Python+大数据-数据处理与分析-pandas快速入门
Python+大数据-数据处理与分析(二)-pandas快速入门
1.Pandas快速入门
1.1DataFrame和Series介绍
1)DataFrame
- 用来处理结构化数据(SQL数据表,Excel表格)
- 可以简单理解为一张数据表(带有行标签和列标签)
2)Series
- 用来处理单列数据,也可以以把DataFrame看作由Series对象组成的字典或集合
- 可以简单理解为数据表的一行或一列

1.2 加载数据集(tsv和csv)
2)导入 pandas 包
注意:pandas 并不是 Python 标准库,所以先导入pandas
# 在 ipynb 文件中导入 pandas
import pandas as pd
3)加载 csv 文件数据集
tips = pd.read_csv('./data/tips.csv')
tips
4)加载 tsv 文件数据集
# sep参数指定tsv文件的列元素分隔符为\t,默认sep参数是,
china = pd.read_csv('./data/china.tsv', sep='\t')
china
1.3 loc函数获取指定行列的数据
基本格式:
| 语法 | 说明 |
|---|---|
df.loc[[行标签1, ...], [列标签1, ...]] |
根据行标签和列标签获取对应行的对应 列的数据,结果为:DataFrame |
df.loc[[行标签1, ...]] |
根据行标签获取对应行的所有列的数据 结果为:DataFrame |
df.loc[:, [列标签1, ...]] |
根据列标签获取所有行的对应列的数据 结果为:DataFrame |
df.loc[行标签] |
1)如果结果只有一行,结果为:Series 2)如果结果有多行,结果为:DataFrame |
df.loc[[行标签]] |
无论结果是一行还是多行,结果为DataFrame |
df.loc[[行标签], 列标签] |
1)如果结果只有一列,结果为:Series, 行标签作为 Series 的索引标签 2)如果结果有多列,结果为:DataFrame |
df.loc[行标签, [列标签]] |
1)如果结果只有一行,结果为:Series, 列标签作为 Series 的索引标签 2)如果结果有多行,结果为DataFrame |
df.loc[行标签, 列标签] |
1)如果结果只有一行一列,结果为单个值 2)如果结果有多行一列,结果为:Series, 行标签作为 Series 的索引标签 3)如果结果有一行多列,结果为:Series, 列标签作为 Series 的索引标签 4)如果结果有多行多列,结果为:DataFrame |
# 示例1:获取行标签为 1952, 1962, 1972 行的 country、pop、gdpPercap 列的数据
china_df.loc[[1952, 1962, 1972], ['country', 'pop', 'gdpPercap']

# 示例3:获取所有行的 country、pop、gdpPercap 列的数据
china_df.loc[:, ['country', 'pop', 'gdpPercap']]

1.4 iloc函数获取指定行列的数据
基本格式:
| 语法 | 说明 |
|---|---|
df.iloc[[行位置1, ...], [列位置1, ...]] |
根据行位置和列位置获取对应行的对应 列的数据,结果为:DataFrame |
df.iloc[[行位置1, ...]] |
根据行位置获取对应行的所有列的数据 结果为:DataFrame |
df.iloc[:, [列位置1, ...]] |
根据列位置获取所有行的对应列的数据 结果为:DataFrame |
df.iloc[行位置] |
结果只有一行,结果为:Series |
df.iloc[[行位置]] |
结果只有一行,结果为:DataFrame |
df.iloc[[行位置], 列位置] |
结果只有一行一列,结果为:Series, 行标签作为 Series 的索引标签 |
df.iloc[行位置, [行位置]] |
结果只有一行一列,结果为:Series, 列标签作为 Series 的索引标签 |
df.iloc[行位置, 行位置] |
结果只有一行一列,结果为单个值 |
# 示例2:获取行位置为 0, 2, 4 行的所有列的数据
china_df.iloc[[0, 2, 4]]

# 示例4:获取行位置为 1 行的所有列的数据
china_df.iloc[[1]]

1.5 loc和iloc的切片操作
基本格式:
| 语法 | 说明 |
|---|---|
df.loc[起始行标签:结束行标签, 起始列标签:结束列标签] |
根据行列标签范围获对应行的对应列的数据,包含起始行列标签和结束行列标签 |
df.iloc[起始行位置:结束行位置, 起始列位置:结束列位置] |
根据行列标签位置获对应行的对应列的数据,包含起始行列位置,但不包含结束行列位置 |
# 示例1:获取 china_df 中前三行的前三列的数据,分别使用上面介绍的loc和iloc实现
china_df.loc[1952:1962, 'country':'lifeExp']
或
china_df.iloc[0:3, 0:3]

1.6 [] 语法获取指定行列的数据
基本格式:
| 语法 | 说明 |
|---|---|
df[['列标签1', '列标签2', ...]] |
根据列标签获取所有行的对应列的数据,结果为:DataFrame |
df['列标签'] |
根据列标签获取所有行的对应列的数据 1)如果结果只有一列,结果为:Series, 行标签作为 Series 的索引标签 2)如果结果有多列,结果为:DataFrame |
df[['列标签']] |
根据列标签获取所有行的对应列的数据,结果为:DataFrame |
df[起始行位置:结束行位置] |
根据指定范围获取对应行的所有列的数据,不包括结束行位置 |
# 示例1:获取所有行的 country、pop、gdpPercap 列的数据
china_df[['country', 'pop', 'gdpPercap']]

2.Series和DataFrame
2.1 Series介绍
2.1.1 创建Series
1)创建 Series 的最简单方法是传入一个Python列表
- 如果传入的数据类型是统一的数字,那么最终的 dtype 类型是int64
- 如果传入的数据类型是统一的字符串,那么最终的 dtype 类型是object
- 如果传入的数据类型是多种类型,那么最终的 dtype 类型也是object
s = pd.Series(['banana', 42])
print(s)
print(type(s))
s = pd.Series(['banana', 'apple'])
print(s)
print(type(s))
s = pd.Series([50, 42])
print(s)
print(type(s))

2.1.2 Series常用操作
1)加载 scientists.csv 数据集,并获取 Age 列的数据
scientists = pd.read_csv('./data/scientists.csv')
scientists
# 并获取 Age 列的数据
age_series = scientists['Age']
print(age_series)
print(type(age_series))
2)常用属性和方法演示
age_series.shape
age_series.size
age_series.index
age_series.values
age_series.keys()
age_series.loc[1]
age_series.iloc[1]
age_series.dtypes
常用属性和方法:
| 属性或方法 | 说明 |
|---|---|
s.shape |
查看 Series 数据的形状 |
s.size |
查看 Series 数据的个数 |
s.index |
获取 Series 数据的行标签 |
s.values |
获取 Series 数据的元素值 |
s.keys() |
获取 Series 数据的行标签,和 s.index 效果相同 |
s.loc[行标签] |
根据行标签获取 Series 中的某个元素数据 |
s.iloc[行位置] |
根据行位置获取 Series 中的某个元素数据 |
s.dtypes |
查看 Series 数据元素的类型 |
常用统计方法:
| 方法 | 说明 |
|---|---|
s.mean() |
计算 Series 数据中元素的平均值 |
s.max() |
计算 Series 数据中元素的最大值 |
s.min() |
计算 Series 数据中元素的最小值 |
s.std() |
计算 Series 数据中元素的标准差 |
s.value_counts() |
统计 Series 数据中不同元素的个数 |
s.count() |
统计 Series 数据中非空(NaN)元素的个数 |
s.describe() |
显示 Series 数据中元素的各种统计值 |
Series方法(备查):
| 方法 | 说明 |
|---|---|
| append | 连接两个或多个Series |
| corr | 计算与另一个Series的相关系数 |
| cov | 计算与另一个Series的协方差 |
| describe | 计算常见统计量 |
| drop_duplicates | 返回去重之后的Series |
| equals | 判断两个Series是否相同 |
| get_values | 获取Series的值,作用与values属性相同 |
| hist | 绘制直方图 |
| isin | Series中是否包含某些值 |
| min | 返回最小值 |
| max | 返回最大值 |
| mean | 返回算术平均值 |
| median | 返回中位数 |
| mode | 返回众数 |
| quantile | 返回指定位置的分位数 |
| replace | 用指定值代替Series中的值 |
| sample | 返回Series的随机采样值 |
| sort_values | 对值进行排序 |
| to_frame | 把Series转换为DataFrame |
| unique | 去重返回数组 |
2.1.3 bool索引
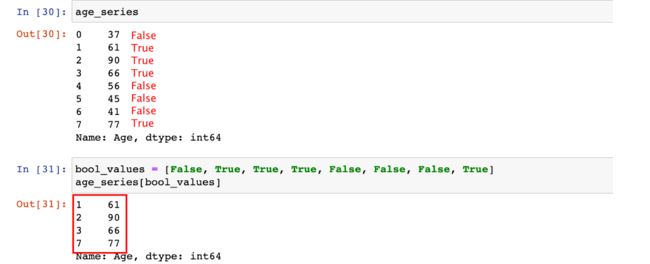
Series 支持 bool 索引,可以从 Series 获取 bool 索引为 True 的位置对应的数据。
bool_values = [False, True, True, True, False, False, False, True]
age_series[bool_values]
2.1.4 Series运算
| 情况 | 说明 |
|---|---|
Series 和 数值型数据运算 |
Series 中的每个元素和数值型数据逐一运算,返回新的 Series |
Series 和 另一 Series 运算 |
两个 Series 中相同行标签的元素分别进行运算,若不存在相 同的行标签,计算后的结果为 NaN,最终返回新的 Series |
Series 和 数值型数据运算:
# 加法
age_series + 100

2.2 DataFrame介绍
2.2.1 创建DataFrame
1)可以使用字典来创建DataFrame
peoples = pd.DataFrame({
'Name': ['Smart', 'David'],
'Occupation': ['Teacher', 'IT Engineer'],
'Age': [18, 30]
})
peoples

2)创建 DataFrame 的时候可以使用colums参数指定列的顺序,也可以使用 index 参数来指定行标签
peoples = pd.DataFrame({
'Occupation': ['Teacher', 'IT Engineer'],
'Age': [18, 30]
}, columns=['Age', 'Occupation'], index=['Smart', 'David'])
peoples

2.2.2 DataFrame常用操作
常用属性和方法:
| 属性或方法 | 说明 |
|---|---|
df.shape |
查看 DataFrame 数据的形状 |
df.size |
查看 DataFrame 数据元素的总个数 |
df.ndim |
查看 DataFrame 数据的维度 |
len(df) |
获取 DataFrame 数据的行数 |
df.index |
获取 DataFrame 数据的行标签 |
df.columns |
获取 DataFrame 数据的列标签 |
df.dtypes |
查看 DataFrame 每列数据元素的类型 |
df.info() |
查看 DataFrame 每列的结构 |
df.head(n) |
获取 DataFrame 的前 n 行数据,n 默认为 5 |
df.tail(n) |
获取 DataFrame 的后 n 行数据,n 默认为 5 |
1)常用属性和方法演示
scientists.shape
scientists.size
scientists.ndim
len(scientists)

Pandas与Python常用数据类型对照:
| Pandas类型 | Python类型 | 说明 |
|---|---|---|
| object | string | 字符串类型 |
| int64 | int | 整形 |
| float64 | float | 浮点型 |
| datetime64 | datetime | 日期时间类型,python中需要加载 |
常用统计方法:
| 方法 | 说明 |
|---|---|
s.max() |
计算 DataFrame 数据中每列元素的最大值 |
s.min() |
计算 DataFrame 数据中每列元素的最小值 |
s.count() |
统计 DataFrame 数据中每列非空(NaN)元素的个数 |
s.describe() |
显示 DataFrame 数据中每列元素的各种统计值 |
2.2.3bool索引
DataFrame 支持 bool 索引,可以从 DataFrame 获取 bool 索引为 True 的对应行的数据。
bool_values = [False, True, True, True, False, False, False, True]
scientists[bool_values]

2.2.4DataFrame运算
DataFrame 和 数值型数据运算:
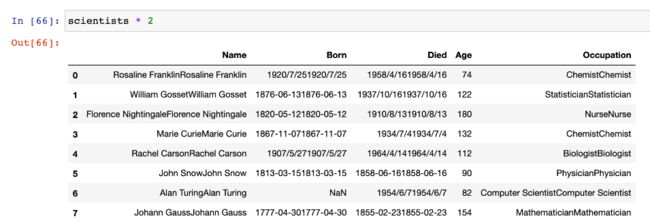
# DataFrame 和 数值型数据运算
scientists * 2
DataFrame 和 另一 DataFrame 运算:
# DataFrame 和 另一 DataFrame 运算
scientists + scientists

# DataFrame 和 另一 DataFrame 运算
scientists + scientists[:4]

2.3 行标签和列标签的操作
2.3.1 加载数据后,指定某列数据作为行标签
加载数据文件时,如果不指定行标签,Pandas会自动加上从0开始的行标签;
可以通过df.set_index(‘列名’)的方法重新将指定的列数据设置为行标签
scientists = pd.read_csv('./data/scientists.csv')
scientists

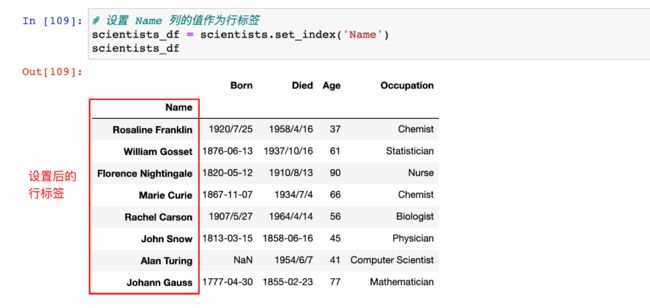
# 设置 Name 列的值作为行标签
scientists_df = scientists.set_index('Name')
scientists_df
2.3.2 加载数据时,指定某列数据作为行标签
加载数据文件的时候,可以通过通过 index_col 参数,指定使用某一列数据作为行标签,index_col 参数可以指定列名或列位置
1)加载 scientists.csv数据时,将 Name 列设置为行标签
pd.read_csv('./data/scientists.csv', index_col='Name')
或
pd.read_csv('./data/scientists.csv', index_col=0)

2.3.4加载数据后,修改行标签和列标签
| 方式 | 说明 |
|---|---|
df.rename(index={'原行标签名': '新行标签名', ...}, columns={'原列标签名': '新列标签名', ...}) |
修改指定的行标签和列标签,rename修改后返回新的 DataFrame |
df.index = ['新行标签名1', '新行标签名2', ...] df.columns = ['新列标签名1', '新列标签名2', …] |
修改行标签和列标签,直接对原 DataFrame 进行修改 |
3.DataFrame增删改
3.1DataFrame行操作
3.1.1添加行
注意:添加行时,会返回新的 DataFrame。
基本格式:
| 方法 | 说明 |
|---|---|
df.append(other) |
向 DataFrame 末尾添加 other 新行数据,返回新的 DataFrame |
1)加载 scientists.csv 数据集
scientists = pd.read_csv('./data/scientists.csv')
scientists
2)示例:在 scientists 数据末尾添加一行新数据
# 准备新行数据
new_series = pd.Series(['LuoGeng Hua', '1910-11-12', '1985-06-12', 75, 'Mathematician'],
index=['Name', 'Born', 'Died', 'Age', 'Occupation'])
scientists.append(new_series, ignore_index=True)
3.1.2 修改行
注意:修改行时,是直接对原始 DataFrame 进行修改。
基本格式:
| 方式 | 说明 |
|---|---|
df.loc[['行标签', ...],['列标签', ...]] |
修改行标签对应行的对应列的数据 |
df.iloc[['行位置', ...],['列位置', ...]] |
修改行位置对应行的对应列的数据 |
1)示例:修改行标签为 4 的行的所有数据

修改之后:
scientists.loc[4] = ['Rachel Carson', '1907-5-27', '1964-4-14', 56, 'Biologist']
scientists

3.1.3删除行
注意:删除行时,会返回新的 DataFrame。
基本格式:
| 方式 | 说明 |
|---|---|
df.drop(['行标签', ...]) |
删除行标签对应行的数据,返回新的 DataFrame |
1)示例:删除行标签为 1 和 3 的行
scientists.drop([1, 3])
3.2 DtaFrame列操作
3.2.1 新增列/修改列
注意:添加列/修改列时,是直接对原始 DataFrame 进行修改。
基本格式:
| 方式 | 说明 |
|---|---|
df['列标签']=新列 |
1)如果 DataFrame 中不存在对应的列,则在 DataFrame 最右侧增加新列 2)如果 DataFrame 中存在对应的列,则修改 DataFrame 中该列的数据 |
df.loc[:, 列标签]=新列 |
1)如果 DataFrame 中不存在对应的列,则在 DataFrame 最右侧增加新列 2)如果 DataFrame 中存在对应的列,则修改 DataFrame 中该列的数据 |
3.2.2 删除列
注意:删除列时,会返回新的 DataFrame。
基本格式:
| 方式 | 说明 |
|---|---|
df.drop(['列标签', ...], axis=1) |
删除列标签对应的列数据,返回新的 DataFrame |
1)示例:删除 scientists 数据中 Country 列的数据
scientists.drop(['Country'], axis=1)

3.3DataFrame 数据导出和导入
3.3.1 Pickle文件
导出到pickle文件:
- 调用to_pickle方法将以二进制格式保存数据
- 如要保存的对象是计算的中间结果,或者保存的对象以后会在Python中复用,可把对象保存为.pickle文件
- 如果保存成pickle文件,只能在python中使用
- 文件的扩展名可以是.p、.pkl、.pickle
scientists = pd.read_csv('data/scientists.csv')
scientists.to_pickle('./data/scientists_df.pickle')
读取pickle文件:
可以使用pd.read_pickle函数读取.pickle文件中的数据
scientists_df = pd.read_pickle('./data/scientists_df.pickle')
scientists_df
3.3.2CSV文件
我们用pd.read_csv()函数读取csv文件,使用df.to_csv()将数据保存为csv文件
- 在CSV文件中,对于每一行,各列采用逗号分隔;使用
\n换行符换行 - 除了逗号,还可以使用其他类型的分隔符,比如TSV文件,使用制表符作为分隔符
- CSV是数据协作和共享的首选格式,因为可以使用excel打开
# TSV文件,设置分隔符必须为\t
scientists.to_csv('./data/scientists_df.tsv', sep='\t')
# 不在csv文件中存入行标签
scientists.to_csv('./data/scientists_df_noindex.csv', index=False)
3.3.3Excel文件
注意:根据anaconda的版本不同,pandas读写excel有时需要额外安装
xlwt、xlrd、openpyxl三个包pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd
导出成Excel文件:
scientists.to_excel('./data/scientists_df.xlsx', sheet_name='scientists', index=False)
读取Excel文件:
使用pd.read_excel() 读取Excel文件
pd.read_excel('./data/scientists_df.xlsx')
4.DataFrame查询操作
4.1 DataFrame条件查询操作
基本格式:
| 方式 | 说明 |
|---|---|
df.loc[条件...] |
获取 DataFrame 中满足条件的数据 |
df.query('条件...') |
获取 DataFrame 中满足条件的数据 |
注意:loc 和 query 中可以跟多个条件,可以使用 &(与)、|(或) 表示条件之间的关系。
1)加载 scientists.csv 数据集
scientists = pd.read_csv('./data/scientists.csv')
scientists
2)示例:获取 Age 大于 60 且 Age < 80 的科学家信息
scientists.loc[(scientists['Age'] > 60) & (scientists['Age'] < 80)]
或
scientists.loc[(scientists.Age > 60) & (scientists.Age < 80)]

scientists.query('Age > 60 & Age < 80')

4.2 DataFrame 分组聚合操作
基本格式:
| 方式 | 说明 |
|---|---|
df.groupby(列标签, ...).列标签.聚合函数() |
按指定列分组,并对分组 数据的相应列进行相应的 聚合操作 |
df.groupby(列标签, ...).agg({'列标签': '聚合', ...}) |
按指定列分组,并对分组 数据的相应列进行相应的 聚合操作 |
df.groupby(列标签, ...).aggregate({'列标签': '聚合', ...}) |
按指定列分组,并对分组 数据的相应列进行相应的 聚合操作 |
常见聚合函数:
| 方式 | 说明 |
|---|---|
mean |
计算平均值 |
max |
计算最大值 |
min |
计算最小值 |
sum |
求和 |
count |
计数(非空数据数目) |
1)示例:按照 Occupation 职业分组,并计算每组年龄的平均值
scientists.groupby('Occupation')['Age'].mean()
或
scientists.groupby('Occupation').Age.mean()

)示例:按照 Occupation 职业分组,并计算每组的人数和年龄的平均值
scientists.groupby('Occupation').agg({'Name': 'count', 'Age': 'mean'})
或
scientists.groupby('Occupation').aggregate({'Name': 'count', 'Age': 'mean'})
4.3DataFrame 排序操作
基本格式:
| 方法 | 说明 |
|---|---|
df.sort_values(by=['列标签'], ascending=True) |
将 DataFrame 按照指定列的数据进行排序: ascending 参数默认为True,表示升序; 将 ascending 设置为 False,表示降序 |
df.sort_index(ascending=True) |
将 DataFrame 按照行标签进行排序: ascending 参数默认为True,表示升序; 将 ascending 设置为 False,表示降序 |
1)示例:按照 Age 从小到大进行排序
# 示例:按照 Age 从小到大进行排序
scientists.sort_values('Age')
2)示例:按照 Age 从大到小进行排序
# 示例:按照 Age 从大到小进行排序
scientists.sort_values('Age', ascending=False)
4.4 nlargest 和 nsmallest 函数
基本格式:
| 方法 | 说明 |
|---|---|
df.nlargest(n, columns) |
按照 columns 指定的列进行降序排序,并取前 n 行数据 |
df.nsmallest(n, columns) |
按照 columns 指定的列进行升序排序,并取前 n 行数据 |
1)示例:获取 Age 最大的前 3 行数据
# 示例:获取 Age 最大的前 3 行数据
scientists.nlargest(3, columns='Age')
2)示例:获取 Age 最小的前 3 行数据
# 示例:获取 Age 最小的前 3 行数据
scientists.nsmallest(3, columns='Age')