NeurIPS 2021 放榜!Transformer或成最大赢家!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
前言
NeurIPS 2021 刚刚公布接收结果!先恭喜各位论文被收录的同学,文末附NeurIPS 2021接收群,中稿的同学可以加入,方便交流开会信息。
NeurIPS 2021 共提交了9122篇论文,最终接收率是26%(根据推断,应该收录有2371左右篇论文)。

Transformer或成最大赢家
这里重点强调一下Transformer的"分量"。NeurIPS 2021是AI大类顶会,包含了NLP、CV、ML等大类领域。对于NLP而言,Transformer无疑统治了大大大半壁江山;而对于CV而言,从2020下半年开始,特别是2021上半年,Visual Transformer的研究热点达到了前所未有的高峰。再次强调引爆CV圈 Transformer热潮的两篇最具代表性论文,即ECCV 2020的DETR(目标检测)和 ICLR 2021的ViT(图像分类)。
Transformer持续统治NLP,逐渐出圈染指CV。后者在arXiv上体现的淋漓尽致,到了CVPR 2021上得以证明:最新!CVPR 2021 视觉Transformer论文大盘点(43篇)
据Amusi了解,ICCV 2021上视觉Transformer的相关工作应该有70篇+,而根据当前社群反映情况,光今天刚放榜已知的NeurIPS 2021 视觉Transformer都已经至少30篇+了。
所以Transformer在NeurIPS 2021上一定是举足轻重般的存在,称为最大赢家也不为过。额外说几句,自监督/无监督相关的工作也是非常之多。
Amusi 第一时间整理了 9篇 NeurIPS 2021上的视觉Transformer论文,而且大多数都是已经在CVer上第一时间报道过的~
NeurIPS 2021 视觉Transformer的部分论文
1. SegFormer:简单有效Transformer的语义分割新思路
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
论文: https://arxiv.org/abs/2105.15203
代码:https://github.com/NVlabs/SegFormer
论文解读:港大&NVIDIA提出SegFormer:简单有效Transformer的语义分割新思路

2. MaskFormer:语义分割是像素分类问题吗?
Per-Pixel Classification is Not All You Need for Semantic Segmentation
论文: https://arxiv.org/abs/2107.06278
代码链接:
https://github.com/facebookresearch/MaskFormer
论文解读:屠榜语义分割和全景分割!FAIR提出MaskFormer:语义分割是像素分类问题吗?

3. Twins:更高效的视觉Transformer主干网,完美适配下游检测、分割任务
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
论文:http://arxiv.org/abs/2104.13840
代码:https://github.com/Meituan-AutoML/Twins
论文解读:重磅开源!Twins:更高效的视觉Transformer主干网,完美适配下游检测、分割任务

4. TransGAN:用纯Transformer构建高分辨率GAN
TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up
论文:https://arxiv.org/abs/2102.07074
代码:https://github.com/VITA-Group/TransGAN
论文解读:超越StyleGAN!TransGAN更新!用纯Transformer构建高分辨率GAN

5. 视觉Transformer的增强Shortcuts
Augmented Shortcuts for Vision Transformers
论文:https://arxiv.org/abs/2106.15941

6. 视觉Transformer的训练后量化
Post-Training Quantization for Vision Transformer
论文:https://arxiv.org/abs/2106.14156

7. TNT:Transformer in Transformer
论文:https://arxiv.org/abs/2103.00112
论文解读:
https://zhuanlan.zhihu.com/p/354147534

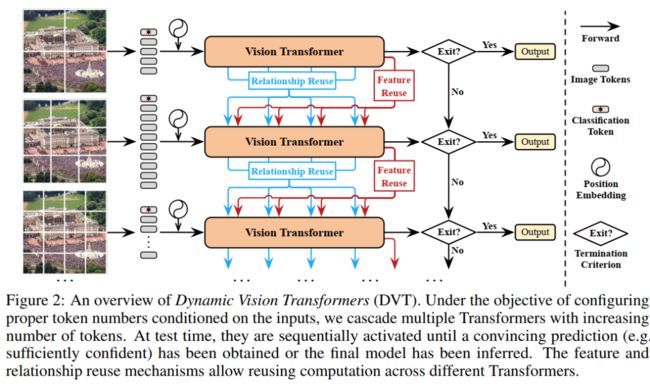
8. 所有图像都值16x16个词吗?可变序列长度的动态Transformer来了
Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length
论文:https://arxiv.org/abs/2105.15075
论文解读:
https://zhuanlan.zhihu.com/p/377961269
9. YOLOS:基于视觉Transformer的目标检测
You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
论文:https://arxiv.org/abs/2106.00666
代码:https://github.com/hustvl/YOLOS
论文解读:致敬YOLO!华科提出YOLOS:基于视觉Transformer的目标检测

NeurIPS 2021收录交流群
欢迎已经中稿的同学加入交流群,方便交流开会事宜;另外如果你想报道你的论文工作,也可以跟小助手联系。
注:已经在CVer的NeurIPS 2021投稿群的同学不必重复进群,投稿群现在也就是收录群,已合并处理。
【加群方式】添加小助手微信:CVer111,加群备注:NIPS中稿+公司/学习+昵称。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看