StarRocks(三)数据导入与查询
1、Stream Load(同步)
StarRocks支持从本地直接导入数据,支持CSV格式。数据量在10G以下,可以使用Stream Load导入,这种导入方式是通过用户发送HTTP请求将本地文件或数据流导入到StarRocks中。Stream Load同步执行导入并返回结果。用户可以直接通过返回结果判断是否导入成功。
基本原理:Steam Load中,用户通过HTTP协议提交导入命令,提交到FE节点,FE节点则会通过HTTP 重定向指令请求转发给某一个BE节点,用户也可以直接提交导入命令指定BE节点。

1、使用
-- 创建测试表
CREATE TABLE users (
user_id BIGINT NOT NULL,
NAME STRING NOT NULL,
email STRING NULL,
address STRING NULL,
age TINYINT NULL,
sex TINYINT NULL
) PRIMARY KEY (user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 4
-- 创建测试数据
vim test.csv
1001,'test1',[email protected],'测试地址1',18,1
1002,'test2',[email protected],'测试地址2',18,1
1003,'test3',[email protected],'测试地址3',20,0
1004,'test4',[email protected],'测试地址4',21,1
1005,'test5',[email protected],'测试地址5',23,0
1006,'test6',[email protected],'测试地址6',22,1
1007,'test7',[email protected],'测试地址7',18,0
1008,'test8',[email protected],'测试地址8',25,1
1009,'test9',[email protected],'测试地址9',19,0
1010,'test10',[email protected],'测试地址10',10,1
1011,'test11',[email protected],'测试地址11',18,1
-- 根据官网语法将CSV数据导入对应user表中,官网语法:
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT
http://fe_host:http_port/api/{db}/{table}/_stream_load
-- 注意:命令-H为头部信息column_separator为测试文件中字段间隔符,虽然官网写着支持csv,但默认是\t,默认支持csv所以这把这个参数改成逗号
curl --location-trusted -u root -T 1.csv -H "column_separator:," http://hadoop2:8030/api/test_db/users/_stream_load因为Stream load是同步导入,所以可以立马看到是否导入成功。

2、Broker Load(异步)
StarRocks支持从Apache HDFS、Amazon S3等外部存储系导入数据,支持CSV、ORCFile、Parquet等文件格式。数据量在几十GB到上百GB级别。
在Broker Load模式下,通过部署的Broker程序,StarRocks可读取对应数据源(如HDFS, S3)上的数据,利用自身的计算资源对数据进行预处理和导入。这是一种异步的导入方式,用户需要通过MySQL协议创建导入,并通过查看导入命令检查导入结果。
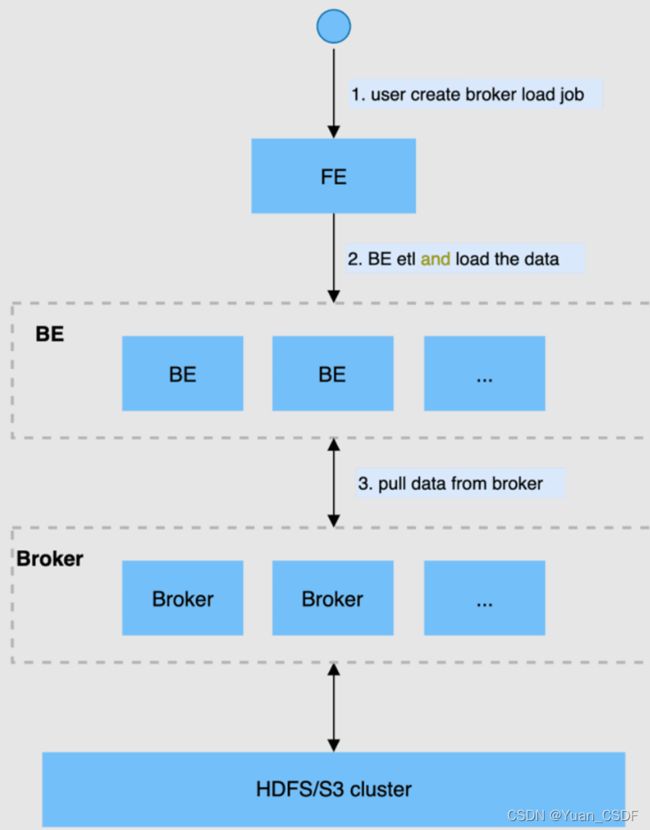
Broker Load任务语法如下图

1、需要将hdfs-site.xml复制到apache_hdfs_broker/conf目录下,并重启Broker。
2、创建hive表,采用parquet列式存储,snappy压缩,导入数据:
create external table test_member(
uid int,
ad_id int,
birthday string,
email string,
fullname string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
insert into test_member values
(1001,1,'1990-01-01','[email protected]','test1','2021-11-20','A'),
(1002,2,'1990-01-01','[email protected]','test1','2021-11-20','A'),
(1003,3,'1990-01-01','[email protected]','test1','2021-11-20','A'),
(1004,4,'1990-01-01','[email protected]','test1','2021-11-20','A'),
(1005,5,'1990-01-01','[email protected]','test1','2021-11-20','A');3、创建对应的StarRocks表:
CREATE TABLE test_bl( uid INT, ad_id INT, birthday varchar(20), email varchar(20), fullname varchar(20), dt varchar(20), dn varchar(20) )DUPLICATE KEY(uid) DISTRIBUTED BY HASH(uid) BUCKETS 8;4、据官方语法创建Broker Load将数据导入到StartRocks
LOAD LABEL test_db.label2
(
DATA INFILE("hdfs://hadoop1:9000/user/hive/warehouse/test_member/dt=2021-11-20/dn=A/*")
INTO TABLE test_bl
FORMAT AS "parquet"
(uid,ad_id,birthday,email,fullname)
SET
(
uid=uid,
ad_id=ad_id,
birthday=birthday,
email=email,
fullname=fullname,
dt='2021-11-20',
dn='A'
)
)
WITH BROKER "broker1"
(
"dfs.client.failover.proxy.provider.mycluster"="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
PROPERTIES
(
"timeout" = "3600"
);
5、查看任务执行情况: show load where label='label2';
3、Rountine Load(异步流式导入)
Routine Load 是一种例行导入方式,StarRocks通过这种方式支持从Kafka持续不断的导入数据,并且支持通过SQL控制导入任务的暂停、重启、停止。本节主要介绍该功能的基本原理和使用方式。
基本原理:
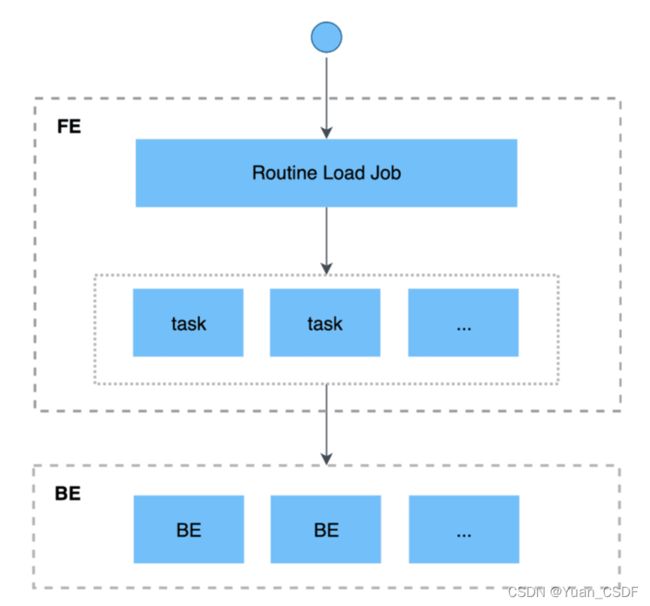
- 用户通过支持MySQL协议的客户端向 FE 提交一个Kafka导入任务。
- FE将一个导入任务拆分成若干个Task,每个Task负责导入指定的一部分数据。
- 每个Task被分配到指定的 BE 上执行。在 BE 上,一个 Task 被视为一个普通的导入任务,
- 通过 Stream Load 的导入机制进行导入。
- BE导入完成后,向 FE 汇报。
- FE 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
- FE 会不断的产生新的 Task,来完成数据不间断的导入。
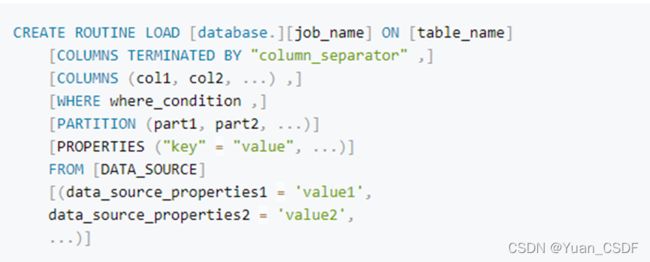
1、语法如下图
2、启动kafka集群,创建一个测试用的topic,编写代码往测试topic发送测试数据
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092");
props.put("acks", "-1");
props.put("batch.size", "1048576");
props.put("linger.ms", "5");
props.put("compression.type", "snappy");
props.put("buffer.memory", "33554432");
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
for (int i = 0; i < 10000; i++) {
producer.send(new ProducerRecord("test-starrocks", i + ",1,2000-01-01,[email protected],test2,2021-11-20,A"));
}
producer.flush();
producer.close();
} 3、创建load将kafka中的数据导入到test_bl中;
CREATE ROUTINE LOAD rl_test on test_bl
COLUMNS TERMINATED BY ","
PROPERTIES
(
"desired_concurrent_number"="3", -- 指定并行度
"max_error_number"="1000" -- 允许出错的最大条数
)
FROM KAFKA
(
"kafka_broker_list"= "hadoop1:9092,hadoop2:9092,hadoop3:9092",
"kafka_topic" = "test-starrocks",
"property.group.id" = "start-rocks-test",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);4、通过 SHOW ROUTINE LOAD\G; 查看load任务,可以看到接收到了数据,并且任务一直是running正在运行状态。

4、Insert into导入
Insert Into 语句的使用方式和 MySQL 等数据库中 Insert Into 语句的使用方式类似。 但在 StarRocks 中,所有的数据写入都是 一个独立的导入作业 。
语法: