经典网络解析(四) transformer | 自注意力、多头、发展
文章目录
- 1 背景
-
- 1.1 困境
- 1.2 基本架构
- 2 嵌入层
- 3 编码器部分
-
- 3.1 自注意力层
- 3.2 多头注意力机制
- 3.3 LayerNorm归一化层
- 4 解码器
- 5 transformer的发展
- 6 代码
1 背景
1.1 困境
transformer可以并行训练,也是用来实现attention注意力机制
之前RNN的困境
(1)特征的有效性不够,某一时刻拿到了前一时刻的所有特征,特征没有聚焦点
(2)训练效率不够,必须得等前一时刻训练出来之后才能进行这一时刻的训练,而我们的transformer通过矩阵运算实现并行
注意力模型其实有很多
transformer是做的比较好的一类
1.2 基本架构
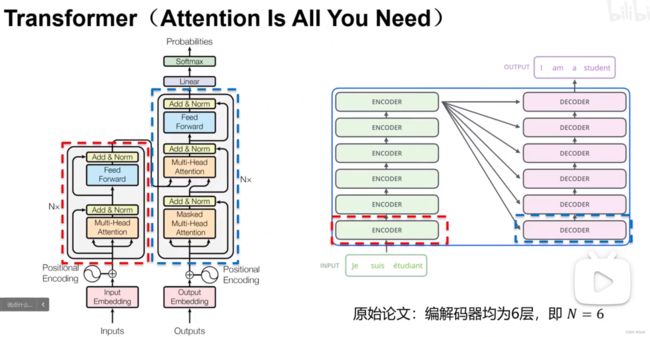
Encoder和Decoder构架
Encoder部分把原语言特征抽取出来 ,送到Decoder
堆叠多层Encoder和Decoder为什么?
特征提取能力可以更强
transformer
Encoder 抽取特征 多层累加形式(所以输入输出维度不变)例子中都是[L.512]维度
比如有十个单词,那么经过Encoder以后就会输出十个特征,输入序列长度等于输出序列长度
Decoder 根据特征翻译出来找到对应的层
左边编码器堆叠六层 N=6
右边解码器堆叠六层 N=6
2 嵌入层
input Embeding 嵌入层 把单词降为成512维 所以输入L个单词 512维 则输入为L×512 维,
将ont-hot 表示映射到连续空间上,可以用nn.Embedding
embeding嵌入层 一般进行降维 将到d_model (一般512维度)
通过一个变换将单词的one-hot表示映射到连续空间上(降维)可以使用nn.Embedding实现
比如我们翻译L个单词,词典大小10000,则利用独热编码后,我们的inputs维度为[L,10000]
然后送入embeding层,变为[L,512]
3 编码器部分
我们想要把上下文信息编码进去,就是通过自注意力实现的
比如吃苹果,苹果手机
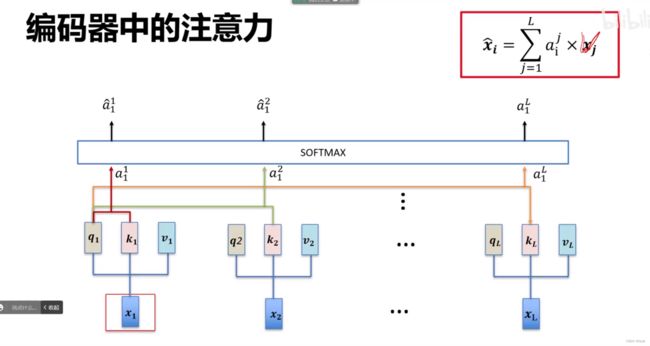
3.1 自注意力层
之前的注意力就是建立权重
采用如下方式产生权重
每个单词经过3个线性变换生成3个向量q,k,v ,用每个单词自己的q和其他单词的k做点乘,得到ai 然后再softmax 转换为权值大小,则最后的翻译参考的x等于权值×对应的v累加
最后再直接输出
输出 翻译得到单词的概率
注意这里的每一个xi都有一个输出,而且都利用了上下文的信息
具体计算的时候
(1)x1怎么到 q1,k1,v1呢,是通过三个矩阵Q1,K1,V1 这三个矩阵是可学习的,x1×Q1得到q1 ,x1×K1得到k2 ……其他同理,进而决定了我们的每一个x对应的q,k,v是多少?
(2)然后对于每一个单词的qi,和其余所有单词包括自己的k做点积,得到一组score ,然后除以维度开根号(主要解决有些输出过大有些输出过小数据分布方差过大的情况)然后再softmax操作就可以得到权重
(3)然后对于每一个单词的输出,将每一个单词的vi和所有其余单词的(2)得到的权重做点乘然后累加
以上所有操作都可以矩阵并行运算
3.2 多头注意力机制
经过一组参数,多头注意力就是学习多个矩阵Q,K,V,一模一样的操作,(实际上就是多组Q,K,V)得到八组, 形成八组结果
然后连接contact层,再经过一个线性变换层得到最后的结果
3.3 LayerNorm归一化层
注意LayerNorm和batch Norm的区别
batch Norm是一个数据集批次之间的操作
而layerNorm是我们的一组句子提取特征后进行的操作
残差 减均值除方差 前向神经网络,批归一化
全连接 做特征提取,加强非线性操作
4 解码器
解码器的输入是已经翻译过的语言特征,并且中途会插入原语言特征(来自编码器)
源语言的K,V传入Decoder
利用原语言提取的特征,加上已经翻译过的特征进行预测未翻译的语言的特征
通过Mask 就可以并行的训练了,已经翻译过来的内部关系
attention 就是权重
为什么用sin,cos位置编码
主要是可以记住相对位置,也可以记住绝对位置
5 transformer的发展
GPT
BERT模型 完形填空
GPT-2 GPT-3
探索了无监督的
完形填空,预测下一个词
Non-local
ViT 沿用Bert
6 代码
class Transformer(nn.Module):
''' A sequence to sequence model with attention mechanism. '''
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True):
super().__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
# Encoder
self.encoder = Encoder(
n_src_vocab=n_src_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=src_pad_idx, dropout=dropout)
# Decoder
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=trg_pad_idx, dropout=dropout)
# 最后的linear输出层
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
# xavier初始化
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
assert d_model == d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'
self.x_logit_scale = 1.
if trg_emb_prj_weight_sharing:
# Share the weight between target word embedding & last dense layer
self.trg_word_prj.weight = self.decoder.trg_word_emb.weight
self.x_logit_scale = (d_model ** -0.5)
if emb_src_trg_weight_sharing:
self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
def forward(self, src_seq, trg_seq):
# mask
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
# encoder & decoder
enc_output, *_ = self.encoder(src_seq, src_mask)
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
# final linear layer得到logit vector
seq_logit = self.trg_word_prj(dec_output) * self.x_logit_scale
return seq_logit.view(-1, seq_logit.size(2))