【java基础】对象序列化和反序列化详解
文章目录
- 说明
- 对象序列化
- 反序列化
- 序列化和反序列化保存的机制
- transient关键字
- 自定义序列化机制
-
- readObject和writeObject方式
- Externalizable机制
- 解决单例序列化问题
- 版本管理
- 序列化与深拷贝
- 总结
说明
在本篇文章中将会说明如何将对象存储到文件,如何从对象中读回对象。java提供了完善的对象序列化和反序列化的机制,主要就是通过ObjectOutputStream和ObjectInputStream来完成功能的。
对象序列化
对象序列化我们是使用ObjectOutputStream来完成的
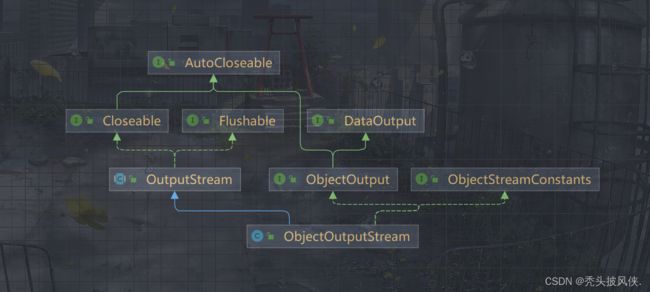
下面就是一个简单的序列化案例
注意:对于要序列化的类,我们必须要实现Serializable接口,这个接口的作用就是用来标记的
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Dog implements Serializable {
private Integer id;
private String name;
private Integer age;
}
将Dog对象保存到my.dat文件中。使用ObjectOutputStream的writeObject方法即可
@Test
public void t1() throws IOException {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("my.dat"))) {
Dog dog = new Dog(1, "旺财", 2);
oos.writeObject(dog);
}
}
保存之后就会在当前项目下生成一个my.dat文件,里面就保存了Dog的信息
反序列化
反序列化是使用的ObjectInputStream这个类

现在我们就来读取上面创建的my.dat文件。使用ObjectInputStream的readObject即可
@Test
public void t2() throws IOException, ClassNotFoundException {
Object object;
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("my.dat"))) {
object = ois.readObject();
}
System.out.println(object.getClass());
System.out.println(object);
}
输出结果如下

序列化和反序列化保存的机制
在我们进行序列化时,每一个对象都是使用一个序列号来进行保存的。
对象序列化的过程如下:
- 对你遇到的每一个对象引用都关联一个序列号。
- 对于每个对象,当第一次遇到时,保存其对象数据到输出流中。
- 如果某个对象之前已经被保存过,那么只写出“与之前保存过的序列号为x的对象相同”。
就像是上面图片中展示的那样,两个类引用了相同的Employee,那么存储该对象时只会存储该对象的序列号。
对象反序列化的过程如下:
- 对于对象输入流中的对象,在第一次遇到其序列号时,构建它,并使用流中数据来初始化它,然后记录这个顺序号和新对象之间的关联。
- 当遇到“与之前保存过的序列号为x的对象相同”这一标记时,获取与这个序列号相关联的对象引用。
transient关键字
这个关键字的作用就是在序列化时,会跳过transient所标记的字段
@Data
@NoArgsConstructor
@AllArgsConstructor
public class A implements Serializable {
private String name;
private B b;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class B {
private String name;
}
上面有2个类,其中A类实现了Serializable 接口,而B类没有,A类中有引用了B类,现在我们来将A类序列化,看有什么效果。
@Test
public void t3() throws IOException {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("a.dat"))) {
A a = new A("我是A", new B("我是B"));
oos.writeObject(a);
}
System.out.println("序列化成功!!!");
}
运行代码,输出如下
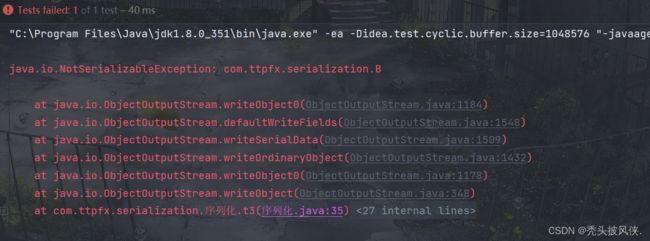
报错的原因就是B类没有实现Serializable 接口,对于没有实现Serializable 接口的,我们应该使用transient来进行标记。
@Data
@NoArgsConstructor
@AllArgsConstructor
public class A implements Serializable {
private String name;
private transient B b;
}
这时再序列化就会跳过b这个成员属性了。
我们序列化A之后再获取A,A输出如下
@Test
public void t4() throws IOException, ClassNotFoundException {
Object object;
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("a.dat"))) {
object = ois.readObject();
}
System.out.println(object.getClass());
System.out.println(object);
}
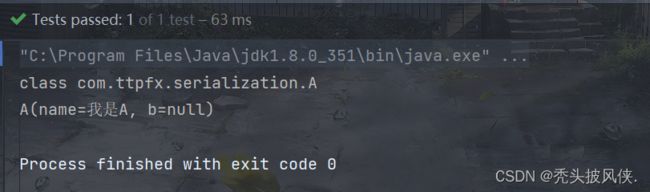
自定义序列化机制
readObject和writeObject方式
在上面,我们知道看transient关键字标识之后不会被序列化,于是b字段就为null,这里我们使用自定义序列化机制来解决这个问题。
序列化机制为单个的类提供了一种方式,去向默认的读写行为添加验证或任何其他想要的行为。可序列化的类可以定义具有下列签名的方法:
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
}
private void writeObject(ObjectOutputStream out) throws IOException {
}
之后,数据域就再也不会被自动序列化,取而代之的是调用这些方法。
我们只需要在A类中添加这2个方法,然后编写对应的方法即可
@Data
@NoArgsConstructor
@AllArgsConstructor
public class A implements Serializable {
private String name;
private transient B b;
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
String bName = in.readUTF();
b = new B(bName);
}
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeUTF("我是B--通过自定义方式实现序列化");
}
}
defaultReadObject和defaultWriteObject方法表示默认写入和读出,就是将非static和transient标识的字段进行写入和读出。
现在我们将A序列化,然后再读出,程序输出如下:
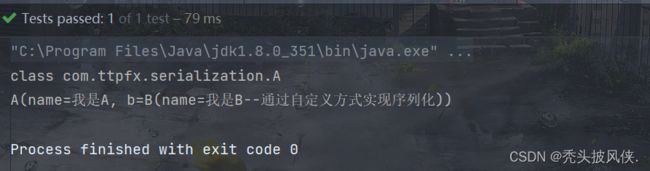
成功实现了自定义序列化
Externalizable机制
除了让序列化机制来保存和恢复对象数据,类还可以定义它自己的机制。为了做到这一点,这个类必须实现Externalizable接口
这个接口有2个方法,我们必须实现。
与前面描述的readObject和writeObject不同,这些方法对包括超类数据在内的整个对象的存储和恢复负全责。在写出对象时,序列化机制在输出流中仅仅只是记录该对象所属的类。在读入可外部化的类时,对象输入流将用无参构造器创建一个对象,然后调用readExternal方法。下面展示了如何为People类实现这些方法:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class People implements Externalizable {
private String name;
private Integer age;
private Double salary;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
out.writeDouble(salary);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = in.readUTF();
age = in.readInt();
salary = in.readDouble();
}
}
测试代码如下
@Test
public void t5() throws Exception {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("people.dat"))) {
People people = new People("ttpfx", 21, 33333.3);
System.out.println(people);
oos.writeObject(people);
}
System.out.println("序列化成功....");
System.out.println("------------------------------------");
System.out.println("反序列化内容");
Object object;
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("people.dat"))) {
object = ois.readObject();
}
System.out.println(object.getClass());
System.out.println(object);
}
代码输出如下

注意:readObject和writeObject方法是私有的,并且只能被序列化机制调用。与此不同的是,readExternal和writeExternal方法是公共的。特别是,readExternal还潜在地允许修改现有对象的状态。
解决单例序列化问题
下面有一个单例模式的类,内容如下
public class Color implements Serializable {
public static final Color RED = new Color("红色");
public static final Color GREEN = new Color("绿色");
public static final Color BLUE = new Color("蓝色");
private String color;
private Color(String color) {
this.color = color;
}
}
由于构造器私有,所以里面的RED,GREEN,BLUE都是单例的。现在我们来看一段代码
@Test
public void t6() throws Exception {
Color red = Color.RED;
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("color.dat"))) {
oos.writeObject(red);
}
Color color;
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("color.dat"))) {
color = (Color) ois.readObject();
}
System.out.println(red);
System.out.println(color);
System.out.println(red == color);
}
代码输出如下
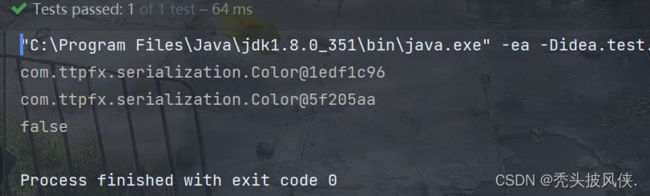
可以发现,单例模式在序列化之后再反序列化创建了一个新的对象,即使构造器是私有的,序列化机制也可以创建新的对象!
为了解决这个问题,你需要定义另外一种称为readResolve的特殊序列化方法。如果定义了readResolve方法,在对象被序列化之后就会调用它。它必须返回一个对象,而该对象之后会成为readObject的返回值。
我们再Color里面添加readResolve这个方法。
public class Color implements Serializable {
public static final Color RED = new Color("红色");
public static final Color GREEN = new Color("绿色");
public static final Color BLUE = new Color("蓝色");
private String color;
private Color(String color) {
this.color = color;
}
public Object readResolve() throws ObjectStreamException {
if ("红色".equals(color)) return RED;
else if ("绿色".equals(color)) return GREEN;
else if ("蓝色".equals(color)) return BLUE;
return null;
}
}
再次运行代码,输出如下
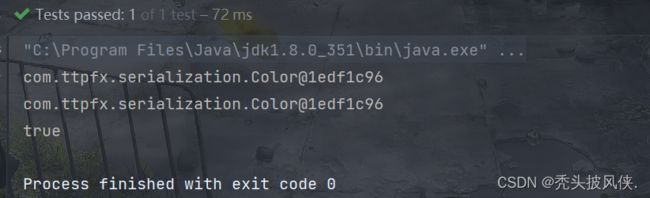
成功解决了单例问题
注意:我们使用枚举的时候不需要考虑单例的问题,readResolve是为了维护遗留的单例代码而存在的
请记住向遗留代码中所有类型安全的枚举以及向所有支持单例设计模式的类中添加readResolve方法。
版本管理
如果我们有一个类为User
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private String name;
private Integer age;
}
现在将User序列化到文件中,然后我们的User类发生了变化,可能多了字段,也可能少了字段,这时候会产生什么情况呢?
java.io.InvalidClassException: com.ttpfx.serialization.User; local class incompatible: stream classdesc serialVersionUID = 3204448204792269522, local class serialVersionUID = -7557592464667344196
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2028)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1875)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2209)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1692)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:508)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:466)
at com.ttpfx.serialization.序列化.t8(序列化.java:95)
这个时候就会报错,不管修改了什么。因为对象在保存的时候会对该类的所有信息进行安全散列算法(SHA),我们不管改变了类的什么信息,散列值都会发生改变,此时就已经认为不是同一个对象了,所以就会报错。
如果一个类有一个静态字段为serialVersionUID,那么在对象序列化和反序列化的时候就不会进行SHA了,而是直接使用这个字段的值。
如果在序列化和反序列化时的散列值相同,那么就可以进行转换。转换规则如下
如果这个类只有方法产生了变化,那么在读入新对象数据时是不会有任何问题的。但是,如果数据域产生了变化,那么就可能会有问题。例如,旧文件对象可能比程序中的对象具有更多或更少的数据域,或者数据域的类型可能有所不同。在这些情况中,对象输入流将尽力将流对象转换成这个类当前的版本。
对象输入流会将这个类当前版本的数据域与被序列化的版本中的数据域进行比较,当然,对象流只会考虑非瞬时和非静态的数据域。如果这两部分数据域之间名字匹配而类型不匹配,那么对象输入流不会尝试将一种类型转换成另一种类型,因为这两个对象不兼容;如果被序列化的对象具有在当前版本中所没有的数据域,那么对象输入流会忽略这些额外的数据;如果当前版本具有在被序列化的对象中所没有的数据域,那么这些新添加的域将被设置成它们的默认值(如果是对象则是null,如果是数字则为0,如果是boolean值则是false)。
我们一个将序列化后还会可能会发生改变的类加上serialVersionUID
public static final long serialVersionUID = 8888888888888888888L;
serialVersionUID 的值是自己设置的
序列化与深拷贝
深拷贝相信大家都听说过,如果要自己写一套逻辑的化还是挺麻烦的。我们使用序列化和反序列化就可以轻松的实现深拷贝。
序列化机制有一种很有趣的用法:即提供了一种克隆对象的简便途径,只要对应的类是可序列化的即可。其做法很简单:直接将对象序列化到输出流中,然后将其读回。这样产生的新对象是对现有对象的一个深拷贝(deep copy)。在此过程中,我们不必将对象写出到文件中,因为可以用ByteArrayOutputStream将数据保存到字节数组中。
我们应该当心这个方法,尽管它很灵巧,但是通常会比显式地构建新对象并复制或克隆数据域的克隆方法慢得多。
总结
对于序列化,我们应当记住以下内容
- 对象流输出中包含所有对象的类型和数据域
- 每个对象都有一个序列号
- 相同对象的重复出现将被存储为这个对象的序列号引用
- 对象的构造器即使是私有的也能使用,默认情况下会创建新的对象
- 单例模式的可序列化类应当定义一个readResolve方法
- 可以自定义序列化机制
- 可以自定义serialVersionUID替代SHA(安全散列算法)的值
- 通过序列化可以实现深拷贝
在这篇文章中,序列化之后的内容没有进行说明,大家感兴趣可以参考java核心卷|| 第二章的2.3.2小节