e136ec79235c
2.2 map和set底层都是用红黑树(RB-tree)实现的;
unordered map 底层用的是 Hash 表
2.3 STL迭代器删除元素:
-
对于序列容器vector,deque来说,使用erase(itertor)后,后边的每个元素的迭代器都会失效,但是后边每个元素都会往前移动一个位置,但是 erase会返回下一个有效的迭代器 ;
-
对于关联容器map set来说,使用了erase(iterator)后,当前元素的迭代器失效,但是其结构是红黑树,删除当前元素的,不会影响到下一个元素的迭代器,所以在 调用erase之前,记录下一个元素的迭代器即可 ;
-
对于list来说,它使用了不连续分配的内存,并且它的erase方法也会返回下一个有效的iterator,因此上面两种正确的方法都可以使用。
3. 操作系统
3.1 I/O模式
https://segmentfault.com/a/1190000003063859
-
阻塞I/O(blocking IO)

-
非阻塞I/O(nonblocking IO)
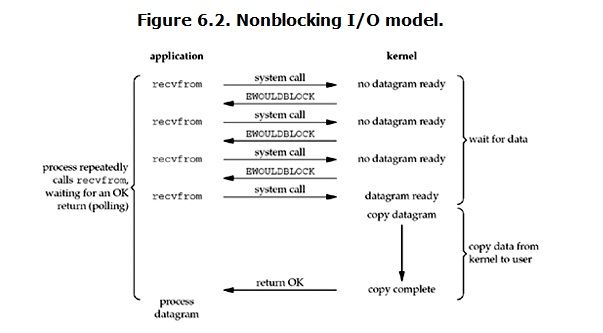
-
I/O多路复用(IO multiplexing)

-
信号驱动I/O(signal driven IO)=> 不常用
-
异步I/O(asynchronous IO)

3.2 blocking和non-blocking的区别
调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
3.3 synchronous IO和asynchronous IO的区别
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。

3.4 I/O多路复用 => select、poll、epoll
-
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); -
poll
struct pollfd { int fd; /* file descriptor */ short events; /* requested events to watch */ short revents; /* returned events witnessed */ }; int poll (struct pollfd *fds, unsigned int nfds, int timeout); -
epoll
https://zhuanlan.zhihu.com/p/63179839
=> epoll 采用红黑树和双向链表实现
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
3.5 进程间通信方式
-
管道通信 => 半双工
- 匿名管道 => 只能用于有亲缘关系的进程之间;
- 命名管道 => 允许没有亲缘关系的的进程之间进行半双工的管道通信。
-
消息队列:
消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
信号量通信:
信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
-
信号:
信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
-
共享内存:
共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
-
套接字
3.6 虚拟地址空间
为了防止不同进程同一时刻在物理内存中运行而对物理内存的争夺和践踏,采用了虚拟内存。
虚拟内存技术使得不同进程在运行过程中,它所看到的是自己独自占有了当前系统的4G内存。所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。 事实上,在每个进程创建加载时,内核只是为进程“创建”了虚拟内存的布局,具体就是初始化进程控制表中内存相关的链表,实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射),等到运行到对应的程序时,才会通过缺页异常,来拷贝数据。还有进程运行过程中,要动态分配内存,比如malloc时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
请求分页系统、请求分段系统和请求段页式系统都是针对虚拟内存的,通过请求实现内存与外存的信息置换。
-
虚拟内存的好处:
-
扩大地址空间;
-
内存保护:每个进程运行在各自的虚拟内存地址空间,互相不能干扰对方。虚存还对特定的内存地址提供写保护,可以防止代码或数据被恶意篡改。
-
公平内存分配。采用了虚存之后,每个进程都相当于有同样大小的虚存空间。
-
当进程通信时,可采用虚存共享的方式实现。
-
当不同的进程使用同样的代码时,比如库文件中的代码,物理内存中可以只存储一份这样的代码,不同的进程只需要把自己的虚拟内存映射过去就可以了,节省内存
-
虚拟内存很适合在多道程序设计系统中使用,许多程序的片段同时保存在内存中。当一个程序等待它的一部分读入内存时,可以把CPU交给另一个进程使用。在内存中可以保留多个进程,系统并发度提高
-
在程序需要分配连续的内存空间的时候,只需要在虚拟内存空间分配连续空间,而不需要实际物理内存的连续空间,可以利用碎片
-
-
虚拟内存的代价:
-
虚存的管理需要建立很多数据结构,这些数据结构要占用额外的内存
-
虚拟地址到物理地址的转换,增加了指令的执行时间。
-
页面的换入换出需要磁盘I/O,这是很耗时的
-
如果一页中只有一部分数据,会浪费内存。
-
3.7 操作系统中程序的内存结构

-
text段(代码段):存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域属于只读。在代码段中,也有可能包含一些只读的常数变量;
-
data段(数据段):存放程序中已初始化的全局变量的一块内存区域。数据段也属于静态内存分配;
- 已初始化数据区;
- BBS(未初始化区)=> 的内容并不存放在磁盘上的程序文件中。其原因是内核在程序开始运行前将它们设置为0。需要存放在程序文件中的只有正文段和初始化数据段
-
栈区(运行时):
由编译器自动释放,存放函数的参数值、局部变量等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存放到栈中。然后这个被调用的函数再为他的自动变量和临时变量在栈上分配空间。每调用一个函数一个新的栈就会被使用。栈区是从高地址位向低地址位增长的,是一块连续的内存区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小
-
堆区(运行时):
用于动态分配内存,位于BSS和栈中间的地址区域。由程序员申请分配和释放。堆是从低地址位向高地址位增长,采用链式存储结构。频繁的malloc/free造成内存空间的不连续,产生碎片。当申请堆空间时库函数是按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多
3.8 死锁发生的条件和解决办法
3.8.1 死锁发生条件
-
互斥条件:进程对所分配到的资源不允许其他进程访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源;
-
请求和保持条件:进程获得一定的资源后,又对其他资源发出请求,但是该资源可能被其他进程占有,此时请求阻塞,但该进程不会释放自己已经占有的资源
-
不可剥夺条件:进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用后自己释放
-
环路等待条件:进程发生死锁后,必然存在一个进程-资源之间的环形链
3.8.2 死锁解决
- 资源一次性分配,从而剥夺请求和保持条件
- 可剥夺资源:即当进程新的资源未得到满足时,释放已占有的资源,从而破坏不可剥夺的条件
- 资源有序分配法:系统给每类资源赋予一个序号,每个进程按编号递增的请求资源,释放则相反,从而破坏环路等待的条件
3.9 虚拟内存置换方式
-
FIFO
=> 缺点:无法体现页面冷热信息;
-
LFU => 按引用计数排序
=> 缺点:需要排序;缓存颠簸;
-
LRU => 使用栈,新页面或者命中页放到栈底,每次淘汰栈顶元素
=> 优点:LRU算法对热点数据命中率是很高的
=> 缺点:
- 缓存颠簸,当缓存(1,2,3)满了,之后数据访问(0,3,2,1,0,3,2,1。。。);
- 缓存污染,突然大量偶发性的数据访问,会让内存中存放大量冷数据
-
LRU-K(LRU-2、LRU-3)
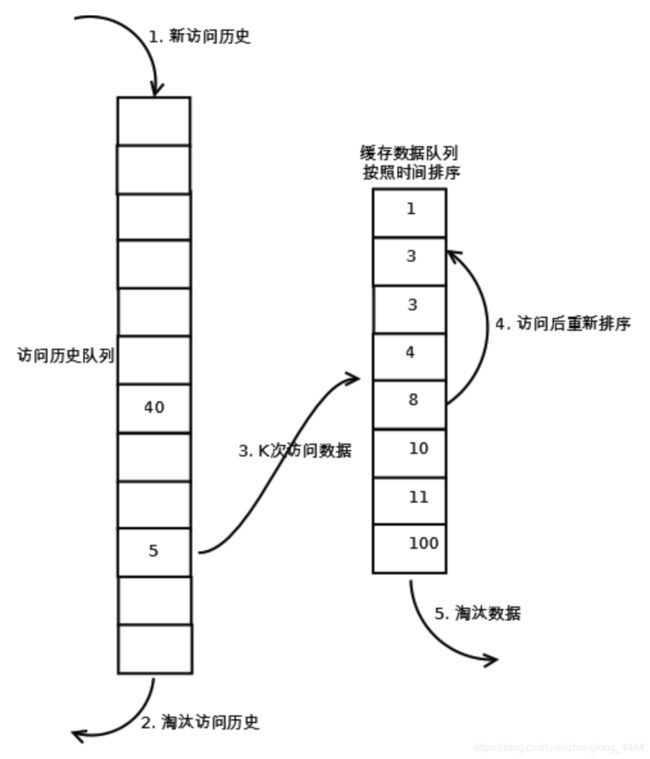
-
数据第一次被访问,加入到访问历史列表;
-
如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
-
当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
-
缓存数据队列中被再次访问后,重新排序;
-
需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;
当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高
-
-
2Q
类似LRU-2。使用一个FIFO队列和一个LRU队列
3.10 进程状态转换图

3.11 僵尸进程
- 孤儿进程:父进程退出,子进程还在运行,即成为孤儿进程;
- 僵尸进程:子进程退出,父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。
- 如果父进程未退出,且没有处理僵尸进程,僵尸进程会一直占用空间,如果父进程退出,则会有init进程接管孤儿进程,进而处理进程状态信息
3.12 虚拟内存、物理内存和共享内存
https://cloud.tencent.com/developer/article/1493029
3.13 Linux内存管理
https://zhuanlan.zhihu.com/p/149581303
4. 数据库
4.1 数据库事务
事务(Transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元。事务是DBMS中最基础的单位,事务不可分割
事务具有4个基本特征,分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Duration),简称ACID
-
原子性
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。
-
一致性
事务必须使数据库从一个一致性状态变换到另一个一致性状态。
-
隔离性
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离,有四种隔离级别
-
Read uncommitted(读未提交)
一个事务可以读取另一个事务未提交的数据 => 存在脏读问题
-
Read committed(读已提交)
一个事务要等另一个事务提交后才能读取数据 => 解决脏读,存在不可重复读问题
-
Repeatable read(重复读)
就是在开始读取数据(事务开启)时,不再允许修改操作 => 解决脏读、不可重复读问题,存在幻读问题
不允许修改操作,但是允许插入操作
-
Serializable(序列化)=> 最高级别的事务隔离
事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用
-
-
持久性
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作
4.2 数据库索引
mysql数据库索引分类
数据库索引是为了增加查询速度而对表字段附加的一种标识,是对数据库表中一列或多列的值进行排序的一种结构。DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。
- 优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性;
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因;
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间;
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
- 缺点:
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加;
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大;
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
- 添加索引原则:
- 在查询中很少使用或者参考的列不应该创建索引;
- 只有很少数据值的列也不应该增加索引;
- 定义为text、image和bit数据类型的列不应该增加索引;
- 当修改性能远远大于检索性能时,不应该创建索引。
4.3 唯一索引和普通索引
唯一索引和普通索引的区别:https://blog.csdn.net/Srodong/article/details/88838046
4.4 聚簇索引和非聚簇索引
https://cloud.tencent.com/developer/article/1541265
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因

- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
4.5 索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能的在select后只写必要的查询字段,以增加索引覆盖的几率。
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
4.6 索引的类型
-
主键索引 : 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
-
唯一索引 : 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
-
可以通过
ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引 -
可以通过
ALTER TABLE table_name ADD UNIQUE (column1,column2);创建唯一组合索引
-
-
普通索引 : 基本的索引类型,没有唯一性的限制,允许为NULL值。
- 可以通过
ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引 - 可以通过
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引
- 可以通过
-
全文索引 :是目前搜索引擎使用的一种关键技术。
- 可以通过
ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
- 可以通过
4.7 MySQL 最左前缀匹配原则
https://www.cnblogs.com/xuwc/p/14007766.html
因为建立联合索引(a, b, c)时,底层是B+树实现的,所以首先会按照a的顺序建立树,在a相等的情况下b才是有序的,在a和b相等的情况下c才是有序的,所以想直接查询 b = 1,是利用不到这个联合索引的。
4.8 MySQL 索引的分类
按数据结构分类可分为:B+tree索引、Hash索引、Full-text索引。
按物理存储分类可分为:聚簇索引、二级索引(辅助索引)。
按字段特性分类可分为:主键索引、普通索引、前缀索引。
按字段个数分类可分为:单列索引、联合索引(复合索引、组合索引)。
4.8.1 按数据结构分类
MySQL索引按数据结构分类可分为:B+tree索引、Hash索引、Full-text索引。
| InnoDB | MyISAM | Memory | |
|---|---|---|---|
| B+tree索引 | √ | √ | √ |
| Hash索引 | × | × | √ |
| Full-text索引 | √(MySQL5.6+) | √ | × |
注:InnoDB实际上也支持Hash索引,但是InnoDB中Hash索引的创建由存储引擎引擎自动优化创建,不能人为干预是否为表创建Hash索引
B+tree 是MySQL中被存储引擎采用最多的索引类型。B+tree 中的 B 代表平衡(balance),而不是二叉(binary),因为 B+tree 是从最早的平衡二叉树演化而来的。下面展示B+tree数据结构与其他数据结构的对比。
1. B+tree与B-tree的对比
B-tree 中的每个节点根据实际情况可以包含多条数据信息和子节点,如下图所示为一个3阶的B-tree:

(图片来源于网络)
相对于B-tree,B+tree有以下两点不同:
- B+tree 非叶子节点只存储键值信息, 数据记录都存放在叶子节点中。而B-tree的非叶子节点也存储数据。所以B+tree单个节点的数据量更小,在相同的磁盘I/O次数下,能查询更多的节点。
- B+tree 所有叶子节点之间都采用单链表连接。适合MySQL中常见的基于范围的顺序检索场景,而B-tree无法做到这一点。

2. B+tree与红黑树的对比

(图片来源于网络)
红黑树是一种弱平衡二叉查找树。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其他路径长出两倍。
对于有N个叶子结点的 B+tree,其搜索复杂度为 O(logdN) ,其中 d(degree) 为 B+tree 的度,表示节点允许的最大子节点个数为d个,在实际应用当中,d值一般是大于100的,即使数据量达到千万级别时B+tree的高度依然维持在3-4左右,保证了3-4次磁盘I/O操作就能查询到目标数据。
红黑树是二叉树,节点子节点个数为两个,意味着其搜索复杂度为 O(logN),树的高度也会比 B+tree 高出不少,因此红黑树检索到目标数据所需经历的磁盘I/O次数更多。
3. B+tree与Hash的对比
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
Hash 索引仅仅能满足 = , IN 和 <=>(表示NULL安全的等价) 查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
Hash 索引无法适用数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash值,而且Hash值的大小关系并不一定和 Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
Hash 索引依然需要回表扫描。
Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键可能存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
由于范围查询是MySQL数据库查询中常见的场景,Hash表不适合做范围查询,它更适合做等值查询。另外Hash表还存在Hash函数选择和Hash值冲突等问题。因此,B+tree索引要比Hash表索引有更广的适用场景。
4.8.2 按物理存储分类
MySQL索引按叶子节点存储的是否为完整表数据分为:聚簇索引、二级索引(辅助索引)。全表数据存储在聚簇索引中,聚簇索引以外的其他索引叫做二级索引,也叫辅助索引。
1. 聚簇索引
聚簇索引的每个叶子节点存储了一行完整的表数据,叶子节点间按id列递增连接,可以方便地进行顺序检索。

(图片来源于网络)
InnoDB表要求必须有聚簇索引,默认在主键字段上建立聚簇索引,在没有主键字段的情况下,表的第一个非空的唯一索引将被建立为聚簇索引,在前两者都没有的情况下,InnoDB将自动生成一个隐式的自增id列,并在此列上建立聚簇索引。
以MyISAM为存储引擎的表不存在聚簇索引。
MyISAM表中的主键索引和非主键索引的结构是一样的,索引的叶子节点不存储表数据,存放的是表数据的地址。所以,MyISAM表可以没有主键。

(图片来源于网络)
MyISAM表的数据和索引是分开存储的。MyISAM表的主键索引和非主键索引的区别仅在于主键索引的B+tree上的key必须符合主键的限制,非主键索引B+tree上的key只要符合相应字段的特性就可以了。
2. 二级索引
二级索引的叶子节点并不存储一行完整的表数据,而是存储了聚簇索引所在列的值。

(图片来源于网络)
回表查询
由于二级索引的叶子节点不存储完整的表数据,索引当通过二级索引查询到聚簇索引列值后,还需要回到聚簇索引也就是表数据本身进一步获取数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ntZKA8go-1651108790488)(https://upload-images.jianshu.io/upload_images/7222676-38b54433b27559f8.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
(图片来源于网络)
回表查询 需要额外的 B+tree 搜索过程,必然增大查询耗时。
需要注意的是,通过二级索引查询时,回表不是必须的过程,当SELECT的所有字段在单个二级索引中都能够找到时,就不需要回表,MySQL称此时的二级索引为覆盖索引或触发了索引覆盖。
可以用Explain命令查看SQL语句的执行计划,执行计划的Extra字段中若出现Using index,表示查询触发了索引覆盖。
4.8.3 按字段特性分类
MySQL索引按字段特性分类可分为:主键索引、普通索引、前缀索引。
1. 主键索引
建立在主键上的索引被称为主键索引,一张数据表只能有一个主键索引,索引列值不允许有空值,通常在创建表时一起创建。
2. 唯一索引
建立在UNIQUE字段上的索引被称为唯一索引,一张表可以有多个唯一索引,索引列值允许为空,列值中出现多个空值不会发生重复冲突。
3. 普通索引
建立在普通字段上的索引被称为普通索引。
4. 前缀索引
前缀索引是指对字符类型字段的前几个字符或对二进制类型字段的前几个bytes建立的索引,而不是在整个字段上建索引。前缀索引可以建立在类型为char、varchar、binary、varbinary的列上,可以大大减少索引占用的存储空间,也能提升索引的查询效率。
4.8.4 按索引字段个数分类
MySQL索引按字段个数分类可分为:单列索引、联合索引(复合索引、组合索引)。
1. 单列索引
建立在单个列上的索引被称为单列索引。
2. 联合索引(复合索引、组合索引)
建立在多个列上的索引被称为联合索引,又叫复合索引、组合索引。
5. 数据结构
5.1 AVL树(平衡二叉树)
以树中所有结点为根的树的左右子树高度之差的绝对值不超过1
5.2 红黑树
红黑树是一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍 ,因此,红黑树是一种弱平衡二叉树,相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,通常使用红黑树。
-
性质:
- 每个节点非红即黑;
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如果一个节点是红色的,则它的子节点必须是黑色的;
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
-
与 AVL 树相比:
AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
红黑树在查找,插入删除的性能都是O(logn),且性能稳定,所以STL里面很多结构包括map底层实现都是使用的红黑树。
5.3 哈夫曼树
哈夫曼树是一种带权路径长度最短的二叉树,也称为最优二叉树。
-
构建哈夫曼树:

- 将每个节点单独作为一个树,构成森林;
- 选择当前森林中根节点权值最小的两棵树,生成一个新的节点作为根节点,其权值为两棵树的根节点的权值之和;
- 从森林中删除这两棵树,并将新树加到森林中;
- 递归执行前两步,直到森林中只剩下一棵树,那棵树即为构造好的哈夫曼树。
-
哈夫曼编码:

根据字符出现的频率设计的一种可变编码(VLC),概率越低的字符权值越低,构造一个哈夫曼树,这样概率越高的字符的编码越短,概率越低的字符编码越短,可以使得整个文本的长度被大幅压缩。
5.4 B树
5.5 B+树
5.6 堆和栈的区别
-
申请方式:
栈由系统自动分配和管理,堆由程序员手动分配和管理。
-
效率:
栈由系统分配,速度快,不会有内存碎片;
堆由程序员分配,速度较慢,可能由于操作不当产生内存碎片。
-
扩展方向:
栈从高地址向低地址进行扩展,堆由低地址向高地址进行扩展。
-
程序局部变量是使用的栈空间,new/malloc动态申请的内存是堆空间,函数调用时会进行形参和返回值的压栈出栈,也是用的栈空间。
5.7 Array和List的区别
- Array
- 优点:
- 随机访问性强;
- 查找速度快。
- 缺点:
- 插入和删除效率低;
- 可能浪费内存;
- 内存空间要求高,必须有足够的连续内存空间;
- 数组大小固定,不能动态拓展。
- 优点:
- List
- 优点:
- 插入删除速度快;
- 内存利用率高,不会浪费内存;
- 大小没有固定,拓展很灵活。
- 缺点:
- 不能随机查找,必须从第一个开始遍历,查找效率低。
- 优点:
5.8 排序算法

5.9 解决Hash冲突的方法
开放定址法、再哈希法、链地址法、建立公共溢出区
5.10 分布式 rehash
https://www.jianshu.com/p/b17bc9719645
5.11 并查集(Union-Find)
https://labuladong.gitbook.io/algo/mu-lu-ye-1/mu-lu-ye-2/unionfind-suan-fa-xiang-jie
-
目标:解决图论中 动态连通性问题
-
实现:
- 用数组模拟一个森林;
- 每个节点初始都指向自己;
- 合并是找到两棵树的根节点,把其中一个挂到另一个上面就可以了;
class UF { // 连通分量个数 private int count; // 存储一棵树 private int[] parent; // 记录树的“重量” private int[] size; public UF(int n) { this.count = n; parent = new int[n]; size = new int[n]; for (int i = 0; i < n; i++) { parent[i] = i; size[i] = 1; } } public void union(int p, int q) { int rootP = find(p); int rootQ = find(q); if (rootP == rootQ) return; // 小树接到大树下面,较平衡 if (size[rootP] > size[rootQ]) { parent[rootQ] = rootP; size[rootP] += size[rootQ]; } else { parent[rootP] = rootQ; size[rootQ] += size[rootP]; } count--; } public boolean connected(int p, int q) { int rootP = find(p); int rootQ = find(q); return rootP == rootQ; } private int find(int x) { while (parent[x] != x) { // 进行路径压缩 parent[x] = parent[parent[x]]; x = parent[x]; } return x; } public int count() { return count; } }
-
优化:
- 小树挂到大树上面;
- 路径压缩
-
应用:
- 可以作为DFS的一种替代方案,很多使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决;
- 表示一种等价性
-
相关例题:
- 990. 等式方程的可满足性
6. 算法
6.1 数据流中的中位数
https://leetcode-cn.com/problems/shu-ju-liu-zhong-de-zhong-wei-shu-lcof/
思路:使用两个堆,大顶堆存较小的一半数,小顶堆存较大的一半数
6.2 用摩尔投票法解决求众数问题
- 相关题目:
- leetcode 229
- 解题思路:
- 记录n个候选者的票数,如果发现n+1个不同的候选者则全部抵消一票,最后留下来的候选者有可能为众数票获得者;
- 再遍历一遍查看余下的候选者是否超过了指定比例的票数,如果超过则当选。
6.3 Top K 问题
-
相关题目:
- 剑指offer 40
-
解题思路:
- 全部排序,取前K个;
- 用快排的思想,进行分区划分,当找到一个分区元素的下标等于k,且前k个均大于(或小于)这个元素,停止;( O ( n ) O(n) O(n))
- 用堆(大顶堆或者小顶堆),持续push,最后pop K 个元素即可;( O ( n l o g n ) O(nlogn) O(nlogn))
- 用优先队列实现最小堆,先往其中push前K个元素,然后每次push一次,pop一次,最后取堆顶元素即可。
6.4 统计 1~n 整数中 1 出现的次数
-
相关题目:
- 剑指Ωoffer 43
-
解题思路:
-
统计每个数位上1可能出现的次数,然后加和
-
对于每个数位上的1如何统计,思路如下:
-
cur == 0

-
cur == 1

-
cur > 1

-
-
6.5 数字序列中的某位数字
-
相关题目:
数字序列中某一位的数字
-
解题思路:
- 1 ~ 9, 10 ~ 99, 100 ~ 999, … => 若干个区间
- 定位到其中一个区间,该区间内所有的数字的位数都是相等的,可以简单的定位到指定数字
6.6 把数组排成最小的数
-
相关题目:
把数组排成最小的数
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
-
解题思路:
-
对于任意两个数字 x , y x, y x,y,定义排序规则为:
- x + y > y + x x + y > y + x x+y>y+x => x > y x > y x>y
- x + y < y + x x + y < y + x x+y<y+x => x < y x < y x<y
-
自定义 C++ priority_queue 比较函数:
struct queue_cmp { bool operator()(const string &a, const string &b) { return stol(a + b) > stol(b + a); } }; -
使用优先队列实现最小堆来排序:
priority_queue<string, vector<string>, queue_cmp> q;
-
6.7 最长不包含重复字符的子字符串
-
相关题目:
最长不含重复字符的子字符串
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
-
解题思路:
-
双指针滑动法:
- 动态规划+哈希表:
- 用hash表记录某个字符最后出现的位置;
- dp[i] 表示以 s[i] 结尾的最长的不含重复字符的子串的长度;
- base case: dp[0] = 1;
- 状态转移方程:
- f ( i ) = { f ( i − 1 ) + 1 d i c t [ i ] < i − f ( i − 1 ) i − d i c t [ i ] d i c t [ i ] > = i − f ( i − 1 ) f(i)=\left\{ \begin{aligned} f(i - 1) + 1 & &dict[i] < i - f(i - 1) \\ i - dict[i] & &dict[i] >= i - f(i - 1) \\ \end{aligned} \right. f(i)={f(i−1)+1i−dict[i]dict[i]<i−f(i−1)dict[i]>=i−f(i−1)
-
6.8 丑数
-
相关题目:
丑数
我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。
-
解题思路:
-
最小堆:
- 先将1放入;
- 每次取堆顶元素,并对堆顶元素分别×2、3、5,加入堆;
- 循环取n次即可;
-
动态规划:
-
dp[i] 表示第 i + 1 i+1 i+1 个 丑数;
-
pa => 指向下一个丑数 * 2,pb => 指向下一个丑数 * 3, pc 指向下一个丑数 * 5;
-
base case: dp[0] = 1, pa = 0, pb = 0, pc = 0;
-
状态转移方程:
f ( i ) = { m i n { f ( p a ) ∗ 2 , f ( p b ) ∗ 3 , f ( p c ) ∗ 5 } i > 0 f(i)=\left\{ \begin{aligned} min\{f(pa) * 2, f(pb) * 3, f(pc) * 5\} && i > 0 \\ \end{aligned} \right. f(i)={min{f(pa)∗2,f(pb)∗3,f(pc)∗5}i>0
if (dp[i] == n1) a++; if (dp[i] == n2) b++; if (dp[i] == n3) c++;
-
-
6.9 数组中的逆序对(难)
-
相关题目:
剑指 Offer 51. 数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
-
解题思路:
-
归并:
- 使用归并排序的思路,每次合并有序数组时,如果右侧小于左侧,则逆序对数量加等于左侧i右半数组的长度

-
6.10 数组中数字出现的次数(中)
-
相关题目:
剑指 Offer 56 - I. 数组中数字出现的次数
一个整型数组
nums里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。 -
解题思路:
- 对于一个数组中除了一个数字之外,其它数字都出现了两次的情况,只要对所有的数字进行异或,剩下的结果就是那个数字;
- 对于一个数组中除了两个数字之外,其它数字都出现了两次的情况 => 可以将数组划分成两个子数组,保证两个子数组都符合上面的情况,就可以简化成异或计算。
- 所以核心问题是 => 怎么去将数组里面的元素划分成两组,保证每组里面除了一个数字之外,其它数字都出现了两次
- 假设这两个只出现一次的数字为 x x x 和 y y y ,那么对数组的所有数字异或的结果 => x ⊕ y x \oplus y x⊕y ,记为 z z z
- 那么只要根据 z z z 的第一个为1的位来分组即可;
扩展:剑指 Offer 56 - II. 数组中数字出现的次数 II
6.11 约瑟夫环问题
-
相关题目:
剑指 Offer 62. 圆圈中最后剩下的数字
-
解题思路
-
用栈模拟 => 数字较大时会超时
-
动态规划:
-
base case : dp[0] = 0
-
状态转移方程:
f ( n ) = ( f ( n − 1 ) + m ) m o d n f(n) = (f(n - 1) + m) \mod n f(n)=(f(n−1)+m)modn
-
-
6.12 最长递增子序列(中)
-
相关题目:
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
最长递增子序列
-
解题思路:
-
动态规划:
-
dp[i] => 以 nums[i] 结尾的最长递增子序列长度
-
base case: dp[i] = 1
-
状态转移方程:
f ( n ) = m a x { f ( i ) ∣ 0 < = i < n & & n u m s [ i ] < n u m s [ n ] } + 1 f(n) = max\{f(i) | 0 <= i < n \&\& nums[i] < nums[n]\} + 1 f(n)=max{f(i)∣0<=i<n&&nums[i]<nums[n]}+1
-
-
6.13 俄罗斯信封套娃问题(难)
-
相关题目:
给你一个二维整数数组 envelopes ,其中 envelopes[i] = [wi, hi] ,表示第 i 个信封的宽度和高度。
当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算 最多能有多少个 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
注意:不允许旋转信封。
俄罗斯套娃信封问题
-
解题思路:
-
按 w 升序之后,相同的 w 情况下按 h 降序进行排序;(因为相同宽度的不能嵌套,所以要对h进行降序排序)
// 先按第一个元素升序,按第二个元素降序 sort(envelopes.begin(), envelopes.end(), [](const vector<int> &a, const vector<int> &b) { if (a[0] == b[0]) { return a[1] > b[1]; } return a[0] < b[0]; }); -
对排序后的数组,按 h 进行最长递增子序列求解即可。
-
7. Redis
https://juejin.cn/post/6844903982066827277
8. 其它
7.1 HTTP2.0
https://mp.weixin.qq.com/s?srcid=0729OoCJZv9OMMrHijFaNuhH&scene=23&sharer_sharetime=1627488323223&mid=2247486228&sharer_shareid=59606716db4868d8bb3a343d6a801bcd&sn=d2f686ff92344889764454bcdb0e8a07&idx=1&__biz=Mzg2ODU1MDkwMw%3D%3D&chksm=ceabda8cf9dc539a52809389b5e4494e00d1cc52a42350dae15043182f7c1963d7c90e12b626&mpshare=1#rd