IOTDB介绍
IoTDB介绍

全球最大的开源软件基金会 Apache 软件基金会于北京时间 2020 年 9 月 23 日宣布 Apache IoTDB 毕业成为 Apache 顶级项目!

简介
IoTDB (Internet of Things Database) 是由清华大学主导的 Apache 孵化项目,是一款聚焦工业物联网、高性能轻量级的时序数据管理系统,也是一款开源时序数据库,为用户提供数据收集、存储和分析等服务。作为一款时序数据库,IoTDB的相关竞品有 KairosDB,InfluxDB,TimescaleDB等。
IoTDB 提供端云一体化的解决方案,在云端,提供高性能的数据读写以及丰富的查询能力,针对物联网场景定制高效的目录组织结构,并与 Apache Hadoop、Spark、Flink 等大数据系统无缝打通;在边缘端,提供轻量化的 TsFile 管理能力,端上的数据写到本地 TsFile,并提供一定的基础查询能力,同时支持将 TsFile 数据同步到云端。

经基准测试表明 IoTDB 的读写性能均优于现有的时序数据库 KairosDB,InfluxDB,TimescaleDB、OpenTSDB 等。
不同数据库遇到的问题
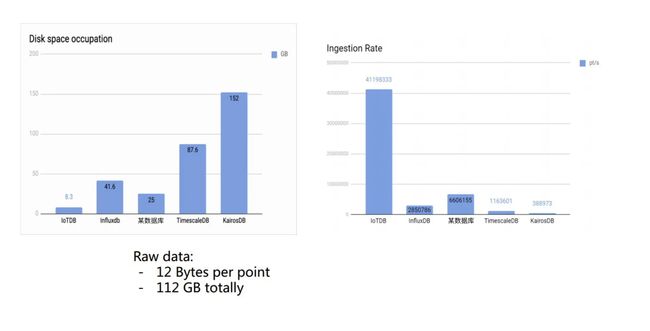
磁盘空间占用&摄取率对比
查询延迟对比

什么是时序数据?
转载于:https://my.oschina.net/u/3374539/blog/3163843
个人理解时序数据就是基于时间维度的同一个物体或概念的值构成的一个序列数据。
在传统关系型数据库中,例如 MySQL,我们通常会放置一个自增的 id 列作为主键标识,如下:
| Id | 人名 | 体温 | 测量时间 |
|---|---|---|---|
| 1 | 张三 | 36.5 | 2022-03-16 9:00:10 |
| 2 | 李四 | 36.9 | 2022-03-16 9:00:10 |
| 3 | 王五 | 36.2 | 2022-03-16 9:00:10 |
| 4 | 张三 | 36.3 | 2022-03-16 9:22:50 |
| 5 | 张三 | 36.9 | 2022-03-16 10:45:23 |
上面的表结构就是一个时序数据,将表结构做个变形更容易理解:
| 时间戳 | 人名 | 体温 |
|---|---|---|
| 1647392410 | 张三 | 36.5 |
| 1647392410 | 李四 | 36.9 |
| 1647392410 | 王五 | 36.2 |
| 1647393770 | 张三 | 36.3 |
| 1647398723 | 张三 | 36.9 |
如果把时间作为一个唯一键对齐展示,能够更像时序数据一些,这也是 IoTDB 中查询结果的展示方式:
| 时间戳 | 张三 | 李四 | 王五 |
|---|---|---|---|
| 1647392410 | 36.5 | 36.9 | 36.2 |
| 1647393770 | 36.3 | NULL | NULL |
| 1647398723 | 36.9 | NULL | NULL |
IoTDB 功能特点

IoTDB 完成了上述问题中的几乎所有功能,而且可以灵活对接多生态,高性能优势等。
基本框架
应用
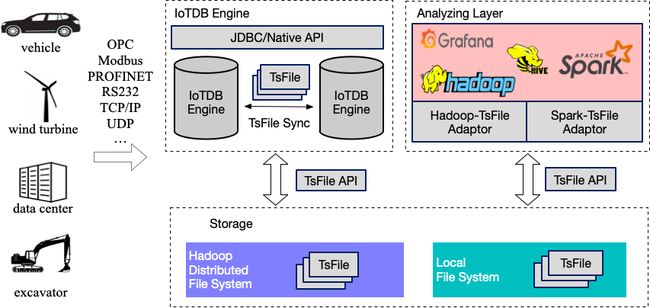
其中,灰色部分是IotDB的组件,数据可以通过JDBC/Native API 写入IoTDB,多个IoTDB之间的数据通过TsFile Sync来实现同步,IotDB Egine通过TsFile的API讲数据写成TsFile的格式,支持的存储方式有本地存储和HDFS。TsFile支持hadoop、Hive、Spark直接进行大数据分析。可以看到IoTDB的核心部分就是TsFile,承载了IoTDB多个实例间的数据同步和数据分析。
上面的图,在逻辑上被分为三部分,其中:
- Engine 是完整的数据库进程,负责 sql 语句的解析,数据写入、查询、元数据管理等功能。
- Storage 是底层存储结构,类似于Mysql 的 idb 文件
- Analyzing Layer 是各种连接器。
Engine 和 Storage 中主要包含:
- IoTDB Engine,也就是代码中的
Server模块. - Native API,他是高效写入的基石,代码中的
Session模块 - JDBC,传统的 JDBC 连接调用方式,代码中的
JDBC模块 - TsFile,这是IoTDB整个数据库的一个特色所在,传统的数据库如果使用 Spark 做离线分析,或者 ETL 都需要通过数据库进程对外读取,而 IoTDB 可以直接迁移文件,省去了来回转换类型的开销。TsFile 提供了两种读写模式,一种基于 HDFS,一种基于本地文件。
架构

IoTDB使用客户端服务器的架构,客户端向服务端发起读或写的请求,服务端将请求转发到相应的模块,例如写入请求转发到StorageEgnine, 读请求转发到QueryEngine,其他还有schema manager 和Administration模块。
模块
从IoTDB的源码,我们可以得知IoTDB项目目前包含30个模块。现对IoTDB所有的模块进行大致分类,可划分为Client,IoTDB Engine(JDBC,Server,TsFile),Grafana,Distribution 以及各种生态的连接器这几类。
Client模块介绍
- cli:基于Java的客户端接口。
- client-cpp:基于C++的客户端接口。
- client-py:基于Python的客户端接口。
IoTDB Engine模块介绍
- server:对应框架中的IoTDB Engine。
- session:它是高效写入的基石,对应框架中的Native API。
- jdbc:传统的 JDBC 连接调用方式,对应框架中的JDBC。
- tsfile:这是整个数据库的一个特色所在,传统的数据库如果使用 Spark 做离线分析,或者 ETL 都需要通过数据库进程对外读取,而 IoTDB 可以直接迁移文件,省去了来回转换类型的开销。在Storage中TsFile 提供了两种读写模式,一种基于 HDFS,一种基于本地文件。框架中的TsFile。
各种生态及其生态连接器模块介绍
-
flink-iotdb-connector、flink-tsfile-connector:flink连接器。flink流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。
-
grafana-connector、grafana-plugin:grafana连接器和grafana插件。grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。
-
hadoop:tsfile的HDFS读写方式。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。
-
hive-connector:hive连接器。hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
-
spark-iotdb-connector、spark-tsfile:spark连接器和spark处理tsfile。Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。
-
zeppelin-interpreter:Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。
-
server-rpc:服务端rpc。
-
compile-tools.thrift:编译工具-thrift,thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。
-
thrift、thrift-cluster、thrift-influxdb、thrift-sync:Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用。它通过一个代码生成引擎联合了一个软件栈,来创建不同程度的、无缝的跨平台高效服务,可以使用C#、C++(基于POSIX兼容系统)、Cappuccino、Cocoa、Delphi、Erlang、Go、Haskell、Java、Node.js、OCaml、Perl、PHP、Python、Ruby和Smalltalk。
其他模块介绍
- antlr:使用antlr4 自定义语法。antlr4是一款强大的语法生成器工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件。
- cluster:集群管理。
- integration:集群集成。
- cross-tests:一个测试模块。
- distribution:使用assembly插件自定义各个模块的打包方式。
- example:各种连接器连接实例代码。
- metrics:metrics可以为你的代码的运行提供无与伦比的洞察力。作为一款监控指标的度量类库,它提供了很多模块可以为第三方库或者应用提供辅助统计信息, 比如Jetty, Logback, Log4j, Apache HttpClient, Ehcache, JDBI, Jersey, 它还可以将度量数据发送给Ganglia和Graphite以提供图形化的监控。
- openapi:使用openapi3接口规范。
TsFile
TsFile(TimeSeriresFile) 是 IoTDB 的底层数据文件,一种专门为时间序列数据设计的列式文件格式,整体以树状目录结构组织,一个 TsFile 里可存储多个设备的数据,每个设备包含多个 measurment(指标)。
TsFile文件概览

一个完整的 TsFile 是由图中的几大块组成,图中的数据块与索引块之间使用 1 个字节的分隔符 2 来进行分隔,这个分隔符的意义是当 TsFile 损坏的时候,顺序扫描 TsFile 时,依然可以判断下一个是 MetaData 是什么东西。
1、识别符(Magic)
现在各种软件五花八门,很多软件都拥有自己的文件格式用来存储数据内容,但当硬盘上文件非常多的时候如何有效的识别是否为自己的文件,确认可以打开呢?经常用 windows 系统的朋友可能会想到用扩展名,但假如文件名丢失了,那我们如何知道这个文件是不是能被程序正确访问呢?
这时候通常会使用一个独有的字符填充在文件开头和结尾,这样程序只要访问 1 个固定长度的字符就知道这个文件是不是自己能正常访问的文件了,当然,TsFile 作为一个数据库文件,肯定需要在这个识别符上精心打造一番,它看起来是这样:
(decimal) 84 115 70 105 108 101
(hex) 54 73 46 69 6c 65
(ASCII) T s F i l e
2、文件版本(Version)
再精妙的设计也难免产生一些问题,那么就需要升级,那么文件内容也一样,有时候当你的改动特别大了,就会出现完全不兼容的两个版本!·TsFile 中采用了 6 个字节来保存文件版本信息,当前 0.9.x 版本看起来就是这样:
(decimal) 48 48 48 48 48 50
(hex) 30 30 30 30 30 32
(ASCII) 0 0 0 0 0 2
3、数据块
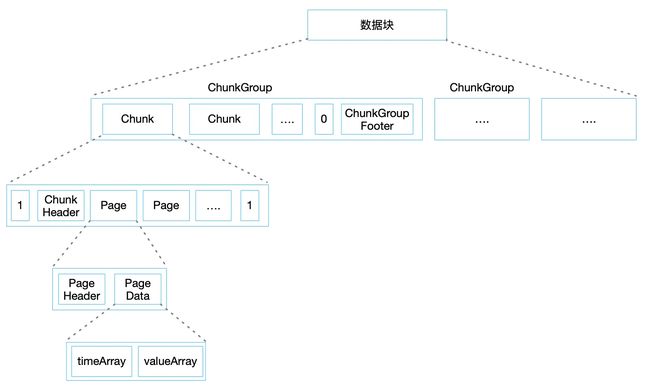
名词解释
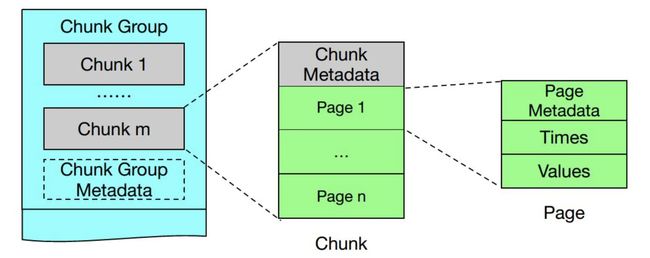
这是一个数据被刷入磁盘后的缩减版 TsFile 格式,我们还拿上面的数据举例,用来直观的解释 TsFile 中出现的一些名词,假如我的数据为:
| 时间戳 | 人名 | 体温 | 心率 |
|---|---|---|---|
| 1580950800 | 张三 | 36.5 | 70 |
| 1580950800 | 李四 | 36.9 | 80 |
| 1580950800 | 王五 | 36.7 | 100 |
| 1580950911 | 王五 | 36.6 | 90 |
上面的数据刷新到磁盘上后会对应关系如下:
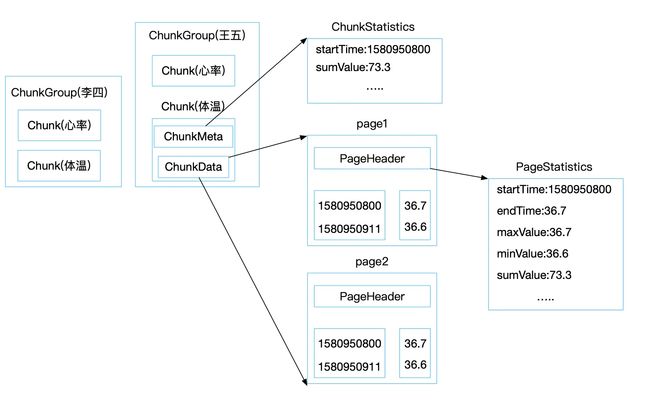
ChunkGroup 中包含多个 Chunk,Chunk 中包含多个 Page ,Page 中 包含多个 时间点和数据项
ChunkGroup
文件的数据块中包含了多个 ChunkGroup ,它代表了设备(逻辑概念上的一个集合)一段时间内的数据,在 IoTDB 中称为 Device。
在实际的文件中,ChunkGroup是由多个 Chunk 和一个 ChunkGroupFooter 组成。其中最后一个 Chunk 的结尾和 ChunkGroupFooter 之间使用 1 个字节的分隔符 0 来做区分,ChunkGroupFooter 没有什么具体作用。
Chunk
一个 ChunkGroup 中包含了多个 Chunk,它代表了测点数据(逻辑概念上的某一类数据的集合,如体温数据),在 IoTDB 中称为 Measurement。
在实际文件中 Chunk 是由 ChunkHeader 和多个 Page 组成,并被 1 个字节的分隔符 1 包裹。ChunkHeader中主要保存了当前 Chunk 的数据类型、压缩方式、编码方式、包含的 Pages 占用的字节数等信息。
ChunkStatistics
ChunkStatistics 是保存的是Chunk当中数据的预聚合信息。
Page
Page 中存储的是具体数据,包含一个时间序列、一个值序列。一个 Chunk 中包含多个 Page,它是一个数据组织方式,数据大小被限制在 64K 左右。
在实际文件中由 PageHeader 和 PageData 组成。其中 PageHeader 里主要保存了当前 page 里的一些预聚合信息,包含了最大值、最小值、开始时间、结束时间等。
PageHeader的存在是非常有意义的,因为当某些特定场景的读时候,不必要解开 page 的数据就能够得到结果,比如说
selece 体温 from 王五 where time > 1647392410, 当读到 PageHeader 的时候,找到 startTime 和 endTime 就能判断是否可以使用当前 page。
PageData
一个 Page 中包含了一个 PageData,里面有两个数组:时间数组和值数组,且这两个数组的下标是对齐的,也就是时间数组中的第一个对应值数组中的第一个。
举个例子:
timeArray: [1,2,3,4]
valueArray: ['a', 'b', 'c', 'd']
在page中就是这样保存的数据,其中 1 代表了时间 1970-01-01 08:00:00 后的 1 毫秒,对应的值就是 ‘a’。
PageStatistics
PageStatistics 是保存的是Page当中数据的预聚合信息。
TsFile文件结构
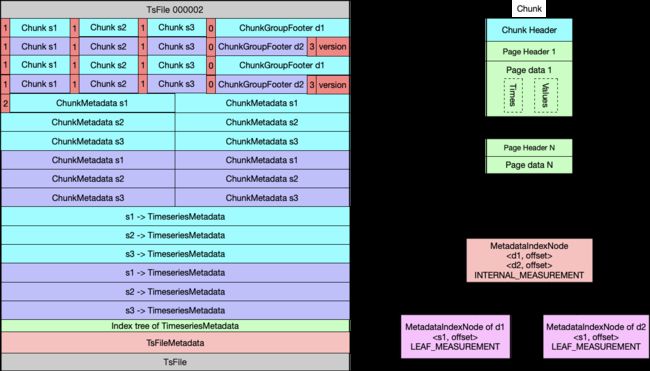
TsFile 整体是一个多级映射表,TsFileMetaData ==> TimeSeriesMetadata ==> ChunkMetadata ==> Chunk。
TsFileMetadata描述整个 TsFile ,包含格式版本信息,MetadataIndexNode的位置,总的 chunk 数等元数据信息。MetadataIndexNode包含多个TimeSeriesMetadata,每个TimeSeriesMetadata指向一个设备的元数据信息ChunkMetadata列表;ChunkMetadata指向ChunkHeader位置,并对应最终的Chunk Data。
查询引擎
IoTDB 内置查询引擎负责所有用户命令的解析、生成计划、交给对应的执行器、返回结果集。IoTDB 通过查询引擎提供了 JDBC 访问 API,简单易用。
IoTDB> CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN
IoTDB> CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status) values(100,true);
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,20.71)
IoTDB> SELECT status FROM root.ln.wf01.wt01
+-----------------------+------------------------+
|Time|root.ln.wf01.wt01.status|
+-----------------------+------------------------+
|1970-01-01T08:00:00.100| true|
|1970-01-01T08:00:00.200| false|
+-----------------------+------------------------+
Total line number = 2

元数据管理
IoTDB 的元数据模型采用树状结构组织,一个实例包含多个 Storage Group 存储组(类似于 Namespace、Database 的概念),一个 Storage Group 里包含多个 Device 实体,每个 Device 包含多个 Measurement 物理量 , Measurement 对应的时间序列数据最终存储在 TsFile Chunk 里。另外,为了方便数据过期,每个 Stroage Group 的数据会以时间范围的形式切分存储,默认以周为单位,使用不同的目录存储。

以风电场物联网场景为例
IoTDB 采用树形结构定义数据模式,以从 ROOT 节点到叶子节点的路径来命名一个时间序列,层次间以“.”连接。
例如,下图最左侧路径对应的时间序列名称为ROOT.ln.wf01.wt01.status。

物理量、实体、存储组、路径
物理量(Measurement)
物理量,也称工况或字段(field),是在实际场景中检测装置所记录的测量信息,且可以按一定规律变换成为电信号或其他所需形式的信息输出并发送给 IoTDB。在 IoTDB 当中,存储的所有数据及路径,都是以物理量为单位进行组织。
实体(Entity)
一个物理实体,也称设备(device),是在实际场景中拥有物理量的设备或装置。在 IoTDB 当中,所有的物理量都有其对应的归属实体。
存储组(Storage group)
一组物理实体,用户可以将任意前缀路径设置成存储组。如有 4 条时间序列root.ln.wf01.wt01.status, root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware, root.ln.wf02.wt02.status,路径root.ln下的两个实体 wt01, wt02可能属于同一个业主,或者同一个制造商,这时候就可以将前缀路径root.ln指定为一个存储组。未来root.ln下增加了新的实体,也将属于该存储组。
一个存储组中的所有实体的数据会存储在同一个文件夹下,不同存储组的实体数据会存储在磁盘的不同文件夹下,从而实现物理隔离。
注意 1:不允许将一个完整路径(如上例的
root.ln.wf01.wt01.status) 设置成存储组。注意 2:一个时间序列其前缀必须属于某个存储组。在创建时间序列之前,用户必须设定该序列属于哪个存储组(Storage Group)。只有设置了存储组的时间序列才可以被持久化在磁盘上。
一个前缀路径一旦被设定成存储组后就不可以再更改这个存储组的设定。
一个存储组设定后,其对应的前缀路径的祖先层级与孩子及后裔层级也不允许再设置存储组(如,root.ln设置存储组后,root 层级与root.ln.wf01不允许被设置为存储组)。
存储组节点名只支持中英文字符、数字、下划线和中划线的组合。例如root. 存储组_1-组1 。
路径(Path)
路径(path)是指符合以下约束的表达式:
path
: layer_name ('.' layer_name)*
;
layer_name
: wildcard? id wildcard?
| wildcard
;
wildcard
: '*'
| '**'
;
我们称一个路径中由 '.' 分割的部分叫做层级(layer_name)。例如:root.a.b.c为一个层级为 4 的路径。
下面是对层级(layer_name)的约束:
-
root作为一个保留字符,它只允许出现在下文提到的时间序列的开头,若其他层级出现root,则无法解析,提示报错。 -
除了时间序列的开头的层级(
root)外,其他的层级支持的字符如下:- 中文字符
"\u2E80"到"\u9FFF" "_","@","#","$""A"到"Z","a"到"z","0"到"9"
- 中文字符
-
除了时间序列的开头的层级(
root)和存储组层级外,层级还支持使用被`或者"符号引用的特殊字符串作为其名称。需要注意的是,被引用的字符串不可带有.字符。下面是一些合法的例子:
root.sg."select"."+-from="."where""where"""."$" # 6 个层级分别为 root, sg, select, +-from, where"where", $
root.sg.````.`select`.`+="from"`.`$` # 6 个层级分别为 root, sg, `, select, +-"from", $
-
层级 (
layer_name) 不允许以数字开头,除非层级 (layer_name) 以或"` 引用。 -
特别地,如果系统在 Windows 系统上部署,那么存储组层级名称是大小写不敏感的。例如,同时创建
root.ln和root.LN是不被允许的。
路径模式(Path Pattern)
为了使得在表达多个时间序列的时候更加方便快捷,IoTDB 为用户提供带通配符*或**的路径。用户可以利用两种通配符构造出期望的路径模式。通配符可以出现在路径中的任何层。
*在路径中表示一层。例如root.vehicle.*.sensor1代表的是以root.vehicle为前缀,以sensor1为后缀,层次等于 4 层的路径。
**在路径中表示是(*)+,即为一层或多层*。例如root.vehicle.device1.**代表的是root.vehicle.device1.*, root.vehicle.device1.*.*, root.vehicle.device1.*.*.*等所有以root.vehicle.device1为前缀路径的大于等于 4 层的路径;root.vehicle.**.sensor1代表的是以root.vehicle为前缀,以sensor1为后缀,层次大于等于 4 层的路径。
*在路径中表示一层。例如root.vehicle.*.sensor1代表的是以root.vehicle为前缀,以sensor1为后缀,层次等于 4 层的路径。
**在路径中表示是(*)+,即为一层或多层*。例如root.vehicle.device1.**代表的是root.vehicle.device1.*, root.vehicle.device1.*.*, root.vehicle.device1.*.*.*等所有以root.vehicle.device1为前缀路径的大于等于 4 层的路径;root.vehicle.**.sensor1代表的是以root.vehicle为前缀,以sensor1为后缀,层次大于等于 4 层的路径。
注意:
*和**不能放在路径开头。