Leetcode刷题笔记——剑指offer II (一)【整数、数组、字符串、链表】
目录
- 整数
-
- 剑指 Offer II 001. 整数除法
- 剑指 Offer II 002. 二进制加法
- 剑指 Offer II 003. 前 n 个数字二进制中 1 的个数
- 剑指 Offer II 004. 只出现一次的数字
- 剑指 Offer II 005. 单词长度的最大乘积
- 剑指 Offer II 006. 排序数组中两个数字之和
- 数组
-
-
- 剑指 Offer II 007. 数组中和为 0 的三个数
- 剑指 Offer II 009. 乘积小于 K 的子数组
- 剑指 Offer II 014. 字符串中的变位词
- 前(后)缀和
-
- 剑指 Offer II 008. 和大于等于 target 的最短子数组
- 560. 和为 K 的子数组
- 剑指 Offer II 011. 0 和 1 个数相同的子数组
- 剑指 Offer II 012. 左右两边子数组的和相等
- 304. 二维区域和检索 - 矩阵不可变
- 差分数组
-
- 1109. 航班预订统计
-
- 字符串
-
- 76. 最小覆盖子串
- 剑指 Offer II 015. 字符串中的所有变位词
- 剑指 Offer II 016. 不含重复字符的最长子字符串
- 剑指 Offer II 017. 含有所有字符的最短字符串
- 剑指 Offer II 018. 有效的回文
- 剑指 Offer II 019. 最多删除一个字符得到回文
- 剑指 Offer II 020. 回文子字符串的个数
- 28. 实现 strStr() KMP算法
- 链表
-
- 剑指 Offer II 021. 删除链表的倒数第 n 个结点
- 剑指 Offer II 025. 链表中的两数相加
- 剑指 Offer II 022. 链表中环的入口节点
- 剑指 Offer II 026. 重排链表
- 剑指 Offer II 027. 回文链表
- 剑指 Offer II 029. 排序的循环链表
整数
剑指 Offer II 001. 整数除法
给定两个整数 a 和 b ,求它们的除法的商 a/b ,要求不得使用乘号 ‘*’、除号 ‘/’ 以及求余符号 ‘%’ 。
注意:
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−231, 231−1]。本题中,如果除法结果溢出,则返回 231 − 1
示例 1:
输入:a = 15, b = 2
输出:7
解释:15/2 = truncate(7.5) = 7
示例 2:
输入:a = 7, b = -3
输出:-2
解释:7/-3 = truncate(-2.33333..) = -2
示例 3:
输入:a = 0, b = 1
输出:0
示例 4:
输入:a = 1, b = 1
输出:1
提示:
-231 <= a, b <= 231 - 1
b != 0
我的解法:位运算
((a^b)<0) == true 说明 a与b异号
int divide(int a, int b) {
int res = 0;
//bool flag = true;
//if (a > 0 && b < 0 || (a < 0 && b > 0)) flag = false;
bool flag = !((a^b)<0);
if (a != INT_MIN) a = abs(a);
if (b != INT_MIN) b = abs(b);
if (a == INT_MIN) {
if (b == 1) return flag? INT_MAX: a;
if (b == INT_MIN) return 1;
a = a + b;
a = abs(a);
res += 1;
}
if (b == INT_MIN) {
if (a == INT_MIN) return 1;
else return 0;
}
while (a >= b) {
int bound = b, tmp = 1;
while (a - bound > bound) {
bound <<= 1;// 除数左移,不断扩大2倍
tmp <<= 1; // 商左移,不断扩大2倍
}
a = a - bound;// 剩余的数
res += tmp;//
}
return flag? res: -res;
}
复杂度分析:假设n为a与b的差值
O(log n)
O(log n)
剑指 Offer II 002. 二进制加法
给定两个 01 字符串 a 和 b ,请计算它们的和,并以二进制字符串的形式输出。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "10"
输出: "101"
示例 2:
输入: a = "1010", b = "1011"
输出: "10101"
提示:
每个字符串仅由字符 '0' 或 '1' 组成。
1 <= a.length, b.length <= 10^4
字符串如果不是 "0" ,就都不含前导零。
我的方法:转换为int计算
string addBinary(string a, string b) {
if (a == "0" && a == b) return "0";
bool c = false;
string res;
int rightA = a.size() - 1, rightB = b.size() - 1;
while (c || rightA >= 0 || rightB >= 0) {
int tmp = 0;
if (c) { // 如果进位
tmp++;
c = false;
}
if (rightA >= 0) {
int intA = a[rightA] - '0';
tmp += intA;
}
if (rightB >= 0) {
int intB = b[rightB] - '0';
tmp += intB;
}
if (tmp > 1) { // 进位
tmp = tmp - 2;
c = true;
}
rightA--; rightB--;
res.push_back(tmp +'0');
}
reverse(res.begin(), res.end());
while (*(res.begin()) == '0') res.erase(res.begin());
return res;
}
复杂度分析
假设 n = max { ∣ a ∣ , ∣ b ∣ } n = \max\{ |a|, |b| \} n=max{∣a∣,∣b∣}。
- 时间复杂度:O(n) ,这里的时间复杂度来源于顺序遍历 a 和 b。
- 空间复杂度:O(1) ,除去答案所占用的空间,这里使用了常数个临时变量。
方法二:位运算
如果不允许使用加减乘除,则可以使用位运算替代上述运算中的一些加减乘除的操作。
如果不了解位运算,可以先了解位运算并尝试练习以下题目:
只出现一次的数字 II
只出现一次的数字 III
数组中两个数的最大异或值
重复的DNA序列
最大单词长度乘积
我们可以设计这样的算法来计算:
- 把 a 和 b 转换成整型数字 x 和 y,在接下来的过程中,x 保存结果,y 保存进位。
- 当进位不为 0 时
- 计算当前 x 和 y 的无进位相加结果:answer = x ^ y
- 计算当前 x 和 y 的进位:carry = (x & y) << 1
- 完成本次循环,更新 x = answer,y = carry
- 返回 x 的二进制形式
为什么这个方法是可行的呢?在第一轮计算中,answer 的最后一位是 x 和 y 相加之后的结果,carry 的倒数第二位是 x 和 y 最后一位相加的进位。接着每一轮中,由于 carry 是由 x 和 y 按位与并且左移得到的,那么最后会补零,所以在下面计算的过程中后面的数位不受影响,而每一轮都可以得到一个低 i 位的答案和它向低 i+1 位的进位,也就模拟了加法的过程。
class Solution:
def addBinary(self, a, b) -> str:
x, y = int(a, 2), int(b, 2)
while y:
answer = x ^ y
carry = (x & y) << 1
x, y = answer, carry
return bin(x)[2:]
剑指 Offer II 003. 前 n 个数字二进制中 1 的个数
给定一个非负整数 n ,请计算 0 到 n 之间的每个数字的二进制表示中 1 的个数,并输出一个数组。
示例 1:
输入: n = 2
输出: [0,1,1]
解释:
0 --> 0
1 --> 1
2 --> 10
示例 2:
输入: n = 5
输出: [0,1,1,2,1,2]
解释:
0 --> 0
1 --> 1
2 --> 10
3 --> 11
4 --> 100
5 --> 101
我的方法1:暴力,位运算
vector<int> countBits(int n) {
vector<int> res(1);
for (int i = 1; i <= n; ++i) {
int cnt = 0, tmp = i;
while (tmp) {
tmp = tmp & (tmp - 1);
cnt ++ ;
}
res.emplace_back(cnt);
}
return res;
}
复杂度分析
-
时间复杂度: O ( n log n ) O(n \log n) O(nlogn)。需要对从 0 到 n 的每个整数使用计算「一比特数」,对于每个整数计算「一比特数」的时间都不会超过 O ( log n ) O(\log n) O(logn)。
-
空间复杂度:O(1)。除了返回的数组以外,空间复杂度为常数。
我的方法2:一次遍历
通过找规律我们可以得知,以2的倍数为分解线,前一半的值=后一半的值-1
设定一个int rBound,每次以2的倍数增长
vector<int> countBits(int n) {
vector<int> res(n+1);
if (n==0) return res;
int rBound = 1;
while (!res[n]) {
int i = 0;
while (i < rBound) {
if (res[n] != 0) break;
res[rBound + i] = res[i] + 1;
i++;
}
rBound <<= 1;
}
return res;
}
复杂度
时间:O(n)
空间:O(1)
剑指 Offer II 004. 只出现一次的数字
给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。
剑指 Offer II 004. 只出现一次的数字
示例 1:
输入:nums = [2,2,3,2]
输出:3
示例 2:
输入:nums = [0,1,0,1,0,1,100]
输出:100
提示:
1 <= nums.length <= 3 * 104
-231 <= nums[i] <= 231 - 1
nums 中,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次
我的方法:哈希表
int singleNumber(vector<int>& nums) {
unordered_map<int, int> m;
for (auto it : nums)
++m[it];
auto it = m.begin();
while (it != m.end() && (*it).second != 1)
it++;
return (*it).first;
}
};
进阶:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
方法二:依次确定每一个二进制位
// 将整数的各个数位上的加起来,然后对3取余,
// 若结果为0,则待求数字在该位上是0;
// 若结果为1,则待求数字在该位上是1.
最后再对每一位的和,3取余,不等于0的说明是来源于目标整数。
int singleNumber(vector<int>& nums) {
// 将整数的各个数位上的加起来,然后对3取余,
// 若结果为0,则待求数字在该位上是0;
// 若结果为1,则待求数字在该位上是1.
int ans = 0;
for (int i = 0; i < 32; ++i) {
int total = 0;
for (auto it : nums) {
it >>= i;
total += (it & 1);
}
if (total % 3) {
ans += (total % 3) << i;
}
}
return ans;
}
复杂度分析
- 时间复杂度: O ( n log C ∼ n ) O(n \log C\sim n) O(nlogC∼n),其中 n 是数组的长度,C 是元素的数据范围,在本题中 log C = log 2 32 = 32 \log C=\log 2^{32} = 32 logC=log232=32,也就是我们需要遍历第 0 ∼ 31 0\sim31 0∼31 个二进制位。
- 空间复杂度: O ( 1 ) O(1) O(1)。
剑指 Offer II 005. 单词长度的最大乘积
给定一个字符串数组 words,请计算当两个字符串 words[i] 和 words[j] 不包含相同字符时,它们长度的乘积的最大值。假设字符串中只包含英语的小写字母。如果没有不包含相同字符的一对字符串,返回 0。
示例 1:
输入: words = ["abcw","baz","foo","bar","fxyz","abcdef"]
输出: 16
解释: 这两个单词为 "abcw", "fxyz"。它们不包含相同字符,且长度的乘积最大。
示例 2:
输入: words = ["a","ab","abc","d","cd","bcd","abcd"]
输出: 4
解释: 这两个单词为 "ab", "cd"。
示例 3:
输入: words = ["a","aa","aaa","aaaa"]
输出: 0
解释: 不存在这样的两个单词。
提示:
2 <= words.length <= 1000
1 <= words[i].length <= 1000
words[i] 仅包含小写字母
我的解法:哈希map
两次遍历
//class mySortStr {
//public:
// bool operator()(const string & a, const string & b) {
// return a.size() > b.size();
// }
//};
int maxProduct(vector<string>& words) {
//sort(words.begin(), words.end(), mySortStr());
int res = 0;
for (int i = 0; i < words.size(); ++i) {
unordered_map<char, int>* tmp = new unordered_map<char, int>();
for (auto it : words[i]) ++(*tmp)[it];
for (int j = i + 1; j < words.size(); ++j) {
bool flag = false;
for (auto it : words[j]) {
if ((*tmp).count(it)) {
flag = true;
break;
}
}
if (!flag)
res = max(res, words[i].size() * words[j].size());
}
delete tmp;
}
return res;
}
复杂度, 假设vector size为n,最大的string size 为m
时间 O ( n 2 m ) O(n^2m) O(n2m)
空间O(m)
方法二:位运算,位掩码,状态压缩
采用哈希集合的暴力法会超时
定义一个masks数组来记录每个字符串的位掩码(状态压缩),对整个字符串数组进行位运算处理,对字符串数组的里的字符串进行两两按位与,若结果为0则说明两个字符串里没有相同字符,然后去更新答案
要注意&的优先级小于==
注意处,masks[i] |= 1 << (words[i][j] - 'a')这里用的是或等|=,不能用赋值=,因为后者会覆盖掉前面计算的值。
int maxProduct(vector<string>& words) {
int n = words.size();
vector<int> masks(n);
for (int i = 0; i < n; ++i) {
for (int j = 0; j < words[i].size(); ++j) {
masks[i] |= 1 << (words[i][j] - 'a');//
}
}
int ans = 0;
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (!(masks[i] & masks[j])) {
int tmp = words[i].size() * words[j].size();
ans = tmp > ans ? tmp : ans;
}
}
}
return ans;
}
复杂度分析:
- 时间复杂度:O((m + n)* n)
- 空间复杂度:O(n)
剑指 Offer II 006. 排序数组中两个数字之和
给定一个已按照 升序排列 的整数数组 numbers ,请你从数组中找出两个数满足相加之和等于目标数 target 。
函数应该以长度为 2 的整数数组的形式返回这两个数的下标值。numbers 的下标 从 0 开始计数 ,所以答案数组应当满足 0 <= answer[0] < answer[1] < numbers.length 。
假设数组中存在且只存在一对符合条件的数字,同时一个数字不能使用两次。
示例 1:
输入:numbers = [1,2,4,6,10], target = 8
输出:[1,3]
解释:2 与 6 之和等于目标数 8 。因此 index1 = 1, index2 = 3 。
示例 2:
输入:numbers = [2,3,4], target = 6
输出:[0,2]
示例 3:
输入:numbers = [-1,0], target = -1
输出:[0,1]
提示:
2 <= numbers.length <= 3 * 104
-1000 <= numbers[i] <= 1000
numbers 按 递增顺序 排列
-1000 <= target <= 1000
仅存在一个有效答案
我的方法:双指针
vector<int> twoSum(vector<int>& numbers, int target) {
int left = 0, right = numbers.size() - 1;
int sum = numbers[left] + numbers[right];
while (sum != target) {
if (sum < target) left++;
if (sum > target) right--;
sum = numbers[left] + numbers[right];
}
return vector<int>{left, right};
}
// 时间复杂度:O(n)
// 空间复杂度:O(1)
数组
剑指 Offer II 007. 数组中和为 0 的三个数
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a ,b ,c ,使得 a + b + c = 0 ?请找出所有和为 0 且 不重复 的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
示例 2:
输入:nums = []
输出:[]
示例 3:
输入:nums = [0]
输出:[]
提示:
0 <= nums.length <= 3000
-105 <= nums[i] <= 105
我的方法:固定b,双指针ac
- 先排序
- 假设三个数a
vector<vector<int>> resThreesum;
set<vector<int>> visted;
void twoSum(vector<int>& numbers, int target, int mid) {
int left = 0, right = numbers.size() - 1;
int sum = numbers[left] + numbers[right];
while ( 1 ) {
if (sum == target && left<mid && right>mid) {
vector<int> tmp = vector<int>{ numbers[left], numbers[mid], numbers[right] };
if (resThreesum.size() > 0 && visted.count(tmp));
else {
resThreesum.push_back(tmp);
visted.insert(tmp);
}
}
int tmpL = left, tmpR = right;
if (sum <= target && left < mid) left++;
if (sum >= target && right > mid) right--;、
sum = numbers[left] + numbers[right];
if (tmpL == left && tmpR == right) break;
}
return ;
}
vector<vector<int>> threeSum(vector<int>& nums) {
if (nums.size() < 3) return {};
sort(nums.begin(), nums.end());
for (int mid = 1; mid < nums.size()-1; mid++) {
twoSum(nums, -nums[mid], mid);
}
return resThreesum;
}
评价:很傻逼,固定b很难去除重复。
方法二:固定a,双指针bc
vector<vector<int>> threeSum(vector<int>& nums) {
if (nums.size() < 3) return {};
vector<vector<int>> res;
sort(nums.begin(), nums.end());
for (auto it = nums.begin(); it != nums.end(); it++) {
if (*it > 0) return res;
if (it != nums.begin() && *it == *(it - 1)) continue; // 防止重复
int target = -(*it);
auto l = it + 1, r = nums.end() - 1;
while (l < r) {
if (*l + *r > target) { r--; continue; }
if (*l + *r < target) { l++; continue; }
if (*l + *r == target) {
res.push_back({*it, * l, * r});
l++; r--;
while (l < r && *l == *(l - 1)) ++l;
while (l < r && *r == *(r + 1)) --r;
}
}
}
return res;
}
复杂度分析
时间复杂度: O ( N 2 ) O(N^2) O(N2),其中 N 是数组 nums \textit{nums} nums 的长度。
空间复杂度: O ( log N ) O(\log N) O(logN)。我们忽略存储答案的空间,额外的排序的空间复杂度为 O(\log N)O(logN)。然而我们修改了输入的数组 nums \textit{nums} nums,在实际情况下不一定允许,因此也可以看成使用了一个额外的数组存储了 nums \textit{nums} nums 的副本并进行排序,空间复杂度为 O ( N ) O(N) O(N)。
剑指 Offer II 009. 乘积小于 K 的子数组
给定一个正整数数组 nums和整数 k ,请找出该数组内乘积小于 k 的连续的子数组的个数。
示例 1:
输入: nums = [10,5,2,6], k = 100
输出: 8
解释: 8 个乘积小于 100 的子数组分别为: [10], [5], [2], [6], [10,5], [5,2], [2,6], [5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于100的子数组。
示例 2:
输入: nums = [1,2,3], k = 0
输出: 0
提示:
1 <= nums.length <= 3 * 104
1 <= nums[i] <= 1000
0 <= k <= 106
我的方法:暴力,超时
方法一:取log,乘法转加法
由于乘积可能会非常大(在最坏情况下会达到 100 0 50000 1000^{50000} 100050000,会导致数值溢出,因此我们需要对 n u m s \mathrm{nums} nums 数组取对数,将乘法转换为加法,即 log ( ∏ i n u m s [ i ] ) = ∑ i log n u m s [ i ] \log(\prod_i \mathrm{nums}[i]) = \sum_i \log \mathrm{nums}[i] log(∏inums[i])=∑ilognums[i],这样就不会出现数值溢出的问题了。
前缀和+二分 or 滑动窗口法
方法一:滑动窗口
对于每个 r i g h t \mathrm{right} right,我们需要找到最小的 l e f t \mathrm{left} left,满足 ∏ i = l e f t r i g h t n u m s \prod_{i=\mathrm{left}}^\mathrm{right} \mathrm{nums} ∏i=leftrightnums。由于当 l e f t \mathrm{left} left 增加时,这个乘积是单调不增的,因此我们可以使用双指针的方法,单调地移动 l e f t \mathrm{left} left。
算法
我们使用一重循环枚举 r i g h t \mathrm{right} right,同时设置 l e f t \mathrm{left} left 的初始值为 0。在循环的每一步中,表示 r i g h t \mathrm{right} right 向右移动了一位,将乘积乘以 n u m s [ r i g h t ] \mathrm{nums}[\mathrm{right}] nums[right]。此时我们需要向右移动 l e f t \mathrm{left} left,直到满足乘积小于 k 的条件。在每次移动时,需要将乘积除以 n u m s [ l e f t ] \mathrm{nums}[\mathrm{left}] nums[left]。当 l e f t \mathrm{left} left 移动完成后,对于当前的 r i g h t \mathrm{right} right,就包含了 r i g h t − l e f t + 1 \mathrm{right} - \mathrm{left} + 1 right−left+1个乘积小于 k k k 的连续子数组。
count = r - l +1 = 包含最右侧元素的 子数组的 数量。 如题 10,5,2,6
第一次窗口 10 以右侧元素10为基准 答案中加入[10] 整体答案 有[10]
第二次窗口 10,5 以右侧元素5为基准 答案中加入 [10,5] [5] 此时的整体答案有 [10] + [10,5] [5]--
第三次窗口 10,5,2 不满足窗口的标准,所以需要移动左指针 将10排出去,得到真实窗口为 5,2 以右侧元素2为基准 得到 [5,2] [2] 此时整体答案 [10] [10,5] [5] + [5,2] [2]--
第四次窗口 5,2,6 以右侧元素6为基准 答案中加入 [5,2,6] [2,6] [6] 至此右指针=nums.size() 窗口滑动结束。整体答案为 [10] [10,5] [5] [5,2] [2] [5,2,6] [2,6] [6]
int numSubarrayProductLessThanK(vector<int>& nums, int k) {
if (k <= 1) return 0;
int l = 0, r = 0, ans = 0, tmp = 1;
while (r < nums.size()) {
tmp *= nums[r];
while (tmp >= k) {
tmp /= nums[l];
l++;
}
ans += r - l + 1;
r++;
}
return ans;
}
复杂度分析
时间复杂度:O(n),其中 n 是 n u m s \mathrm{nums} nums 数组的长度。循环的时间复杂度为 O(n),而 \mathrm{left}left 最多移动 n 次,因此总的时间复杂度为 O(n)。
空间复杂度:O(1)。
方法一:二分查找
分析
我们可以使用二分查找解决这道题目,即对于固定的 i,二分查找出最大的 j 满足 n u m s [ i ] \mathrm{nums}[i] nums[i] 到 n u m s [ j ] \mathrm{nums}[j] nums[j] 的乘积小于 k。但由于乘积可能会非常大(在最坏情况下会达到 100 0 50000 1000^{50000} 100050000,会导致数值溢出,因此我们需要对 n u m s \mathrm{nums} nums 数组取对数,将乘法转换为加法,即 log ( ∏ i n u m s [ i ] ) = ∑ i log n u m s [ i ] \log(\prod_i \mathrm{nums}[i]) = \sum_i \log \mathrm{nums}[i] log(∏inums[i])=∑ilognums[i],这样就不会出现数值溢出的问题了。
算法
对 n u m s \mathrm{nums} nums 中的每个数取对数后,我们存储它的前缀和 p r e f i x \mathrm{prefix} prefix,即 p r e f i x [ i + 1 ] = ∑ x = 0 i n u m s [ x ] \mathrm{prefix}[i + 1] = \sum_{x=0}^i \mathrm{nums}[x] prefix[i+1]=∑x=0inums[x],这样在二分查找时,对于 i 和 j,我们可以用 p r e f i x [ j + 1 ] − p r e f i x [ i ] \mathrm{prefix}[j + 1] - \mathrm{prefix}[i] prefix[j+1]−prefix[i]得到 n u m s [ i ] \mathrm{nums}[i] nums[i] 到 n u m s [ j ] \mathrm{nums}[j] nums[j] 的乘积的对数。对于固定的 i i i,当找到最大的满足条件的 j j j 后,它会包含 j − i + 1 j-i+1 j−i+1 个乘积小于 k 的连续子数组。
下面的代码和算法中下标的定义略有不同。
class Solution(object):
def numSubarrayProductLessThanK(self, nums, k):
if k == 0: return 0
k = math.log(k)
prefix = [0]
for x in nums:
prefix.append(prefix[-1] + math.log(x))
ans = 0
for i, x in enumerate(prefix):
j = bisect.bisect(prefix, x + k - 1e-9, i+1)
ans += j - i - 1
return ans
剑指 Offer II 014. 字符串中的变位词
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的某个变位词。
换句话说,第一个字符串的排列之一是第二个字符串的 子串 。
示例 1:
输入: s1 = "ab" s2 = "eidbaooo"
输出: True
解释: s2 包含 s1 的排列之一 ("ba").
示例 2:
输入: s1= "ab" s2 = "eidboaoo"
输出: False
提示:
1 <= s1.length, s2.length <= 104
s1 和 s2 仅包含小写字母
我的方法:滑动窗口
注意窗口大小,一定为s1的长度n
因此当r-l
当r-l==n时,判断是否为所求
若不是,则将窗口左侧扔掉,继续循环至s2的最终
bool checkInclusion(string s1, string s2) {
unordered_map<char, int> need;
unordered_map<char, int> window;
for (auto i : s1) need[i]++;
int n = s1.size();
int r = 0, l = 0;
bool flag;
while (r < s2.size()) {
while (r - l < n && r < s2.size()) {
if (!need.count(s2[r])) break;//如果不是所需的字符,直接跳
window[s2[r]]++;
r++;
}
flag = true;
for (auto i : need)
if (!window.count(i.first) || i.second != window[i.first]) { flag = false; break; }
if (flag) return flag;
window[s2[l]]--;
l++;
if (r < l) r = l;
}
return false;
}
优化一:双map变单map
但是单map的查找变多了,我们用指针去改元素
bool checkInclusion(string s1, string s2) {
unordered_map<char, int> need;
for (auto i : s1) need[i]++;
int n = s1.size();
int r = 0, l = 0;
bool flag;
unordered_map<char, int>::iterator tmp;
while (r < s2.size()) {
while (r - l < n && r < s2.size()) {
/*if (!need.count(s2[r]) || !need[s2[r]]) break;
need[s2[r]]--;*/ // 相同地方查找了三次
tmp = need.find(s2[r]);
if (tmp == need.end() || !tmp->second) break;
tmp->second--;
r++;
}
flag = true;
for (auto i : need)
if (i.second) { flag = false; break; }
if (flag) return flag;
tmp = need.find(s2[l]);
if (tmp!=need.end()) tmp->second++;
//if (need.count(s2[l])) need[s2[l]]++;// 相同地方查找了二次
l++;
if (r < l) r = l;
}
return false;
}
优化二:使用类似状态压缩的思想,将哈希表换为数组
方法三:其实本题匹配字符串,可转化为窗口中的和相等
前(后)缀和
前缀和主要适用的场景是 原始数组不会被修改的情况下,频繁查询某个区间的累加和。
剑指 Offer II 008. 和大于等于 target 的最短子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
提示:
1 <= target <= 109
1 <= nums.length <= 105
1 <= nums[i] <= 105
进阶:
如果你已经实现 O(n) 时间复杂度的解法, 请尝试设计一个 O(n log(n)) 时间复杂度的解法。
我的方法:前缀和+快慢指针 (可优化为滑动窗口)
int minSubArrayLen(int target, vector<int>& nums) {
vector<int> sumPre(nums.size()+1);
int ans = INT_MAX;
for (int i = 1; i < nums.size() ; ++i) {
sumPre[i] = sumPre[i-1] + nums[i-1];
}
if (target > sumPre.back()) return 0;
int slow = 0, fast = 1;
while (1) {
int sum = sumPre[fast] - sumPre[slow];
if (sum < target && fast< sumPre.size()) { fast++; }
if (sum >= target) {
ans = min(ans, fast - slow);
slow++;
}
if (fast == sumPre.size() && sum < target) break;
}
return ans==INT_MAX? 0: ans;
}
前缀和数组在这里没用,其实空间可以优化为滑动窗口
处实际等价于前缀和
int n = nums.size();
int ans = INT_MAX, sum = 0;
int start = 0, end = 0;
while (end < n) {
sum += nums[end]; //
while (sum >= target) {
ans = min(ans, end - start + 1);
sum -= nums[start++];//
}
end++;
}
return ans == INT_MAX ? 0 : ans;
复杂度分析
- 时间复杂度:O(n),其中 n 是数组的长度。指针 start \textit{start} start和 end \textit{end} end 最多各移动 n 次。
- 空间复杂度:O(1)。
方法三:前缀和+双指针
为了使用二分查找,需要额外创建一个数组 sums \text{sums} sums 用于存储数组 nums \text{nums} nums的前缀和,其中 sums [ i ] \text{sums}[i] sums[i] 表示从 nums [ 0 ] \text{nums}[0] nums[0] 到 nums [ i − 1 ] \text{nums}[i-1] nums[i−1] 的元素和。得到前缀和之后,对于每个开始下标 ii,可通过二分查找得到大于或等于 i 的最小下标 bound \textit{bound} bound,使得 sums [ bound ] − sums [ i − 1 ] ≥ s \text{sums}[\textit{bound}]-\text{sums}[i-1] \ge s sums[bound]−sums[i−1]≥s,并更新子数组的最小长度(此时子数组的长度是 bound − ( i − 1 ) \textit{bound}-(i-1) bound−(i−1)。
因为这道题保证了数组中每个元素都为正,所以前缀和一定是递增的,这一点保证了二分的正确性。如果题目没有说明数组中每个元素都为正,这里就不能使用二分来查找这个位置了。
在很多语言中,都有现成的库和函数来为我们实现这里二分查找大于等于某个数的第一个位置的功能(二分左侧查找),比如 C++ 的 lower_bound, Python 中的 bisect.bisect_left
int minSubArrayLen(int s, vector<int>& nums) {
int n = nums.size();
if (n == 0) {
return 0;
}
int ans = INT_MAX;
vector<int> sums(n + 1, 0);
for (int i = 1; i <= n; i++) {
sums[i] = sums[i - 1] + nums[i - 1];
}
for (int i = 1; i <= n; i++) {
int target = s + sums[i - 1];
auto bound = lower_bound(sums.begin(), sums.end(), target);
if (bound != sums.end()) {
ans = min(ans, static_cast<int>((bound - sums.begin()) - (i - 1)));//强制转换
}
}
return ans == INT_MAX ? 0 : ans;
}
复杂度分析
-
时间复杂度: O ( n log n ) O(n \log n) O(nlogn),其中 n 是数组的长度。需要遍历每个下标作为子数组的开始下标,遍历的时间复杂度是 O ( n ) O(n) O(n),对于每个开始下标,需要通过二分查找得到长度最小的子数组,二分查找得时间复杂度是 O ( log n ) O(\log n) O(logn),因此总时间复杂度是 O ( n log n ) O(n \log n) O(nlogn)。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组的长度。额外创建数组 sums \text{sums} sums 存储前缀和。
560. 和为 K 的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
示例 1:
输入:nums = [1,1,1], k = 2
输出:2
示例 2:
输入:nums = [1,2,3], k = 3
输出:2
提示:
1 <= nums.length <= 2 * 104
-1000 <= nums[i] <= 1000
-107 <= k <= 107
方法二:前缀和 + 哈希表优化
思路和算法
我们可以基于方法一利用数据结构进行进一步的优化,我们知道方法一的瓶颈在于对每个 i,我们需要枚举所有的 j 来判断是否符合条件,这一步是否可以优化呢?答案是可以的。
我们定义 pre [ i ] \textit{pre}[i] pre[i] 为 [ 0.. i ] [0..i] [0..i] 里所有数的和,则 pre [ i ] \textit{pre}[i] pre[i] 可以由 pre [ i − 1 ] \textit{pre}[i-1] pre[i−1] 递推而来,即:
pre [ i ] = pre [ i − 1 ] + nums [ i ] \textit{pre}[i]=\textit{pre}[i-1]+\textit{nums}[i] pre[i]=pre[i−1]+nums[i]
那么「 [ j . . i ] [j..i] [j..i] 这个子数组和为 k 」这个条件我们可以转化为
pre [ i ] − pre [ j − 1 ] = = k \textit{pre}[i]-\textit{pre}[j-1]==k pre[i]−pre[j−1]==k
简单移项可得符合条件的下标 jj 需要满足
pre [ j − 1 ] = = pre [ i ] − k \textit{pre}[j-1] == \textit{pre}[i] - k pre[j−1]==pre[i]−k
所以我们考虑以 ii 结尾的和为 kk 的连续子数组个数时只要统计有多少个前缀和为 pre [ i ] − k \textit{pre}[i]-k pre[i]−k 的 pre [ j ] \textit{pre}[j] pre[j] 即可。我们建立哈希表 mp \textit{mp} mp,以和为键,出现次数为对应的值,记录 pre [ i ] \textit{pre}[i] pre[i] 出现的次数,从左往右边更新 mp \textit{mp} mp 边计算答案,那么以 i 结尾的答案 mp [ pre [ i ] − k ] \textit{mp}[\textit{pre}[i]-k] mp[pre[i]−k]即可在 O ( 1 ) O(1) O(1) 时间内得到。最后的答案即为所有下标结尾的和为 k 的子数组个数之和。
需要注意的是,从左往右边更新边计算的时候已经保证了 mp [ pre [ i ] − k ] \textit{mp}[\textit{pre}[i]-k] mp[pre[i]−k] 里记录的 pre [ j ] \textit{pre}[j] pre[j] 的下标范围是 0 ≤ j ≤ i 0\leq j\leq i 0≤j≤i 。同时,由于\textit{pre}[i]pre[i] 的计算只与前一项的答案有关,因此我们可以不用建立 pre \textit{pre} pre 数组,直接用 pre \textit{pre} pre 变量来记录 p r e [ i − 1 ] pre[i-1] pre[i−1] 的答案即可。
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int cnt = 0;
unordered_map<int, int> m;
m[0] = 1;
int sum = 0;
for (int i = 0; i < nums.size(); ++i) {
sum += nums[i]; // 此处即为前缀和
int tmp = sum - k;
if (m.count(tmp)) cnt += m[tmp];
m[sum]++;
}
return cnt;
}
};
复杂度分析
时间复杂度:O(n),其中 n 为数组的长度。我们遍历数组的时间复杂度为 O(n),中间利用哈希表查询删除的复杂度均为 O(1),因此总时间复杂度为 O(n)。
空间复杂度:O(n),其中 n 为数组的长度。哈希表在最坏情况下可能有 n 个不同的键值,因此需要 O(n)的空间复杂度。
剑指 Offer II 011. 0 和 1 个数相同的子数组
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。
示例 1:
输入: nums = [0,1]
输出: 2
说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。
示例 2:
输入: nums = [0,1,0]
输出: 2
说明: [0, 1] (或 [1, 0]) 是具有相同数量 0 和 1 的最长连续子数组。
提示:
1 <= nums.length <= 105
nums[i] 不是 0 就是 1
我的思路:暴力,超时
解题思路就是两个for循环,理清楚第二个for循环在做什么,然后将其转换为哈希表
我的思路二:前缀和+哈希表
由于「 0 和 1 的数量相同」等价于「1 的数量减去 0 的数量等于 0」,我们可以将数组中的 0 0 0视作 − 1 -1 −1,则原问题转换成「求最长的连续子数组,其元素和为 0」。
设数组 nums \textit{nums} nums 的长度为 n ,将数组 nums \textit{nums} nums 进行转换得到长度相等的新数组 newNums \textit{newNums} newNums:对于 0 ≤ i < n 0 \le i
为了快速计算 newNums \textit{newNums} newNums 的子数组的元素和,需要首先计算 newNums \textit{newNums} newNums 的前缀和。用 prefixSums [ i ] \textit{prefixSums}[i] prefixSums[i] 表示 newNums \textit{newNums} newNums 从下标 0 到下标 i 的前缀和,则 newNums \textit{newNums} newNums 从下标 j + 1 j+1 j+1 到下标 k(其中 j
当 prefixSums [ k ] − prefixSums [ j ] = 0 \textit{prefixSums}[k]-\textit{prefixSums}[j]=0 prefixSums[k]−prefixSums[j]=0时,即得到 newNums \textit{newNums} newNums 的一个长度为 k−j 的子数组元素和为 00,对应 nums \textit{nums} nums 的一个长度为 k − j k−j k−j 的子数组中有相同数量的 0 和 1 。
实现方面,不需要创建数组 newNums \textit{newNums} newNums 和 prefixSums \textit{prefixSums} prefixSums,只需要维护一个变量 counter \textit{counter} counter 存储 newNums \textit{newNums} newNums 的前缀和即可。具体做法是,遍历数组 nums \textit{nums} nums,当遇到元素 1 时将 counter \textit{counter} counter 的值加 1,当遇到元素 0 时将 counter \textit{counter} counter 的值减 1,遍历过程中使用哈希表存储每个前缀和第一次出现的下标。
规定空的前缀的结束下标为 − 1 -1 −1,由于空的前缀的元素和为 0,因此在遍历之前,首先在哈希表中存入键值对 ( 0 , − 1 ) (0,-1) (0,−1)。遍历过程中,对于每个下标 i,进行如下操作:
如果 counter \textit{counter} counter 的值在哈希表中已经存在,则取出 \textit{counter}counter 在哈希表中对应的下标 prevIndex \textit{prevIndex} prevIndex, nums \textit{nums} nums 从下标 prevIndex + 1 \textit{prevIndex}+1 prevIndex+1 到下标 i 的子数组中有相同数量的 0 和 1,该子数组的长度为 i − prevIndex i-\textit{prevIndex} i−prevIndex,使用该子数组的长度更新最长连续子数组的长度;
如果 counter \textit{counter} counter 的值在哈希表中不存在,则将当前余数和当前下标 i 的键值对存入哈希表中。
由于哈希表存储的是 counter \textit{counter} counter 的每个取值第一次出现的下标,因此当遇到重复的前缀和时,根据当前下标和哈希表中存储的下标计算得到的子数组长度是以当前下标结尾的子数组中满足有相同数量的 0 和 1 的最长子数组的长度。遍历结束时,即可得到 nums \textit{nums} nums 中的有相同数量的 0 和 1 的最长子数组的长度。
【注意】
- 之前使用了multi map,这里的查找速度是log(n),会超时
-
m.insert(pair这一句实际上可以简化,其实insert不会改变已经加入hash table中的键值对。并不是每个i都需要insert,我们只需要记录最远距离的坐标即可, 即记录第一次出现的坐标就行
int findMaxLength(vector<int>& nums) {
int findMaxLength(vector<int>& nums) {
unordered_map<int, int> m; //
int ans = 0, sum = 0;
m.insert(pair<int, int>(0, -1));
for (int i = 0; i < nums.size(); ++i) {
int replace = nums[i] == 0 ? -1 : 1;
sum += replace;
if (m.count(sum)) ans = max(ans, i - m[sum]);// i-m[sum] 表示求 二者相距的长度
// m.insert(pair(sum, i)); //
else m[sum] = i;
}
return ans;
}
复杂度分析
时间复杂度: O ( n ) O(n) O(n),其中 n 是数组 nums \textit{nums} nums 的长度。需要遍历数组一次。
空间复杂度: O ( n ) O(n) O(n),其中 n 是数组 nums \textit{nums} nums 的长度。空间复杂度主要取决于哈希表,哈希表中存储的不同的 counter \textit{counter} counter 的值不超过 n 个。
剑指 Offer II 012. 左右两边子数组的和相等
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入:nums = [1,7,3,6,5,6]
输出:3
解释:
中心下标是 3 。
左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,
右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
示例 2:
输入:nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心下标。
示例 3:
输入:nums = [2, 1, -1]
输出:0
解释:
中心下标是 0 。
左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),
右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
提示:
1 <= nums.length <= 104
-1000 <= nums[i] <= 1000
我的方法:前缀和+后缀和
例如nums=[1,7,3,6,5,6]
preSum = [0,1,8,11,17,22,28,0]
postSum= [0,28,27,20,17,11,6,0]
从左往右遍历,当发现在第i个索引,两个数组的元素相等。
则该位置即为答案所求
int pivotIndex(vector<int>& nums) {
int n = nums.size(), ans = 0;
vector<int> preSum(n + 2), postSum(n + 2);
for (int i = 1; i <= n; ++i) {
preSum[i] = preSum[i - 1] + nums[i - 1];
postSum[n - i + 1] = postSum[n - i + 2] + nums[n - i];
}
for (int i = 1; i <= n; ++i) {
if (preSum[i] == postSum[i]) return i-1;
}
return -1;
}
复杂度:
时间:O(N)
空间:O(N)
304. 二维区域和检索 - 矩阵不可变
给定一个二维矩阵 matrix,以下类型的多个请求:
计算其子矩形范围内元素的总和,该子矩阵的 左上角 为 (row1, col1) ,右下角 为 (row2, col2) 。
实现 NumMatrix 类:
NumMatrix(int[][] matrix) 给定整数矩阵 matrix 进行初始化
int sumRegion(int row1, int col1, int row2, int col2) 返回 左上角 (row1, col1) 、右下角 (row2, col2) 所描述的子矩阵的元素 总和 。
示例 1:
输入:
["NumMatrix","sumRegion","sumRegion","sumRegion"]
[[[[3,0,1,4,2],[5,6,3,2,1],[1,2,0,1,5],[4,1,0,1,7],[1,0,3,0,5]]],[2,1,4,3],[1,1,2,2],[1,2,2,4]]
输出:
[null, 8, 11, 12]
解释:
NumMatrix numMatrix = new NumMatrix([[3,0,1,4,2],[5,6,3,2,1],[1,2,0,1,5],[4,1,0,1,7],[1,0,3,0,5]]);
numMatrix.sumRegion(2, 1, 4, 3); // return 8 (红色矩形框的元素总和)
numMatrix.sumRegion(1, 1, 2, 2); // return 11 (绿色矩形框的元素总和)
numMatrix.sumRegion(1, 2, 2, 4); // return 12 (蓝色矩形框的元素总和)
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 200
-105 <= matrix[i][j] <= 105
0 <= row1 <= row2 < m
0 <= col1 <= col2 < n
最多调用 104 次 sumRegion 方法
我的方法:前缀和
class NumMatrix {
public:
vector<vector<int>> matSum;
NumMatrix(vector<vector<int>>& matrix) {
matSum = vector<vector<int>>(matrix.size() + 1, vector<int>(matrix.back().size() + 1));
for (int i = 1; i < matSum.size(); i++) {
for (int j = 1; j < matSum.back().size(); j++) {
matSum[i][j] = matSum[i - 1][j] + matSum[i][j - 1] - matSum[i - 1][j - 1] + matrix[i - 1][j - 1];
}
}
}
int sumRegion(int row1, int col1, int row2, int col2) {
int s1 = matSum[row2 + 1][col2 + 1];
int s2, s3, s4;
s2 = matSum[row2 + 1][col1];
s3 = matSum[row1][col2 + 1];
s4 = matSum[row1][col1];
return s1 - s2 - s3 + s4;
}
};
复杂度分析
-
时间复杂度:初始化 O ( m n ) O(mn) O(mn),每次检索 O ( 1 ) O(1) O(1),其中 m 和 n 分别是矩阵 matrix \textit{matrix} matrix 的行数和列数。
初始化需要遍历矩阵 matrix \textit{matrix} matrix 计算二维前缀和,时间复杂度是 O ( m n ) O(mn) O(mn)。
每次检索的时间复杂度是 O ( 1 ) O(1) O(1)。 -
空间复杂度: O ( m n ) O(mn) O(mn),其中 m 和 n 分别是矩阵 matrix \textit{matrix} matrix 的行数和列数。需要创建一个 m + 1 m+1 m+1 行 n + 1 n+1 n+1 列的二维前缀和数组 sums \textit{sums} sums。
差分数组
主要适用场景是频繁对原始数组的某个区间的元素进行增减。

注意:
- diff 数组长度与原数组一样
- 对区间 [ f i r , s e c ] [fir, sec] [fir,sec] 的所有值 + 1 +1 +1,等价于
diff[fir] += 1, diff[sec+1] -= 1 - diff 数组还原 nums 时,使用的 PreSum 跟 diff 数组长度一样,不过只用到了 diff[1:]
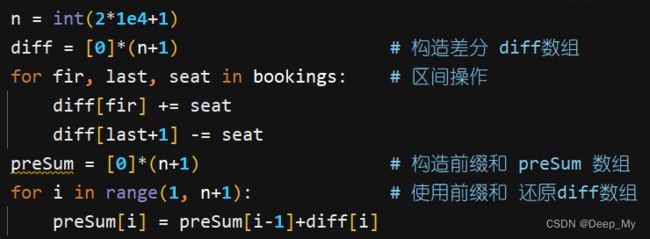
1109. 航班预订统计
这里有 n 个航班,它们分别从 1 到 n 进行编号。
有一份航班预订表 bookings ,表中第 i 条预订记录 bookings[i] = [firsti, lasti, seatsi] 意味着在从 firsti 到 lasti (包含 firsti 和 lasti )的 每个航班 上预订了 seatsi 个座位。
请你返回一个长度为 n 的数组 answer,里面的元素是每个航班预定的座位总数。
示例 1:
输入:bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5
输出:[10,55,45,25,25]
解释:
航班编号 1 2 3 4 5
预订记录 1 : 10 10
预订记录 2 : 20 20
预订记录 3 : 25 25 25 25
总座位数: 10 55 45 25 25
因此,answer = [10,55,45,25,25]
示例 2:
输入:bookings = [[1,2,10],[2,2,15]], n = 2
输出:[10,25]
解释:
航班编号 1 2
预订记录 1 : 10 10
预订记录 2 : 15
总座位数: 10 25
因此,answer = [10,25]
提示:
1 <= n <= 2 * 104
1 <= bookings.length <= 2 * 104
bookings[i].length == 3
1 <= firsti <= lasti <= n
1 <= seatsi <= 104
class Solution:
def corpFlightBookings(self, bookings: List[List[int]], n: int) -> List[int]:
diff = [0]*(n+2)
for s, e, v in bookings:
diff[s] += v
diff[e+1] -= v
preSum = [0]*(n+2)
for i in range(1, n+2):
preSum[i] = preSum[i-1] + diff[i]
return preSum[1:n+1]
字符串
76. 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
示例 2:
输入:s = "a", t = "a"
输出:"a"
示例 3:
输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
提示:
1 <= s.length, t.length <= 105
s 和 t 由英文字母组成
进阶:你能设计一个在 o(n) 时间内解决此问题的算法吗?
思路:滑动窗口
def minWindow(self, s: str, t: str) -> str:
from collections import Counter
l, r = 0, 0
cnt = Counter(t)
ans = None
while l<len(s):
while r<len(s) and any(map(lambda x: x>0, cnt.values())):
if s[r] in cnt:
cnt[s[r]] -= 1
r += 1
if all(map(lambda x: x<=0, cnt.values())) and (not ans or r-l<len(ans)):
ans = s[l:r]
if s[l] in cnt:
cnt[s[l]] += 1
l += 1
return ans if ans else ""
时间复杂度:O(n*k)
优化:
any 每次都要遍历一遍频率数组,判断是否满足条件。
这里我们可以用一个 int match,去判断 match==len(t) 代替any函数
def minWindow(self, s: str, t: str) -> str:
from collections import Counter
l, r = 0, 0
cnt = Counter(t)
match = 0
ans = None
while l<len(s):
while r<len(s) and match!=len(t):
if s[r] in cnt:
if cnt[s[r]]>0:
match += 1
cnt[s[r]] -= 1
r += 1
if match==len(t) and (not ans or r-l<len(ans)):
ans = s[l:r]
if s[l] in cnt:
cnt[s[l]] += 1
if cnt[s[l]]>0:
match -= 1
l += 1
return ans if ans else ""
时间复杂度:O(n)
剑指 Offer II 015. 字符串中的所有变位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 变位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
变位词 指字母相同,但排列不同的字符串。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的变位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的变位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的变位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的变位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的变位词。
提示:
1 <= s.length, p.length <= 3 * 104
s 和 p 仅包含小写字母
我的方法:同上,滑动窗口
vector<int> findAnagrams(string s2, string s1) {
vector<int> ans;
unordered_map<char, int> need;
for (auto i : s1) need[i]++;
int n = s1.size();
int r = 0, l = 0;
bool flag;
unordered_map<char, int>::iterator tmp;
while (r < s2.size()) {
while (r - l < n && r < s2.size()) {
tmp = need.find(s2[r]);
if (tmp == need.end() || !tmp->second) break;
tmp->second--;
r++;
}
flag = true;
for (auto i : need)
if (i.second) { flag = false; break; }
if (flag) ans.push_back(l);
tmp = need.find(s2[l]);
if (tmp!=need.end()) tmp->second++;
l++;
if (r < l) r = l;
}
return ans;
}
方法二:官解——滑动窗口
根据题目要求,我们需要在字符串 s 寻找字符串 p 的变位词。因为字符串 p 的变位词的长度一定与字符串 p 的长度相同,所以我们可以在字符串 s 中构造一个长度为与字符串 p 的长度相同的滑动窗口,并在滑动中维护窗口中每种字母的数量;当窗口中每种字母的数量与字符串 p 中每种字母的数量相同时,则说明当前窗口为字符串 p 的变位词。
算法
在算法的实现中,我们可以使用数组来存储字符串 p 和滑动窗口中每种字母的数量。
细节
当字符串 s 的长度小于字符串 p 的长度时,字符串 s 中一定不存在字符串 p 的变位词。但是因为字符串 s 中无法构造长度与字符串 p 的长度相同的窗口,所以这种情况需要单独处理。
优化
在方法一的基础上,我们不再分别统计滑动窗口和字符串 p 中每种字母的数量,而是统计滑动窗口和字符串 p 中每种字母数量的差;并引入变量 differ \textit{differ} differ 来记录当前窗口与字符串 p 中数量不同的字母的个数,并在滑动窗口的过程中维护它。
在判断滑动窗口中每种字母的数量与字符串 pp 中每种字母的数量是否相同时,只需要判断 \textit{differ}differ 是否为零即可。
vector<int> findAnagrams(string s, string p) {
int sLen = s.size(), pLen = p.size();
if (sLen < pLen) {
return vector<int>();
}
vector<int> ans;
vector<int> count(26);
for (int i = 0; i < pLen; ++i) {
++count[s[i] - 'a'];
--count[p[i] - 'a'];
}
int differ = 0;
for (int j = 0; j < 26; ++j) {
if (count[j] != 0) {
++differ;
}
}
if (differ == 0) {
ans.emplace_back(0);
}
for (int i = 0; i < sLen - pLen; ++i) {
if (count[s[i] - 'a'] == 1) { // 窗口中字母 s[i] 的数量与字符串 p 中的数量从不同变得相同
--differ;
} else if (count[s[i] - 'a'] == 0) { // 窗口中字母 s[i] 的数量与字符串 p 中的数量从相同变得不同
++differ;
}
--count[s[i] - 'a'];
if (count[s[i + pLen] - 'a'] == -1) { // 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从不同变得相同
--differ;
} else if (count[s[i + pLen] - 'a'] == 0) { // 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从相同变得不同
++differ;
}
++count[s[i + pLen] - 'a'];
if (differ == 0) {
ans.emplace_back(i + 1);
}
}
return ans;
}
复杂度分析
- 时间复杂度: O ( n + m + Σ ) O(n+m+\Sigma) O(n+m+Σ),其中 n 为字符串 s 的长度,m 为字符串 p 的长度,其中 Σ \Sigma Σ为所有可能的字符数。我们需要 O ( m ) O(m) O(m) 来统计字符串 pp 中每种字母的数量;需要 O ( m ) O(m) O(m) 来初始化滑动窗口;需要 O ( Σ ) O(\Sigma) O(Σ)来初始化 differ \textit{differ} differ;需要 O ( n − m ) O(n-m) O(n−m)来滑动窗口并判断窗口内每种字母的数量是否与字符串 p 中每种字母的数量相同,每次判断需要 O ( 1 ) O(1) O(1)。因为 s 和 p 仅包含小写字母,所以 Σ = 26 \Sigma = 26 Σ=26。
- 空间复杂度: O ( Σ ) O(\Sigma) O(Σ)。用于存储滑动窗口和字符串 p 中每种字母数量的差。
剑指 Offer II 016. 不含重复字符的最长子字符串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长连续子字符串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子字符串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子字符串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
提示:
0 <= s.length <= 5 * 104
s 由英文字母、数字、符号和空格组成
我的方法:滑动窗口
int lengthOfLongestSubstring(string s) {
int ans = 0;
int l = 0, r = 0, tmp;
unordered_set<char> mem;
while (r < s.size()) {
while (r < s.size() && !mem.count(s[r])) {
mem.insert(s[r]);
r++;
}
tmp = r - l;
ans = ans >= tmp ? ans : tmp;
mem.erase(s[l]);
l++;
}
return ans;
}
优化,直接用数组【256】代替unordered_set
int lengthOfLongestSubstring(string s) {
int ans = 0;
int l = 0, r = 0, tmp;
int mem[256] = { 0 }; //
while (r < s.size()) {
while (r < s.size() && !mem[s[r]]) {
mem[s[r]]++;//
r++;
}
tmp = r - l;
ans = ans >= tmp ? ans : tmp;
mem[s[l]]--;//
l++;
}
return ans;
}
剑指 Offer II 017. 含有所有字符的最短字符串
给定两个字符串 s 和 t 。返回 s 中包含 t 的所有字符的最短子字符串。如果 s 中不存在符合条件的子字符串,则返回空字符串 “” 。
如果 s 中存在多个符合条件的子字符串,返回任意一个。
注意: 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最短子字符串 "BANC" 包含了字符串 t 的所有字符 'A'、'B'、'C'
示例 2:
输入:s = "a", t = "a"
输出:"a"
示例 3:
输入:s = "a", t = "aa"
输出:""
解释:t 中两个字符 'a' 均应包含在 s 的子串中,因此没有符合条件的子字符串,返回空字符串。
提示:
1 <= s.length, t.length <= 105
s 和 t 由英文字母组成
我的方法:滑动窗口,无脑回溯
string minWindow(string s, string t) {
unordered_map<char, int> need;
int cnt = t.size();
string ans;
int tmp = INT_MAX;
for (auto i : t) { need[i]++; }
int l = 0, r = 0;
while (l < s.size()) {
while (cnt && r < s.size()) {
if (need.count(s[r])) {
if (need[s[r]] > 0) {
cnt--;
}
need[s[r]]--;
}
r++;
}
if (cnt == 0) {
ans = tmp > r - l ? s.substr(l, r - l) : ans;
tmp = ans.size();
}
tmp = ans.size();
if (need.count(s[l])) {
if (need[s[l]] >= 0) {
cnt++;
}
need[s[l]]++;
}
l++;
}
return ans;
}
滑动窗口,快速版
思路:两个hash table,一个need存需求,一个window存当前窗口包含的字符
先移动r,使window存满复合要求的字符时,移动l指针,缩减窗口
string minWindow(string s, string t) {
unordered_map<char, int> need;
unordered_map<char, int> window;
int cnt = 0;
string ans;
for (auto i : t) { need[i]++; }
int l = 0, r = 0;
while (r < s.size()) {
if (need.count(s[r])) {
if (need[s[r]] > window[s[r]]) cnt++;
}
window[s[r]]++;
while (cnt == t.size()) {
if (ans.size() == 0) ans = s.substr(l, r - l + 1);
if (need.count(s[l])) {
if (need[s[l]] == window[s[l]]) {
cnt--;
ans = r - l + 1 > ans.size() ? ans : s.substr(l, r - l + 1);
}
}
window[s[l]]--;
l++;
}
r++;
}
return ans;
}
剑指 Offer II 018. 有效的回文
给定一个字符串 s ,验证 s 是否是 回文串 ,只考虑字母和数字字符,可以忽略字母的大小写。
本题中,将空字符串定义为有效的 回文串 。
示例 1:
输入: s = "A man, a plan, a canal: Panama"
输出: true
解释:"amanaplanacanalpanama" 是回文串
示例 2:
输入: s = "race a car"
输出: false
解释:"raceacar" 不是回文串
提示:
1 <= s.length <= 2 * 105
字符串 s 由 ASCII 字符组成
我的方法
bool isValidCondition(char c) {
if (c - 'a' < 26 && c - 'a' >= 0) return true;
else if (c - '0' < 10 && c - '0' >= 0) return true;
return false;
}
bool isPalindrome(string s) {
unordered_map<char, char> upper2Lower;
char lower = 'a', upper = 'A';
for (int i = 0; i < 26; ++i) {
upper2Lower[upper++] = lower++;
}
for (auto& i: s) if (upper2Lower.count(i)) i = upper2Lower[i];
//transform(s.begin(), s.end(), s.begin(), tolower); // 使用该函数,可直接省略上述步骤
int l = 0, r = s.size()-1;
while (l < r) {
while (l < r && !isValidCondition(s[l])) l++;
while (l < r && !isValidCondition(s[r])) r--;
if (l < r) {
if (s[l] != s[r]) return false;
l++; r--;
}
}
return true;
}
官解
isalnum () 函数:用来检测一个字符是否是字母或者十进制数字;
isalpha () 函数:检测一个字符是否是字母;
isdigit () 函数:检测一个字符是否是十进制数字。
tolower() 函数:将字符转为小写
toupper() 函数:将字符转为大写
bool isPalindrome(string s) {
int l = 0, r = s.size()-1;
while (l < r) {
while (l < r && !isalnum(tolower(s[l]))) l++;
while (l < r && !isalnum(tolower(s[r]))) r--;
if (l < r) {
if (tolower(s[l]) != tolower(s[r])) return false;
l++; r--;
}
}
return true;
}
复杂度分析
时间复杂度:O(|s|),其中 |s| 是字符串 s 的长度。
空间复杂度:O(1)。
剑指 Offer II 019. 最多删除一个字符得到回文
给定一个非空字符串 s,请判断如果 最多 从字符串中删除一个字符能否得到一个回文字符串。
示例 1:
输入: s = "aba"
输出: true
示例 2:
输入: s = "abca"
输出: true
解释: 可以删除 "c" 字符 或者 "b" 字符
示例 3:
输入: s = "abc"
输出: false
提示:
1 <= s.length <= 105
s 由小写英文字母组成
我的思路:左右指针判断+一次递归
bool validPalindromeHelper(string& s, int l, int r, bool flag) {
while (l < r) {
if (s[l] != s[r]) {
if (flag)
return validPalindromeHelper(s, l, r-1, false) || validPalindromeHelper(s, l+1, r, false);
else return false;
}
l++; r--;
}
return true;
}
bool validPalindrome(string s) {
int l = 0, int r = s.size() - 1;
return validPalindromeHelper(s, l, r, true);
}
剑指 Offer II 020. 回文子字符串的个数
给定一个字符串 s ,请计算这个字符串中有多少个回文子字符串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例 1:
输入:s = "abc"
输出:3
解释:三个回文子串: "a", "b", "c"
示例 2:
输入:s = "aaa"
输出:6
解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
提示:
1 <= s.length <= 1000
s 由小写英文字母组成
string palindromeCS(string& s, int l, int r) {
while (l >= 0 && r < s.size() && s[l]==s[r]) {
l--; r++;
}
return s.substr(l+1, r - l - 1);
}
int countSubstrings(string s) {
int n = s.size(), ans = 0;
int l = 0, r = n - 1;
string s1, s2;
for (int i = 0; i < n; ++i) {
s1 = palindromeCS(s, i, i);
s2 = palindromeCS(s, i, i + 1);
ans += (s1.size() + 1) / 2 + s2.size() / 2;
}
return ans;
}
复杂度:O(n^2), O(1)
28. 实现 strStr() KMP算法
实现 strStr() 函数。
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
示例 1:
输入:haystack = "hello", needle = "ll"
输出:2
示例 2:
输入:haystack = "aaaaa", needle = "bba"
输出:-1
示例 3:
输入:haystack = "", needle = ""
输出:0
提示:
1 <= haystack.length, needle.length <= 104
haystack 和 needle 仅由小写英文字符组成
方法:KMP模板
class KMP {
public:
vector<vector<int>> dp;
string pat;
KMP(string pat) {
this->pat = pat;
int End = pat.size();
//dp[状态][字符] = next->状态
dp = vector<vector<int>>(End, vector<int>(256));
// base case
dp[0][pat[0]] = 1;
int X = 0;
for (int j = 1; j < End; ++j) {
for (int c = 0; c < 256; ++c) {
if (pat[j] == c) dp[j][c] = j + 1; //状态推进
else dp[j][c] = dp[X][c]; // 状态重启
}
X = dp[X][pat[j]]; // 更新最近影子状态
}
}
int search(string txt) {
int n = txt.size();
int End = pat.size();
int start = 0;
for (int i = 0; i < n; ++i) {
start = dp[start][txt[i]];
if (start == End) return i - End + 1;
}
return -1;
}
};
int strStr(string haystack, string needle) {
KMP k = KMP(needle);
return k.search(haystack);
}
复杂度分析
-
时间复杂度: O ( n + m ) O(n+m) O(n+m),其中 n 是字符串 haystack \textit{haystack} haystack 的长度, m 是字符串 needle \textit{needle} needle 的长度。我们至多需要遍历两字符串一次。
-
空间复杂度: O ( m ) O(m) O(m),其中 mm 是字符串 needle \textit{needle} needle 的长度。我们只需要保存字符串 needle \textit{needle} needle 的前缀函数。
链表
剑指 Offer II 021. 删除链表的倒数第 n 个结点
给定一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz
进阶:能尝试使用一趟扫描实现吗?
我的解法:快慢指针
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* pre = head, *cur = head, *tmp;
bool flag = false; //
if (n == 0) return head;
for (int i = 0; i < n + 1; i++) {
if (cur == nullptr) {
flag = true; break;//
}
cur = cur->next;
}
if (flag) return head->next;//
while (cur) {
pre = pre->next;
cur = cur->next;
}
tmp = pre->next->next;
pre->next = tmp;
return head;
}
细节1:cur需要提前走n+1步,因为pre需要找到倒数第n个结点的前一个结点
2: 当n=链表长度时,cur循环会越界,此时需提前退出,同时删除第一个结点即可
复杂度分析
- 时间复杂度:O(L) ,其中 L 是链表的长度。
- 空间复杂度:O(1) 。
对于两点细节,其实可以给head前面+一个哑结点,这样就不会出现越界了
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummy = new ListNode(0, head);
ListNode* first = head;
ListNode* second = dummy;
for (int i = 0; i < n; ++i) {
first = first->next;
}
while (first) {
first = first->next;
second = second->next;
}
second->next = second->next->next;
ListNode* ans = dummy->next;
delete dummy;
return ;
}
剑指 Offer II 025. 链表中的两数相加
给定两个 非空链表 l1和 l2 来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
可以假设除了数字 0 之外,这两个数字都不会以零开头。

示例1:
输入:l1 = [7,2,4,3], l2 = [5,6,4]
输出:[7,8,0,7]
示例2:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[8,0,7]
示例3:
输入:l1 = [0], l2 = [0]
输出:[0]
提示:
链表的长度范围为 [1, 100]
0 <= node.val <= 9
输入数据保证链表代表的数字无前导 0
进阶:如果输入链表不能修改该如何处理?换句话说,不能对列表中的节点进行翻转。
我的方法:递归(隐式调用栈)
int dfsaddTwoNumbers(ListNode* l1, ListNode* l2) 返回进位值(0,或1)
int dfsaddTwoNumbers(ListNode* l1, ListNode* l2) {
if (!l1 || !l2) return 0;
int last = dfsaddTwoNumbers(l1->next, l2->next);
int cur = l1->val + l2->val;
cur += last;
l1->val = cur % 10;
return cur/10;
}
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* l1tmp = l1, * l2tmp = l2, *tmp;
while (l1tmp && l2tmp) {
l1tmp = l1tmp->next;
l2tmp = l2tmp->next;
}
if (l2tmp) { // 保证 l1 长,我们后面只用到了l1
tmp = l1; l1tmp = l2tmp;
l1 = l2; l2 = tmp;
}
while (l1tmp) { // l2前面添0
l1tmp = l1tmp->next;
tmp = new ListNode(0, l2);
l2 = tmp;
}
int cur = dfsaddTwoNumbers(l1, l2);
if (cur) return new ListNode(1, l1);
return l1;
}
时间复杂度: O(n),空间O(n), n为最长的链表的长度
剑指 Offer II 022. 链表中环的入口节点
给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着 next 指针进入环的第一个节点为环的入口节点。如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意,pos 仅仅是用于标识环的情况,并不会作为参数传递到函数中。
说明:不允许修改给定的链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
提示:
链表中节点的数目范围在范围 [0, 104] 内
-105 <= Node.val <= 105
pos 的值为 -1 或者链表中的一个有效索引
进阶:是否可以使用 O(1) 空间解决此题?
我的方法:快慢指针
注意本题有两个步骤 :
1、判断是否有环
2、如有,则返回起点
ListNode* detectCycle(ListNode* head) {
ListNode* l = head, * r = head;
while (r && r->next) {
l = l->next;
r = r->next->next;
if (l == r) break;
}
if (!r || !r->next) return nullptr;
l = head;
while (l != r) {
l = l->next; r = r->next;
}
return l;
}
复杂度分析
-
时间复杂度: O(N),其中 N 为链表中节点的数目。在最初判断快慢指针是否相遇时, slow \textit{slow} slow 指针走过的距离不会超过链表的总长度;随后寻找入环点时,走过的距离也不会超过链表的总长度。因此,总的执行时间为 O ( N ) + O ( N ) = O ( N ) O(N)+O(N)=O(N) O(N)+O(N)=O(N)。
-
空间复杂度: O(1)。我们只使用了 l , r \textit{l}, \textit{r} l,r 三个指针。
剑指 Offer II 026. 重排链表
剑指 Offer II 026. 重排链表
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln-1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:
输入: head = [1,2,3,4]
输出: [1,4,2,3]
示例 2:
输入: head = [1,2,3,4,5]
输出: [1,5,2,4,3]
提示:
链表的长度范围为 [1, 5 * 104]
1 <= node.val <= 1000
我的方法:栈
void reorderList(ListNode* head) {
ListNode* cur = head, *tmp, *pre = nullptr;
int cnt = 0;
stack<ListNode*> stk;
while (cur) {
stk.push(cur);
cur = cur->next;
cnt++; // 记录元素长度
}
int cntTmp = cnt / 2; // 操作次数
while (cntTmp--) {
cur = head->next; // 首部
pre = stk.top(); stk.pop();// 尾部
head->next = pre;
pre->next = cur;
head = cur;
}
if (cnt % 2) head->next = nullptr; //截断多余结点
else head->next->next = nullptr;
return;
}
O(n), O(n)
剑指 Offer II 027. 回文链表
给定一个链表的 头节点 head ,请判断其是否为回文链表。
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。
示例 1:
输入: head = [1,2,3,3,2,1]
输出: true
示例 2:
输入: head = [1,2]
输出: false
提示:
链表 L 的长度范围为 [1, 105]
0 <= node.val <= 9
进阶:能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
我的方法:递归
bool dfsisPalindrome(ListNode*& head, ListNode*& cur) {
if (!cur) return true;
bool tmp = dfsisPalindrome(head, cur->next);
tmp = tmp && (cur->val == head->val);
head = head->next; // 回溯时,head不断前进,注意head参数需要使用引用
return tmp;
}
bool isPalindrome(ListNode* head) {
return dfsisPalindrome(head, head);
}
O(n), O(n)
方法二:快慢指针
思路
避免使用 O(n) 额外空间的方法就是改变输入。
我们可以将链表的后半部分反转(修改链表结构),然后将前半部分和后半部分进行比较。比较完成后我们应该将链表恢复原样。虽然不需要恢复也能通过测试用例,但是使用该函数的人通常不希望链表结构被更改。
该方法虽然可以将空间复杂度降到 O(1),但是在并发环境下,该方法也有缺点。在并发环境下,函数运行时需要锁定其他线程或进程对链表的访问,因为在函数执行过程中链表会被修改。
算法
整个流程可以分为以下五个步骤:
- 找到前半部分链表的尾节点。
- 反转后半部分链表。
- 判断是否回文。
- 恢复链表。
- 返回结果。
执行步骤一,我们可以计算链表节点的数量,然后遍历链表找到前半部分的尾节点。
我们也可以使用快慢指针在一次遍历中找到:慢指针一次走一步,快指针一次走两步,快慢指针同时出发。当快指针移动到链表的末尾时,慢指针恰好到链表的中间。通过慢指针将链表分为两部分。
若链表有奇数个节点,则中间的节点应该看作是前半部分。
步骤二可以使用206. 反转链表 问题中的解决方法来反转链表的后半部分。
步骤三比较两个部分的值,当后半部分到达末尾则比较完成,可以忽略计数情况中的中间节点。
步骤四与步骤二使用的函数相同,再反转一次恢复链表本身。
bool isPalindrome(ListNode* head) {
if (head == nullptr) {
return true;
}
// 找到前半部分链表的尾节点并反转后半部分链表
ListNode* firstHalfEnd = endOfFirstHalf(head);
ListNode* secondHalfStart = reverseList(firstHalfEnd->next);
// 判断是否回文
ListNode* p1 = head;
ListNode* p2 = secondHalfStart;
bool result = true;
while (result && p2 != nullptr) {
if (p1->val != p2->val) {
result = false;
}
p1 = p1->next;
p2 = p2->next;
}
// 还原链表并返回结果
firstHalfEnd->next = reverseList(secondHalfStart);
return result;
}
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr != nullptr) {
ListNode* nextTemp = curr->next;
curr->next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
ListNode* endOfFirstHalf(ListNode* head) {
ListNode* fast = head;
ListNode* slow = head;
while (fast->next != nullptr && fast->next->next != nullptr) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
O(n), O(1)
剑指 Offer II 028. 展平多级双向链表
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给定位于列表第一级的头节点,请扁平化列表,即将这样的多级双向链表展平成普通的双向链表,使所有结点出现在单级双链表中。
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:
输入的多级列表如下图所示:

扁平化后的链表如下图:
![]()
示例 2:
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:
输入的多级列表如下图所示:
1---2---NULL
|
3---NULL
示例 3:
输入:head = []
输出:[]
如何表示测试用例中的多级链表?
以 示例 1 为例:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
序列化其中的每一级之后:
[1,2,3,4,5,6,null]
[7,8,9,10,null]
[11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null]
[null,null,7,8,9,10,null]
[null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
提示:
节点数目不超过 1000
1 <= Node.val <= 10^5
方法一:深度优先搜索
当我们遍历到某个节点 node \textit{node} node 时,如果它的 child \textit{child} child 成员不为空,那么我们需要将 child \textit{child} child 指向的链表结构进行扁平化,并且插入 node \textit{node} node 与 node \textit{node} node 的下一个节点之间。
因此,我们在遇到 child \textit{child} child 成员不为空的节点时,就要先去处理 child \textit{child} child 指向的链表结构,这就是一个「深度优先搜索」的过程。当我们完成了对 child \textit{child} child 指向的链表结构的扁平化之后,就可以「回溯」到 node \textit{node} node 节点。
为了能够将扁平化的链表插入 node \textit{node} node 与 node \textit{node} node 的下一个节点之间,我们需要知道扁平化的链表的最后一个节点 last \textit{last} last,(通过dfs函数得到),随后进行如下的三步操作:(明确目的)
-
将 node \textit{node} node 与 node \textit{node} node 的下一个节点 next \textit{next} next 断开:
-
将 node \textit{node} node 与 child \textit{child} child 相连;
-
将 last \textit{last} last 与 next \textit{next} next 相连。
这样一来,我们就可以将扁平化的链表成功地插入。
Node* dfsflatten(Node* node) { //返回的是最后的元素
Node* cur = node;
// 记录链表的最后一个节点
Node* last = nullptr;
while (cur) { // 该循环的cur只需要一直往next走即可
Node* next = cur->next;
// 如果有子节点,那么首先处理子节点
if (cur->child) {
Node* child_last = dfsflatten(cur->child);
next = cur->next;
// 将 node 与 child 相连
cur->next = cur->child;
cur->child->prev = cur;
// 如果 next 不为空,就将 last 与 next 相连
if (next) {
child_last->next = next;
next->prev = child_last;
}
// 将 child 置为空
cur->child = nullptr;
last = child_last;
}
else {
last = cur;
}
cur = next;
}
return last;
}
Node* flatten(Node* head) {
dfsflatten(head);
return head;
}
-
时间复杂度: O(n),其中 nn 是链表中的节点个数。
-
空间复杂度: O(n)。上述代码中使用的空间为深度优先搜索中的栈空间,如果给定的链表的「深度」为 d,那么空间复杂度为 O(d)。在最换情况下,链表中的每个节点的 next \textit{next} next 都为空,且除了最后一个节点外,每个节点的 child \textit{child} child 都不为空,整个链表的深度为 n,因此时间复杂度为 O ( n ) O(n) O(n)。
剑指 Offer II 029. 排序的循环链表
给定循环单调非递减列表中的一个点,写一个函数向这个列表中插入一个新元素 insertVal ,使这个列表仍然是循环升序的。
给定的可以是这个列表中任意一个顶点的指针,并不一定是这个列表中最小元素的指针。
如果有多个满足条件的插入位置,可以选择任意一个位置插入新的值,插入后整个列表仍然保持有序。
如果列表为空(给定的节点是 null),需要创建一个循环有序列表并返回这个节点。否则。请返回原先给定的节点。
示例 1:
输入:head = [3,4,1], insertVal = 2
输出:[3,4,1,2]
解释:在上图中,有一个包含三个元素的循环有序列表,你获得值为 3 的节点的指针,我们需要向表中插入元素 2 。新插入的节点应该在 1 和 3 之间,插入之后,整个列表如上图所示,最后返回节点 3 。
示例 2:
输入:head = [], insertVal = 1
输出:[1]
解释:列表为空(给定的节点是 null),创建一个循环有序列表并返回这个节点。
示例 3:
输入:head = [1], insertVal = 0
输出:[1,0]
提示:
0 <= Number of Nodes <= 5 * 10^4
-10^6 <= Node.val <= 10^6
-10^6 <= insertVal <= 10^6
别人的方法:while循环
Node* insert(Node* head, int x) {
if(!head){
head=new Node(x);
head->next=head;
return head;
}
Node *cur=head;
while(cur->next!=head){
// cur 为边界跳越点
if(cur->next->val<cur->val){
if(x>=cur->val)break;// x比最大值都大
if(x<=cur->next->val)break;// x比最小值都小
}
// 顺序插入x中升序序列中
if(x>=cur->val&&x<=cur->next->val)break;
cur=cur->next;
}
// 将x插入到cur与cur->next之间
cur->next=new Node(x,cur->next);
return head;
}