微服务学习笔记
这里写目录标题
-
- 前置思考与理解
-
- 对什么是微服务的思考
- SOA与微服务的区别
-
- SOA架构特点
- 微服务架构特点
- 主要区别
- 微服务的优点
- 微服务缺点
- Zookeeper
-
- Zookeeper节点(Znode)类型
- Watcher机制
- Zookeeper应用场景
-
- 分布式锁
- Master选举
- 注册中心
- Dubbo
-
- 对通信方式的支持
- Dubbo集群容错模式
- 负载均衡策略
- SPI扩展点
-
- Java SPI
- Dubbo SPI
- Dubbo集成SpringBoot的原理
- Nacos部署
-
- 单机版部署
-
- 编译包安装
- 源码包安装
- Nacos高可用部署
-
- 环境要求
- 配置文件
- 配置MySql数据库
- 启动nacos服务
- Nacos注册中心
-
- Dubbo整合nacos服务注册与发现
-
- 服务注册
- 服务发现
- Nacos作为注册中心的原理
-
- 流程图
- 服务注册源码
- 服务端注册接口源码
- 服务地址动态感知原理
- Nacos配置中心
-
- 传统yml配置的缺点
- Nacos整合Boot读取配置
- 配置字段
- 配置读取规则
- namespace与Group
-
- nacos配置中心数据模型
- 多个配置扩展
- nacos配置中心原理
-
- 动态监听pull、push
- nacos动态监听模式
- 长轮询实现原理
- Sentinel断路器
-
- 基本概念
-
- 限流算法
-
- 计数器
- 滑动窗口
- 漏桶
- 令牌桶
- 熔断
- 熔断和限流的区别
- 降级
- 流控基本应用
-
- 流控类型
- 流控行为
- 熔断基本应用
- SpringCloud集成Sentinel
-
- SPI扩展点接入Sentinel
- Dashboard实现流控
- 自定义URL限流异常
-
- 返回json
- 跳转降级页面
- URL资源清洗
- Sentinel集成Nacos实现动态流控规则
- 分布式事务
-
- CAP定理
- BASE理论
- 术语名词
- XA协议
-
- 两阶段提交协议
- 三阶段提交协议
- TCC补偿型方案
- 可靠性消息最终一致性方案
- 分布式事务框架Seata
前置思考与理解
对什么是微服务的思考
软件开发领域有个经常看到的词叫做分而治之,最开始程序还比较简单的时候,对方法的抽取,到方法所在的文件的隔离,面向对象类的出现,而后在软件逐渐需要做的事情越来越复杂之后,又有了前后端的分离,maven或Gradle等技术对后端代码的分离、SOA思想对服务的分离、近期又出现的微前端思想的前端分离,软件技术在整个迭代过程中一直都离不开分而治之,微服务也不例外,我所理解的微服务是在软件架构体系中对分而治之思想的一个自然延伸,其目的是按照业务领域将整个项目以需要的最小单位进行分割之后,分别独立的进行设计、开发、测试与部署,通过这些分割的小项目之间的通信完成整个项目的业务功能,这样做的好处是将业务需求的伸缩能力精确控制在一个小范围之内,并且更适合在整个软件生命周期中快速的迭代(颗粒度小更适合DevOps)。因为将服务彻底的组件化之后会产生很多新的问题,服务治理问题、分割之后的不同服务与提供相同服务的组件拥有相同或者重叠的配置导致不好管理与维护的问题、服务调用产生的雪崩和扇出等问题、分割之后的前后端交互变复杂的问题等等,所产生的在微服务技术体系中所常见的注册中心、配置中心、断路器、网关等这些技术都只是为了更好的实现组件化,以提高软件的可用性、使软件变得更容易维护,他们只是微服务思想的附加思想或技术,微服务最本质最纯真的思想依然只是分而治之。
SOA与微服务的区别
将SOA的每个服务类比于微服务的每个组件,将企业服务总线类比于网关,如果仅仅是从形式上看似乎两者做的事情差不多,只是微服务比SOA多了更多的东西,cloud alibaba出现了之后,两者的边界更难以区分,知乎上 有个人 的分析说的挺有道理的,他描述了SOA架构和微服务架构的特点。
SOA架构特点
- 服务治理:站在系统的角度,解决企业系统间的通信问题,把原先散乱、无规划的系统间的网状结构,梳理成 规整、可治理的系统间星形结构,这一步往往需要引入 一些产品,比如 ESB、以及技术规范、服务管理规范;这一步解决的核心问题是【有序】
- **系统的服务化:**站在功能的角度,把业务逻辑抽象成 可复用、可组装的服务,通过服务的编排实现业务的 快速再生,目的:把原先固有的业务功能转变为通用 的业务服务,实现业务逻辑的快速复用;这一步解决 的核心问题是【复用】
- **业务的服务化:**站在企业的角度,把企业职能抽象成 可复用、可组装的服务;把原先职能化的企业架构转变为服务化的企业架构,进一步提升企业的对外服务能力;“前面两步都是从技术层面来解决系统调用、系统功能复用的问题”。第三步,则是以业务驱动把一个业务单元封装成一项服务。这一步解决的核心问题是【高效】
微服务架构特点
- 通过服务实现组件化,开发者不再需要协调其它服务部署对本服务的影响。
- 按业务能力来划分服务和开发团队,开发者可以自由选择开发技术,提供 API 服务
- 去中心化,每个微服务有自己私有的数据库持久化业务数据,微服务只能访问自己的数据库,
- 基础设施自动化(devops、自动化部署)
主要区别
我没完全CTRL + C他的,原因是有些细节方面的我感觉原作者没表达清楚,想了解他的点击 有个人 ,以下是结合原笔者和我个人的理解列出来的。
| 区别点 | SOA | 微服务 |
|---|---|---|
| 颗粒度 | 可以不小 | 目标是小 |
| 耦合度 | 松耦合 | 期望是更松的耦合 |
| 组织架构 | 任何类型 | 更适合分散为小团队各自维护 |
| 关注点 | 服务治理、异构系统通信 | 彻底组件化、DevOps |
颗粒度的差异是因为关注点的不一样,而耦合程度和适合的组织架构的不一样又是因为颗粒度的不一样,所以我感觉两个架构思想 最核心的差异还是因为 关注点不一样。
微服务的优点
- 应用达到了最大限度的解耦。
- 组件拥有了各自独立的伸缩能力。
- 单个组件复杂度低,对单个组件的维护会更加简单
- 独立组件使得系统能更方便的迭代,适合DevOps。
- 应用解耦且独立部署后,整个系统有更高的容错性。
- 组件的重用性变高。
微服务缺点
- 日志排查,调用链变长问题排查更困难了
- 微服务的每个组件虽然简单了,但是整体结构却复杂了
- 对设计和开发人员要求更高了(涉及到更高要求的领域边界的划分能力)
- 人事调动的成本更加高了
- 要求的团队协作能力更高了
- 系统的部署、运维、监控成本更高了
Zookeeper
Zookeeper节点(Znode)类型
- 持久化节点:节点的数据会持久化到磁盘
- 临时节点:节点生命周期与创建节点的客户端生命周期一致
- 有序节点:在创建的节点后增加一个递增的序列,该序列对同一个父级节点是唯一的,可以和持久化与临时节点组合
- 容器节点:如果容器节点下面没有子节点,则容器节点 在未来会被Zookeeper自动清除,定时任务默认60s 检查一次
- TTL节点:对于持久化节点,可以设置一个存活时间
【注】 容器节点和TTL节点在3.5.3版本之后才有
Watcher机制
ZooKeeper提供了针对Znode的订阅/通知机制,也就是Znode节点状态发生变化时或者客户端连接发生变化时,会触发事件通知。
- getData(),用于获取节点的value信息,被监听的节点进行创建、修改、删除操作时,会触发相应时间通知。
- getChildren(),用于获取指定节点的子节点,当监听节点的子节点进行创建、修改、删除操作时,触发事件通知。
- exists(),判断节点是否存在,监听的事件类型与getData()相同。
【注】Watcher事件的监听机制是一次性的,第一次触发后需要在回调中再次注册事件
Zookeeper应用场景
分布式锁
使用Zookeeper临时节点以及同级节点的唯一性,就可以利用Zookeeper实现一个分布式锁
-
获得锁
获取排他锁时,客户端在一个固定节点下创建一个临时节点,因为同级节点的唯一性,能保证只有一个客户端创建成功,创建成功则获得排他锁,其他未获得锁的客户端则订阅这个创建的节点的变化情况,收到节点被删除的通知时,重新创建节点争夺锁
-
释放锁
- 客户端因为异常与Zookeeper断开连接,基于临时节点的特性,Zookeeper会删除该节点,也就释放了锁
- 获得锁的客户端执行完业务逻辑后,主动删除了该节点,也就释放了锁
Master选举
- 利用临时节点唯一性,使多台机器同时在Zookeeper创建master节点,能够创建成功的为Master,其他没有创建成功的监听该节点,若Master因为异常与Zookeeper断开连接,则其他客户端得到通知后重新创建master节点争夺Master。
- 利用临时有序节点,使多台机器同时在Zookeeper创建有序节点,编号最小(或最大)的节点即为Master节点,而其他非Master节点订阅该节点的前一个节点,订阅的节点挂掉的时候,后者会收到通知,寻找他节点前一个节点,如果有前一个节点,订阅前一个节点,如果没有,则它自己就是Master节点。
注册中心
作为注册中心,首先需要能实现服务能注册到注册中心中,除此之外,还需要关注两个比较重要的点,一个是服务上下线动态感知,另一个是负载均衡。
-
服务注册
举个例子,当前需要注册一个名为HelloService的服务,服务初始化时创建一个名为com.xsl.service.HelloService的持久化节点,并在该节点下面,提供者在持久化节点下创建providers持久化节点,并将自己的url和端口在该providers下面创建一个临时节点,这样就完成了服务的注册。
-
服务上下线动态感知
这个比较容易,因为客户端注册自己的时候是创建的临时节点,所以当该客户端下线时,Zookeeper便将这个节点删除掉了,现在只需要客户端订阅providers节点的子节点的变化状态,当节点更新时Zookeeper通知客户端,更新url列表
-
负载均衡
通过客户端的负载均衡算法对进行负载均衡。我思考了一下,为什么现在看到的负载均衡大部分都是客户端负载均衡而不是在注册中心做负载均衡呢?我想可能原因如下,如果注册中心做负载均衡,意味着客户端调用的时候需要每次就去注册中心拉一次列表,这样会不会给注册中心过高的压力?
Dubbo
对通信方式的支持
-
支持多种协议的发布:
Dubbo服务支持多种协议的发布,默认是dubbo://,还可以支持rest://,webservice://,thrift://协议等。
-
支持多种注册中心:
Dubbo支持的注册中心有Nacos、Zookeeper、Redis,未来还有计划支持Consul、Eureka与Etcd等。
-
支持多种序列化技术:
支持avro、fst、fastjson、hessian2、kryo等。
Dubbo集群容错模式
dubbo提供了六种容错模式,默认为Failover Cluster,若六种模式都不满足实际需求,还可以自行扩展。
- Failover Cluster:失败自动切换。服务调用失败后,会切换到集群的其他机器重试,默认重试次数为2,该参数可以修改retries=2来修改重试次数
- Failfast Cluster:快速失败。即失败后立即报错,不做处理。
- Failsafe Cluster:失败安全。即错误后忽略异常。
- Failback Cluster:失败后自动回复。失败后后台保存这条记录后定时重发。
- Forking Cluster:并行调用集群中的多个服务,有一个成功就返回,修改forks=2来设置最大并行数。
- Broadcast Cluster:广播所有的服务调用的提供者,任意一个提供者失败则表示调用失败。
容错模式设置建议:对于能保证幂等性的服务,可以采用Failover模式,而其他无法保证幂等性的服务,可以设置容错模式为快速失败的模式,或者使用
Failover模式将重试次数修改为0。
负载均衡策略
Dubbo提供了四种负载均衡策略,默认的负载均衡策略为random,如果这四种不满足需求,可以根据Bubbo中的SPI机制进行扩展。
- Random LoadBalance:随机,这种模式下可以给服务设置权重值,权重越高随机到的概率越大。
- RoundRobin LoadBalance:轮询,同样的,也可以设置权重值。
- LeastActive LoadBalance:最小活跃数,处理较慢的节点将会收到更少的请求。
- ConsistenHash LoadBalance:一致性Hash,即对相同ip的请求总是发送到同一个服务器。
SPI扩展点
SPI 全称为 Service Provider Interface,是一种服务发现机制,程序运行调用接口时,会根据配置文件或默认规则信息加载对应的实现类,所以在程序中并没有直接指定使用接口的哪个实现,而是在外部进行装配。在 Dubbo 中有大量功能的实现都是基于 Dubbo SPI 实现解耦。
Java SPI
这里利用JDK原生的SPI来模拟一下数据库驱动Driver的设计,新建一个Maven工程,创建一个子工程driver,工程内部定义一个接口
/**
* 模拟JavaEE的驱动,测试SPI扩展点
*
* @author xsl
*/
public interface Driver {
/**
* 建立连接
*/
String connect();
}
然后创建另外一个子工程mysql,依赖driver工程,内部定义一个MysqlDriver实现Driver接口
/**
* Mysql驱动
*
* @author xsl
*/
public class MysqlDriver implements Driver{
@Override
public String connect() {
return "连接到Mysql";
}
}
在mysql的resources/META-INF/services目录下创建一个以Driver接口全限定类名的文件,在里面填写我们的实现MysqlDriver的全限定类名
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aKVXpnar-1633400976036)(https://gitee.com/yiming_1/pic/raw/master/pic/1627444491(1)].png)
创建一个测试类加载扩展点,并尝试调用方法
/**
* 测试扩展点
*
* @author xsl
*/
public class SpiTest {
public static void main(String[] args) {
ServiceLoader<Driver> load = ServiceLoader.load(Driver.class);
load.forEach(driver -> System.out.println(driver.connect()));
}
}
Dubbo SPI
Dubbo没有直接使用Jdk的SPI机制,他们实现了自己的一套SPI机制,Dubbo的SPI扩展机制使用起来与Java SPI略有不同,Dubbo SPI需要在META-INF/dubbo、META-INF/dubbo/internal、META-INF/services目录下创建以接口全限定类名命名的文件,且其内部的内容以key=value的形式填写该文件。
测试一个Dubbo的扩展点步骤如下:
在一个依赖了Dubbo的工程,创建一个扩展点以及一个实现,在Dubbo中扩展点需要声明@SPI注解
@SPI
public interface Driver {
/**
* 建立连接
*/
String connect();
}
/**
* Mysql驱动
*
* @author xsl
*/
public class MysqlDriver implements Driver{
@Override
public String connect() {
return "连接到Mysql";
}
}
在resources/META-INF/dubbo目录下创建resources/META-INF/services目录下创建一个以Driver接口全限定类名的文件,在里面填写mysqlDriver=我们的实现MysqlDriver的全限定类名,如下所示:
mysqlDriver=com.xsl.spi.MysqlDriver
创建测试类,加载扩展点实现测试使用
@Test
public void connectTest(){
ExtensionLoader<Driver> extensionLoader = ExtensionLoader.getExtensionLoader(Driver.class);
Driver driver = extensionLoader.getExtension("mysqlDriver");
System.out.println(driver.connect());
}
Dubbo集成SpringBoot的原理
任何框架集成进SpringBoot,最方便的方式都是使用SpringBoot-starter技术,我们从@DubboComponentScan,集成SpringBoot的入口开始看起
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import(DubboComponentScanRegistrar.class)
public @interface DubboComponentScan {
String[] value() default {};
String[] basePackages() default {};
Class<?>[] basePackageClasses() default {};
}
以上是这个注解的定义,这里重点关注的是@Import(DubboComponentScanRegistrar.class),如果@Import注解的参数在括号中的类是ImportBeanDefinitionRegistrar的实现类,则会调用接口方法registerBeanDefinitions()。
public class DubboComponentScanRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
// 获取扫描的包名称
Set<String> packagesToScan = getPackagesToScan(importingClassMetadata);
// 被@Service注解标记的类注册进Spring的Ioc容器
registerServiceAnnotationBeanPostProcessor(packagesToScan, registry);
// 注册被@Refernce的标记的类
registerReferenceAnnotationBeanPostProcessor(registry);
}
private void registerServiceAnnotationBeanPostProcessor(Set<String> packagesToScan, BeanDefinitionRegistry registry) {
// 这个导入的一个static方法,他是这么导入的,比较少见
// import static org.springframework.beans.factory.support.BeanDefinitionBuilder.rootBeanDefinition;
// 这里通过 ServiceAnnotationBeanPostProcessor.class获取了一个BeanDefinition的构造器,这个对Spring源码稍微有点熟悉的都不会陌生
BeanDefinitionBuilder builder = rootBeanDefinition(ServiceAnnotationBeanPostProcessor.class);
builder.addConstructorArgValue(packagesToScan);
builder.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
// 获取beanDefinition
AbstractBeanDefinition beanDefinition = builder.getBeanDefinition();
// 注册进IOC容器
BeanDefinitionReaderUtils.registerWithGeneratedName(beanDefinition, registry);
}
private void registerReferenceAnnotationBeanPostProcessor(BeanDefinitionRegistry registry) {
// 这里点进去就可以看到他通过ReferenceAnnotationBeanPostProcessor.class获取了BeanDefinition
BeanRegistrar.registerInfrastructureBean(registry,
ReferenceAnnotationBeanPostProcessor.BEAN_NAME, ReferenceAnnotationBeanPostProcessor.class);
}
private Set<String> getPackagesToScan(AnnotationMetadata metadata) {
// 获取DubboComponentScan注解的属性集合
AnnotationAttributes attributes = AnnotationAttributes.fromMap(
metadata.getAnnotationAttributes(DubboComponentScan.class.getName()));
// 获取三个数值指定的值
String[] basePackages = attributes.getStringArray("basePackages");
Class<?>[] basePackageClasses = attributes.getClassArray("basePackageClasses");
String[] value = attributes.getStringArray("value");
// 全部转换为全限定类名且去重
Set<String> packagesToScan = new LinkedHashSet<String>(Arrays.asList(value));
packagesToScan.addAll(Arrays.asList(basePackages));
for (Class<?> basePackageClass : basePackageClasses) {
packagesToScan.add(ClassUtils.getPackageName(basePackageClass));
}
if (packagesToScan.isEmpty()) {
return Collections.singleton(ClassUtils.getPackageName(metadata.getClassName()));
}
return packagesToScan;
}
}
看完整个代码就可以发现注入IOC容器的核心在于两个类,一个是ServiceAnnotationBeanPostProcessor,另一个是ReferenceAnnotationBeanPostProcessor,获得BeanDefinition都直接的被这两个类影响,而BeanDefinition 用于保存 Bean 的相关信息,包括属性、构造方法参数、依赖的 Bean 名称及是否单例、延迟加载等,它是实例化 Bean 的原材料,Spring 就是根据 BeanDefinition 中的信息实例化 Bean。我们看ServiceAnnotationBeanPostProcessor类,
// 他实现了很多接口,但是我们只用关注BeanDefinitionRegistryPostProcessor即可了public class ServiceAnnotationBeanPostProcessor implements BeanDefinitionRegistryPostProcessor, EnvironmentAware, ResourceLoaderAware, BeanClassLoaderAware { @Override public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException { Set resolvedPackagesToScan = resolvePackagesToScan(packagesToScan); if (!CollectionUtils.isEmpty(resolvedPackagesToScan)) { // 重点在这个方法 registerServiceBeans(resolvedPackagesToScan, registry); } //..... 省略 } // 上面的方法调用了他 private void registerServiceBeans(Set packagesToScan, BeanDefinitionRegistry registry) { // 看到这个类名很欣慰,这个类继承了ClassPathBeanDefinitionScanner, DubboClassPathBeanDefinitionScanner scanner = new DubboClassPathBeanDefinitionScanner(registry, environment, resourceLoader); BeanNameGenerator beanNameGenerator = resolveBeanNameGenerator(registry); // 设置bean名字生成器 scanner.setBeanNameGenerator(beanNameGenerator); // 设置过滤器,被Service注解的才注入 scanner.addIncludeFilter(new AnnotationTypeFilter(Service.class)); //Add the compatibility for legacy Dubbo's @Service 添加对旧版Service注解的支持 scanner.addIncludeFilter(new AnnotationTypeFilter(com.alibaba.dubbo.config.annotation.Service.class)); for (String packageToScan : packagesToScan) { // 扫描被两个@Service注解的类注册进Ioc容器 scanner.scan(packageToScan); // Finds all BeanDefinitionHolders of @Service whether @ComponentScan scans or not. // 查找@Service 的所有BeanDefinitionHolders,无论@ComponentScan 是否扫描。 Set beanDefinitionHolders = findServiceBeanDefinitionHolders(scanner, packageToScan, registry, beanNameGenerator); if (!CollectionUtils.isEmpty(beanDefinitionHolders)) { for (BeanDefinitionHolder beanDefinitionHolder : beanDefinitionHolders) { // 遍历单个注册进Ioc容器 registerServiceBean(beanDefinitionHolder, registry, scanner); } } // ......省略 } } private void registerServiceBean(BeanDefinitionHolder beanDefinitionHolder, BeanDefinitionRegistry registry, DubboClassPathBeanDefinitionScanner scanner) { // 对应的类的字节码 Class beanClass = resolveClass(beanDefinitionHolder); // 类是否被dubbo的两个中的任意一个Service注解呢 Annotation service = findServiceAnnotation(beanClass); // 获取service注解的属性 AnnotationAttributes serviceAnnotationAttributes = getAnnotationAttributes(service, false, false); // 获取服务的接口 Class interfaceClass = resolveServiceInterfaceClass(serviceAnnotationAttributes, beanClass); // 服务名 String annotatedServiceBeanName = beanDefinitionHolder.getBeanName(); // 构建BeanDefinition AbstractBeanDefinition serviceBeanDefinition = buildServiceBeanDefinition(service, serviceAnnotationAttributes, interfaceClass, annotatedServiceBeanName); // 生成服务名称 String beanName = generateServiceBeanName(serviceAnnotationAttributes, interfaceClass); if (scanner.checkCandidate(beanName, serviceBeanDefinition)) { // 注册进入IOC registry.registerBeanDefinition(beanName, serviceBeanDefinition); // ......省略 } // ......省略 } // 类是否被dubbo的两个Service中的一个注解呢 private Annotation findServiceAnnotation(Class beanClass) { Annotation service = findMergedAnnotation(beanClass, Service.class); if (service == null) { service = findMergedAnnotation(beanClass, com.alibaba.dubbo.config.annotation.Service.class); } return service; }}
Nacos部署
单机版部署
Nacos安装有Nacos源码安装和编译好的安装包安装两种方式,安装包在github上下载即可, 下载地址 ,其中source为源码包,另一个为编译包
编译包安装
编译包安装非常简单,解压编译包文件,cmd进入nacos/bin/执行startup.cmd -m standalone即可,当然,使用linux则下载linux的编译包执行./startup.sh -m standalone即可单机启动
源码包安装
- 配置maven环境变量
- 解压源码包进入根目录,执行 mvn -Prelease-nacos clean install -U 构建,构建之后会创建一个distribution目录。
- cd distribution/target/nacos-server-$version/nacos/bin
- 与编译包一样的执行命令
在安装成功之后可以通过部署的ip地址:8848/nacos访问nacos登录界面,账号与密码都为nacos
Nacos高可用部署
环境要求
本次部署中的环境为:
- 64 bit Os Linux/Unix/Mac,推荐使用linux系统
- 3台服务器或虚拟机
- 64 bit JDK 1.8以上
- maven 3.2.x及以上
- 3个或3个以上的nacos节点才能构成集群
- MySql数据库(最好为5.7版本)
配置文件
nacos/conf目录下包含以下文件
- application.properties: SpringBoot项目默认的配置文件
- cluster.conf.example: 集群配置样例文件
- nacos-mysql.sql: Mysql数据库初始脚本。Nacos默认使用自带的Derby数据库,可以配置为Mysql。
- nacos-logback.xml: nacos的日志配置文件
配置nacos集群需要用到cluster.conf,我们可以直接重命名提供的example文件,修改该配置的信息类似下面
192.168.13.104:8848192.168.13.105:8848192.168.13.106:8848
将三台机器的配置保持一致,并且防火墙开放8848端口
## 直接关闭防火墙,生产上不建议使用systemctl stop firewalld.service## 开放端口并配置生效,生产上建议这样开放端口firewall-cmd --zone=public --add-port=8848/tcp --permanent# --zone 作用域# --add-port=5121/tcp 添加端口,格式为:端口/通讯协议# --permanent 永久生效,没有此参数重启后失效firewall-cmd --reload
配置MySql数据库
- 创建数据库nacos_config,并利用nacos-mysql.sql初始化
- 修改nacos/conf下的application.properties文件,增加mysql配置
spring.datasource.platform=mysqldb.num=1db.url.0=jdbc:mysql://192.168.13.106:3306/nacos-configdb.user=rootdb.password=root
启动nacos服务
分别进入3台机器部署的nacos的bin目录,执行sh startup.sh或者start.cmd -m cluster命令启动服务,服务启动成功后,再nacos\logs\start.out可以获取如下日志,表示服务启动成功。
2021-07-29 4:00:24,654 INFO Nacos Log files: /data/program/nacos/logs/2021-07-29 4:00:24,654 INFO Nacos Conf files: /data/program/nacos/conf/2021-07-29 4:00:24,654 INFO Nacos Data files: /data/program/nacos/data/2021-07-29 4:00:24,654 INFO Nacos started successfully in cluster mode.
通过ip:8848/nacos访问nacos控制台,在节点列表下可以看到集群的节点信息。
Nacos注册中心
Dubbo整合nacos服务注册与发现
服务注册
demo源码 :https://gitee.com/yiming_1/spring-cloud-0alibaba/tree/master/spring-boot-dubbo-nacos-sample
服务发现
服务端demo源码 :https://gitee.com/yiming_1/spring-cloud-alibaba/tree/master/spring-cloud-nacos-sample
消费者demo源码 :https://gitee.com/yiming_1/spring-cloud-alibaba/tree/master/spring-cloud-nacos-consumer
Nacos作为注册中心的原理
流程图

服务注册源码
在Spring-Cloud-Common包中有个接口 org.springframework.cloud.client.serviceregistry.ServiceRegistry,这个接口是SpringCloud提供的服务注册标准,集成到SpringCloud中实现服务注册的组件,都会实现该接口。
public interface ServiceRegistry<R extends Registration> { // 服务注册 void register(R registration); // 取消注册 void deregister(R registration); void close(); void setStatus(R registration, String status); T getStatus(R registration);}
这个接口有一个实现类com.alibaba.cloud.nacos.registry.NacosServiceRegistry,用idea可以很明显的看到类上被SpringBoot管理的标志

三方依赖的类被Springboot管理,显然是使用了spring-boot-starter技术,要么被@Import注解导入,要么采用了spring.factories来导入,发现在spring.factories中有个com.alibaba.cloud.nacos.NacosDiscoveryAutoConfiguration被导出,这个类是一个配置类,在这个类里面发现了NacosServiceRegistry被注入IOC容器。
// 向IOC容器注入NacosServiceRegistry@Beanpublic NacosServiceRegistry nacosServiceRegistry(NacosDiscoveryProperties nacosDiscoveryProperties) { return new NacosServiceRegistry(nacosDiscoveryProperties);}// 同时也注入了这个类NacosAutoServiceRegistration,这个类很重要,后面会用到@Bean@ConditionalOnBean(AutoServiceRegistrationProperties.class)public NacosAutoServiceRegistration nacosAutoServiceRegistration( NacosServiceRegistry registry, AutoServiceRegistrationProperties autoServiceRegistrationProperties, NacosRegistration registration) { return new NacosAutoServiceRegistration(registry, autoServiceRegistrationProperties, registration);}
NacosServiceRegistry确实是注入进IOC容器了,那是什么时候触发的根据NacosServiceRegistry将之注册进Nacos的呢?回到Commons包的spring.factories文件,可以看到org.springframework.boot.autoconfigure.EnableAutoConfiguration有导出一个org.springframework.cloud.client.serviceregistry.AutoServiceRegistrationAutoConfiguration
@Configuration@Import(AutoServiceRegistrationConfiguration.class)@ConditionalOnProperty(value = "spring.cloud.service-registry.auto-registration.enabled", matchIfMissing = true)public class AutoServiceRegistrationAutoConfiguration { // 注入了这么一个类,这个类被nacos的包中注入了一个实现NacosAutoServiceRegistration,也就是上面说的很重套的类 @Autowired(required = false) private AutoServiceRegistration autoServiceRegistration; @Autowired private AutoServiceRegistrationProperties properties; @PostConstruct protected void init() { if (this.autoServiceRegistration == null && this.properties.isFailFast()) { throw new IllegalStateException("Auto Service Registration has " + "been requested, but there is no AutoServiceRegistration bean"); } }}
可以看到这个配置类中注入了一个AutoServiceRegistration,看这个接口的实现有一个NacosAutoServiceRegistration,NacosAutoServiceRegistration(在NacosDiscoveryAutoConfiguration中被注入IOC的的另一个类)的继承关系如下图:

NacosAutoServiceRegistration的父类是一个AbstractAutoServiceRegistration的抽象类,这个抽象类实现了ApplicationListener接口,ApplicationListener是一个监听事件,看到AbstractAutoServiceRegistration对这个接口的实现
@Override@SuppressWarnings("deprecation")public void onApplicationEvent(WebServerInitializedEvent event) { bind(event);}
接口监听了一个WebServerInitializedEvent事件,该事件在web容器启动时触发,在方法中调用了一个bind()方法,bind()方法的最后一行调用了start()方法,start()方法中调用了一个register()方法,在register()方法中(老母猪带胸罩,一套又一套…):
protected void register() { // 服务注册 this.serviceRegistry.register(getRegistration());}
这里调用了serviceRegistry.register()进行服务注册,这个serviceRegistry通过构造器注入,而NacosAutoServiceRegistration初始化的时候就会注入这个已经被IOC容器管理的NacosServiceRegistry,终于闭环了。在NacosServiceRegistry重写的register()方法中,可以看到
namingService.registerInstance(serviceId, group, instance);
这个方法就是注册进nacos实例的方法:
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException { if (instance.isEphemeral()) { BeatInfo beatInfo = new BeatInfo(); beatInfo.setServiceName(NamingUtils.getGroupedName(serviceName, groupName)); beatInfo.setIp(instance.getIp()); beatInfo.setPort(instance.getPort()); beatInfo.setCluster(instance.getClusterName()); beatInfo.setWeight(instance.getWeight()); beatInfo.setMetadata(instance.getMetadata()); beatInfo.setScheduled(false); long instanceInterval = instance.getInstanceHeartBeatInterval(); beatInfo.setPeriod(instanceInterval == 0L ? DEFAULT_HEART_BEAT_INTERVAL : instanceInterval); // 心跳 this.beatReactor.addBeatInfo(NamingUtils.getGroupedName(serviceName, groupName), beatInfo); } // 注册服务实例 this.serverProxy.registerService(NamingUtils.getGroupedName(serviceName, groupName), groupName, instance);}
这个方法中,beatReactor.addBeatInfo() 是心跳的实现方法,点进去看看
public void addBeatInfo(String serviceName, BeatInfo beatInfo) { LogUtils.NAMING_LOGGER.info("[BEAT] adding beat: {} to beat map.", beatInfo); String key = this.buildKey(serviceName, beatInfo.getIp(), beatInfo.getPort()); BeatInfo existBeat = null; if ((existBeat = (BeatInfo)this.dom2Beat.remove(key)) != null) { existBeat.setStopped(true); } this.dom2Beat.put(key, beatInfo); // 定时任务发送心跳包 this.executorService.schedule(new BeatReactor.BeatTask(beatInfo), beatInfo.getPeriod(), TimeUnit.MILLISECONDS); MetricsMonitor.getDom2BeatSizeMonitor().set((double)this.dom2Beat.size()); }
看executorService.schedule可以看出来就是开启了一个定时任务向服务端发送数据包,然后启动一个线程不断检测服务端的回应,未收到回应则服务端故障,而服务端也是通过这个数据包来更新服务的状态。
服务端注册接口源码
服务注册服务端接口在nacos-naming模块下的InstanceController类中。
@CanDistro@PostMapping@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)public String register(HttpServletRequest request) throws Exception { final String namespaceId = WebUtils .optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID); final String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME); NamingUtils.checkServiceNameFormat(serviceName); final Instance instance = parseInstance(request); getInstanceOperator().registerInstance(namespaceId, serviceName, instance); return "ok";}
这个方法其他倒是没什么好看的,跟据发来的请求获取namespaceId、serviceName、获取实例,注册服务。getInstanceOperator().registerInstance(),看看这个方法。
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException { com.alibaba.nacos.naming.core.Instance coreInstance = (com.alibaba.nacos.naming.core.Instance) instance; // 注册服务 serviceManager.registerInstance(namespaceId, serviceName, coreInstance);}
继续往下看
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException { // 创建空服务 createEmptyService(namespaceId, serviceName, instance.isEphemeral()); Service service = getService(namespaceId, serviceName); checkServiceIsNull(service, namespaceId, serviceName); // 添加实例 addInstance(namespaceId, serviceName, instance.isEphemeral(), instance);}
在createEmptyService()方法中,调用了createServiceIfAbsent()方法,代码如下:
public void createServiceIfAbsent(String namespaceId, String serviceName, boolean local, Cluster cluster) throws NacosException { // 容器是否有服务? Service service = getService(namespaceId, serviceName); // 没有就创建服务 if (service == null) { Loggers.SRV_LOG.info("creating empty service {}:{}", namespaceId, serviceName); service = new Service(); service.setName(serviceName); service.setNamespaceId(namespaceId); service.setGroupName(NamingUtils.getGroupName(serviceName)); // now validate the service. if failed, exception will be thrown service.setLastModifiedMillis(System.currentTimeMillis()); service.recalculateChecksum(); // 如果有集群,放进集群的Map内部去 if (cluster != null) { cluster.setService(service); service.getClusterMap().put(cluster.getName(), cluster); } service.validate(); // 置入存放服务的容器,瞅瞅这个方法 putServiceAndInit(service); if (!local) { addOrReplaceService(service); } } }
private void putServiceAndInit(Service service) throws NacosException { // 放进服务缓存,没什么就是双重检查锁放进一个ConcurrentHashMap putService(service); service = getService(service.getNamespaceId(), service.getName()); // 建立心跳 checkTask = new HealthCheckTask(this);HealthCheckReactor.scheduleCheck(checkTask);做健康检查也是个定时任务 service.init(); // 数据一致性监听 consistencyService .listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), true), service); consistencyService .listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), false), service); Loggers.SRV_LOG.info("[NEW-SERVICE] {}", service.toJson()); }
服务地址动态感知原理
其实流程图中已经表现出来了,很简单,消费者与注册中心建立心跳,每10s拉取一遍提供者列表,提供者注册进入注册中心之后,与注册中心建立心跳,注册中心感知到心跳异常了,更新服务列表,将消息以udp的形式发送给消费者,消费者接收消息更新服务地址。
Nacos配置中心
传统yml配置的缺点
- 难以实现配置的动态更新,如果需要这样的需求,只能将配置信息抽到内存或者中间件
- 配置集中管理问题,集群下改一个配置文件需要修改多个配置文件
Nacos整合Boot读取配置
nacos配置中心demo :https://gitee.com/yiming_1/spring-cloud-alibaba/tree/master/spring-cloud-nacos-config
配置字段
- Data Id:标识nacos某个配置集的ID,通常用于组织划分系统的配置集
- Group:标识配置所属的分组
- 配置格式:配置内容锁遵循的格式
配置读取规则
- 配置中心配置项要放在bootstrap.properties或者bootstrap.yaml/yml中,因为bootstrap的优先级比application优先级要高。
- 指定了spring.cloud.nacos.config.prefix,会读取Data Id为 s p r i n g . c l o u d . n a c o s . c o n f i g . p r e f i x . {spring.cloud.nacos.config.prefix}. spring.cloud.nacos.config.prefix.{spring.cloud.nacos.config.file-extension}的配置文件
- 未指定spring.cloud.nacos.config.prefix,读取Data Id为 s p r i n g . a p p l i c a t i o n . n a m e . {spring.application.name}. spring.application.name.{spring.cloud.nacos.config.file-extension}的配置文件
- 如果在bootstrap配置文件中配置了spring.profiles.active=env,{spring.application.name}- e n v . {env}. env.{spring.cloud.nacos.config.file-extension}的配置
namespace与Group
nacos配置中心数据模型

官方的建议是,NameSpace用于解决多环境或多租户数据的隔离问题,而group用于解决业务层面的数据分组,在设计之前,需要对namespace
和group定性
多个配置扩展
spring.cloud.nacos.config.ext-config[n].data-id=example.properties #指定dataIdspring.cloud.nacos.config.ext-config[n].group=DEFAULT_GROUP #指定DEFAULT_GROUPspring.cloud.nacos.config.ext-config[n].refresh=true #是否动态刷新
使用中要注意的点:
- 配置data-id必须要带文件格式后缀
- 多个Data-id时,n越大优先级越高
- 如果ext-config与 s p r i n g . a p p l i c a t i o n . n a m e . {spring.application.name}. spring.application.name.{file-extension:properties}都存在的情况下,优先级高的是后者。
nacos配置中心原理
动态监听pull、push
pull,即客户端主动去拉,push即服务端主动推;两者各有优劣,pull需要定时拉,时间间隔大则不实时,时间间隔小则服务端压力大;而push需要服务端和客户端维持一个长连接,如果客户端多,需要浪费内存资源保持连接,为了检测连接的有效性可能还需要发心跳包。
nacos动态监听模式
nacos采用了一种较为综合的模式,主体依然是pull,但是pull的机制有所变化,在服务端接收到pull请求后,服务端检查配置信息是否有变化,如果有变化直接返回最新信息,无变化则hold住这个请求,等待有变化或者超过29.5秒则返回结果,这种方式的名称叫做长轮询,这样做既避免了轮询pull带来的服务端压力大或者时效性差的问题,又避免了长连接+心跳的资源浪费问题。
长轮询实现原理

nacos获得client的请求后,如果配置没有更新,则设置一个定时任务,延时29.5秒执行,并且把当前客户端长轮询连接加入到allSubs队列中,此时若有更新,会触发一个更新事件机制,监听该事件的任务通过该任务中的连接进行返回,完成推送操作。
Sentinel断路器
基本概念
限流算法
计数器
限制每个时间周期的访问量,累加器累加访问次数,达到阈值限制访问次数,下个时间周期清零,这个比较简单。但是会有临界问题,在两个时间段的临界点之前与之后瞬间同时发送总和超过阈值但是在每个段又不超出阈值的请求数,会在瞬间让服务器接收到超出处理能力的请求量。
滑动窗口
在计数器算法的基础上,划分一个更小的颗粒度,以其中后n个颗粒的请求总和作为限制条件,这样可以丢弃过时的那部分时间片。(其实感觉本质上没有避免临界问题,只是减缓了临界问题)
漏桶
漏桶算法是访问请求到达时直接放入漏桶,如当前容量已达到上限,则进行丢弃,漏桶以固定的速率释放访问请求,直到漏桶为空。
令牌桶
令牌桶算法是程序以r(r=时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满,请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略。令牌桶的相较于漏桶的好处是,假设现在希望平均每秒处理13个请求,那漏桶是控制的是流出速率,所以无法处理瞬时大于13的情况,但是令牌桶限制的是令牌的流入速率,也就是说桶内积攒的令牌可以被瞬时吃光,瞬时处理可以超过13,可以更高的压榨服务器性能。而令牌桶相较于计数器或者滑动窗口,也可以比较好的限制临界点问题,因为当桶内令牌用光了之后,生成令牌的速率并不会那么快,所以可以有效的限制临界点两次大量请求的问题。
熔断
熔断指服务无法正常为服务调用者提供服务时,为了防止整个系统出现雪崩效应,暂时讲出现故障的接口隔离出来,断绝与外部接口的联系,当触发熔断之后,后续对该服务的调用都会直接失败,直到服务恢复正常。
熔断和限流的区别
熔断是指调用者为了避免被调用者堵塞而影响了自身的处理速度,是对下游的限制,而限流是对上游调用者的请求量的限制,两者针对对象不同。
降级
服务降级,就是对不怎么重要的服务进行低优先级的处理。说白了,就是尽可能的把系统资源让给优先级高的服务。资源有限,而请求是无限的。如果在并发高峰期,不做服务降级处理,一方面肯定会影响整体服务的性能,严重的话可能会导致宕机某些重要的服务不可用。所以,一般在高峰期,为了保证网站核心功能服务的可用性,都要对某些服务降级处理。
-
拒绝服务
判断应用来源,高峰时段拒绝低优先级应用的服务请求,保证核心应用正常工作。
-
关闭服务
既然是高峰期,那么可以关闭一些冷门的或者边缘不重要的服务,给核心服务让出资源。
流控基本应用
首先引入Sentinel核心库
<dependency> <groupId>com.alibaba.cspgroupId> <artifactId>sentinel-coreartifactId> <version>1.7.1version>dependency>
定义一个普通方法
/** * 抛一个异常的流控 * @param i */ private static void doSomething(int i) { try(Entry entry = SphU.entry("doSomething")){ System.out.println(i + " hello sentinel"); }catch (BlockException e){ System.err.println(i + " 流控"); } }
制定限流规则并添加
private static void initFlowsRules(){ List<FlowRule> rules = new ArrayList<>(); FlowRule flowRule = new FlowRule(); // 保护的资源 SphU.entry参数对应 flowRule.setResource("doSomething"); // 限流类型,QPS与并发线程 flowRule.setGrade(RuleConstant.FLOW_GRADE_QPS); flowRule.setCount(20); rules.add(flowRule); FlowRuleManager.loadRules(rules); }
测试
public static void main(String[] args) throws InterruptedException { initFlowsRules(); int i = 1; while (true){ Thread.sleep(20); doSomething(i); i++; }}
这种方式在限流的时候会跑一个异常,也有返回布尔值的
/** * 返回一个布尔值的流控 * @param i */private static void doSomething1(int i) { if (SphO.entry("doSomething")){ try { System.out.println(i + " hello sentinel"); }finally { SphO.exit(); } }else { System.err.println(i + " 流控"); }}
也可以用注解方式
@SentinelResource(value = "getUserById", blockHandler = "blockHandlerForUser") public HashMap getUserById(Integer id){ return new HashMap(2){ { put("name", "xsl"); } }; } public HashMap blockHandlerForUser(String id, BlockException e){ return new HashMap(2){ { put("流控", "流控"); } }; }
流控类型
- 并发线程数:统计当前请求的上下文线程数量,如果超出阈值,请求会被拒绝。
- QPS:每秒查询数。
流控行为
- 直接拒绝:请求流量超出阈值直接抛出异常。
- Warm Up:冷启动,如果希望请求的数量逐步递增,并在一个预期时间之后打到允许的处理请求的最大值时,可以用这。
- 匀速排队:严格控制请求的间隔时间,让请求以均匀的速度通过
- 冷启动+匀速排队
熔断基本应用
实现服务熔断与限流的配置相似,只是限流使用的是FlowRule,熔断用DegradeRule,配置代码如下。
private static void initDegradeRule(){ List<DegradeRule> rules = new ArrayList<>(); DegradeRule degradeRule = new DegradeRule(); degradeRule.setResource("KEY"); degradeRule.setCount(20); // 熔断策略 degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_RT); // 熔断降级时间窗口,触发熔断后多长时间自动熔断 degradeRule.setTimeWindow(10); // 1s内持续多少个请求的平均RT超出阈值后触发熔断 degradeRule.setMinRequestAmount(5); // 触发异常熔断的最小请求数 degradeRule.setRtSlowRequestAmount(5); rules.add(degradeRule);}
SpringCloud集成Sentinel
SPI扩展点接入Sentinel
创建一个Springboot-web工程,引入cloud依赖和sentinel依赖
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-dependenciesartifactId> <version>Greenwich.RELEASEversion> dependency> <dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-sentinelartifactId> <version>2.1.1.RELEASEversion> dependency>
编写一个rest接口,并通过SentinelResource配置限流保护资源
package com.example.sentinel.controller;import com.alibaba.csp.sentinel.annotation.SentinelResource;import com.alibaba.csp.sentinel.slots.block.BlockException;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;/** * 测试sentinel * * @author xsl */@RestControllerpublic class HelloController { @SentinelResource(value = "hello", blockHandler = "blockHandleHello") @GetMapping("/say") public String sayHello(){ return "hello sentinel"; } public String blockHandleHello(BlockException e){ return "被限流啦"; }}
实现InitFunc接口
package com.example.sentinel.config;import com.alibaba.csp.sentinel.init.InitFunc;import com.alibaba.csp.sentinel.slots.block.RuleConstant;import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;import java.util.ArrayList;import java.util.List;/** * 配置流控规则 * * @author xsl */public class FlowRuleInitFunc implements InitFunc { @Override public void init() throws Exception { List<FlowRule> rules = new ArrayList<>(); FlowRule flowRule = new FlowRule(); flowRule.setCount(1); flowRule.setResource("hello"); flowRule.setGrade(RuleConstant.FLOW_GRADE_QPS); flowRule.setLimitApp("default"); rules.add(flowRule); FlowRuleManager.loadRules(rules); }}
在resources目录下创建 META/services/com.alibaba.csp.sentinel.init.InitFunc文件,然后在文件内填写InitFunc实现类的全限定类名
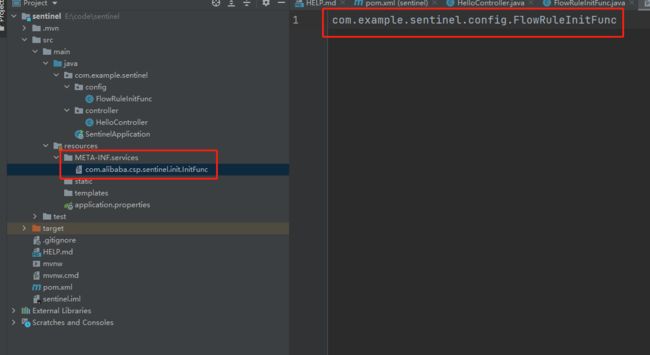
Dashboard实现流控
启动sentinel-dashboard
java -Dserver.port=7777 -Dcsp.sentinel.dashboard.server=localhost:7777 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.2.jar
将SPI扩展文件,InitFunc的实现删掉,并将资源埋点删掉,只剩下一个单纯的Controller接口
package com.example.sentinel.controller;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;/** * 测试sentinel * * @author xsl */@RestControllerpublic class HelloController { @GetMapping("/say") public String sayHello(){ return "hello sentinel"; }}
添加sentinel dashboard配置:
spring: application: name: spring-cloud-sentinel-sample cloud: sentinel: transport: dashboard: 127.0.0.1:7777
启动服务,访问say接口(只有第一次被访问后才会在dashboard看到),然后打开localhost:7777,输入账号和密码,初始账号和密码为:sentinel,主页可以看到yml配置的application.name,点击它然后点击簇点链路,找到接口点击流控,设置单机阈值1,在流控规则中可以看到刚刚添加的流控

再次快速访问say接口输出Blocked by Sentinel (flow limiting)
自定义URL限流异常
默认情况下URL触发限流之后会直接返回:Blocked by Sentinel (flow limiting),实际开发中,我们大概率都是需要返回一个Json或者直接跳转到一个降级页面,我们可以用如下方式实现。
返回json
配置一个CustomUrlBlockHandler实现UrlBlockHandler并注入到Spring的IOC容器中
package com.example.sentinel.handler;import com.alibaba.csp.sentinel.adapter.servlet.callback.UrlBlockHandler;import com.alibaba.csp.sentinel.slots.block.BlockException;import org.springframework.stereotype.Service;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;/** * 限流处理 * * @author xsl */@Servicepublic class CustomUrlBlockHandler implements UrlBlockHandler { @Override public void blocked(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, BlockException e) throws IOException { httpServletResponse.setHeader("Content-Type", "application/json;charset=UTF-8"); String message = "{\"code\":9999, \"msg\":\"访问人数太多啦\"}"; httpServletResponse.getWriter().write(message); }}
重启服务,重新访问接口,在dashboard设置流控规则,发现返回的就是一个json了
{"code":9999, "msg":"访问人数太多啦"}
跳转降级页面
通过spring.cloud.sentinel.servlet.block-page={url}
URL资源清洗
接口流控时,统计的时url在rest风格下,类似于"/clean/{id}“这样的接口统计时就有问题了,因为它统计的是不同的id下的请求量,且sentinel的默认资源阈值是6000,多出的不会生效。对这种情况我们可以通过UrlCleaner接口实现资源清洗,也就是对”/clean/{id}“这类的url统一归集到”/clean/*"下
package com.example.sentinel;import com.alibaba.csp.sentinel.adapter.servlet.callback.UrlCleaner;import org.springframework.stereotype.Service;/** * 资源清洗配置 * * @author xsl */@Servicepublic class CustomerUrlCleaner implements UrlCleaner { @Override public String clean(String s) { if (s.startsWith("/clean/")){ return "/clean/*"; } return s; }}
Sentinel集成Nacos实现动态流控规则
由于Sentinel存储路由规则是在内存中的,应用重启后会丢失,而Nacos是有自己的数据库或者可以Mysql数据库的,Sentinel提供了动态数据源的支持,当然他提供的不仅仅是nacos的支持,对consul、Zookeeper、Redis、Nacos、Apollo、etcd等都有支持。
依赖:
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-dependenciesartifactId> <version>Greenwich.RELEASEversion> dependency> <dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-sentinelartifactId> <version>2.1.1.RELEASEversion> dependency> <dependency> <groupId>com.alibaba.cspgroupId> <artifactId>sentinel-datasource-nacosartifactId> <version>1.7.0version> dependency>
创建一个rest接口用于测试
package com.example.sentinelnacos.controller;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;/** * @author xsl */@RestControllerpublic class DynamicController { @GetMapping("/dynamic") public String dynamic(){ return "hello dynamic rule"; }}
加入配置
spring: application: name: spring-cloud-sentinel-dynamic cloud: sentinel: transport: dashboard: 127.0.0.1:7777 datasource: ## 支持nacos、redis、apollo、zk、file - nacos: server-addr: 127.0.0.1:8848 data-id: ${spring.application.name}-sentinel-flow groud-id: DEFAULT_GROUP ## 支持json和xml data-type: json ## 规则是什么类型 flow、degrade、param-flow、gw-flow rule-type: flow
登录控制台,创建流控配置规则

登录sentinel-dashboard就可以看到配置的流控规则已经被加载了

分布式事务
CAP定理
C:(Consistency)指一致性,数据在多个副本之间能够保持一致的特性(严格的一致性)
A:(Availability)指可用性,非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
P:(Partition tolerance)指分区容错性,分布式系统出现网络分区的时候,仍然能够对外提供服务。
CAP理论证明,在分布式系统中,要么满足CP,要么满足AP,为什么呢,因为网络通信往往是不可靠的,一些网络延时、异常、波动非常常见,所以P的分区容错性是必须要保证的,这是能提供服务的前提,所以只能在C和A之间做选择。
CP:放弃高可用性,实现强一致性,前面的XA协议就是这种方案。
AP:放弃强一致性,实现最终一致性,这是互联网公司解决分布式数据一致性问题的主要选择。
BASE理论
BASE理论是从CAP定理中的AP衍生出来的思想,核心思想在于通过牺牲数据强一致性换取高可用性,他有如下几个特征:
- Basically Avaiable(基本可用):分布式系统在出现故障的时候,允许损失一部分可用性,保证核心功能可用。
- Soft State(软状态):允许系统中的数据存在中间状态,这个状态不影响系统的可用性,也就是允许系统中不同节点的数据副本之间的同步存在延时。
- Eventually Consistent(最终一致性):中间状态的数据在经过一段时间后,会达到最终的数据一致性。
术语名词
TM:事务管理器(事务协调者)
RM:资源管理器
XA协议
两阶段提交协议
事务执行流程:
- 准备阶段:TM通知RM准备分支事务,记录事务日志,并告知事务管理器结果。
- 提交/回滚阶段:如果资源管理器在准备阶段都明确返回成功,则事务管理器向所有的资源管理器发起事务提交指令完成数据变更,反之回滚。
缺点:
- 同步阻塞:所有参与者都是同步阻塞的,对于任何一次指令都需要有明确的响应才能继续进行下一步,否则处于阻塞状态,占用资源一直被锁定。
- 网络波动:由于网络波动只有部分RM收到Commit,导致数据不一致
三阶段提交协议
- 询问阶段:TM向RM发送事务执行请求,询问是否可以完成指令,参与者只需回答是与不是即可。
- 准备阶段:TM根据RM询问的反馈情况决定是否继续执行,若可,则向所有参与者发送preCommit请求,RM收到请求写redo和undo log,但是不commit,然后ack响应等待TM下一步通知。
- 提交/回滚阶段:若每个RM都准备成功,则事务提交;任意一个返回失败,则回滚。
相比二阶段三阶段的不同点:
- 增加了询问,尽早发现无法执行操作而减少资源和时间的浪费
- 在准备阶段之后,TM和RM都都引入了超时机制,一旦超时,继续提交事务(因为这种情况默认认为成功的可能性较大)
TCC补偿型方案
TCC(Try-Confirm-Cancel)补偿性方案是指将一个业务拆分成三部分,T为对数据的校验或资源的预留,第一个C为确认真正的执行任务,操作T步骤预留的资源,第二个C为取消执行,释放T步骤预留的资源。
举个例子,比如通过账户余额购买一个理财产品1000元,这里涉及到了两个事务操作,一个是扣账户余额A,一个是扣理财产品的可申购金额B。
那么A可以分为这三步:
- T A账户余额冻结1000元,但是不扣余额的钱,可以理解成可以在一个位置记录这个账户这笔购买冻结了1000元
- Confirm A账户清空冻结金额,余额扣除1000元
- Cancel 删除该笔冻结1000元
B可以分为这三步:
- T 理财产品冻结1000元,可以和A做类似的理解
- Confirm 理财产品可申购金额扣除1000元
- Cancel 解除冻结
然后在购买理财产品时Application先通知TCC框架,通知A B两个服务做冻结,也就是执行T接口,若在Try阶段都执行成功,则通知Confirm,但任意一个T未成功,则通知所有执行Cancel。由于服务与TCC服务之间通过网络通信,而网络汪汪是不可靠的(波动)等原因,TCC服务需要做失败重试,所以TCC暴露的接口都需要满足幂等性。
可靠性消息最终一致性方案
可靠性消息最终一致性方案其实就是Base理论的实践,也就是事务的问题咱不做强一致性要求,而只是发送一个消息到消息队列中等待消费者消费。
还是拿TCC补偿性中的例子来说
A步骤成了这样:
begin transaction;
try{
sendMsg();
update money;
commit transaction;
}catch(Exception e){
rollback transaction;
}
但是这样sendMsg动作发送之后,发生异常更新钱可以回滚,但是消息却撤不回了,如果对换呢,可能会有Mq发送消息已经成功,但是网络有问题超时响应而导致事务回滚了但是消息却发出去了。针对这种情况我们可以使用RocketMQ事务消息,具体的执行逻辑如下:
- 生产者发送一个事务消息到消息队列上,消息队列只记录这条消息的数据,此时消费者无法消费这条消息
- 生产者执行具体的业务逻辑,完成本地事务操作
- 生产者根据本地事务的执行结果发送一条确认消息给消息队列服务器,如果本地事务执行成功,则发送一个commit消息,表示消息可以被消费了,否则,消息队列服务器会把第一步存储的消息删除
- 如果生产者在执行本地事务的过程中因为某些情况一直未给消息队列服务器发commit消息,那么消息队列会定时主动回查生产者获取本地事务结果,根据回查结果来决定该消息是否需要投递给消费者
- 消费者消费消息之后ack消息给队列服务器,消息消费成功。