Mysql——三、SQL语句(上篇)
Mysql
-
- 一、SQL语句基础
-
- 1、SQL简介
- 2、SQL语句分类
- 3、SQL语句的书写规范
- 二、数据库操作
- 三、MySQL 字符集
-
- 1、变量
- 2、utf8和utf8mb4的区别
- 四、数据库对象
- 五、SELECT语句
-
- 1、简单的SELECT语句
- 2、SQL函数
-
- 2.1 聚合函数
- 2.2 数值型函数
- 2.3 字符串函数
- 2.4 日期和时间函数
- 2.5 流程控制函数
一、SQL语句基础
1、SQL简介
SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务。
- 改变数据库的结构
- 更改系统的安全设置
- 增加用户对数据库或表的许可权限
- 在数据库中检索需要的信息
- 对数据库的信息进行更新
2、SQL语句分类
MySQL致力于支持全套ANSI/ISO SQL标准。在MySQL数据库中,SQL语句主要可以划分为以下几类:
mysql
数据库show databases;
表
行 列
DDL(Data Definition Language):数据定义语言,定义对数据库对象(库、表、列、索引)的操作。CREATE、DROP、ALTER、RENAME、 TRUNCATE等。
DML(Data Manipulation Language): 数据操作语言,定义对数据库记录的操作。select ,INSERT、DELETE、UPDATE等。 DQL(Data Query Language)数据查询语言:SELECT语句。
DCL(Data Control Language): 数据控制语言,定义对数据库、表、字段、用户的访问权限和安全级别。GRANT、REVOKE等。
TCL(Transaction Control):事务控制。COMMIT、ROLLBACK、SAVEPOINT等。注:可以使用help查看这些语句的帮助信息。
3、SQL语句的书写规范
- 在数据库系统中,SQL语句不区分大小写(建议用大写) 。
- (数据)但字符串常量区分大小写。
- SQL语句可单行或多行书写,以“;”结尾。
- 关键词不能跨多行或简写。
- 用空格和缩进来提高语句的可读性。
- 子句通常位于独立行,便于编辑,提高可读性。
sql语句注释:
- (1)单行注释:“–” “#”
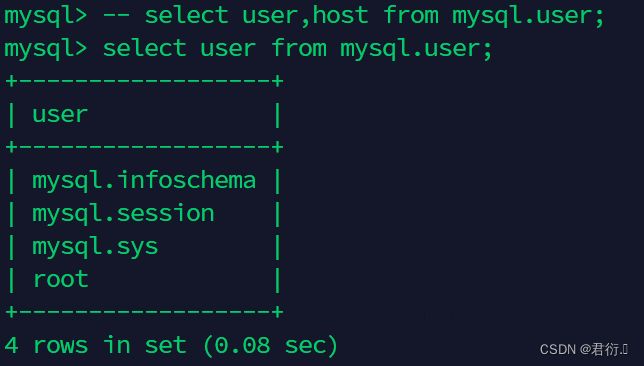
mysql> -- select user,host from mysql.user;
mysql> select user from mysql.user -- where user='root';
-> ;
+------------------+
| user |
+------------------+
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
+------------------+

- (2)多行注释:/* text */
mysql> select user from mysql.user /*
/*> where user='root'
/*> */
-> ;
+------------------+
| user |
+------------------+
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
+------------------+
二、数据库操作
1、查看
语法:SHOW DATABASES [LIKE wild];
wild可以使用"%“和”_"通配符。
%表示匹配任意零个或多个的任意字符。
_表示单个任意字符。
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+

Information_schema:主要存储了系统中的一些数据库对象信息:如用户表信息、列信息、权限信息、字符集信息、分区信息等。(数据字典表)
performance_schema:主要存储数据库服务器的性能参数
mysql:存储了系统的用户权限信息及帮助信息。
sys: 5.7新增,之前版本需要手工导入。这个库是通过视图的形式把information_schema和performance_schema结合起来,查询出更加令人容易理解的数据。
test:系统自动创建的测试数据库,任何用户都可以使用。
mysql> show databases like '__s%';
+-----------------+
| Database (__s%) |
+-----------------+
| mysql |
| sys |
+-----------------+
2、创建
语法:CREATE DATABASE [IF NOT EXISTS] 数据库名;
用给定的名字创建一个数据库,如果数据库已经存在,则报错。
#查看创建数据库的语句:SHOW CREATE DATABASE <数据库名>;
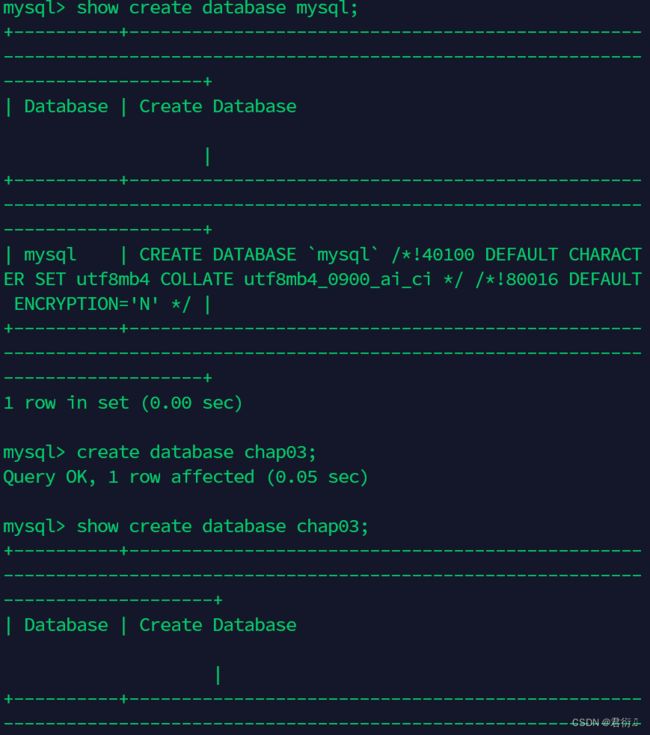
mysql> show create database mysql;
+----------+---------------------------------------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+---------------------------------------------------------------------------------------------------------------------------------+
| mysql | CREATE DATABASE `mysql` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+---------------------------------------------------------------------------------------------------------------------------------+
mysql> create database chap03;
Query OK, 1 row affected (0.00 sec)
mysql> show create database chap03;
+----------+----------------------------------------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------------------------------------------------------------------------+
| chap03 | CREATE DATABASE `chap03` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+----------------------------------------------------------------------------------------------------------------------------------+
3、删除
语法:DROP DATABASE [IF EXISTS]数据库名;
删除数据库中得所有表和数据库(慎用)
mysql> drop database chap03;

4、切换
语法: USE 数据库名;
把指定数据库作为默认(当前)数据库使用,用于后续语句。
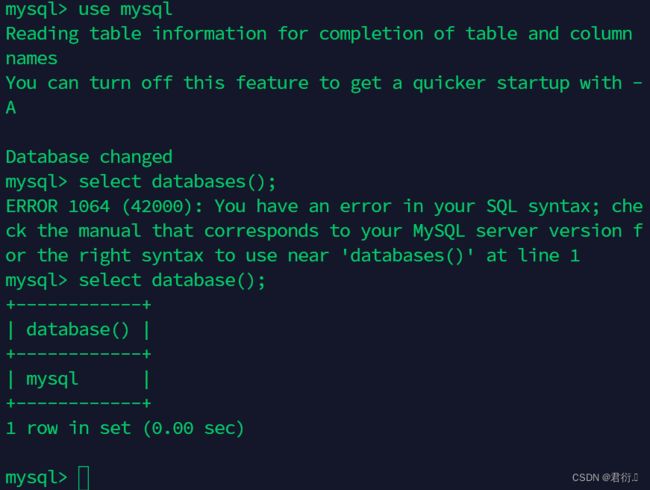
mysql> use mysql
# 查看当前连接的数据库
mysql> select database();
+------------+
| database() |
+------------+
| mysql |
+------------+
#设置提示符显示当前数据库名称
[root@mysql8-0-30 mysql]# vim /etc/my.cnf.d/mysql-server.cnf
[mysql]
prompt=mysql8.0 [\\d]>
[root@mysql8-0-30 mysql]# systemctl restart mysqld
[root@mysql8-0-30 mysql]# mysql -uroot -pAdmin123! mysql
mysql8.0 [mysql]>
5、执行系统命令
语法:system 命令
mysql> system date
2023年 02月 06日 星期一 15:57:52 CST
mysql> system ls /
afs boot etc lib media opt root sbin sys usr
bin dev home lib64 mnt proc run srv tmp var

三、MySQL 字符集
MySQL字符序包括字符集(CHARACTER)和校对规则(COLLATION)两个概念:字符集是多个字符(英文字符,汉字字符,或者其他国家语言字符)的集合,字符集种类较多,每个字符集包含的字符个数不同。
通常命名规则是: 字符集\_语言\_ci/cs/bin
常见字符集:
gbk支持中文简体字符,汉子占用的两个;
big5支持中文繁体字符;
utf8几乎支持世界所有国家的字符,汉字占用3个字节;
latin1支持西欧字符、希腊字符等
校对规则
cs: 区分大小写
bin:区分大小写
ci: 不区分大小写
特点:
1、字符编码方式是用一个或多个字节表示字符集中的一个字符
2、每种字符集都有自己特有的编码方式,因此同一个字符,在不同字符集的编码方式下,会产生不同的二进制
Mysql的字符集和校验规则有4个级别的默认设置:服务器级,数据库级,表级和字段级。分别在不同的地方设置,作用也不相同。
1、变量
系统变量
全局变量
作用域:mysql服务器每次启动都会为所有的系统变量设置初始值。我们为系统变量赋值,针对所有会话(连接)有效,可以跨连接,但不能跨重启,重启之后,mysql服务器会再次为所有系统变量赋初始值。
会话变量:
作用域:针对当前会话(连接)有效,不能跨连接。会话变量是在连接创建时由mysql自动给当前会话设置的变量。
>-- show [global|session] variables lile '%变量名%'
>-- select @@[global.|session.]系统变量名称;
>-- set [global|session|persist] 系统变量名=值; 修改变量值
eg: >set global password_history=1;
自定义变量
概念:变量由用户自定义的,而不是系统提供的。
作用域:针对当前会话(连接)有效,作用域同会话变量。
局部变量:
declare用于定义局部变量变量,在存储过程和函数中通过declare定义变量在begin…end中,且在语句之前。并且可以通过重复定义多个变量。(declare变量的作用范围同编程里面类似,在这里一般是在对应的begin和end之间。在end之后这个变量就没有作用了,不能使用了。这个同编程一样。)
-- set @变量名=值;
-- set @变量名:=值;
-- select @变量名:=值;
-- set中=号前面冒号是可选的,select方式=前面必须有冒号
赋值(更新变量的值)
set @变量名=值;
set @变量名:=值;
select @变量名:=值;
select @变量名
#查看字符集
mysql> show variables like 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8mb3 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+

修改mysql默认字符集
- 1.在[mysqld]下添加
character-set-server=utf8
init_connect = ‘SET NAMES utf8’ - 2.在[client]下添加
default-character-set=utf8 - 3.5.8开始,官方建议使用utf8mb4。
#查看当前mysql服务实例支持的校对规则
mysql> show collation;
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
| armscii8_bin | armscii8 | 64 | | Yes | 1 | PAD SPACE |

Collation字符集校对规则名称。MySQL校对规则名称是:以对应的字符集名称开头,以国家名居中(或以general居中),以ci、cs或bin结尾。【ci表示大小写不敏感,cs表示大小写敏感,bin表示按二进制编码值比较。】
Charset与字符集校对规则关联的字符集名称
Id字符集校对规则编号
Default是不是对应字符集默认的校对规则
Compiled是否有将此字符集校对规则集成到服务器中
Sortlen这个与字符串表示的字符集所需要的内存数量有关
Pad_attribute控制字符串尾部空格处理方式。PAD SPACE:在排序和比较运算中,忽略字符串尾部空格;NO PAD:在排序和比较运算中,字符串尾部空格当成普通字符,不能忽略。
2、utf8和utf8mb4的区别
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符,如表情等等(utf8的缺点)。
因此在8.0之后,建议大家使用utf8mb4这种编码。
查看MYSQL所支持的字符集
mysql> show charset;
mysql>SHOW COLLATION;”即可查看当前MySQL服务实例支持的字符序(校验码)
自定义字符集的方式
方式一:服务器级别
mysql>SHOW VARIABLES like 'character%';
mysql>show variables like 'collation%'; 字符序
character_set_client:MySQL客户机字符集。
character_set_connection:数据通信链路字符集,当MySQL客户机向服务器发送请求时,请求数据以该字符 集进行编码。
character_set_database:数据库字符集。
character_set_filesystem:MySQL服务器文件系统字符集,该值是固定的binary。
character_set_results:结果集的字符集,MySQL服务器向MySQL客户机返回执行结果时,执行结果以该字符 集进行编码。
character_set_server:MySQL服务实例字符集。
character_set_system:元数据(字段名、表名、数据库名等) 的字符集,默认值为utf8。
# vim /etc/mysql/my.cnf
5.5以前系统,在【client】下面加入 default-character-set=utf8
[client]
default-character-set=utf8
5.5版本以后的系统
[client]
default-character-set=utf8
[mysqld]
default-storage-engine=INNODB
character-set-server=utf8
collation-server=utf8_general_ci
重启服务查看测试
mysql> show variables like 'char%';
注意:修改my.cnf是对今后所创建的数据库起作用,修改的是mysql默认的字符集,但是不能修改已经创建好的数据库编码,已经创建好的需要重新进行修改。这里建议在修改了单个数据库之后,最好是将全局的默认编码也一并改过来,省的以后在出现相似的问题

方式二:(自定义数据库更改字符集)
mysql> show create database db2;
mysql> alter database db1 default character set utf8; 更改数据库的字符集
mysql> alter database db1 default character set utf8mb4 collate utf8mb4_general_ci;
mysql> create database db2 default character set=utf8;
mysql> create database db2 default character set gbk;
方式三:(自定义表数据字符集)
mysql> show create table student\G
mysql> create table student (id num,name char(10),tel int) default character utf8;
mysql> alter table student convert to character set gbk;或者 alter table t4 default character set utf8;
方式四:(修改指定字段的字符集)
mysql> alter table test1 modify name char(10) character set utf8;
mysql> show full columns from test1\G
....
*************************** 2. row ***************************
Field: name
Type: char(10)
Collation: utf8_general_ci
Null: YES
Key:
Default: NULL
Extra:
Privileges: select,insert,update,references
Comment:
2 rows in set (0.00 sec)
四、数据库对象
数据库对象的命名规则:
- 必须以字母开头
- 可包括数字和特殊字符(_和$)
- 不要使用MySQL的保留字
- 同一Schema下的对象不能同名
五、SELECT语句
1、简单的SELECT语句
- 1.select语法
#简单的SELECT语句:
SELECT {*, column [alias],...}
FROM table;
说明:
select *表示所有列。
FROM 提供数据源(表名/视图名)
- 2、SELECT语句中的算术表达式:
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * / %)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -)
运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
运算符的优先级:
乘法和除法的优先级高于加法和减法;
同级运算的顺序是从左到右;
表达式中使用括号可强行改变优先级的运算顺序;
1、导入实验sql
mysql> source /root/myemployees.sql

2、熟悉四张表
使用该数据库
mysql> use myemployees;
Database changed
查看数据库中的表
mysql> show tables;
+-----------------------+
| Tables_in_myemployees |
+-----------------------+
| departments |
| employees |
| jobs |
| locations |
+-----------------------+
4 rows in set (0.00 sec)
查询表中内容
mysql> select * from departments;
mysql> select * from employees;
mysql> select * from jobs;
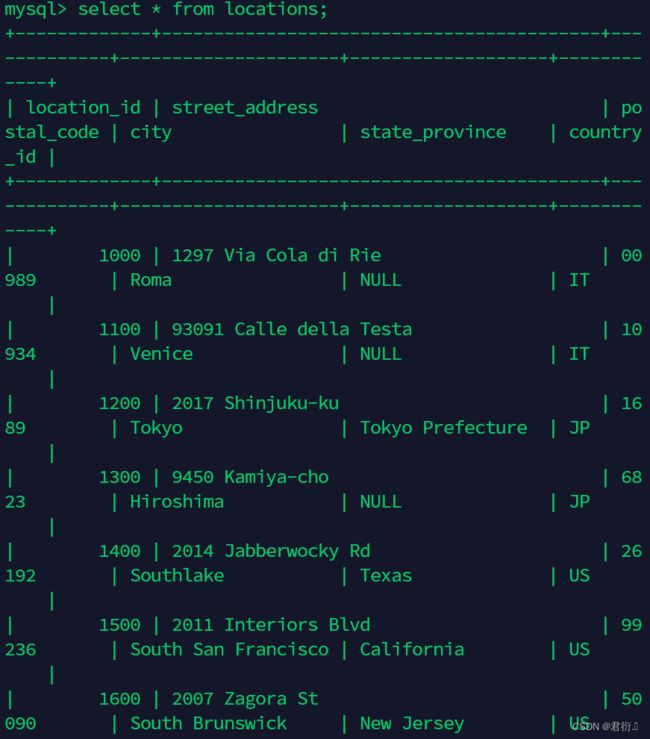
mysql> select * from locations;
查看表结构
mysql> desc departments;
mysql> desc employees;
mysql> desc jobs;
mysql> desc locations;





3、select 语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[into_option]
[FOR {UPDATE | SHARE}
[OF tbl_name [, tbl_name] ...]
[NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]
[into_option]
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}
基础语法:select 字段列表 from 数据源;
完整语法:select 去重选项 字段列表 [as 字段别名] from 数据源 [where子句] [group by 子句] [having子句] [order by 子句] [limit子句];
select 要查询的信息 from 表名;
要查询你的信息可以是什么:
(1)表中的一个字段或很多字段(中间用“,”分开)as 字段别名
(2)常量值
(3)表达式
(4)函数
(1)查询表字段(all distinct)
#查询单个字段
mysql> select first_name from employees;
#查询多个字段
mysql> select first_name,last_name from employees;
#查询所有字段
mysql> select * from employees;
#去重复 distinct,#DISTINCT的作用范围是后面所有字段的组合
mysql> select distinct department_id from employees;



(2)查询常量
mysql> select 100;
+-----+
| 100 |
+-----+
| 100 |
+-----+
1 row in set (0.00 sec)
注意:在数据库中表数据字符一定要用单引号
mysql> select 'john';
+------+
| john |
+------+
| john |
+------+
1 row in set (0.00 sec)

(3)查询表达式
mysql> select 1+1;
+-----+
| 1+1 |
+-----+
| 2 |
+-----+
1 row in set (0.00 sec)
#dual特殊表,虚拟表主要是为了使执行的select语句的语法完整
mysql> select 1 + 1 from dual;
+-------+
| 1 + 1 |
+-------+
| 2 |
+-------+
1 row in set (0.00 sec)
mysql> select 100%98;
+--------+
| 100%98 |
+--------+
| 2 |
+--------+
1 row in set (0.00 sec)
+符号的作用
mysql> select 100+90;
+--------+
| 100+90 |
+--------+
| 190 |
+--------+
1 row in set (0.00 sec)
#当有字符型的时候,它会试图将字符型转换成数值型,然后再计算。
mysql> select '123'+100;
+-----------+
| '123'+100 |
+-----------+
| 223 |
+-----------+
1 row in set (0.00 sec)
#如果字符型不能转换,它就会自动将字符型转换为0,然后再计算。
mysql> select 'abc'+90;
+----------+
| 'abc'+90 |
+----------+
| 90 |
+----------+
1 row in set, 1 warning (0.00 sec)
#NULL+任何东西的结果为NULL,null是一种状态不是一种数据类型
mysql> select null+'hehe';
+-------------+
| null+'hehe' |
+-------------+
| NULL |
+-------------+
1 row in set, 1 warning (0.00 sec)
补充说明:MySQL的+默认只有一个功能:运算符
SELECT 100+80; # 结果为180
SELECT '123'+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203
SELECT 'abc'+80; # 转换不成功,则字符型数值为0,结果为80
SELECT 'This'+'is'; # 转换不成功,结果为0
SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL
null值使用
空值是指不可用、未分配的值
空值不等于零或空格
任意类型都可以支持空值
(包括空值的任何算术表达式都等于空)
字符串和null进行连接运算,得到也是null


(4)查询函数
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.34 |
+-----------+
1 row in set (0.00 sec)
#字段别名

(5)查询定义别名as 可以省略
改变列的标题头
用于表示计算结果的含义
作为列的别名
如果别名中使用特殊字符,或者是强制大小写敏感,或有空格时,都可以通过为别名添加加双引号实现。
mysql> select 100%98 as 余数结果;
+--------------+
| 余数结果 |
+--------------+
| 2 |
+--------------+
1 row in set (0.00 sec)
mysql> select 100%98 余数;
+--------+
| 余数 |
+--------+
| 2 |
+--------+
1 row in set (0.00 sec)

函数连接姓名进行查询concat
mysql> select last_name+first_name as 姓名 from employees; 这个无法实现
mysql> select concat (last_name,first_name) as 姓名 from employees;
案列:查询salary,并起别名为 out put,别名里有特殊符号空格,这时要加单引号。
mysql> select salary as 'out put' from employees;
ifnull()函数
ifnull(expression,alt_values) 当第一个参数的表达式expression为null,则返回第二参数的备用值。
练习:
1.显示表departments的结构,查询它的全部数据。
explain desc describe
>desc departments;
>select * from departments;
2.显示employees中的全部job_id(不能重复)
select distinct job_id from employees;
3.显示employees的全部列(注意commission_pct有可能为null),各列之间用逗号链接,列头显示OUT_PUT
select concat(employee_id,',',first_name,',',ifnull(commission_pct,0),',',hiredate) as out_put from employees;
1.desc departments;
select * from departments;
2....distinct....;
3.select concat(first_name,',',last_name,',',ifnull(commission_pct,0),......) from employees;
2、SQL函数
2.1 聚合函数
聚合函数对一组值进行运算,并返回单个值。也叫分组函数。
COUNT(*|列名) 统计行数,*表示所有记录都不忽略,指定列名时会忽略null
AVG(数值类型列名) 平均值,忽略null
SUM (数值类型列名) 求和,忽略null
MAX(列名) 最大值,忽略null
MIN(列名) 最小值,忽略null
2.2 数值型函数
| 函数名称 | 作用 |
|---|---|
| ABS() | 求绝对值 |
| SQRT | 求平方根 |
| POW 和 POWER(2,3) | 两个函数的功能相同,返回参数的幂次方 |
| MOD(10,3) | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数时,用来产生重复序列; # rand() --> 属于[0,1) # rand() * 6 --> 属于[0,6) ,达不到6,可以达到5 # rand() * 6 + 5 --> 属于[5,11) ,达不到11,可以达到10 # floor(rand() * 6 + 5) --> 属于[5,10] |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号(-1表示负值,0,1表示正数) |
2.3 字符串函数
| 函数名称 | 作用 |
|---|---|
| LENGTH(‘str’) | 计算字符串长度函数,返回字符串的字节长度 |
| CHAR_LENGTH(‘str’) | 计算字符串长度函数,返回字符串的字符长度,注意两者的区别 |
| CONCAT(‘column1’,‘column2,’…) | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以是一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数从第pos字符还是将len长度的字符替换为新字符 |
| LOWER(‘Str’) | 将字符串中的字母转换为小写 |
| UPPER(‘str’) | 将字符串中的字母转换为大写 |
| LEFT(str,len) | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT(str,len) | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM(’ str ') trim(j from ‘jaj’) | 删除字符串左右两侧的空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(str,n,len) | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE(‘’) | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
| STRCMP(expr1,expr2) | 比较两个表达式的顺序。若expr1 小于 expr2 ,则返回 -1,0相等,1则相反 |
| LOCATE(substr,str [,pos]) | 返回第一次出现子串的位置 |
| INSTR(str,substr) | 返回第一次出现子串的位置 |
2.4 日期和时间函数
| 函数名称 | 作用 |
|---|---|
| CURDATE() CURRENT_DATE() CURRENT_DATE |
两个函数作用相同,返回当前系统的日期值 |
| CURTIME CURRENT_TIME() CURRENT_TIME |
两个函数作用相同,返回当前系统的时间值 |
| NOW() | 返回当前系统的日期和时间值 |
| SYSDATE | 返回当前系统的日期和时间值 |
| DATE | 获取指定日期时间的日期部分 |
| TIME | 获取指定日期时间的时间部分 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定曰期对应的月份的英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值,也就是星期数,注意周日是开始日,为1 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1 〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH 和 DAY | 两个函数作用相同,获取指定日期是一个月中是第几天,返回值范围是1~31 |
| DATEDIFF(expr1,expr2) | 返回两个日期之间的相差天数,如 SELECT DATEDIFF(‘2007-12-31 23:59:59’,‘2007-12-30’); |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| TIME_TO_SEC | 将时间参数转换为秒数,是指将传入的时间转换成距离当天00:00:00的秒数,00:00:00为基数,等于 0 秒 |
2.5 流程控制函数
| 函数名称 | 作用 |
|---|---|
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时,或者为1时返回 v1,当expr = false、null 、0时返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回 v2 |
| CASE | 搜索语句 |