K8s之service的管理和部署
K8s之service的管理和部署
- 一、了解service
-
- 1. 什么是service
- 2. Service的三种工作方式:
- 二、IPVS模式
-
- 1.更改ipvs模式
- 2.更新pod
- 三.kube-dns(k8s内置dns解析服务,用于实现域名访问)
- 四. Headless无头模式
-
- 1. 配置
- 2. 版本更新
- 五、service的外部访问
-
- 1. nodeport
-
- 1> 了解nodeport
- 2> nodeport的部署
- 2.LoadBalancer
-
- 1> 了解loadBalancer
- 2> loadBalancer部署
- 3> 定义地址池
- 3. Ingress
-
- 1> 了解ingress
- 2> ingress部署
- 3> 域名访问+ingress-nginx
-
- 添加第一个域名
- 第二个域名
一、了解service
1. 什么是service

![]()
2. Service的三种工作方式:
第一种: 是Userspace方式
如下图描述, Client Pod要访问Server Pod时,它先将请求发给本机内核空间中的service规则,由它再将请求,
转给监听在指定套接字上的kube-proxy,kube-proxy处理完请求,并分发请求到指定Server Pod后,再将请求
递交给内核空间中的service,由service将请求转给指定的Server Pod。
由于其需要来回在用户空间和内核空间交互通信,因此效率很差,接着就有了第二种方式.
第二种: iptables模型
此工作方式是直接由内核中的iptables规则,接受Client Pod的请求,并处理完成后,直接转发给指定ServerPod.
第三种: ipvs模型
它是直接有内核中的ipvs规则来接受Client Pod请求,并处理该请求,再有内核封包后,直接发给指定的Server Pod。
以上不论哪种,kube-proxy都通过watch的方式监控着kube-APIServer写入etcd中关于Pod的最新状态信息,
它一旦检查到一个Pod资源被删除了 或 新建,它将立即将这些变化,反应再iptables 或 ipvs规则中,以便
iptables和ipvs在调度Clinet Pod请求到Server Pod时,不会出现Server Pod不存在的情况。
自k8s1.1以后,service默认使用ipvs规则,若ipvs没有被激活,则降级使用iptables规则. 但在1.1以前,service使用的模式默认为userspace.
二、IPVS模式
安装服务:
![]()

1.更改ipvs模式
![]()
将模式更改为ipvs:
![]()

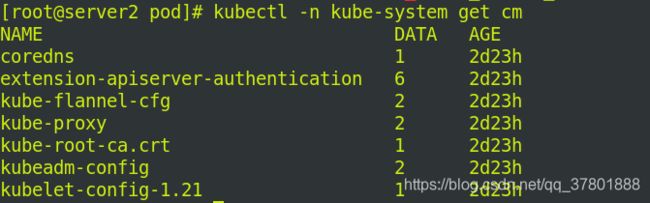
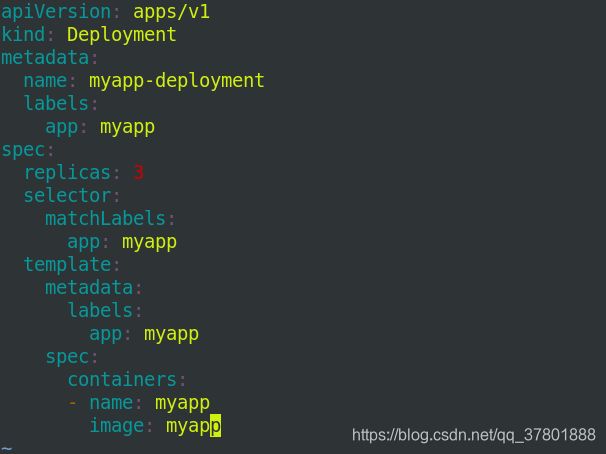
2.更新pod

修改清单deployment.yaml 的镜像为myapp:v1
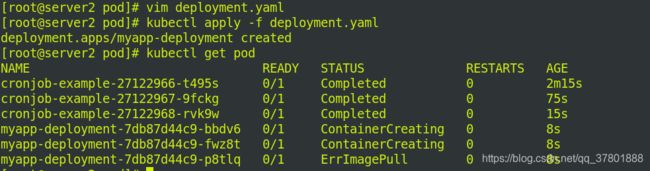
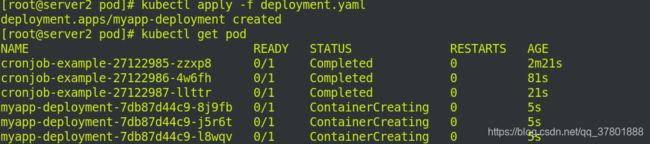
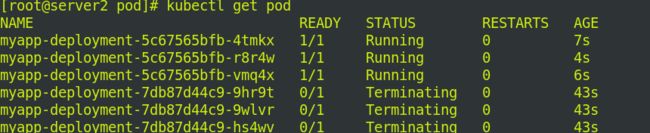
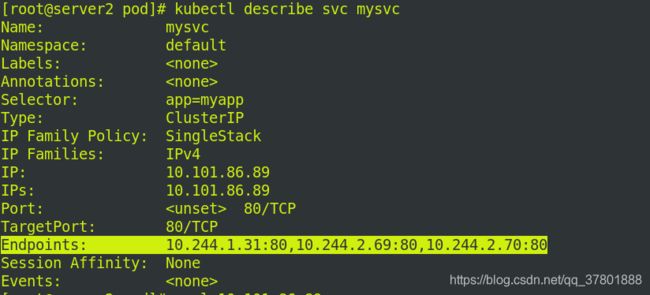
查看svc配置信息:
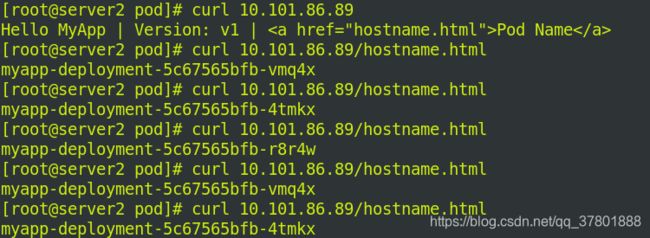
访问网址:
而且ip addr也可以看到这个ip!
三.kube-dns(k8s内置dns解析服务,用于实现域名访问)
kubectl -n kube-system get pod
kubectl -n kube-system get svc
kubectl run demo --image=busyboxplus -it --restart=Never
-> nslookup mysvc.default
kubectl -n kube-system describe svc kube-dns
kubectl -n kube-system get pod -o wide
kubectl get svc
curl 10.102.253.86
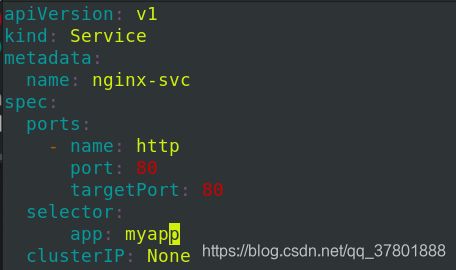
四. Headless无头模式
1. 配置
Headless Service不需要分配一个VIP,而是直接以DNS记录的方式解析出被代理Pod的IP地址。
Pod滚动更新后,依然可以解析
![]()


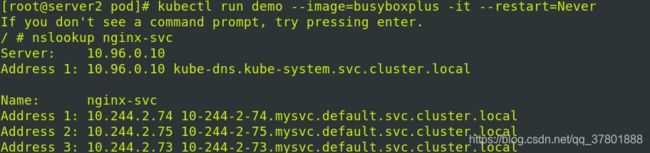
直接访问域名:
![]()
负载均衡:
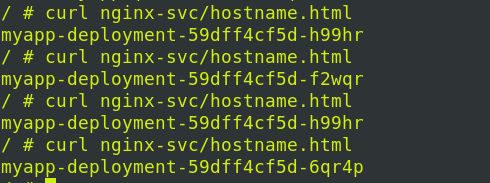
退出容器并删除demo

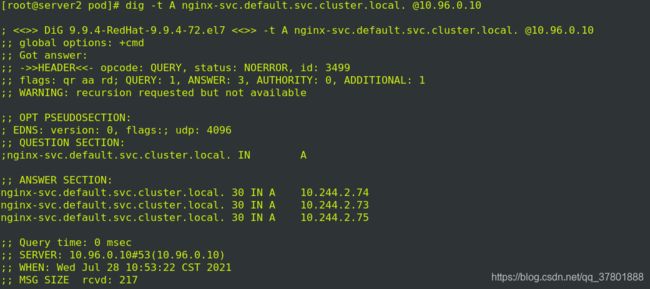
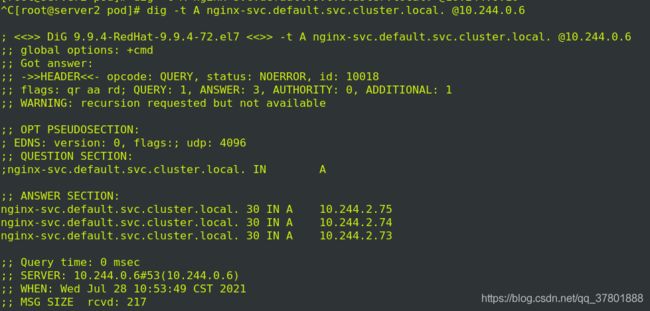
安装dig插件,查看解析的A记录
![]()
2. 版本更新
将deployment.yaml的版本更新V2
vim deployment.yaml
![]()
dig -t -A nginx-svc.default.svc.cluster.local. @10.96.0.10
kubectl describe svc nginx-svc
解析地址会变化!!
五、service的外部访问
Kubernetes的三种外部访问方式:NodePort、LoadBalancer 和 Ingress
1. nodeport
1> 了解nodeport
NodePort 服务是引导外部流量到你的服务的最原始方式。NodePort,正如这个名字所示,在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务。
NodePort 服务主要有两点区别于普通的“ClusterIP”服务。第一,它的类型是“NodePort”。有一个额外的端口,称为 nodePort,它指定节点上开放的端口值 。如果你不指定这个端口,系统将选择一个随机端口。大多数时候我们应该让 Kubernetes 来选择端口,因为如评论中 thockin 所说,用户自己来选择可用端口代价太大。
何时使用这种方式?
这种方法有许多缺点:
每个端口只能是一种服务
端口范围只能是 30000-32767
如果节点/VM 的 IP 地址发生变化,你需要能处理这种情况。
基于以上原因,我不建议在生产环境上用这种方式暴露服务。如果你运行的服务不要求一直可用,或者对成本比较敏感,你可以使用这种方法。这样的应用的最佳例子是 demo 应用,或者某些临时应用。
2> nodeport的部署
编辑mysvc 的svc配置文件,将type改为NodePort

![]()

查看type的更改:

检查端口
![]()
访问ip端口:
![]()
负载均衡:

将之前实验的pod节点demo删掉(kubectl delete pod demo)

进入容器中查看解析,自动写好了本地解析:
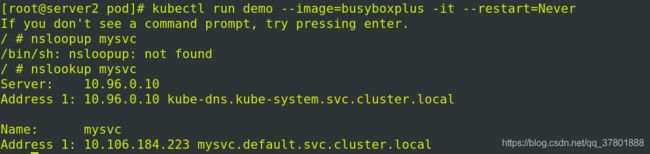
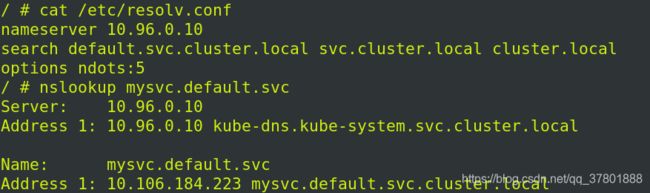
退出容器,删掉demo

2.LoadBalancer
1> 了解loadBalancer
LoadBalancer 服务是暴露服务到 internet 的标准方式。在 GKE 上,这种方式会启动一个 Network Load Balancer,它将给你一个单独的 IP 地址,转发所有流量到你的服务。
何时使用这种方式?
如果你想要直接暴露服务,这就是默认方式。所有通往你指定的端口的流量都会被转发到对应的服务。它没有过滤条件,没有路由等。这意味着你几乎可以发送任何种类的流量到该服务,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意种类。
这个方式的最大缺点是每一个用 LoadBalancer 暴露的服务都会有它自己的 IP 地址,每个用到的 LoadBalancer 都需要付费,这将是非常昂贵的。
2> loadBalancer部署
修改kube-proxy的配置

kubectl edit configmap -n kube-system kube-proxy
strictARP: true
更新kube-proxy pod
kubectl get pod -n kube-system |grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
在server1harbor创建新的仓库,方便一会上传镜像



在server2创建新的目录存储配置文件
![]()
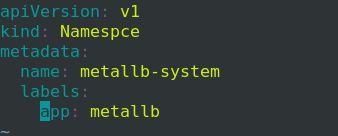
修改镜像文件:
![]()
![]()
![]()
执行镜像文件:
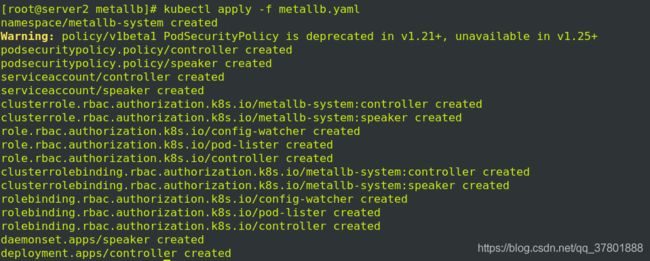
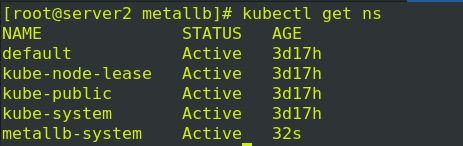
查看metallb-system节点
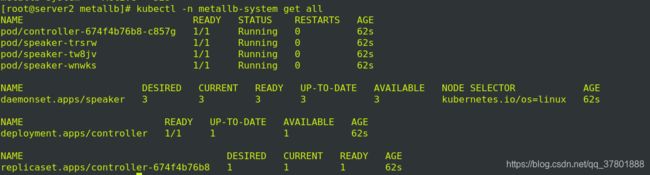

自动生成secrets memberlist
查看:

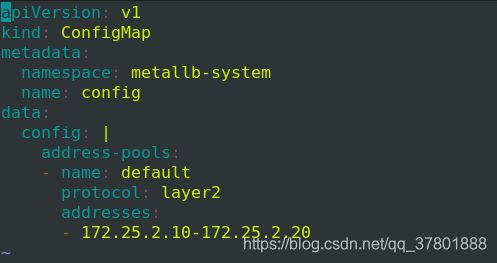
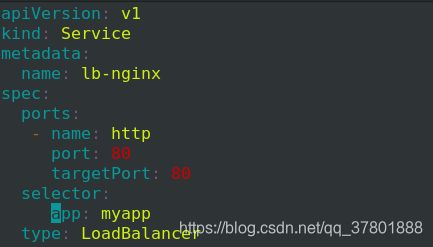
3> 定义地址池
![]()
![]()
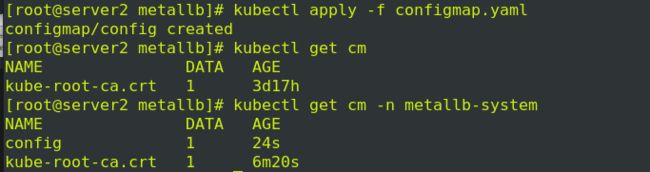
![]()
可以看到分配到了前面定义的10-20之间的Ip

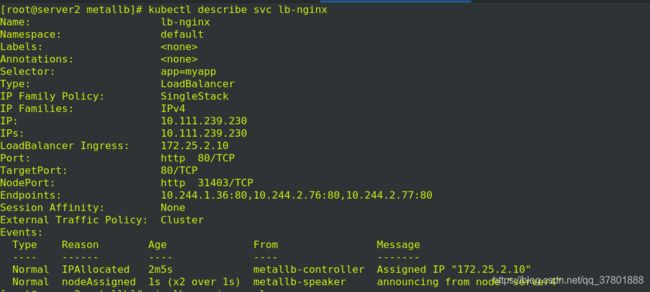
集群外部访问分配的IP实现负载均衡
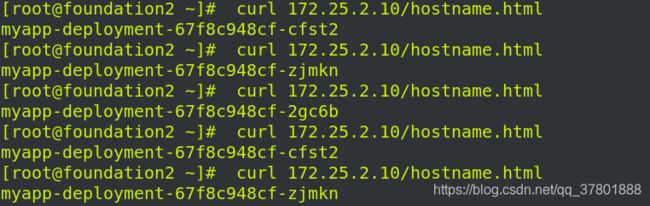
当然也可以ipvsadm -ln看到负载均衡已经加入进来、
3. Ingress
1> 了解ingress
有别于以上所有例子,Ingress 事实上不是一种服务类型。相反,它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色。
你可以用 Ingress 来做许多不同的事情,各种不同类型的 Ingress 控制器也有不同的能力。
GKE 上的默认 ingress 控制器是启动一个 HTTP(S) Load Balancer。它允许你基于路径或者子域名来路由流量到后端服务。例如,你可以将任何发往域名 foo.yourdomain.com 的流量转到 foo 服务,将路径 yourdomain.com/bar/path 的流量转到 bar 服务。
何时使用这种方式?
Ingress 可能是暴露服务的最强大方式,但同时也是最复杂的。Ingress 控制器有各种类型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它还有各种插件,比如 cert-manager,它可以为你的服务自动提供 SSL 证书。
如果你想要使用同一个 IP 暴露多个服务,这些服务都是使用相同的七层协议(典型如 HTTP),那么Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要为一个负载均衡器付费,且由于 Ingress是“智能”的,你还可以获取各种开箱即用的特性(比如 SSL,认证,路由,等等)。
2> ingress部署
现在server1上上传镜像:

![]()
![]()
![]()
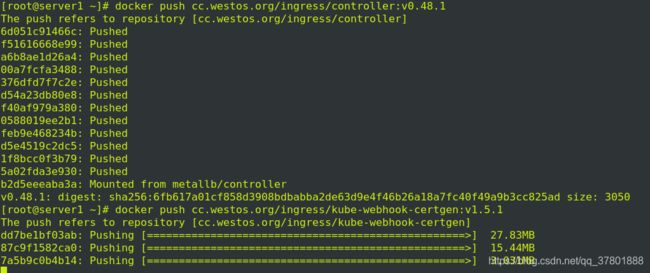
在server2上更改镜像信息:
vim deploy.yaml
![]()
![]()
![]()
执行deploy.yaml清单,查看ns状态:
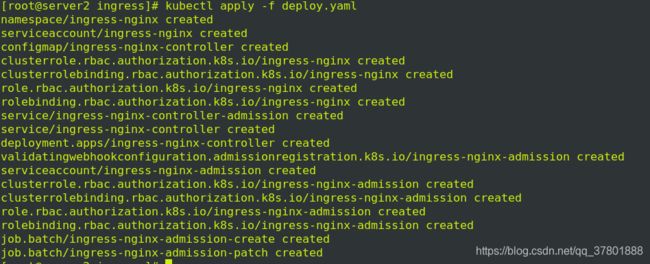

查看ip:

3> 域名访问+ingress-nginx
添加第一个域名
编辑ingress.yaml
现在的名字起为ingress-demo
name: ingress-demo
![]()
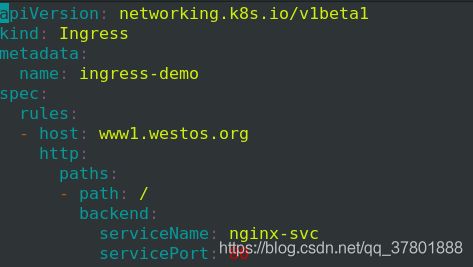
将之前实验的sv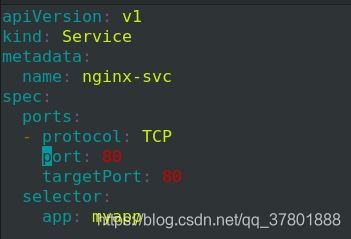
c删除,重新执行一个svc节点
编辑svc.yaml

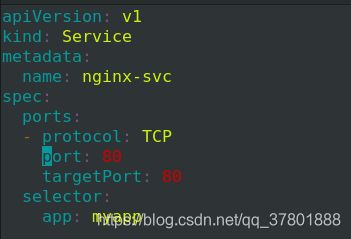

![]()

删掉test

删掉之后, 准备执行ingress.yaml清单


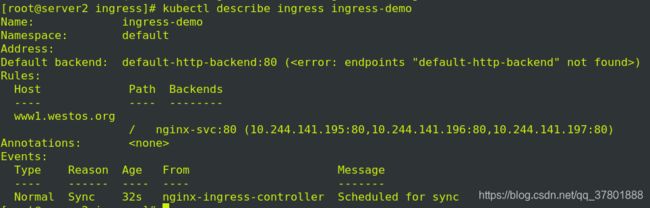
更改类型:
![]()
![]()

添加解析:
![]()
![]()
访问一下:
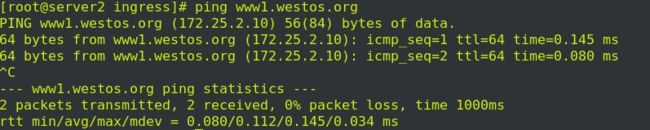
![]()
第二个域名
![]()
添加如下内容
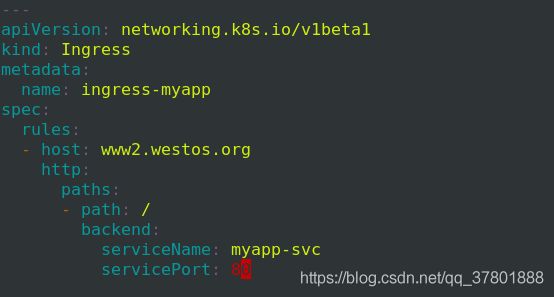

添加如下内容:
![]()

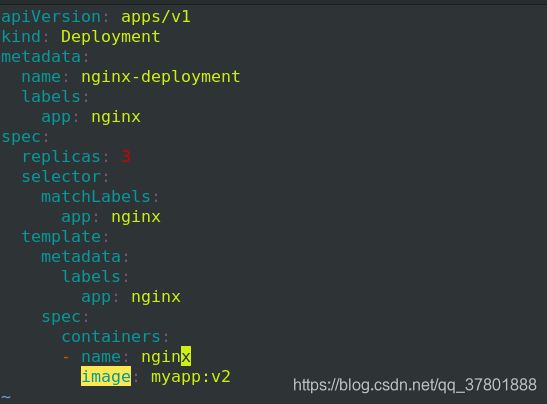
更改内容:
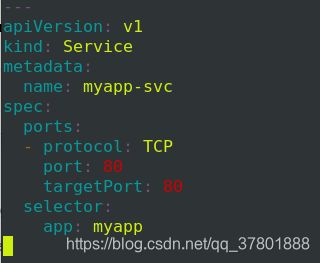
执行之后查看svc:
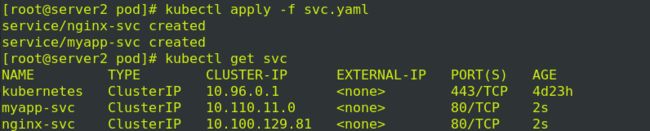
执行ingress
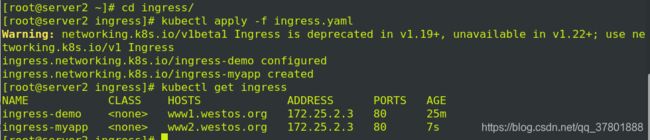
作解析:
![]()
![]()
访问:
![]()