python+selenium
一、安装selenium库并安装浏览器驱动
需要的自取,但是建议官方
链接: https://pan.baidu.com/s/1D5FdFs2iz070t2h9ZhZ99g?pwd=cfqx 提取码: cfqx 复制这段内容后打开百度网盘手机App,操作更方便哦

1.1安装命令
C:\Users\33612>pip3 install selenium
Collecting selenium
Downloading selenium-4.9.1-py3-none-any.whl (6.6 MB)
---------------------------------------- 6.6/6.6 MB 63.0 kB/s eta 0:00:00
Collecting urllib3[socks]<3,>=1.26
Downloading urllib3-2.0.2-py3-none-any.whl (123 kB)
---------------------------------------- 123.2/123.2 kB 61.3 kB/s eta 0:00:00
Collecting trio~=0.17
Downloading trio-0.22.0-py3-none-any.whl (384 kB)
---------------------------------------- 384.9/384.9 kB 79.4 kB/s eta 0:00:00
Collecting trio-websocket~=0.9
Downloading trio_websocket-0.10.2-py3-none-any.whl (17 kB)
Collecting certifi>=2021.10.8
Downloading certifi-2023.5.7-py3-none-any.whl (156 kB)
---------------------------------------- 157.0/157.0 kB 88.6 kB/s eta 0:00:00
Collecting attrs>=19.2.0
Downloading attrs-23.1.0-py3-none-any.whl (61 kB)
---------------------------------------- 61.2/61.2 kB 74.0 kB/s eta 0:00:00
Collecting sortedcontainers
Downloading sortedcontainers-2.4.0-py2.py3-none-any.whl (29 kB)
Collecting async-generator>=1.9
Downloading async_generator-1.10-py3-none-any.whl (18 kB)
Collecting idna
Downloading idna-3.4-py3-none-any.whl (61 kB)
---------------------------------------- 61.5/61.5 kB 63.2 kB/s eta 0:00:00
Collecting outcome
Downloading outcome-1.2.0-py2.py3-none-any.whl (9.7 kB)
Collecting sniffio
Downloading sniffio-1.3.0-py3-none-any.whl (10 kB)
Collecting cffi>=1.14
Downloading cffi-1.15.1-cp311-cp311-win_amd64.whl (179 kB)
---------------------------------------- 179.0/179.0 kB 66.7 kB/s eta 0:00:00
Collecting exceptiongroup
Downloading exceptiongroup-1.1.1-py3-none-any.whl (14 kB)
Collecting wsproto>=0.14
Downloading wsproto-1.2.0-py3-none-any.whl (24 kB)
Collecting pysocks!=1.5.7,<2.0,>=1.5.6
Downloading PySocks-1.7.1-py3-none-any.whl (16 kB)
Collecting pycparser
Downloading pycparser-2.21-py2.py3-none-any.whl (118 kB)
---------------------------------------- 118.7/118.7 kB 117.6 kB/s eta 0:00:00
Collecting h11<1,>=0.9.0
Downloading h11-0.14.0-py3-none-any.whl (58 kB)
---------------------------------------- 58.3/58.3 kB 61.5 kB/s eta 0:00:00
Installing collected packages: sortedcontainers, urllib3, sniffio, pysocks, pycparser, idna, h11, exceptiongroup, certifi, attrs, async-generator, wsproto, outcome, cffi, trio, trio-websocket, selenium
Successfully installed async-generator-1.10 attrs-23.1.0 certifi-2023.5.7 cffi-1.15.1 exceptiongroup-1.1.1 h11-0.14.0 idna-3.4 outcome-1.2.0 pycparser-2.21 pysocks-1.7.1 selenium-4.9.1 sniffio-1.3.0 sortedcontainers-2.4.0 trio-0.22.0 trio-websocket-0.10.2 urllib3-2.0.2 wsproto-1.2.0
[notice] A new release of pip available: 22.3.1 -> 23.1.2
[notice] To update, run: python.exe -m pip install --upgrade pip
//最后两行提醒你升级pip,在命令行中运行python.exe -m pip install --upgrade pip即可
1.2 驱动下载地址(选择与浏览器相近版本的驱动)
1.2.1下载chrome浏览器
1.2.2 下载浏览器驱动https://chromedriver.storage.googleapis.com/index.html
解压
Starting ChromeDriver 112.0.5615.28 (e01c41304994a51cedfb5f0fac134687ba993bfb-refs/branch-heads/5615@{#494}) on port 9515
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
1.2.3双击就会弹出上面的界面,为解压后的驱动添加环境变量D:\Mysoftware\chromedriver_win32即可使用
1.2.4csdn博主,他是把它放到python的scripts文件夹下了,我觉得原理一样都是为了让驱动被找到,添加环境变量全局可用
https://blog.csdn.net/flyskymood/article/details/124158706?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168618764216800184118071%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=168618764216800184118071&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-124158706-null-null.142
运行这个python文件
from selenium import webdriver
// Chrome浏览器
driver = webdriver.Chrome()
弹出chrome即代表安装成功
闪退(不加下面这行代码就会)
input()
闪退的其他解决方法
1.csdn搜索selenium自动化
2.把chromedrive_win32放在python文件夹
3.在系统变量path添加环境变量
4.chromedriver与当前浏览器版本差距过大,下载相近版本
【Python + Selenium Web自动化 2022更新版教程 自动化测试 软件测试 爬虫】 https://www.bilibili.com/video/BV1Z4411o7TA/?p=3&share_source=copy_web
二、pycharm的相关使用问题
2.1: 在pycharm中运行需要在termianl中执行pip3 install selenium 重新安装?
ModuleNotFoundError: No module named ‘selenium’
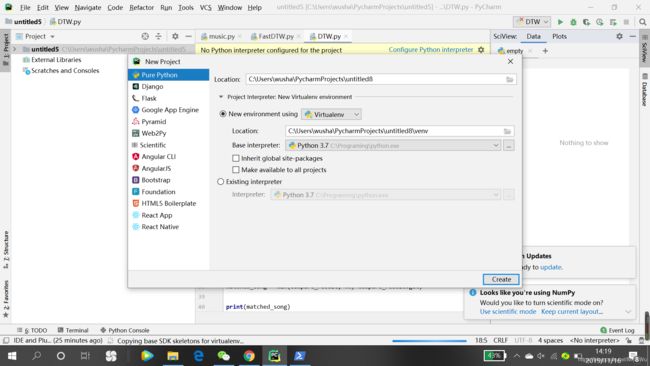
创建项目之前一定要勾选Inherit global site-package和Make available to all projects这两个!这样我们通过cmd安装在Python的Scripts文件夹中的库就可以直接导入Interpreter了!


用来快捷显示类,方法,变量的用法CTRL+b
快速导入包ALT+ENTER
跳转到指定的行和列CTRL+G
三、元素定位
面试题:如果元素定位不到,你会怎么去分析
-
元素是否加载完成
-
页面是否存在frame或者iframe
-
元素是否不可用(disabled)不可读(readonly)不可见(hidden)或者(style=“display none”)
-
是否是动态元素(有前提条件),动态div层,自定义控件(select)
前提:元素必须唯一
八种定位方式:id name,xpath,css,link_text,partial_link_text,class_name,tag_name
3.1 id,name link_text,partial_link_text用法
from selenium import webderiver
from selenium.webdriver.common.by import By
deriver = webderiver.Chrome//这里浏览器首字母必须大写
driver.implicitly_wait(10)//等待十秒,用来给浏览器缓冲内容,让程序有执行的时间。如果代码结尾是input()则不用缓冲,这个不会关闭浏览器
deriver.get("https://www.baidu.com")//用来打开网址
deriver.find_element(By.ID,"kw").send_keys("码上教育")//ID用法与name用法一样 [By.[属性名],["属性值"]]
deriver.find_element(By.ID,"su").click()//
deriver.find_element(By.LINK_TEXT,"新闻").click()//匹配文本并点击
deriver.find_element(By.PARTIAL_LINK_TEXT,"新").click()//匹配部分文本并点击(匹配范围更大)
3.2 xpath
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
#在检查元素界面,定位元素后右击copy-copy fullxpath,
driver.find_element(By.XPATH,"/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input").send.keys("码上教育")
driver.find_element(By.XPATH,"//span/div/").send.keys("码上教育")
绝对路径:用一个/开头
相对路径:用一个//开头
相对路径://form/span/input
相对路径+索引定位://form/span[2]/input
相对路径+属性定位:
//input[@autocomplete=‘off’]多个属性可以使用 and或者or
//input[@atuocomplete=‘off’ and @class=‘s_ipt’]单个属性无法定位,可以增添定位属性
相对路径+部分属性:
属性以什么开头://input[starts-with(@autocomplete,’o’)]
属性以什么结尾://input[substring(@autocomplete,2)=‘ff’]
属性包含://input[contains(autoplete,’f’)]
相对路径+通配符://*[@*=‘’kw’]
相对路径+文本://span[text()=‘按图片搜索’]
##基于https://www.baidu,com
四、unittest单元测试
1,新建一个类继承(unittest.testcase)
2.导入unittest包
3,新建一个以test_开头的用例
unittest运行的方式
1.通过命令行去运行
在terminal台内输入
python -m unittest test_01_login.py
2.通过main方法去运行测试用例
在右上角编辑配置里,添加新配置(python文件不用编写内容),使用当前配置,点击三角型按钮,运行当前文件。不要用鼠标或者快捷键与运行。
五、设计模式
po:关键字驱动
po:page object,主要放页面对象层模型
京东:仓库、分类、日用品、电脑、文具
分三类:
1.基础层:base,主要放的是selenium的原生方法,如:打开浏览器,加载网页,定位元素
2.页面对象层:pageobject,主要放页面的元素以及页面动作,一个页面就是一个类
3.测试用例层:testcase,存放一个测试用例及测试数据

关键字千万不要打错!!!!
线性脚本
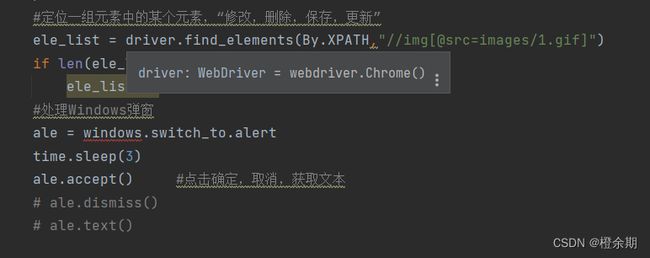

driver.switch_to.frame("menu-frame") #寻找框架,即向定位元素上面寻找标签
driver.find_element(By.LINK_TEXT, "商品列表").click()
driver.switch_to.default_content() #出框架
driver.switch_to.frame("main-frame") #进框架,值应该是id的值否则进不去框架!!!!!!!!!!!!!
#处理下拉框
sel = Select(driver.find_element(By.NAME,"brand.id"))
sel.Select_by_index(1) #通过下标选中,下标从0开始
sel.Select_by_value(10) #通过值
sel.Select_by_visible_text("诺基亚") #通过文本
#定位一组元素中的某个元素,“修改,删除,保存,更新”
ele_list = driver.find_elements(By.XPATH,"//img[@src=images/1.gif]")
if len(ele_list)>1:
ele_list(0).click()
#处理Windows弹窗
ale = windows.switch_to.alert
time.sleep(3)
ale.accept() #点击确定,取消,获取文本
# ale.dismiss()
# ale.text()
非线性脚本

