Redis学习第九天
今天是Jedis!作者的Redis在游戏本上,但是Java的IDEA总是下载不了,所以只能作为概念听一听了,目前无法做到实操。
Jedis概念

Jedis实操
首先要保证redis的服务器开启,然后引入jedis依赖,最后通过服务器的IP和端口创建一个Jedis类的对象。该对象能够使用redis的基本操作。
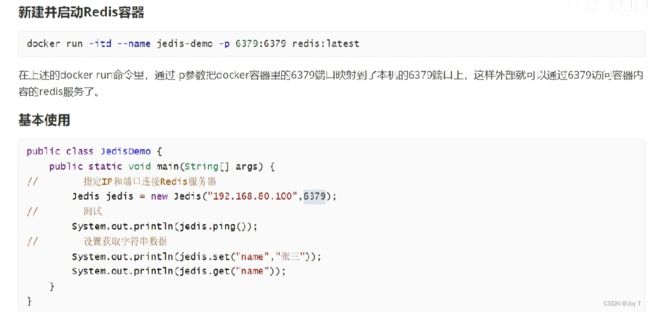
jedis.ping()输出PONG字符串,就说明连接成功。还有其他指令:
对于事务操作,需要使用Transaction类的对象,接收jedis.multi()方法的返回值。

Jedis连接池
在数据库相关操作中,可以使用连接池连接多个资源。在频繁使用数据库进行操作时,可以直接从连接池中获取数据,用完该资源后不关闭而是直接归还到池中,无需每次都做新的申请。使用JedisPoolConfig对象管理配置,最终的连接池类是JedisPool。
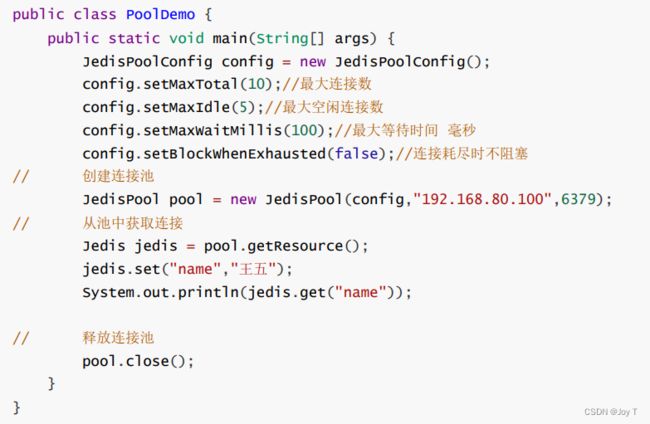
不设置的时候是有默认值的!使用pool.getResource对象

注意列表对象的lpush是不断把新的元素添加到链表的头部,rpush是不断把新元素添加到链表的尾部,建议平常使用rpush,这个不同决定了lindex决定的元素(没有rindex)。
有序集合需要使用score分数进行排序!
Redis与Mysql整合
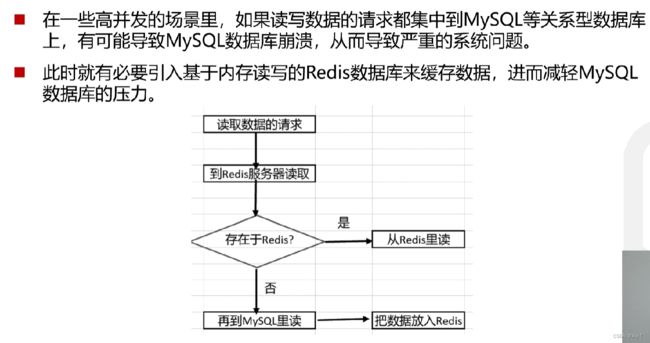
通常在传统数据库的基础上通过使用内存型数据库完成缓存操作。通常存放热点数据,如果redis里有,就从redis上读取数据。这就是缓存器的作用,与主存-CPU之间的cache原理一致。
首先在容器中安装mysql环境,比较简单作者不展示。就是需要进行一些权限、密码等配置。
期间老师的思想非常值得学习:
Jedis连接池只需要执行一次,所以把所有的JedisPool创建语句放在static{ }静态代码块中。在Java中,静态代码块(也称为静态初始化器)是在类加载到JVM时执行的,且只执行一次。静态代码块主要用于初始化静态成员变量。这样设计的好处是:
- 效率:避免每次需要
Jedis对象时都重新配置和创建一个新的JedisPool。- 资源管理:一个应用中通常只需要一个
JedisPool实例,这样可以更有效地复用和管理Redis连接。

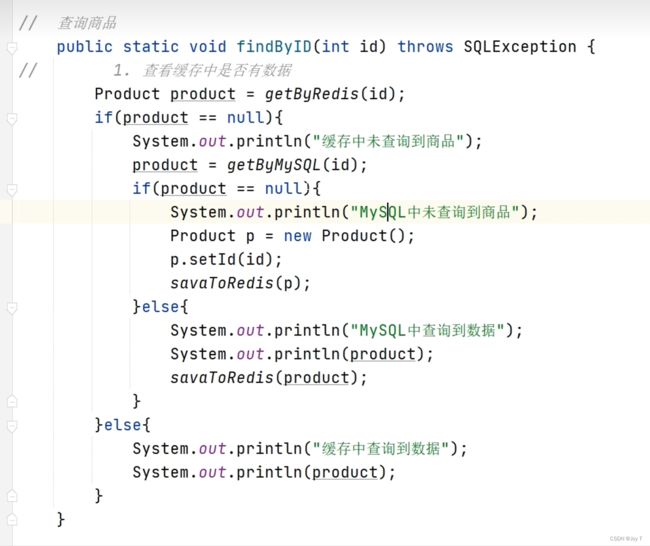
其实最终的理念就是上图。首先判断缓存中是否有数据,这是通过查询redis得到的。老师的代码还可以改进一下,作者认为redis数据是会大量复现的(否则也不会使用redis),所以最好是首先判断if (product != null),这样的可以更快地对redis需要复现的数据进行读取。
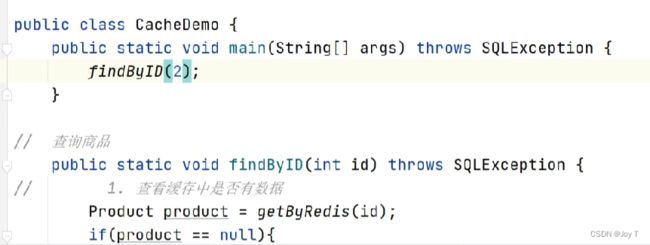
还需要有一些注意的点:上面的判断/读写代码只是针对于商品product的。底层mysql存储的是product,redis存储的也是hash表,加上前缀product:id表明键的信息。

是否进行其他操作是需要通过如上图CasheDemo类的方法调度。可以通过ID获取,也可以定义其他类,把读取product类的方法改成findProductByID()就好。而实现这个find方法需要在CacheDemo类中定义好两类数据库的存取操作,标注为静态方法。
还可以定义存储的方法,上面是find,不涉及到mysql的存储,但是有可能涉及到redis的存储。
Redis缓存优化
缓存穿透
缓存里没有,数据库里也没有,且有大量请求发送。
数据不在缓存中,需要经过mysql数据库将数据返回给缓存,并最终存储在缓存中。但是,缓存如果一直没有相关的数据(比如id=-1这样的,有可能是恶意攻击,也有可能处于高并发过程),这时缓存就没有任何作用,因为没有有用的数据直接从缓存中可以读到,大量数据在缓存中查不到。
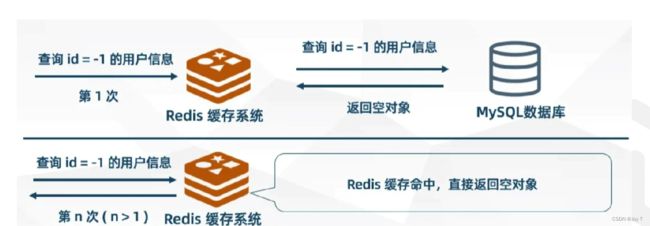
解决方案是:即使没有这个数据,系统也会分配一个这样的空对象null回应,并给到缓存中。相当于给缓存一个挡箭牌,面对大量错误数据可以不打扰Mysql数据库,直接返回一个空对象“敷衍过去”。因为这样大量快速的数据往往是相同的,所以这种方法还是比较有效的。
当Mysql也没有查到数据时,创建一个假的数据作为挡箭牌给到redis中。
缓存雪崩
之前没有考虑到缓存的有效期问题,有效期是一个必选项!存的时候就要想好它什么时候会过期,否则大量数据持续有效、积累会导致内存溢出。
并且也不能让大量数据的有效期一致,否则大量数据过期和大量数据存储同时进行时,很容易导致缓存雪崩。缓存雪崩就是缓存出现问题了,还有Redis宕机、机房停电等事件能够导致缓存雪崩:
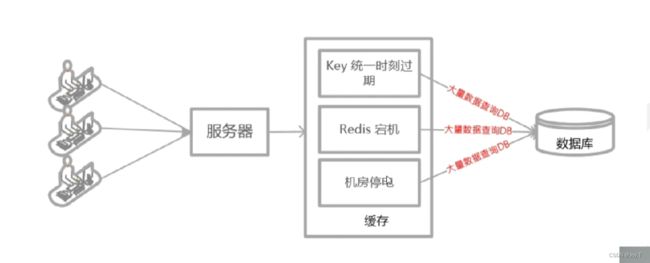
Redis宕机可以通过集群解决,机房停电可以通过云端部署异地机房减少其影响程度。
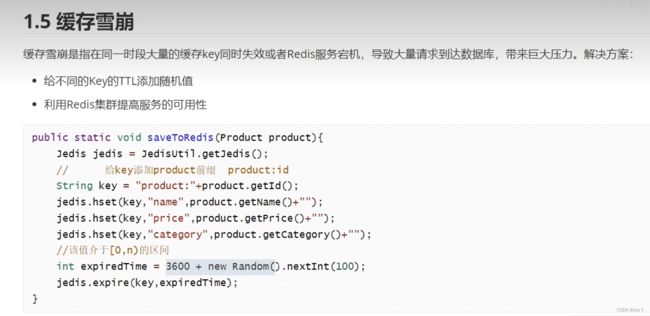
利用随机数避免大量数据同一时刻过期。
Redis限流
某一时间段只允许一定次数的请求

本质上就是两个条件,一个是一定时间内,一个是小于某一次数。
Redis整合MySql主从集群
Mysql主从集群


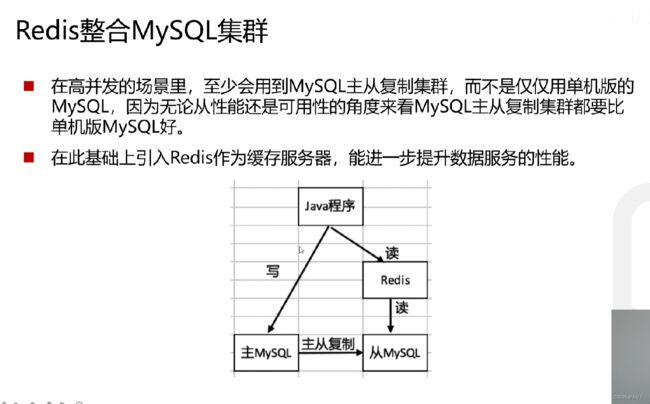
对于Mysql集群,其实都是类似的配置过程。首先下载镜像,然后分别创建主、从服务器的配置文件,主要是配置服务器id和日志文件的位置。然后就可以创建容器并运行。然后分别对主从服务器授予远程访问权限:

开始配置关系:首先进入从服务器:
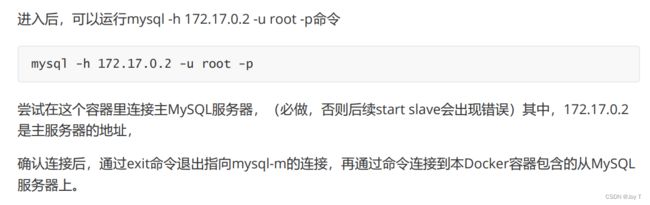
一定要首先尝试连接主Mysql服务器!否则会出现错误。尝试完之后就可以真正地进行操作了;

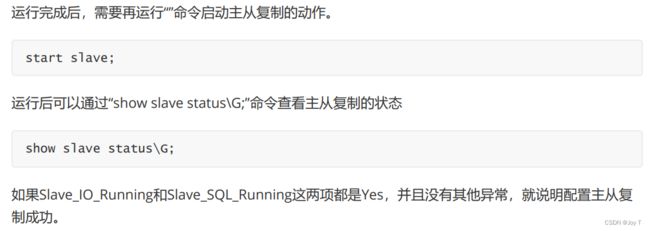
配置好状态之后,所有主服务器的写操作结果都会被自动导入从服务器中。
主从集群应用
在实际应用中如何使用主从集群呢?可以在建立连接时分清是与主服务器连接执行写操作还是与从服务器连接执行读操作。在本课程中,使用isWrite作为读写标志,在getConnection()中加上这个参数,如果isWrite=true,就把原来的url换成主服务器的地址;反之,换成从服务器的地址。对于多个从服务器甚至多个主从集群,可以考虑使用负载均衡和连接池解决。
负载均衡(Load Balancing)
负载均衡是分发网络或应用程序流量的过程,它在多个服务器(通常被称为后端或应用服务器)之间有效地分配工作负载。负载均衡的目的是优化资源使用,最大化吞吐量,最小化响应时间,同时确保无一单一服务器因为过度的工作负载而崩溃。
意义
- 提升性能: 通过分散处理和网络交通,负载均衡有助于提高响应时间和整体系统可靠性。
- 避免故障: 通过将流量分散到多个服务器,它可以防止单个服务器的过载,从而增加系统的可用性和稳定性。
- 扩展性: 它允许你简单地增加更多的服务器以处理更大的流量和工作负载。
- 灵活性和可靠性: 如果一个服务器崩溃或进行维护,流量将被重新定向到其他服务器。
应用
- 网站和云应用:对于接收大量流量的高流量网站和应用,负载均衡有助于分散流量,从而保持网站的性能和响应时间。
- 数据库:数据库的负载均衡可以确保查询分发得当,优化数据库性能。
负载均衡策略
轮询(Round Robin):
- 应用场景: 适用于所有服务器处理能力大致相等的情况。
- 优点: 简单,不需要复杂的算法实现。
- 代码示例(基于本课程的isWrite标志):
public Connection getConnection(boolean isWrite) {
if (isWrite) {
// 连接到主服务器
return connectToUrl(masterUrl);
} else {
// 负载均衡:轮询连接到从服务器
currentIndex = (currentIndex + 1) % slaveUrls.length;
return connectToUrl(slaveUrls[currentIndex]);
}
}
像不像计数器?currentIndex作者盲猜是静态变量,每次加1,实现无差别循环轮转。
随机(Random):
- 应用场景: 适用于服务器处理能力大致相等,请求处理时间不固定的场景。
- 优点: 实现简单,不需要记录状态信息。
- 代码示例:
public Connection getRandomConnection() {
int index = new Random().nextInt(slaveUrls.length);
return connectToUrl(slaveUrls[index]);
}
权重(Weighted):
- 应用场景: 适用于不同服务器的处理能力不同的情况。
- 优点: 能够更好地利用高性能的服务器。
- 代码示例:
public Connection getWeightedConnection() {
int totalWeights = 10; // 假设总权重为10
int randomWeight = new Random().nextInt(totalWeights);
if (randomWeight < 3) return connectToUrl(slaveUrls[0]); // 权重为3
else if (randomWeight < 7) return connectToUrl(slaveUrls[1]); // 权重为4
else return connectToUrl(slaveUrls[2]); // 权重为3
}
其实这个权重就是用来进行概率分配的,权重越大,其被选中的概率越大!
最少连接 (Least Connections):
概念
- 这种负载均衡策略主要是基于每个服务器当前的连接数来分配请求。
- 系统会将新的请求分配给当前连接数最少的服务器。
应用场景
- 当所有服务器的硬件配置大致相同,但每个请求处理时间不一致时,最少连接策略能够更有效地分发请求。
优点
- 确保了每个服务器的工作负载大致相等,避免了某个服务器过载而其他服务器空闲的情况。
代码示例
假设每个服务器的连接数都存储在一个数组或其他数据结构中:
public Connection getLeastConnectionsConnection() {
int index = findServerWithLeastConnections(); // 寻找当前连接数最少的服务器
return connectToUrl(slaveUrls[index]);
}
IP Hash:
- 应用场景: 适用于需要会话保持的场景。即用户与服务器交互的多个请求之间保持某种状态或数据的持续性。
- 优点: 相同IP的请求总是发到同一个服务器,可以保持用户的会话状态。
- 代码示例:
public Connection getIPHashConnection(String clientIP) {
int hash = clientIP.hashCode() % slaveUrls.length;
return connectToUrl(slaveUrls[hash]);
}
在使用多个服务器进行负载均衡时,会话保持尤为重要,因为不同的用户请求可能被路由到不同的服务器。如果一个服务器不知道另一个服务器上的会话状态,那么用户可能会在每个请求之间失去会话状态。为了避免这种情况,负载均衡器通常提供会话持久性功能,确保来自同一用户的所有请求都被路由到同一服务器,从而提供更有个性化和便捷的用户体验。
最低延迟 (Least Latency):
概念
- 最低延迟策略是根据每个服务器的响应时间来分配请求。
- 系统会将请求分发给当前响应时间最短的服务器。
应用场景
- 当服务器硬件配置不同,或者网络延迟差异较大时,最低延迟策略更为合适。
优点
- 确保了用户请求总是被发送到响应时间最短的服务器,优化了用户的访问体验。
代码示例
public Connection getLeastLatencyConnection() {
int index = findServerWithLeastLatency(); // 寻找当前延迟时间最短的服务器
return connectToUrl(slaveUrls[index]);
}
每种负载均衡策略都有自己的优缺点,选择哪种策略取决于具体的应用场景和需求。在实际应用中,还可能会使用这些策略的组合来实现更优的负载均衡效果。
Redis整合Lua脚本


其实就是脚本的作用:实现重复性工作,减少人力成本。

redis本质上就是对键和值的处理。对lua脚本中传入键、值就是为了更好地处理redis中的数据。
Springboot整合Redis
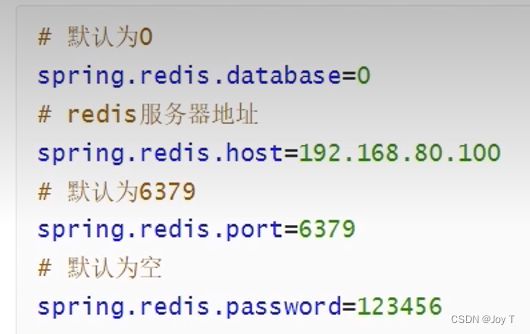
主要还是通过Spring的API:RedisTemplate支持所有Redis原生的API。与Jedis的方法有所不同,只是稍微增加了对于面向对象风格的改进,如;
redisTemplate.opsForValue().set(key,value);这个API调用的方法都是以ops开头,ForValue表示它要操作的数据类型是String字符串,先通过方法确定操作数据的类型,再调用相应的set()/get()函数。

首先要通过Resource注入属性值。

会话仓库!SpringSession:只要把Session放进来,就能自动存到Redis里。
之前的session都是单体,所以只需要存储在一台机器上的特定位置。但是现在往往都使用集群,一旦session还只存储在某一台服务器上,同一个用户很容易下一次就访问到别的机器上了,所以需要一个统一存储Session的仓库,这个仓库可以是Redis/MongoDB/JDBC,宗旨就是快!

在配置以上依赖后,再在Controller中使用Session就完全不一样了,它会自动读取配置文件连接的Redis信息,最终存储在Redis中。

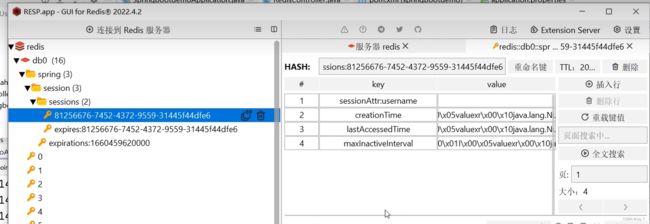
这样session就会被自动存储在Redis中,用多级目录存储,防止存储冲突。