深度学习——多层感知机二
深度学习——多层感知机二
文章目录
- 前言
- 一、多层感知机的从零实现
-
- 1.1. 初始化模型参数
- 1.2. 激活函数
- 1.3. 模型
- 1.4. 损失函数
- 1.5. 训练
- 二、多层感知机的简洁实现
- 总结
前言
上一章对多层感知机的概念做了简单介绍,而本章将正式讲述多层感知机的代码实现。
一、多层感知机的从零实现
1.1. 初始化模型参数
import torch
from d2l import torch as d2l
from torch import nn
# 选定并加载批量样本
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256 # 定义输入层、输出层、隐藏层
# torch.randn(),生成一个大小为(num_inputs,num_hiddens)的随机张量
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
1.2. 激活函数
自定义一个Relu激活函数
def RELU(x):
a = torch.zeros_like(x)
return torch.max(a, x)
1.3. 模型
# 使用reshape将每个二维图像转换为一个长度为num_inputs的向量
def net(x):
x = x.reshape((-1, num_inputs))
H = RELU(x @ W1 + b1) # 这里“@”代表矩阵乘法
return H @ W2 + b2
1.4. 损失函数
# 调用损失函数
loss = nn.CrossEntropyLoss(reduction="none")
# reduction参数被设置为"none",这意味着不会对损失进行降维操作,而是返回一个与输入大小相同的张量,其中包含每个样本的损失。
1.5. 训练
# 多层感知机的训练过程与softmax回归的训练过程完全相同。 可以直接调用d2l包的train_ch3函数
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr) # 创建了一个优化器(optimizer),使用随机梯度下降(SGD)算法
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
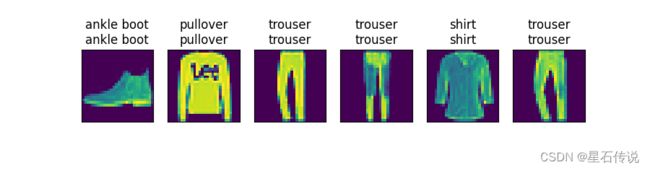
#展现前面六个图像分类的预测情况(上面为真实值标签,下面为预测值标签)
d2l.predict_ch3(net, test_iter)
d2l.plt.show()

二、多层感知机的简洁实现
"""
创建一个序列模型 nn.Sequential,其中包含多个层的线性堆叠。
nn.Flatten() 将输入的图像数据展平为一维向量。
nn.Linear(784, 256) 创建一个线性层,将输入大小为 784 的向量映射到大小为 256 的隐藏层。
nn.ReLU() 应用 ReLU 激活函数。
nn.Linear(256, 10) 创建一个线性层,将隐藏层的输出映射到大小为 10 的输出层(对应于分类任务的类别数)。
"""
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256),
nn.ReLU(), nn.Linear(256, 10))
#用于初始化模型的权重
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01) #使用正态分布随机初始化线性层 m 的权重,均值为 0,标准差为 0.01
net.apply(init_weights)
batch_size,lr,num_epochs = 256,0.1,10
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.SGD(net.parameters(),lr) #net.parameters() 返回模型中所有可学习的参数
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
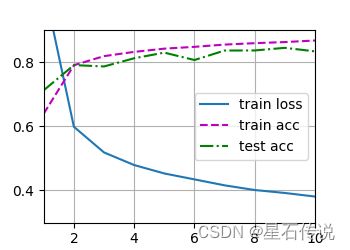
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
d2l.plt.show()
总结
本章简单介绍了一个只具有一个隐藏层的多层感知机的代码实现,实际上隐藏层可以有很多,并且每个隐藏层可以具有不同数量的神经元,从而增加模型的复杂度和表达能力。
但需要注意的是,增加隐藏层的数量和神经元数量会增加模型的复杂度和计算量,并且也可能导致过拟合问题。这时候就需要进行适当的正则化和调参。
少年的肩,应该担起草长莺飞和明月清风
– 2023-9-27 进阶篇