k8s之Pod管理和部署
k8s之Pod管理
- 一、了解pod
-
- 1. 什么是pod
- 2. 静态pod
- 4. pod容器共享volume
- 二.pod的管理和配置
-
- 1. pod的基本操作
-
- 1> 创建pod节点
- 2> 删除pod
- 3> 创建指定数量的pod
- 4> 查看节点标签
- 5> 暴露端口
- 6> Pod扩容和缩容
- 7> 更新pod镜像和回滚
- 8> 容器退出后不重启
- 9> 锁定pod节点
- 三. pod的生命周期
-
- 1. init初始化容器
- 2. 添加服务
- 3. 探针
-
- 1> 什么是探针
- 2> 存活检测-liveness
- 3> 就绪探针-readinessProbe
- 4> 添加标签将svc和pod联系
- 四. 控制器
-
- 1.ReplicaSet–rs控制器
- 2.deployments控制器
-
- 1> 更改标签
- 2> 版本更新
- 3. DaemonSet控制器
- 4.Job控制器
一、了解pod

1. 什么是pod
k8s中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象。pod的组成示意图如下:
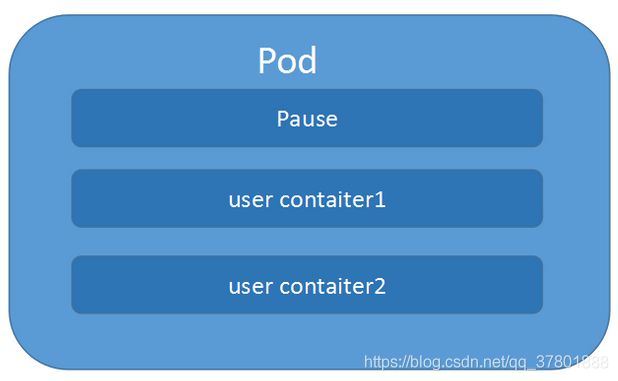
由一个叫”pause“的根容器,加上一个或多个用户自定义的容器构造。pause的状态带便了这一组容器的状态,pod里多个业务容器共享pod的Ip和数据卷。
在kubernetes环境下,pod是容器的载体,所有的容器都是在pod中被管理,一个或多个容器放在pod里作为一个单元方便管理。
还有就是docker和kubernetes也不是一家公司的,如果做一个编排部署的工具,你也不可能直接去管理别人公司开发的东西吧,然后就把docker容器放在了pod里,在kubernetes的集群环境下,我直接管理我的pod,然后对于docker容器的操作,我把它封装在pod里,不直接操作。
2. 静态pod
静态Pod是由kubelet进行管理的仅存在于特定Node上的pod.它们不能通过API Server进行管理,无法与ReplicationController,Ddeployment或者DaemonSet进行关联,也无法进行健康检查。
所以我觉得这个静态pod没啥用武之地啊,就不详细的写下去了,偷个懒,嘻嘻。
4. pod容器共享volume
在pod中定义容器的时候可以为单个容器配置volume,然后也可以为一个pod中的多个容器定义一个共享的pod 级别的volume。 那为啥要这样做呢,比如你在一个pod里定义了一个web容器,然后把生成的日志文件放在了一个文件夹,你还定义了一个分析日志的容器,那这个时候你就可以把这放日志的文件配置为共享的,这样一个容器生产,一个容器度就好了。
在Kubrenetes集群中Pod有如下两种使用方式:
a)一个Pod中运行一个容器。这是最常见用法。在这种方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
b)在一个Pod中同时运行多个容器。当多个应用之间是紧耦合的关系时,可以将多个应用一起放在一个Pod中,同个Pod中的多个容器之间互相访问可以通过localhost来通信(可以把Pod理解成一个虚拟机,共享网络和存储卷)。也就是说一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位 (即一个容器共享文件),另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
就像每个应用容器,pod被认为是临时实体。在Pod的生命周期中,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的pod,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID(查看replication controller获取详情)。
kubernetes为什么使用pod作为最小单元,而不是container
直接部署一个容器看起来更简单,但是这里也有更好的原因为什么在容器基础上抽象一层呢?根本原因是为了管理容器,kubernetes需要更多的信息,比如重启策略,它定义了容器终止后要采取的策略;或者是一个可用性探针,从应用程序的角度去探测是否一个进程还存活着。基于这些原因,kubernetes架构师决定使用一个新的实体,也就是pod,而不是重载容器的信息添加更多属性,用来在逻辑上包装一个或者多个容器的管理所需要的信息。
kubernetes为什么允许一个pod里有多个容器
pod里的容器运行在一个逻辑上的"主机"上,它们使用相同的网络名称空间 (即同一pod里的容器使用相同的ip和相同的端口段区间) 和相同的IPC名称空间。它们也可以共享存储卷。这些特性使它们可以更有效的通信,并且pod可以使你把紧密耦合的应用容器作为一个单元来管理。也就是说当多个应用之间是紧耦合关系时,可以将多个应用一起放在一个Pod中,同个Pod中的多个容器之间互相访问可以通过localhost来通信(可以把Pod理解成一个虚拟机,共享网络和存储卷)。
因此当一个应用如果需要多个运行在同一主机上的容器时,为什么不把它们放在同一个容器里呢?首先,这样何故违反了一个容器只负责一个应用的原则。这点非常重要,如果我们把多个应用放在同一个容器里,这将使解决问题变得非常麻烦,因为它们的日志记录混合在了一起,并且它们的生命周期也很难管理。因此一个应用使用多个容器将更简单,更透明,并且使应用依赖解偶。并且粒度更小的容器更便于不同的开发团队共享和复用。
Pod中可以共享两种资源:网络 和 存储
- 网络:每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。
- 存储:可以Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
二.pod的管理和配置
先开启仓库和kubectl

1. pod的基本操作
1> 创建pod节点
运行镜像:myapp:v1,并查看节点信息!


在系统的目录下查看到分配的网络信息:


访问pod生成的ip地址,可以看到myapp:v1的信息:
![]()

describe指令可以看到更详细的:


2> 删除pod
![]()
3> 创建指定数量的pod
![]()


4> 查看节点标签

查看所有节点信息:

若是删除pod节点中的任何一个,都会自动生成一个,总数永远保持不变!!
![]()
这里楼主没截到,大家自己尝试!!
5> 暴露端口
将指定端口80暴露,使得外部可以访问:
![]()
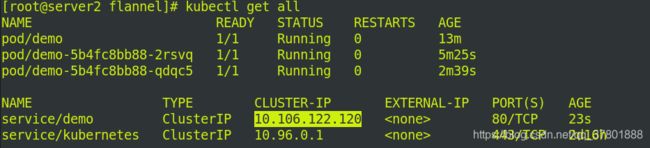
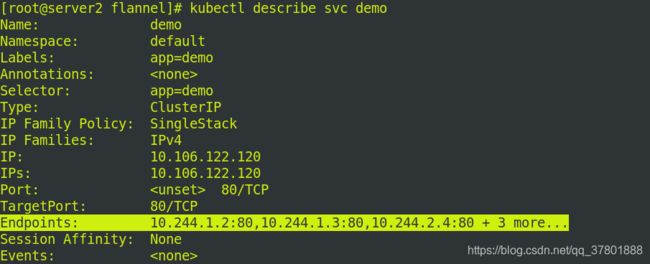
访问demo的ip,从下图可以看出是负载均衡的!!!

查看svc节点信息.
后端节点Endpoints:必须能看到生成的IP地址才是配置成功!!!

6> Pod扩容和缩容
a. 扩容
将节点个数更改为6,服务会自行为我们配置好!!!
![]()
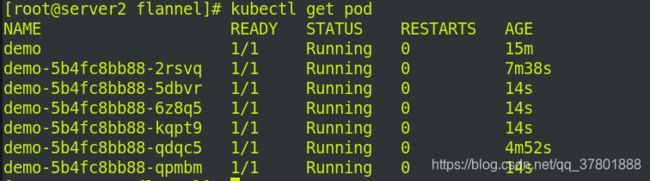
再次访问任意ip:
依然负载均衡!!

b. 缩容


7> 更新pod镜像和回滚
a. 更新
![]()
刚更新完查看时,我们可以看出正在替换!!

过一会查看:

访问更新之后的IP:
可以看到版本是v2
![]()
查看版本迭代的历史信息:

b. 回滚
![]()

访问ip:
可以看到版本退回了v1
![]()
查看rs信息:
说明此时是下面的版本

8> 容器退出后不重启
kubectl run -it busybox --image=busyboxplus --restart=Never
ip addr
退出
kubectl get pod
不加参数就会重新启动容器:
删除刚才的容器busybox!重新创建容器,不加参数!
kubectl delete pod busybox
kubectl run -i -t busybox --image=busyboxplus
ip addr
kubectl get pod
删除busybox容器,删除pod节点
查看标签!
kubectl delete pod busbox
kubectl delete -f pod,yaml
kubectl get node --show-labels
9> 锁定pod节点

锁定pod节点在server4上!
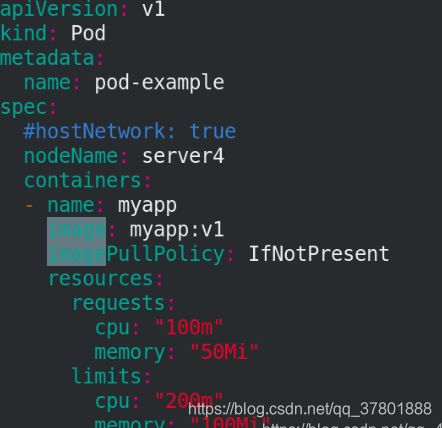

kubectl apply -f pod.yaml
kubectl get pod -o wide (查询时可以看到节点在server4上)

三. pod的生命周期


1. init初始化容器
![]()

执行初始化:
![]()
此处执行之前清理svc和pod
执行完成之后:


只有一个服务时,初始化未成功,会不停重启进行初始化!
2. 添加服务
![]()
在后面添加以下内容:

查询pod和svc


查看容器解析:

删除初始化:
kubectl delete -f init.yaml
3. 探针
1> 什么是探针
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。
有三种类型的处理程序:
| ExecAction | 在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功 |
|---|---|
| TCPSocketAction | 对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的 |
| HTTPGetAction | 对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的 |
每次探测都将获得以下三种结果之一:
成功:容器通过了诊断。
失败:容器未通过诊断。
未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为 Success。
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
- startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success
2> 存活检测-liveness
images:myapp:v1
![]()

添加如下内容:



查看存活探针的信息:

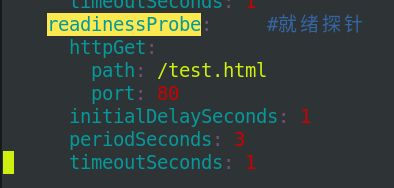
3> 就绪探针-readinessProbe
![]()
![]()

4> 添加标签将svc和pod联系
![]()
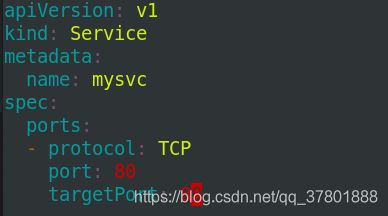



但是此时endpoints是没有就绪的:

因为pod.yaml指定了文件为test.html 但nginx中没有test.html
进入容器,添加测试页
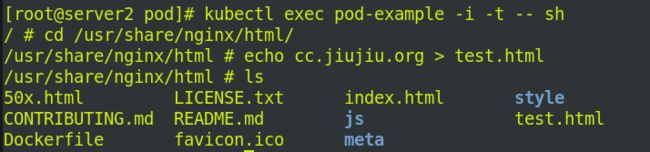

再次查看endpoints是否就绪:
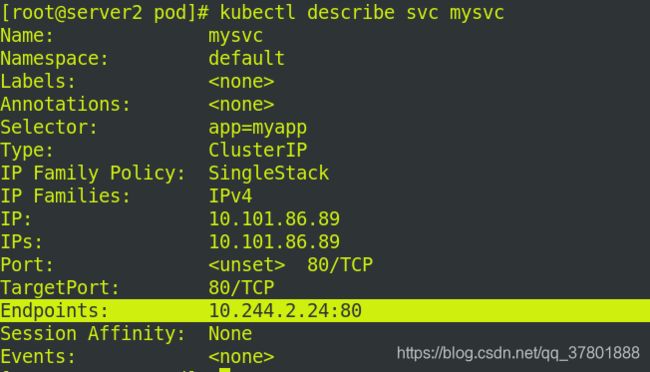
![]()
四. 控制器

1.ReplicaSet–rs控制器

rs控制器:控制副本,确定任何时间都有指定数量的Pod副本在运行,根据标签匹配。
![]()

![]()



拉伸,将个数更改为6:
![]()
这时可以看到有6个节点:
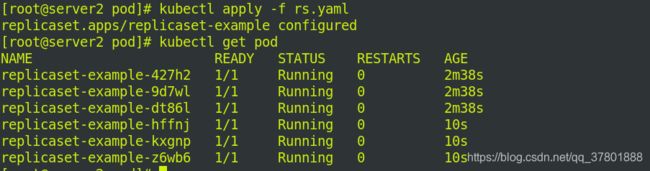
查看标签:
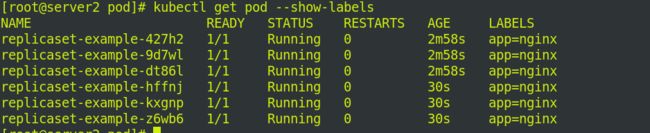
修改节点标签,–overwrite:覆盖节点标签


此时我们删除任意节点:
![]()
再次查询还是6个,删除一个,服务会为我们快速部署下一个:
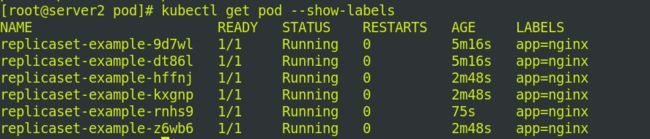
2.deployments控制器

![]()

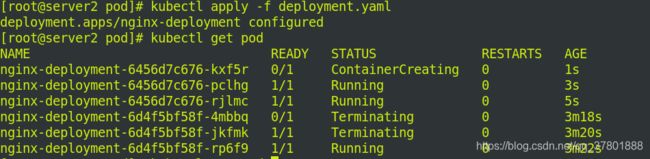


访问ip:
![]()

1> 更改标签
![]()
将最后的myapp:v1更改为myapp:v2
![]()
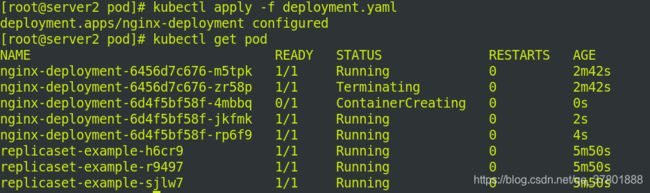
删除rs.yaml文件:
![]()


访问
![]()
2> 版本更新
![]()
![]()



访问ip:


3. DaemonSet控制器

![]()

kubectl apply -f daemonset.yaml

4.Job控制器
在server1上拉取镜像perl.tar,并上传到私有仓库中

![]()

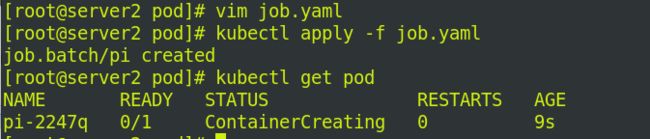
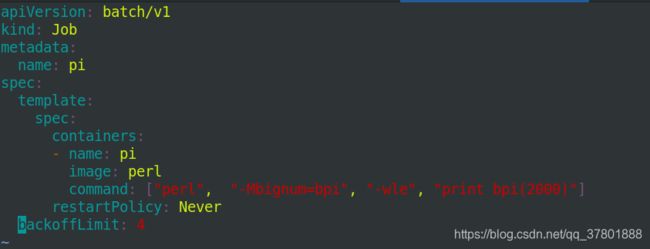

写一个定时清单:
![]()


kubectl logs cronjob-example-****

完成之后,删除cronjob.yaml清单即可!