ResNet论文总结和代码实现
论文: Deep Residual Learning for Image Recognition - AMiner
中文版:ResNet论文翻译——中英文对照+标注总结
目录
一、背景,出发点和主要工作(摘要,引言)
二、Related Work
三、Deep Residual Learning(深度残差学习)
3.1 残差学习
3.2. 快捷恒等映射(残差模块设计)
3.3 网络架构
四、实验
1. ImageNet分类任务
2. CIFAR-10分类任务
3. 在PASCAL和MS COCO上的目标检测(与其他先进网络对比实验)
五、总结
一、背景,出发点和主要工作(摘要,引言)
问题:1. 更深的神经网络更难训练。
Q:为什么更深的神经网络更难训练?
(引言)A:1. 深度神经网络中的梯度不稳定性,会造成训练过程中的梯度消失或者梯度爆炸,导致过拟合,然而,这个问题通过标准初始化和中间标准化层在很大程度上已经解决。
2. 退化问题:随着网络深度的增加,准确率达到饱和然后迅速下降。意外的是,这种下降不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差。
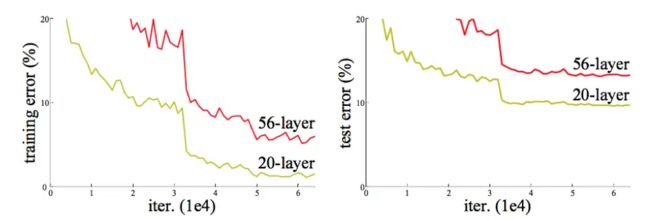
出发点:通过引入深度残差学习框架解决退化问题。
主要工作:在本文中,作者通过引入深度残差学习框架解决了退化问题。明确地让非线性层拟合残差映射,而不是希望每几个堆叠层直接拟合期望的基础映射。
形式上,将期望的基础映射(学习到有效权重的堆叠层表示为H(x))表示为H(x),我们将堆叠的非线性层拟合另一个映射(希望学习到有效权重的堆叠层最终表现为残差函数F(x) )F(x)=H(x)−x。
原始的映射重写为 F(x)+x (通过推论,只需要在堆叠层上添加快捷连接即可)。在极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过一堆非线性层来拟合恒等映射更容易。
Q:为什么希望学习到有效权重的堆叠层最终表现为残差函数F(x)?
A:当残差函数为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
研究成果:在ImageNet数据集上评估了深度高达152层的残差网络——比VGG深8倍但仍具有较低的复杂度。这些残差网络的集合在ImageNet测试集上取得了3.57%的错误率。这个结果在ILSVRC 2015分类任务上赢得了第一名,也赢得了ImageNet检测任务,ImageNet定位任务,COCO检测和COCO分割任务的第一名。
二、Related Work
1. 残差表示方面:VLAD,Fisher矢量,Multigrid方法。
2. 快捷连接方面:在某些工作中,一些中间层直接连接到辅助分类器,用于解决梯度消失/爆炸。一些工作提出了通过快捷连接实现层间响应,梯度和传播误差的方法。还有一些工作中,一个“inception”层由一个快捷分支和一些更深的分支组成。
快捷连接:是指跳过一个或多个层的连接。
三、Deep Residual Learning(深度残差学习)
3.1 残差学习
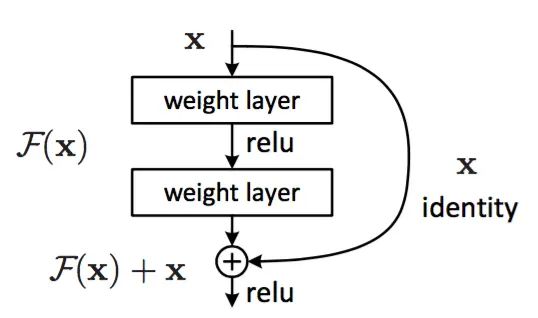
我们把 x 表示为这些层中第一层的输入,H(x) 作为这几个堆叠层要拟合(学习)的基础映射(特征)。假设多个非线性层(堆叠层)可以渐近地近似残差函数 F(x),即 H(x)−x,看作F(x)=H(x)−x,则原始函数 H(x) 变为 F(x)+x (快捷连接)。所以,我们希望学习能够学习到特征 F(x)+x 。
Q:学习到特征 F(x)+x 有什么好处?
A:之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
Q:什么是恒等映射?
现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。
参考:https://zhuanlan.zhihu.com/p/31852747
3.2 快捷恒等映射(残差模块设计)
每隔几个堆叠层采用残差学习。构建模块,如下图所示。
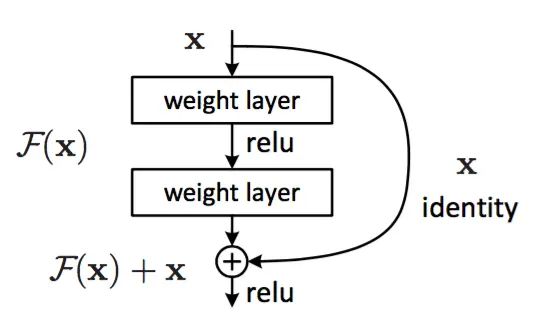
1. 恒等快捷连接
过程:输入向量先经过一个线性层 + 一个非线性层relu,再经过一个非线性层,输出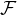 ,再通过快捷连接和各个元素相加来执行
,再通过快捷连接和各个元素相加来执行 ![]() 操作,在相加之后再经过一个非线性层relu。定义如下:
操作,在相加之后再经过一个非线性层relu。定义如下:
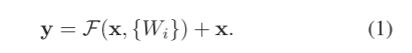
其中,x 和 y 是考虑的层的输入和输出向量,函数 ![]() 表示要学习的残差映射。
表示要学习的残差映射。![]() ,其中,σ表示ReLU函数。
,其中,σ表示ReLU函数。
2. 投影快捷连接
当输入x和的维度不相等的情况下,我们可以通过在快捷连接中增加一个线性层 ![]() 来匹配维度。定义如下:
来匹配维度。定义如下:
![]()
3.3 网络架构
使用VGG网络作为基准网络。通过步长为2的卷积层直接执行下采样,网络尾部是一个全局平均池化层 + 具有softmax的1000维全连接层。如下图所示,34-layer plain是一个加权层总数为34的简单网络,34-layer residual是一个加权层总数为34的残差网络。

在残差网络中,输入输出维度一致时,使用恒等快捷连接,输入输出维度不一致时,使用投影快捷连接。
如下表所示,给出了多种不同种类的残差网络,每层的输出大小,各层内卷积组合种类和数量,网络参数总量。
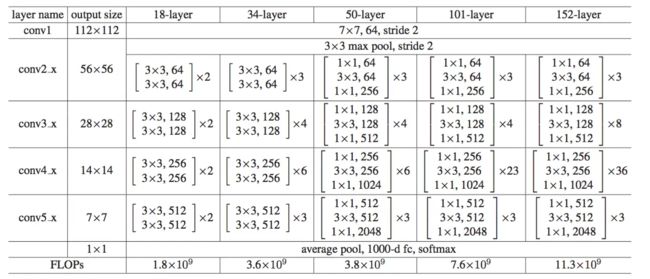
四、实验
数据集:ImageNet 2012分类数据集,CIFAR-10数据集,PASCAL VOC 2007和2012以及COCO的目标检测数据集。
对比网络:VGG-16,GoogleNet,PReLU-net,plain-34。
评估标准:错误率top-1,top-5。
1. ImageNet分类任务
简单网络:首先评估18层和34层的简单网络。表中的结果表明,较深的34层简单网络比较浅的18层简单网络有更高的验证误差。作者观察到了退化问题。
分析:这种优化难度不可能是由于梯度消失引起的。因为这些简单网络使用BN(标椎化操作)训练,这保证了前向传播信号有非零方差。作者还验证了反向传播的梯度,结果显示其符合BN的正常标准。因此既不是前向信号消失也不是反向信号消失。
作者推测深度简单网络可能有指数级低收敛特性,这影响了训练误差的降低。
残差网络:resnet基准架构与上述的简单网络相同,由下表中结果观察,残留学习的情况变了——34层ResNet比18层ResNet更好(2.8%),这表明在这种情况下,退化问题得到了很好的解决。

2. CIFAR-10分类任务
作者对CIFAR-10数据集进行了更多的研究,分别在20层,32层,44层和56层的简单网络和残差网络上,110层ResNet和1202层ResNet进行了进行训练和评估实验。实验结果如下图所示:

分析:实验表明,深度简单网络经历了深度增加,随着深度增加表现出了更高的训练误差。而ResNet设法克服优化困难并随着深度的增加展示了准确性收益。
ResNet20-1202与其他的深且窄网络对比,在CIFAR-10测试集上的分类误差,如下表所示:
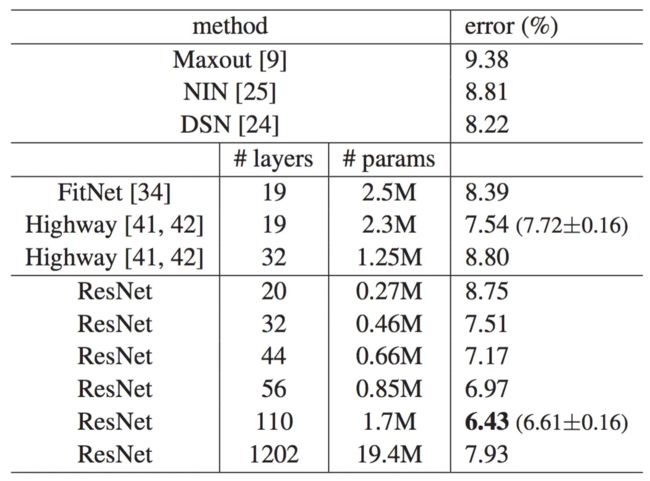
结果显示,ResNet110层网络收敛的最好。
3. 在PASCAL和MS COCO上的目标检测(与其他先进网络对比实验)
如下表所示,显示了PASCAL VOC 2007和2012以及COCO的目标检测基准结果。我们采用更快的R-CNN作为基准网络,使用ResNet-101替换VGG-16。


分析:最显著的,在COCO数据集中,COCO的标准度量指标(mAP@[.5,.95])增长了6.0%,相对改善了28%。这种收益完全是由于学习表示。
五、总结
1. ResNet是为了解决网络模型在训练过程中出现的退化问题(随着网络深度的增加,准确率达到饱和然后迅速下降)而提出的。
2. ResNet简单的来讲就是在多个堆叠层(线性层 + 非线性层)上添加一条恒等快捷连接(实际上是一个跨层的元素相加操作)。
3. 残差学习的好处在于当残差为0时,此时堆叠层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
六、代码实现
注意:恒等快速连接的位置。
import numpy as np
import torch
import torch.nn as nn
from torchsummary import summary
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
# 预训练好的模型权重
# model_urls = {
# 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
# 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
# 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
# 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
# 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
# }
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 这里就是恒等快速连接
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False):
super(ResNet, self).__init__()
self.inplanes = 64
# first section
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# second section
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# third section
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
# if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
# if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
# if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
# if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
# if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
# 观察网络结构
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = resnet18().to(device)
# 打印网络结构和参数
summary(net, (3, 256, 256))