Spark性能监测+集群配置
spark-dashboard
参考链接
架构图
Spark官网中提供了一系列的接口可以查看任务运行时的各种指标

运行
卸载docker
https://blog.csdn.net/wangerrong/article/details/126750198
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
安装docker
# 默认的yum镜像源
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 1、yum 包更新到最新
yum update
# 2、安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
yum install -y yum-utils device-mapper-persistent-data lvm2
# 3、 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 4、 安装docker,出现输入的界面都按 y
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 5、 查看docker版本,验证是否验证成功
docker -v
Docker.pdf
# root启动docker服务
systemctl start docker
# 自动开启docker服务
systemctl enable docker
使用国内docker镜像源
https://blog.csdn.net/ximaiyao1984/article/details/128595319
vim /etc/docker/daemon.json
# 加入以下内容
{
"registry-mirrors": [
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://registry.docker-cn.com"
]
}
service docker restart
docker info
下载并运行Spark dashboard的docker镜像(第一次使用)
// 创建docker容器 名字为monitor -d 为后台运行参数
docker run --restart=always --network=host --name=monitor -d lucacanali/spark-dashboard:v01
之后使用
# 设置自动启动容器
docker update --restart=always monitor
docker start monitor
配置Spark参数
这里做的目的就是将Spark提供的接口数据传送到Spark dashboard中
复制
metrics.properties.template为metrics.properties(非常关键)
编辑metrics.properties文件,加入以下代码:
*.sink.graphite.class=org.apache.spark.metrics.sink.GraphiteSink
# docker运行在哪台机器上就填哪台43.143.103.171
*.sink.graphite.host=hadoop102
*.sink.graphite.port=2003 #端口不要自己更改
# 默认收集信息周期为10s,感觉太长了,可以设置成2s
*.sink.graphite.period=2
*.sink.graphite.unit=seconds
# 平台中的用户名
*.sink.graphite.prefix=jaken
*.source.jvm.class=org.apache.spark.metrics.source.JvmSource
注意分发配置文件!!!!!!!!!!
xsync
登录控制台
http://hadoop102:3000/
在Dashboards中的Browser中找到_v04

运行示例作业
/opt/module/spark3.1/bin/spark-submit --master yarn --deploy-mode cluster /opt/module/spark3.1/examples/src/main/python/pi.py 3000
结果
注意设置右上角的时间
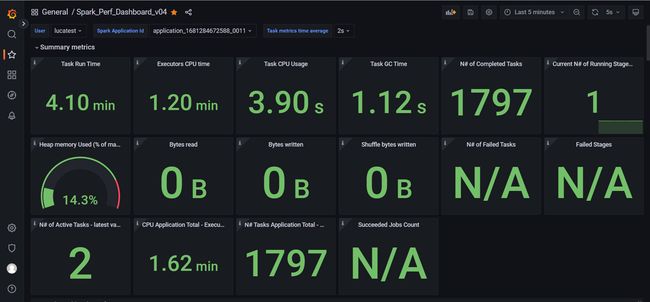
鼠标放在图上 按v可以放大查看

修改最短时间间隔

运行下Hibench
/opt/module/Hibench/hibench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh
/opt/module/Hibench/hibench-master/HiBench-master/bin/workloads/micro/wordcount/spark/run.sh
turbostat
命令行
// 以1秒为周期 焦耳为单位 记录保存在test_record中
turbostat -i 1 -J -o ./test_record

相关说明
Package 处理器包号 – 在只有一个处理器包的系统上不出现
CPU Linux的CPU(逻辑处理器)编号
TSC_MHz 整个间隔期间TSC运行的平均MHz
PkgWatt 整个处理器包所消耗的瓦特
CorWatt 由处理器包的核心部分消耗的瓦特
IRQ 在测量区间内,该CPU所服务的中断数
SMI 在测量时间段内为CPU服务的系统管理中断的数量(所有CPU)
CPU%c1 CPU%c3 CPU%c6 CPU%c7 显示的是硬件核心空闲状态下的驻留百分比。 这些数字来自硬件驻留计数器。
Totl%C0 Any%C0 GFX%C0 CPUGFX%
Pkg%pc8 Pkg%pc9 Pk%pc10 在硬件包空闲状态下的驻留百分比。 这些数字来自硬件驻留计数器。
GFXWatt 由软件包的图形部分消耗的瓦特
RAMWatt 由 DRAM DIMMS 消耗的瓦特
PKG_% RAPL节流在软件包上激活的时间间隔的百分比。
RAM_% RAPL对DRAM进行节流的时间间隔的百分比
lscpu
查看cpu的详细信息

psutil
是python的一个用来测量CPU/MEMO/IO/NET的工具
可以
监测单个进程的资源利用率
参考文档
参考博客
#!/usr/bin/env python
# coding:utf-8
import psutil
import datetime
import time
import platform
import socket
import sys
import os
import json
import redis
from multiprocessing import Process
# 声明进程的类型
monitor_process_types = ['python', 'java', 'scrapy', 'you-get']
# 计算进程的信息
def cal_process_msg(process_all_msg,process):
# 进程数
process_all_msg['process_num'] += 1
for process_type in monitor_process_types:
if process_type in process['name'] or process_type in process['cmdline'] or process_type in process['exe']:
process_all_msg[process_type] += 1
if "run" in process['status']:
process_all_msg['process_running_num'] += 1
process_all_msg["process_running_mem_percent"] += process.get("memory_percent")
else:
if "stop" in process['status']:
process_all_msg['process_stopped_num'] += 1
process_all_msg["process_stopped_mem_percent"] += process.get("memory_percent")
else:
process_all_msg['process_sleeping_num'] += 1
process_all_msg["process_sleeping_mem_percent"] += process.get("memory_percent")
def get_disk_speed(interval):
disk_msg = psutil.disk_io_counters()
read_count, write_count = disk_msg.read_count, disk_msg.write_count
read_bytes, write_bytes = disk_msg.read_bytes, disk_msg.write_bytes
read_time, write_time = disk_msg.read_time, disk_msg.write_time
time.sleep(interval)
disk_msg = psutil.disk_io_counters()
read_count2, write_count2 = disk_msg.read_count, disk_msg.write_count
read_bytes2, write_bytes2 = disk_msg.read_bytes, disk_msg.write_bytes
read_time2, write_time2 = disk_msg.read_time, disk_msg.write_time
read_count_speed = str(int((read_count2 - read_count) / interval)) + " 次/s"
write_count_speed = str(int((write_count2 - write_count) / interval)) + " 次/s"
read_bytes_speed = (read_bytes2 - read_bytes) / interval
read_bytes_speed = str(round((read_bytes_speed / 1048576), 2)) + " MB/s" if read_bytes_speed >= 1048576 else str(
round((read_bytes_speed / 1024), 2)) + " KB/s"
write_bytes_speed = (write_bytes2 - write_bytes) / interval
write_bytes_speed = str(round((write_bytes_speed / 1048576), 2)) + " MB/s" if write_bytes_speed >= 1048576 else str(
round((write_bytes_speed / 1024), 2)) + " KB/s"
return read_count_speed, write_count_speed, read_bytes_speed, write_bytes_speed
def get_net_speed(interval):
net_msg = psutil.net_io_counters()
bytes_sent, bytes_recv = net_msg.bytes_sent, net_msg.bytes_recv
time.sleep(interval)
net_msg = psutil.net_io_counters()
bytes_sent2, bytes_recv2 = net_msg.bytes_sent, net_msg.bytes_recv
sent_speed = (bytes_sent2 - bytes_sent) / interval
sent_speed = str(round((sent_speed / 1048576), 2)) + " MB/s" if sent_speed >= 1048576 else str(
round((sent_speed / 1024), 2)) + " KB/s"
recv_speed = (bytes_recv2 - bytes_recv) / interval
recv_speed = str(round((recv_speed / 1048576), 2)) + " MB/s" if recv_speed >= 1048576 else str(
round(recv_speed / 1024, 2)) + " KB/s"
return sent_speed, recv_speed
def main():
server_info = {}
print('-----------------------------系统信息-------------------------------------')
os_info = {}
os_name = platform.platform()
pc_name = platform.node()
processor = platform.processor()
processor_bit = platform.architecture()[0]
myname = socket.gethostname()
myaddr = socket.gethostbyname(myname)
print(f"{'系统信息:':<15s}{os_name}")
print(f"{'机器名称:':<15s}{pc_name}")
print(f"{'处理器:':<15s}{processor}")
print(f"{'处理器位数:':<15s}{processor_bit}")
print(f"{'IP地址:':<15s}{myaddr}")
# print(f"系统信息:{os_name:>6s}\n机器名称:{pc_name}\n处理器:{processor}\n处理器位数:{bit_msg}\nIP:{myaddr}")
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
boot_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(psutil.boot_time())))
users_count = len(psutil.users())
users_list = ",".join([u.name for u in psutil.users()])
print(f"{'当前用户数量:':<15s}{users_count}")
print(f"{'n当前用户名:':<15s}{users_list}")
boot_time_seconds = time.strptime(boot_time, "%Y-%m-%d %H:%M:%S")
boot_time_seconds = int(time.mktime(boot_time_seconds))
boot_hours = str(round((int(time.time()) - boot_time_seconds) / (60 * 60), 1)) + "小时"
print(f"{'系统启动时间:':<15s}{boot_time}")
print(f"{'系统当前时间:':<15s}{now_time}")
print(f"{'系统已经运行:':<15s}{boot_hours}")
ip = myaddr[myaddr.rfind(".")+1:]
os_info['os_ip'] = ip
os_info['os_name'] = os_name
os_info['os_pcname'] = pc_name
os_info['os_processor'] = processor
os_info['os_processor_bit'] = processor_bit
os_info['os_boot_hours'] = boot_hours
os_info['os_users_count'] = users_count
server_info["os_info"] = os_info
print('-----------------------------cpu信息-------------------------------------')
cpu_info = {}
cpu_cores = psutil.cpu_count(logical=False)
cpu_logic_cores = psutil.cpu_count(logical=True)
cpu_used_percent = str(psutil.cpu_percent(interval = 1,percpu=False)) + '%'
# cpu_used_average = 0
# for i in psutil.cpu_percent(interval = 1,percpu=True):
# cpu_used_average += i
# cpu_used_average = cpu_used_average/len(psutil.cpu_percent(interval = 1,percpu=True))
# print(cpu_used_average)
print(f"{'cpu使用率:':<15s}{cpu_used_percent}")
print(f"{'物理cpu数量:':<15s}{cpu_cores}")
print(f"{'逻辑cpu数量:':<15s}{cpu_logic_cores}")
cpu_info['cpu_used_percent'] = cpu_used_percent
cpu_info['cpu_cores'] = cpu_cores
cpu_info['cpu_logic_cores'] = cpu_logic_cores
server_info["cpu_info"] = cpu_info
print('-----------------------------内存信息-------------------------------------')
memory_info = {}
memory = psutil.virtual_memory()
mem_total = str(round(memory.total / (1024.0 * 1024.0 * 1024.0), 2)) + "Gb"
mem_free = str(round(memory.free / (1024.0 * 1024.0 * 1024.0), 2)) + "Gb"
mem_available = str(round(memory.available / (1024.0 * 1024.0 * 1024.0), 2)) + "Gb"
mem_used_percent = str(memory.percent) + "%"
mem_used = str(round(memory.used / (1024.0 * 1024.0 * 1024.0), 2)) + "Gb"
try:
buffers = str(round(memory.buffers / (1024.0 * 1024.0 * 1024.0), 2)) + "Gb"
cached = str(round(memory.cached / (1024.0 * 1024.0 * 1024.0), 2)) + "Gb"
except:
buffers = cached = ""
print(f"{'内存使用率:':<15s}{mem_used_percent}")
print(f"{'总内存:':<15s}{mem_total}")
print(f"{'已使用内存:':<15s}{mem_used}")
print(f"{'剩余内存:':<15s}{mem_free}")
print(f"{'available内存:':<15s}{mem_available}")
print(f"{'cached使用的内存:':<15s}{cached}")
print(f"{'buffers使用的内存:':<15s}{buffers}")
memory_info['mem_used_percent'] = mem_used_percent
memory_info['mem_total'] = mem_total
memory_info['mem_used'] = mem_used
memory_info['mem_free'] = mem_free
memory_info['mem_cached'] = cached
memory_info['mem_buffers'] = buffers
server_info["memory_info"] = memory_info
print('-----------------------------磁盘信息---------------------------------------')
# disk_msg = psutil.disk_usage("")
# disk_total = str(int(disk_msg.total / (1024.0 * 1024.0 * 1024.0))) + "G"
# disk_used = str(int(disk_msg.used / (1024.0 * 1024.0 * 1024.0))) + "G"
# disk_free = str(int(disk_msg.free / (1024.0 * 1024.0 * 1024.0))) + "G"
# disk_percent = float(disk_msg.percent)
# print(f"磁盘总容量:{disk_total},已用容量:{disk_used},空闲容量:{disk_free},使用率:{disk_percent}%")
# print("系统磁盘信息:" + str(io))
disk_info = {}
disk_partitons = psutil.disk_partitions()
for disk in disk_partitons:
print(disk)
try:
o = psutil.disk_usage(disk.mountpoint)
path = disk.device
total = str(int(o.total / (1024.0 * 1024.0 * 1024.0))) + "G"
used = str(int(o.used / (1024.0 * 1024.0 * 1024.0))) + "G"
free = str(int(o.free / (1024.0 * 1024.0 * 1024.0))) + "G"
percent = o.percent
print(f"磁盘路径:{path},总容量:{total},已用容量{used},空闲容量:{free},使用率:{percent}%")
if disk.mountpoint == "/":
disk_info["total"] = total
disk_info["used"] = used
disk_info["free"] = free
disk_info["percent"] = percent
except:
print("获取异常", disk)
read_count_speed, write_count_speed, read_bytes_speed, write_bytes_speed = get_disk_speed(3)
print("硬盘实时IO")
print(f"读取次数:{read_count_speed} 写入次数:{write_count_speed}")
print(f"读取速度:{read_bytes_speed} 写入速度:{write_bytes_speed}")
disk_info['disk_read_count_speed'] = read_count_speed
disk_info['disk_write_count_speed'] = write_count_speed
disk_info['disk_read_bytes_speed'] = read_bytes_speed
disk_info['disk_write_bytes_speed'] = write_bytes_speed
server_info["disk_info"] = disk_info
print('-----------------------------网络信息-------------------------------------')
net_info = {}
sent_speed, recv_speed = get_net_speed(1)
print(f"网络实时IO\n上传速度:{sent_speed}\n下载速度:{recv_speed}")
net = psutil.net_io_counters()
sent_bytes = net.bytes_recv / 1024 / 1024
recv_bytes = net.bytes_sent / 1024 / 1024
sent_bytes = str(round(sent_bytes, 2)) + "MB" if sent_bytes < 1024 else str(round(sent_bytes / 1024, 2)) + "GB"
recv_bytes = str(round(recv_bytes, 2)) + "MB" if recv_bytes < 1024 else str(round(recv_bytes / 1024, 2)) + "GB"
print(f"网卡总接收流量{recv_bytes}\n总发送流量{sent_bytes}")
net_info['net_sent_speed'] = sent_speed
net_info['net_recv_speed'] = recv_speed
net_info['net_recv_bytes'] = recv_bytes
net_info['net_sent_bytes'] = sent_bytes
server_info["net_info"] = net_info
print('-----------------------------进程信息-------------------------------------')
# 查看系统全部进程
processes_info = {}
processes_info['process_running_num'] = 0
processes_info['process_sleeping_num'] = 0
processes_info['process_stopped_num'] = 0
for process_type in monitor_process_types:
processes_info[process_type] = 0
processes_info["process_sleeping_mem_percent"] = 0
processes_info["process_stopped_mem_percent"] = 0
processes_info["process_running_mem_percent"] = 0
processes_info['process_num'] = 0
processes_info['process_memory_used_top10'] = []
process_list = []
for pnum in psutil.pids():
try:
p = psutil.Process(pnum)
#print("====================================")
process = {}
process['name'] = p.name()
process['cmdline'] = p.cmdline()
process['exe'] = p.exe()
process['status'] = p.status()
process['create_time'] = str(datetime.datetime.fromtimestamp(p.create_time()))[:19]
process['terminal'] = p.terminal()
#process['cpu_times'] = p.cpu_times()
#process['cpu_affinity'] = p.cpu_affinity()
#process['memory_info'] = p.memory_info()
process['memory_percent'] = p.memory_percent()
process['open_files'] = p.open_files()
#process['connections'] = p.connections()
process['io_counters'] = p.io_counters()
process['num_threads'] = p.num_threads()
cal_process_msg(processes_info,process)
process_list.append(process)
#print(process)
# print(f"进程名: {p.name()} 进程状态: {p.status()} 命令: {p.cmdline()} 进程号: {p.pid} 路径1: {p.exe()} 路径2: {p.cwd()} 内存占比: {round(p.memory_percent(),2)}%")
except:
pass
processes_info["process_sleeping_mem_percent"] = str(processes_info["process_sleeping_mem_percent"])[:5] + "%"
processes_info["process_stopped_mem_percent"] = str(processes_info["process_stopped_mem_percent"])[:5] + "%"
processes_info["process_running_mem_percent"] = str(processes_info["process_running_mem_percent"] )[:5] + "%"
process_list = sorted(process_list, key=lambda x: (-int(x['memory_percent'])), reverse=False)
print(process_list[:10])
for i in process_list[:10]:
top_10_info = i.get("cmdline")[0] + " " + i.get("cmdline")[1] + " " + str(i.get("memory_percent"))[:5] + "%"
processes_info['process_memory_used_top10'].append(top_10_info)
print(processes_info)
server_info["processes_info"] = processes_info
server_info_json = json.dumps(server_info,ensure_ascii = False,indent=4)
print(server_info_json)
pool = redis.ConnectionPool(host='ip', port=6379, decode_responses=True,
password='password',
db=2) # host是redis主机,需要redis服务端和客户端都起着 redis默认端口是6379
r = redis.Redis(connection_pool=pool)
r.hset("server_info",ip,server_info_json)
if __name__ == "__main__":
main()
print(sys.argv[0], os.getpid())
jvm_top
监视每个JVM的负载情况,直接使用
jvmtop.sh命令即可
参考文档

迭代计算
![]()
elasecutor
![]()
配置集群
创建用户
useradd jaken
passwd jaken
增加权限
[root@hadoop100 ~]# vim /etc/sudoers
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
jaken ALL=(ALL) NOPASSWD:ALL

虚拟机配置


网络配置
| 10.0.4.2 | 43.143.103.171 |
|---|---|
| 10.0.12.17 | 43.139.163.74 |
| 172.16.0.15 | 129.204.194.101 |
| 10.0.20.12 | 119.29.244.191 |
| 10.0.12.13 | 114.132.62.39 |
192.168.195.184 jk102
192.168.195.163 jk103
192.168.195.225 jk104
192.168.195.68 feizi102
192.168.195.49 feizi103
192.168.195.125 feizi104
修改主机名
这一步也非常重要 hadoop依赖hostname
sudo vim /etc/hostname
![]()
设置IP别名
sudo vim /etc/hosts
如果是本机,用内网IP,否则用外网IP!!!!!!!!

windows下
C:\Windows\System32\drivers\etc
拷贝host文件到桌面,添加对应的IP别名后在粘贴回去
环境变量
先放一台主机 后面同步即可
/etc/profile
sudo vim /etc/profile最后加入以下内容
export JAVA_HOME=/opt/module/jdk1.8.0_371
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export SPARK_HOME=/opt/module/spark3.1
export PYSPARK_PYTHON=/opt/module/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export ZK_HOME=/opt/module/zookeeper
export SCALA_HOME=/opt/module/scala/scala-2.12.15
export MAVEN_HOME=/opt/module/maven/apache-maven-3.8.6
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin:$SCALA_HOME/bin:$MAVEN_HOME/bin:$PATH
~/.bashrc
sudo vim ~/.bashrc
# 添加下面内容
export JAVA_HOME=/opt/module/jdk1.8.0_371
export PYSPARK_PYTHON=/opt/module/anaconda3/envs/pyspark/bin/python3.8
my_env.sh
sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_371
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 使用root用户需要注意----绝不推荐使用root用户
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
source /etc/profile
脚本
复制粘贴脚本文件在~/bin下
确保命令路径在下面的输出中
[atguigu@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/atguigu/bin:/opt/module/jdk1.8.0_212/bin
粘贴 cluster_conf 下的脚本
D:\OneDrive - stu.csust.edu.cn\16cluster_conf\脚本
添加执行权限
chmod +x jpsall jvmtop myhadoop.sh myspark.sh restartcluster.sh shutdowncluster.sh xsync zkstatus
端口配置

SSH免密登录
默认在当前用户的家目录下有.ssh目录
ll -al 可以查看


生成秘钥并拷贝
cd ~
rm -rf .ssh
ssh-keygen -t rsa
ssh-copy-id jk102
ssh-copy-id jk103
ssh-copy-id jk104
ssh-copy-id feizi102
ssh-copy-id feizi103
ssh-copy-id feizi104
05200570.
Matmat0000
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)

所有机器都要生成秘钥并拷贝!!!
安装JDK1.8
一般新的机器没有自带JDK
# 卸载自带的JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
D:\OneDrive - stu.csust.edu.cn\16cluster_conf

解压到/opt/module/
tar -zxvf jdk-8u371-linux-x64.tar.gz -C /opt/module/
java -version
快速安装ALL
D:\OneDrive - stu.csust.edu.cn\16cluster_conf
进入/opt/software中
tar -zxvf scala.tar.gz -C /opt/module/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
tar -zxvf spark3.1.tar.gz -C /opt/module/
因为之前我们的环境变量已经配好了 所以scala可以直接使用
hadoop 需要先删除 data和logs目录
cd /opt/module/hadoop-3.1.3/
rm -rf data/ logs
vim core-site.xml
将HDFS的用户名修改为jaken
安装hadoop3.1.3
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
hadoop-3.1.3.tar.gz 分发压缩包
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
# 检查是否安装成功
hadoop version
配置hadoop
修改副本数
https://blog.csdn.net/Kevinwen0228/article/details/124239219
vim hdfs-site.xml
dfs.replication
3
需要修改以下文件

xsync /opt/module/hadoop-3.1.3/etc/
启动集群
第一次启动
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
第一次启动需要格式化NameNode,也就是lab001
hdfs namenode -format
myhadoop.sh start
启动HDFS
lab001
sbin/start-dfs.sh
启动yarn
lab002
sbin/start-yarn.sh
WEB查看
HDFS
http://lab001:9870
YARN
http://lab002:8088
启动yarn历史服务器
启动历史服务器
mapred --daemon start historyserver
WEB查看
http://lab001:19888/jobhistory
安装maven
apache-maven-3.8.6.tar.gz
在/opt/module 创建maven文件夹,进入文件夹,创建maven-repo文件夹, 然后将上面的文件拷贝下来,解压即可,配置项看Hi
tar -zxvf apache-maven-3.8.6.tar.gz -C /opt/module/maven
注意环境变量一定配置好
安装python
mkdir /opt/software
将Anaconda3-2023.03-Linux-x86_64.sh放到上面的文件夹中
Anaconda3-2023.03-Linux-x86_64.sh
# 执行脚本
sh Anaconda3-2023.03-Linux-x86_64.sh
自定义安装目录

换源(推荐)
在jaken用户下:
vim ~/.condarc #新文件
#文件内容如下:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
记得分发一下
创建并进入pyspark空间
conda create -n pyspark python=3.8

PYSPARK_PYTHON和 JAVA_HOME 需要同样配置在: ~/.bashrc中
sudo vim ~/.bashrc
export JAVA_HOME=/opt/module/jdk1.8.0_371
export PYSPARK_PYTHON=/opt/module/anaconda3/envs/pyspark/bin/python3.8
source ~/.bashrc
安装spark
Spark历史服务器
注意先在HDFS中创建日志存储的目录
![]()
才可以开启历史服务器
如果创建失败 需要修改登入的用户名

spark3.1.tar.gz
放在/opt/module下 解压
配置下面文件

开启动态资源调度
[参考博客]((261条消息) spark任务动态资源分配_spark动态资源配置_YF_raaiiid的博客-CSDN博客)(采用第二种开启外部shuffle服务的方法)
修改
yarn-site.xml
原文件需修改的内容
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
原文件需增加的内容
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port
7337
将
$SPARK_HOME/yarn/ spark-拷贝到每台NodeManager下的-yarn-shuffle.jar ${HADOOP_HOME}/share/hadoop/yarn/lib/目录,然后重启所有修改过配置的节点。

配置
$SPARK_HOME/conf/spark-defaults.conf,增加以下参数
# 启用External shuffle Service服务
spark.shuffle.service.enabled true
# Shuffle Service默认服务端口,必须和yarn-site中的一致
spark.shuffle.service.port 7337
# 开启动态资源分配
spark.dynamicAllocation.enabled true
# 每个Application最小分配的executor数
spark.dynamicAllocation.minExecutors 2
# 每个Application最大并发分配的executor数
spark.dynamicAllocation.maxExecutors 10
# schedulerBacklogTimeout秒内有任务请求则开启申请
spark.dynamicAllocation.schedulerBacklogTimeout 1s
# 有任务在任务队列中持续了sustainedSchedulerBacklogTimeout秒则继续申请
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
# executor 空闲超过60s 则释放
spark.dynamicAllocation.executorIdleTimeout 60s
# 如果启用动态分配,则要运行executor的初始数量。如果设置了“–num-executors”(或“spark.executor.instances”)并且大于这个值,则会使用这个值进行初始化。 如:max(initialExecuor = 3, –num-executors = 10) 取最大
spark.dynamicAllocation.initialExecutors 2
# 如果启用了动态分配,并且缓存数据块的executor已经空闲了超过这个时间,executor将被释放
spark.dynamicAllocation.cachedExecutorIdleTimeout 60s
/opt/module/spark3.1/bin/spark-submit --properties-file /opt/module/hibench/HiBench-master/HiBench-master/report/terasort/spark/conf/sparkbench/spark.conf --class com.intel.hibench.sparkbench.micro.ScalaTeraSort --master yarn --num-executors 3 --executor-cores 2 --executor-memory 6g /opt/module/hibench/HiBench-master/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-8.0-SNAPSHOT-dist.jar hdfs://hadoop102:8020/hibench_test/HiBench/Terasort/Input hdfs://hadoop102:8020/hibench_test/HiBench/Terasort/Output
启动任务命令
/opt/module/spark3.1/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 6G --executor-cores 2 /opt/module/spark3.1/examples/jars/spark-examples_2.12-3.1.3.jar 1000
/opt/module/spark3.1/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 --deploy-mode cluster --executor-memory 6G --executor-cores 2 /opt/module/spark3.1/examples/jars/spark-examples_2.12-3.1.3.jar 1000
/opt/module/spark3.1/bin/spark-submit --master yarn --deploy-mode cluster --executor-memory 8G --executor-cores 2 /opt/module/spark3.1/examples/src/main/python/pi.py 1000
hibench
/opt/module/spark3.1/bin/spark-submit --class com.intel.hibench.sparkbench.micro.ScalaTeraSort --master yarn --executor-memory 6G --executor-cores 2 /opt/module/hibench/HiBench-master/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-8.0-SNAPSHOT-dist.jar hdfs://hadoop102:8020/hibench_test/HiBench/Terasort/Input hdfs://hadoop102:8020/hibench_test/HiBench/Terasort/Output
运行结果
准备数据和jar包阶段

hadoop MapReduce运行

虚拟局域网
zerotier
https://my.zerotier.com/network
如果使用xshell工具 记得Windows也要下载
https://www.zerotier.com/download/
192.168.195.184 jk102
192.168.195.163 jk103
192.168.195.225 jk104
192.168.195.68 feizi102
192.168.195.49 feizi103
192.168.195.125 feizi104
连接
sudo zerotier-cli join 856127940c63df82
iperf 带宽测试
安装
sudo yum install iperf
使用
iperf -s
// iperf -c 192.168.195.184
iperf -c <服务器IP地址>
出现的问题
传输文件太慢,网络带宽引起
systemctl stop NetworkManager 临时关闭
systemctl disable NetworkManager 永久关闭网络管理命令
systemctl start network.service 开启网络服务
控制台输出内容
23/04/26 14:28:52 INFO DataStreamer: Slow ReadProcessor read fields for block BP-2104837750-10.0.4.2-1682347630921:blk_1073741886_1062 took 42664ms (threshold=30000ms); ack: seqno: 1206 reply: SUCCESS reply: SUCCESS reply: SUCCESS downstreamAckTimeNanos: 42663295164 flag: 0 flag: 0 flag: 0, targets: [DatanodeInfoWithStorage[10.0.4.2:9866,DS-57566ce7-f785-4cb8-b191-7ba233c7a17a,DISK], DatanodeInfoWithStorage[129.204.194.101:9866,DS-ca81dc10-4c88-4713-830e-07d582cee8cf,DISK], DatanodeInfoWithStorage[43.139.163.74:9866,DS-23a6defa-ae70-4ad6-88db-5703dc31bb5c,DISK]]
2023-04-25 08:57:48,081 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: DatanodeRegistration(43.139.163.74:9866, datanodeUuid=f01ec0ce-cbe0-4e8c-bb96
-8beab9adf74d, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-ea7287bd-3b77-4206-910b-6f3ffb7e51a0;nsid=515203780;c=168234763092
1) Starting thread to transfer BP-2104837750-10.0.4.2-1682347630921:blk_1073741840_1016 to 10.0.4.2:9866
2023-04-25 08:57:48,082 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: DatanodeRegistration(43.139.163.74:9866, datanodeUuid=f01ec0ce-cbe0-4e8c-bb96
-8beab9adf74d, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-ea7287bd-3b77-4206-910b-6f3ffb7e51a0;nsid=515203780;c=168234763092
1) Starting thread to transfer BP-2104837750-10.0.4.2-1682347630921:blk_1073741843_1019 to 10.0.4.2:9866
2023-04-25 08:58:48,141 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: DatanodeRegistration(43.139.163.74:9866, datanodeUuid=f01ec0ce-cbe0-4e8c-bb96
-8beab9adf74d, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-ea7287bd-3b77-4206-910b-6f3ffb7e51a0;nsid=515203780;c=168234763092
1):Failed to transfer BP-2104837750-10.0.4.2-1682347630921:blk_1073741840_1016 to 10.0.4.2:9866 got
org.apache.hadoop.net.ConnectTimeoutException: 60000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel
[connection-pending remote=/10.0.4.2:9866]
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:534)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.hdfs.server.datanode.DataNode$DataTransfer.run(DataNode.java:2529)
at java.lang.Thread.run(Thread.java:750)
修改hdfs-site,添加以下内容
dfs.client.use.datanode.hostname
true
Whether datanodes should use datanode hostnames when
connecting to other datanodes for data transfer.
一开始我认为是内外网的IP设置问题,其实并不是,而是lab003的网络带宽问题

端口对集群内全部开放
spark-submit提交后,集群的所有服务jps都无法查看到,但却是正常运行的

SSHD病毒

https://blog.csdn.net/liujinghu/article/details/125288926
查看进程
ll /proc/{pid}
查看定时任务
crontab -l
删除定时任务
crontab -r
查看定时服务状态并关闭
/bin/systemctl status crond.service
service crond stop
删除文件夹
sudo rm -rf /var/tmp/*
sudo rm -rf /tmp
限制校园网登录
su
# 迅速登录几次服务器
# 查看登录的ip,就是校园网的服务器ip
tail -n 50 secure
# 实时查看
tail -f /var/log/secure

在安全组中设置限制
![]()
不使用启动脚本
# 开启 ===================================
lab001 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
lab001 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
lab001 "/opt/module/spark3.1/sbin/start-history-server.sh"
lab002 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
# 关闭 ===================================
lab001 "/opt/module/spark3.1/sbin/stop-history-server.sh"
lab001 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
lab001 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
lab002 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
开启防火墙(不能开,开了就连不起来了)
安全组充当了服务器的虚拟防火墙
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开启启动
systemctl restart firewalld.service #重启防火墙使配置生效
systemctl enable firewalld.service #设置防火墙开机启动
firewall-cmd --state #检查防火墙状态
not running #返回值,未运行
43.139.163.74:22

定时任务
crontab -r
查看定时服务状态并关闭
/bin/systemctl status crond.service
service crond stop
删除文件夹
sudo rm -rf /var/tmp/*
sudo rm -rf /tmp
限制校园网登录
su
# 迅速登录几次服务器
# 查看登录的ip,就是校园网的服务器ip
tail -n 50 secure
# 实时查看
tail -f /var/log/secure
[外链图片转存中…(img-xRLDSqds-1696143438913)]
在安全组中设置限制
[外链图片转存中…(img-RvhOeP6F-1696143438914)]
不使用启动脚本
# 开启 ===================================
lab001 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
lab001 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
lab001 "/opt/module/spark3.1/sbin/start-history-server.sh"
lab002 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
# 关闭 ===================================
lab001 "/opt/module/spark3.1/sbin/stop-history-server.sh"
lab001 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
lab001 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
lab002 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
开启防火墙(不能开,开了就连不起来了)
安全组充当了服务器的虚拟防火墙
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开启启动
systemctl restart firewalld.service #重启防火墙使配置生效
systemctl enable firewalld.service #设置防火墙开机启动
firewall-cmd --state #检查防火墙状态
not running #返回值,未运行
43.139.163.74:22
[外链图片转存中…(img-p9D87IM3-1696143438914)]