Linux-正则三剑客
目录
一、正则简介
1.正则表达式分两类:
2.正则表达式的意义
二、Linux三剑客简介
1.文本处理工具,均支持正则表达式引擎
2.正则表达式分类
3.基本正则表达式BRE集合
4.扩展正则表达式ere集合
三、grep
1.简介
2.实践
3.贪婪匹配
四、sed
1.sed简介
2.输出文件的第2,3行的内容
5.替换
6.写入对应行
7.实例
五、awk
1.awk基础
2.举例
3.NF和NR
4.字符串占位
5.awk参数
6.awk变量
7.awk的分隔符
8.awk的变量
一、正则简介
1.正则表达式分两类:
基本正则表达式:BRE
扩展正则表达式:ERE
2.正则表达式的意义
- 处理大量字符串
- 处理文本
通过特殊符号的辅助,可以让linux管理员快速过滤、替换、处理所需要的字符串、文本,让工作高效。
通常Linux运维工作,都是面临大量带有字符串的内容,如:
- 配置文件
- 程序代码
- 命令输出结果
- 日志文件
正则表达式应用广泛,Linux仅受三剑客(sed、awk、grep)支持,其他命令无法使用
通配符是大部分普通命令都支持的,用于查找文件或者目录,而正则表达式 是通过三剑客命令在文件(数据流)中过滤内容。
二、Linux三剑客简介
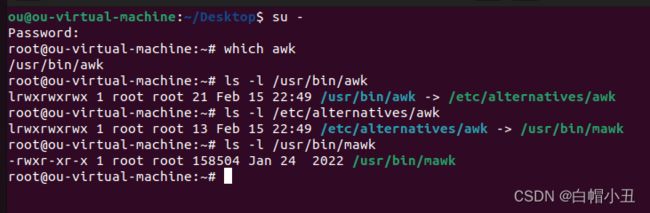
1.文本处理工具,均支持正则表达式引擎
- grep:文本过滤工具,(模式:pattern)工具
- sed:stream editor,流编辑器:文本编辑工具
- awk:Linux的文本报告生成器(格式化文本),Linux上是gawk
2.正则表达式分类
Linux三剑客主要分两类
- 基本正则表达式(BRE)
BRE对应元字符有^$.[]*
- 扩展正则表达式(ERE)
ERE在BRE基础上,增加上 (){}?+|等字符
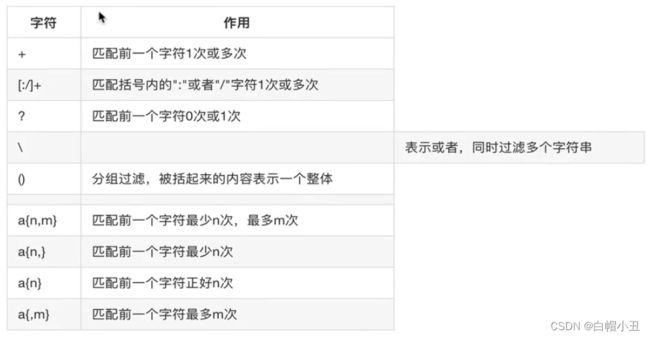
3.基本正则表达式BRE集合
- 匹配字符
- 匹配次数
- 位置锚定


4.扩展正则表达式ere集合
扩展正则表达式必使用grep -E才能生效
三、grep
1.简介
作用:文本搜索工具,格局用户指定的"模式(过滤条件)"对目标文本逐行进行匹配检查,打印匹配到的行
模式:有正则表达式的元字符及文本字符所编写出的过滤条件;
语法:

2.实践
cat /etc/passwd > ./passwd.txt grep -i "root" passwd.txt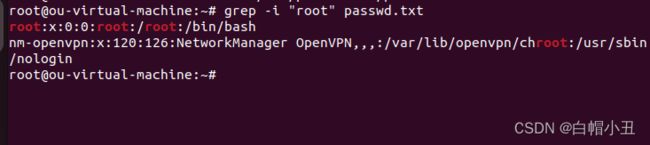
反选
grep -i "root" passwd.txt -v -c
root@ou-virtual-machine:~# grep -i "root" passwd.txt -v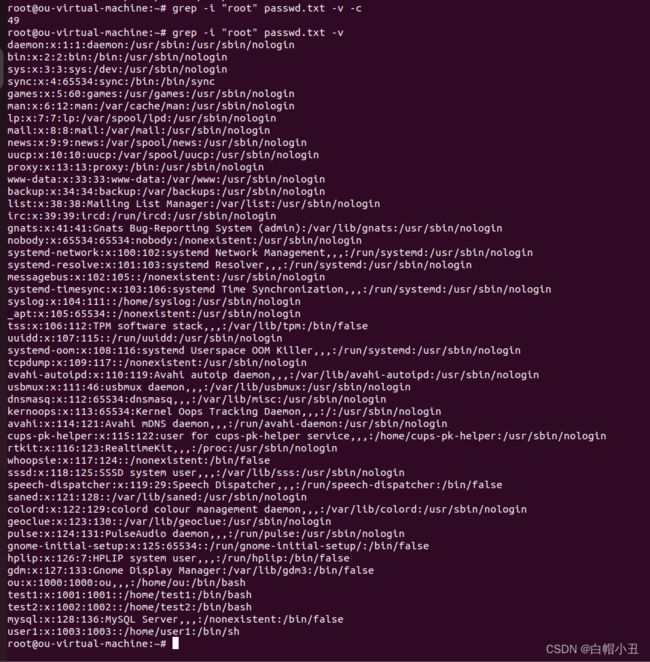
找空行
grep '^$' passwd.txt -n
过滤注释行
grep '^#' passwd.txt -v -n
或者
grep '^[a-zA-Z]' passwd.txt -n
匹配w+前一个任意字符,或者w+后一个任意字符
grep 'w.' passwd.txt
grep '.w' passwd.txt
3.贪婪匹配
grep ".*e" passwd.txt
+号匹配1次或者多次
grep -E "w+" passwd.txt -n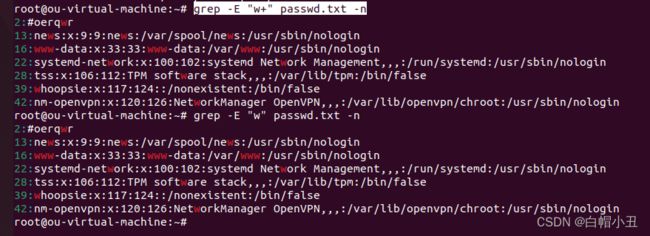
复合实例

四、sed
1.sed简介
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换 文本内容的强大工具。
常用功能包括结合正则表达式对文件实现快速增删改查,其中穿功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。

由于sed还会输出没匹配到的字符行,我们需要-n来处理

常用参数
sed的内置命令字符用于文件进行不同的操作功能,如对文件增删改查
sed常用内置命令字符:

sed匹配范围

2.输出文件的第2,3行的内容
p为打印的意思
sed -n '2,3p' passwd.txt
如果不加-n那么不匹配的也会输出

3.匹配root字符串
sed -n '/root/p' passwd.txt
4.删除的问题
sed '/root/d' passwd.txt
但是查看文件却发现root字符串所在的行还在文件内

这里是因为sed删除的 是内存中的内容,并没有真正对文件内容进行操作。
写入文件加-i

5.替换
sed "s/www/nihaoshijie/g" passwd.txt.bak
但文件内容还是没用修改

-i参数写入文件内
sed "s/www/nihaoshijie/g" passwd.txt.bak -i
多次替换
sed -e "s/nihaoshijie/www/g" -e "s/test/wwwwwwwwwwwwwwwwwwwwww/g" passwd.txt.bak -i
6.写入对应行
sed "2aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" passwd.txt.bak -i
每行都加个分隔符
sed "a ----------------------------------------------------" passwd.txt.bak -i
7.实例
拿出ip和子网掩码和广播地址
ifconfig ens33 | sed "2p" -n | sed "s/^.*inet//"
五、awk
awk更像一门编程语言,支持条件判断、数组、循环等功能
三剑客的各个特点
- grep,擅长单纯的查找或匹配文本内容
- awk,更适合编辑、处理匹配到的文本内容
- sed,更适合格式化文本内容,对文本进行复杂处理
三个命令称之为Linux的三剑客
1.awk基础
awk语法:
awk [option] 'pattern[action]' file...
awk 参数 '条件动作' 文件
2.举例
空格作为分隔符
$0 代表一整行
$1 代表第一列
$2 代表第二列
...
awk '{print $1}' 1.txt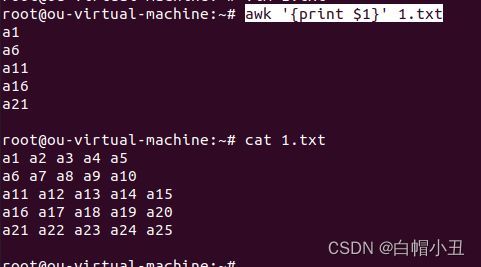

3.NF和NR
awk '{print $NF}' 1.txt
awk '{print $NR}' 1.txt
NR显示文件第五行
awk 'NR==5' 1.txt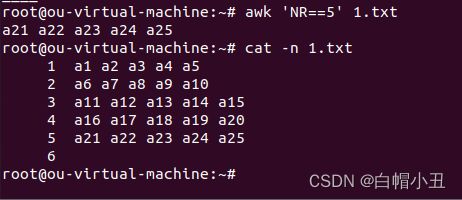
NR显示文件第二行到第五行
root@ou-virtual-machine:~# awk 'NR==2,NR==5' 1.txt
a6 a7 a8 a9 a10
a11 a12 a13 a14 a15
a16 a17 a18 a19 a20
a21 a22 a23 a24 a25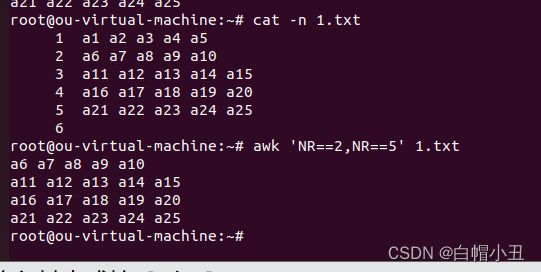
4.字符串占位
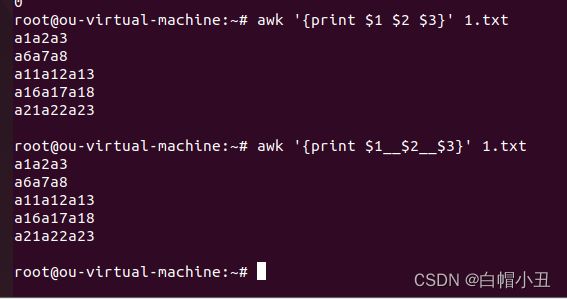
输出默认不带分隔符
root@ou-virtual-machine:~# awk '{print $1 $2 $3}' 1.txt
a1a2a3
a6a7a8
a11a12a13
a16a17a18
a21a22a23
root@ou-virtual-machine:~# awk '{print $1__$2__$3}' 1.txt
a1a2a3
a6a7a8
a11a12a13
a16a17a18
a21a22a23
逗号会默认加空格分隔符
root@ou-virtual-machine:~# awk '{print $1,$2,$3}' 1.txt
a1 a2 a3
a6 a7 a8
a11 a12 a13
a16 a17 a18
a21 a22 a23

"字符串"分隔符
root@ou-virtual-machine:~# awk '{print "1 List: "$1,"2 List: "$2,"3 List: "$3}' 1.txt
1 List: a1 2 List: a2 3 List: a3
1 List: a6 2 List: a7 3 List: a8
1 List: a11 2 List: a12 3 List: a13
1 List: a16 2 List: a17 3 List: a18
1 List: a21 2 List: a22 3 List: a23
1 List: 2 List: 3 List:

5.awk参数

前面的文件分隔符是空格,awk自动识别空格作为分隔符
但是如果我们用其他的分割符,那么awk并不会自动识别
root@ou-virtual-machine:~# cat 1.txt
a1 a2 a3 a4 a5
a6 a7 a8 a9 a10
a11 a12 a13 a14 a15
a16 a17 a18 a19 a20
a21 a22 a23 a24 a25
root@ou-virtual-machine:~# cat 1.txt.bak
a1#a2#a3#a4#a5
a6#a7#a8#a9#a10
a11#a12#a13#a14#a15
a16#a17#a18#a19#a20
a21#a22#a23#a24#a25
root@ou-virtual-machine:~# awk "{print $1}" 1.txt.bak
a1#a2#a3#a4#a5
a6#a7#a8#a9#a10
a11#a12#a13#a14#a15
a16#a17#a18#a19#a20
a21#a22#a23#a24#a25

通过-F来修改识别分隔符
cat 1.txt.bak | awk -F"#" '{print $1}'
小写f
root@ou-virtual-machine:~# echo '"{print}"' > 1
root@ou-virtual-machine:~# awk -f 1 1.txt
a1 a2 a3 a4 a5
a6 a7 a8 a9 a10
a11 a12 a13 a14 a15
a16 a17 a18 a19 a20
a21 a22 a23 a24 a25

6.awk变量
取出本机的ip
第一步先取出ifconfig第二行的数据
ifconfig | awk 'NR==2{print $0}'![]()
ifconfig | awk 'NR==2{print $0}' | awk '{print $2}'
7.awk的分隔符
- 输入分隔符,awk默认是空格,空白字符,变量名是FS
- 输出分隔符,OFS
FS输入分隔符
awk逐行处理文本的时候,以输入分隔符为准,把文本切成多个片段,默认符号是空格
当我们处理特殊文件,没用空格的时候,可以自由指定分隔符
awk -F '#' '{print $1}' 1.txt.bak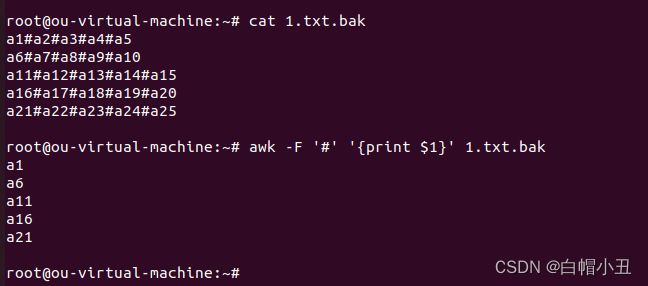
修改默认输出符
root@ou-virtual-machine:~# awk -F '#' '{print $1,$2,$4}' 1.txt.bak
a1 a2 a4
a6 a7 a9
a11 a12 a14
a16 a17 a19
a21 a22 a24
root@ou-virtual-machine:~# awk -F '#' -v OFS=': ' '{print $1,$2,$4}' 1.txt.bak
a1: a2: a4
a6: a7: a9
a11: a12: a14
a16: a17: a19
a21: a22: a24
: :
root@ou-virtual-machine:~#
8.awk的变量
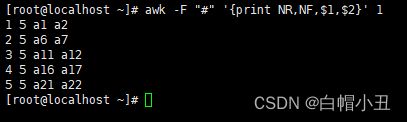
NR、NF和FNR变量
[root@localhost ~]# awk -F "#" '{print NR,NF,$1,$2}' 1
1 5 a1 a2
2 5 a6 a7
3 5 a11 a12
4 5 a16 a17
5 5 a21 a22


NR和FNR的区别
[root@localhost ~]# awk -F "#" '{print FNR,$1,$2}' 1 1
1 a1 a2
2 a6 a7
3 a11 a12
4 a16 a17
5 a21 a22
1 a1 a2
2 a6 a7
3 a11 a12
4 a16 a17
5 a21 a22
[root@localhost ~]# awk -F "#" '{print NR,$1,$2}' 1 1
1 a1 a2
2 a6 a7
3 a11 a12
4 a16 a17
5 a21 a22
6 a1 a2
7 a6 a7
8 a11 a12
9 a16 a17
10 a21 a22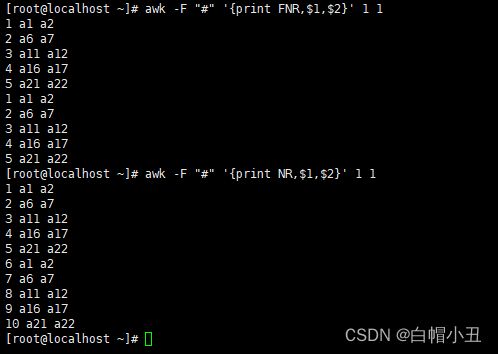
ORS和RS
[root@localhost ~]# awk -F "#" '{print RS="-------",$1,$2}' 1
------- a1 a2
------- a6 a7
[root@localhost ~]# awk -F "#" '{print ORS="-------",$1,$2}' 1
------- a1 a2-------------- a6 a7-------------- a11 a12-------------- a16 a17-------------- a21 a22-------[
[root@localhost ~]#
FILENAME
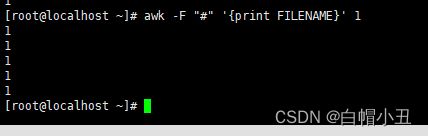
数组
默认数组
[root@localhost ~]# awk "{print ARGV[0],$0}" 1
awk 0
awk 0
awk 0
awk 0
awk 0
[root@localhost ~]# awk "{print ARGV[1]}" 1
1
1
1
1
1
[root@localhost ~]# awk "{print ARGV[2]}" 1
[root@localhost ~]# awk '{print ARGV[0],ARGV[1],ARGV[2]}' 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
awk 1 1
[root@localhost ~]#
自定义变量
[root@localhost ~]# awk -v myname='o' 'BEGIN{print "myname=",myname}'
myname= o
[root@localhost ~]#
9.awk格式化输出
print和printf的区别
printf需要自定义格式
awk '{printf $0}' 1
a1#a2#a3#a4#a5a6#a7#a8#a9#a10a11#a12#a13#a14#a15a16#a17#a18#a19#a20a21#a22#a23#a24#a25[root@localhost ~]#
[root@localhost ~]#
![]()
自定义格式
[root@localhost ~]# printf "%s\n" a b c d e
a
b
c
d
e
[root@localhost ~]# awk 'BEGIN{printf "%s\n%s\n",1,2,3,4,5}'
1
2
区别
