mysql从零基础到基础熟练
本文使用软件为:Mysql版本8.0.29,Navicat PreMium 15
第一章 mysql介绍
1.1什么是数据库
- 数据库:数据的仓库,database简称DB
- 介质:硬盘和内存,数据仓库的位置
- sql:用来和数据库DB打交道,完成和数据库DB的通信。
有一套自己的逻辑标准,但是每个数据库都有别人没有的特性,当使用某个数据库相关功能的特性功能时,此时sql可能就不是标准的了。95%以上的sql都是通用的。
1.2数据库的分类
1.关系型数据库
将复杂的数据结构归结为简单的二元关系。通过对表的关联、结合和链接,在一个或多个关系表中实现对数据库的管理。
优点:存储在磁盘中/二维表结构中,断电不会丢失,符合人类的认知
缺点:浪费空间
2.非关系型数据库
优点:存储在内存中,效率高
缺点:断电易丢失
【举例1,如手机中的8g+128g存储,8g是内存,128g是磁盘;举例2,如插在电脑的磁盘,断电不会丢失】
3.不同的数据产品DBMS
大型数据库:oracle/DB2
中型数据库:mysql/SQL server
小型数据库:access
DBMS-->(执行)SQL-->(操作)DB
dbms:数据库管理系统 database management system
db:数据库 database
sql:结构化查询语言,适用于所有dbms
4.表
表table是数据库的基本组成单位,所有的数据都是以表的形式存储,目的是可读性强。
5.SQL语言的分类
DQL(数据查询语言):关键字select;data query language
DML(数据操纵语言):对表中的数据进行修改关键字:insert插入/delete删除/update修改,data manipulation language
DDL(数据修正语言): create创建/drop删除/alter更新,data definition language
TCL (事务控制语言):rollback 回滚/commit 提交,transaction control language
DCL (数据控制语言):grant 授权/revoke 撤销,database control language
第二章:数据库与表的逻辑
2.1查看有哪些数据库
show databases;
2.2查看你现在打开的是哪个数据库
select database ();
2.3查看当前数据库的版本
select version();
2.4创建数据库
create database 表名;
2.5切换/使用某个数据库
use 数据库名称;
2.7创建表
create table 表名(字段1 字段类型1,字段2 字段类型2...)
2.8查看这个数据库里有哪些表
show tables;
2.9往表中插入数据
- 全部:insert into 表名(字段1,字段2...)values(字段1的值1,字段2的值2,...)
--------只要字段顺序和值顺序一样,那么插入的数据不会受到影响
- 部分:insert into 表名(字段1,字段2...)values(字段1的值1,字段2的值2,...)
=insert into 表名values(值1,值2...)
--------保证值的数量和所有字段的数量相等
- 批量添加:insert into values(值1,值2...),(值1,值2...)
2.10表的复制和批量插入
create table 新表名 as select*from 旧表名;
2.11终止一条sql语句
ctrl+c
2.12删除数据库/表(慎用)!!!
drop database 数据库名称;
drop table 表名; (注:如果这个表在就会被删除,不在 会错)
drop table if exists 表名; (注:如果这个表在就会被删除,不在 不会错)
delete from 表名 where 条件; (注:不写where会删除整个表数据,但表结构在)
第三章:表
3.1常用字段类型:
int 整数
float 小数
date 日期--存储年、月、日的值
注:日期可以升序降序,也可以比较大小
char 字符/字符串:定长型--固定长度n
vachar 字符/字符串:变长型--可变长度,最大长度n
numeric(a,b) 精确数值,总位数a,小数点后位数b
例:numeric(19,4):长度为19位的数,4代表小数的精度为4,保留4位小数
bit:只能是0,1,空值
blob:二进制对象
clob:字符大对象
char和varchar的区别:
char(n):表示最长可以写n个字符,如果我们写的字符少于3个,那也按照3个字符去存储
varchar(n):实际写了几个字符就是几个字符,但是不能超过n个
注 :char效率更高,大部分情况下用varchar
3.2创建表
语法:create table表名(字段1 字段类型1,字段2 字段类型2...);
例 create table student(sid int,sname varchar(5),age char(10),sex char(1));
3.3看数据库中是否有新表
语法:show tables;
3.4在表中插入数据
语法:insert into 表名(字段1,字段2...)values(字段1的值1,字段2的值2...);
注意:只要字段顺序和值顺序应保持一致,那么插入的数据不会受到影响
#案例:insert into student(sid,sname,age,sex)values(1,'世纪','1970-1-1','男');
insert into student(sid,sname,age,sex) values(1,'世纪','1970-1-1','男');
插入部分字段和对应的值语法:insert into student(sid,sname)values(003,'李四');
省略字段添加数据语法:insert into表名values(值1,值2...);
注意 这种添加数据的方式必须保证所有字段的数量和值的数量相等
insert into student values(002,'张六','19','女');
添加多条数据语法:insert into 表名values(值1,值2...),(值1,值2...);
=insert into student(字段1 字段类型1,字段2 字段类型2...) values(值1,值2),(值1,值2...);
3.5查询表中的数据
3.51 查询表中所有数据
语法:select*from 表名;
select*from 表名 where 条件;
3.52 查询表中部分数据
语法:select 字段1,字段2... from 表名;
select 字段1,字段2... from 表名 where 条件;
3.6 查询表的结构:
语法:desc 表名
共有六个字段:
字段名称,字段类型,可不可以为空,主外键,默认值,附加条件
+-------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+-------+
| sid | int | YES | | NULL | |
| sname | varchar(5) | YES | | NULL | |
| age | char(10) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
+-------+------------+------+-----+---------+-------+
3.7 删除表
drop table 表名;
注 如果在会被删除,不在 会错
drop table if exists 表名;
注 如果在会被删除,不在 不会错
3.8 修改表中数据
语法格式:
update 表名 set 字段名1=新值1,字段2=新值2
#案例:将emp表中的King改成世纪
update emp11 set ename ='世纪' where ename='king';
#练习:将smith的员工编号改为6666
update emp11 set empno='6666' where ename='smith';
3.9 修改默认值
创建表时给特定字段设置默认值
语法:create table 表名(字段1 字段类型,字段2 字段类型,字段3 字段类型 default ' '...);
3.10 表的复制和批量插入
语法:create table 新表名 as select*from 旧表名;
*指的是所有字段,如果要插入部分字段,如下图语法:create table 新表名 as select*from 旧表名;
3.11 删除数据/表(慎用!!)
删数据
语法:delete from 表名 where 条件;
注意 不写where删除整个表数据,但表结构还在;
删表
语法:drop table 表名;
3.12 表结构的修改
3.12.1 修改表的字段
语法:alter table 表名 modify 字段 字段类型;
案例:将emp表中的ename字段从varchar改成char(20);
alter table emp modify ename char(20);
(desc 表名:查看表结构)
3.12.2 添加字段
语法:alter table 表名 add column 字段 字段类型;
案例:给emp表加一个salrank字段 字段类型为int
alter table emp add column salrank int(10);
3.12.3 删除字段
语法:alter table 表名 drop column 字段;
案例:删除emp表的salrank字段
alter table emp drop column salrank;
3.12.4 修改表名
语法:alter table 旧表名 rename to 新表名;
案例:将emp表改成century表
alter table emp rename to century;
3.12.5 修改字段名
语法:alter table 表名 change column 旧字段名 新字段名 字段类型;
案例:将emp表中的empno改成id
alter table emp change column empno id int;
第四章 约束
约束会带索引的一种
约束:为了保证数据的完整性,合法性,有效性。比如id不能重复,name不能为空
1.非空约束(not null):被约束的字段不能为空
2.唯一性约束(unique):被约束的字段不能重复
3.主键约束(primary key):(有带索引) unique+not null被约束的字段不能重复且不能为空
4.外键约束(foreign key)
5.检查约束(check)
4.1非空约束(not null)
被约束的字段不能为空
创建stu表,添加id和name字段,我们给id字段添加非空约束
create table stu (id int not null, name varchar(5));
4.2唯一性约束(unique)
被约束的字段不能重复
创建stu表,添加id和name字段,我们给name字段添加唯一性约束
create table stu(id int,name vachar(10) unique);
insert into stu values(1,'张三');
被唯一性约束的字段具有唯一性
但null可以有多个,因为null是一种特殊的数据类型
4.3主键约束(primary key)
unique+not null被约束的字段不能重复且不能为空
练习:创建stu表添加字段id/name/age,给id字段添加主键约束
create table stu(id int primary key,name varchar(5),age int);
4.3.1主键自增(primary key auto_increment)
练习:创建stu 表,包含字段id和name,并给id字段添加主键自增约束
create table stu(id int primary key auto increment,name varchar(5));
4.4父子表
假如有一个业务需求,让你设计一张表来维护学生信息
4.4.1数据冗余
数据冗余:指一个字段在多个表里重复出现。
缺点:会造成数据异常和损坏,应该从设计上避免,同时浪费空间,因此要使用外键,使得数据冗余降到最低
4.4.2父表与子表关系
1.子表中字段引用的是父表
2.在创建表时,应该先创建父表,再创建子表
3.在添加数据时,先添加父表中的数据,再添加子表中的数据
4.在删除表中数据的时候,先删子表中的数据,再删父表中的数据
5.删除表的时候,先删子表,再删父表
(爸爸为大,爸爸为尊)
#案例:
先创建父表class
create table class(classno int primary key,classname varchar(10));

再创建stu表
create table stu(id int,name varchar(5),classno int,foreign key(classno) references class(classno));
往父表中插入数据
insert into class values(101,'清华附中'),(102,'北大附中');
往子表中插入数据
insert into kid values(2001,'张三',101),(2002,'李四',102),(2003,'王五',102);
如果在子表中的外键字段中插入的数据在父表中没有,就会报错。
insert into bro values(2001,'张三',101),(2002,'李四',102),(2003,'王五',103);
【报错提示:出现的原因即外键中的数据在父表的主键中不存在】
#问题:外键字段引用其他表(父表)中的字段时,被引用的字段必须是有主键约束的吗?
#答:不一定。但是必须保证有唯一性约束(unique),比如父表班级表中的classno,如果要是有重复的值,那么在子表学生信息表中的classno就找不出唯一对应的值
第五章 数据查询
5.1查询字段
5.11查询单个字段
select 字段1 from emp;
5.12查询多个字段
select 字段1,字段2... from emp;
5.13起别名
给字段名起别名直接在字段后面加个空格然后写名字就好,或者加个as
select 字段1 字段1 名字,字段2 字段2 名字 from emp;
select 字段1 as 字段1 名字,字段2 as 字段2 名字 from emp;
5.2查询条件
条件查询必须用到where语句中,where必须放在from的 后面
语法:select 字段...from 表名 where 条件
一定要记住!!执行顺序是from,然后where(相当于筛选),最后select
5.2.1 等于 =
#案例:查询月薪为5000的员工信息
select ename,sal from emp where sal=5000;
5.2.2 不等于 !=或<>
#案例:查询员工部门编号不为30的员工姓名和员工薪资
select ename,sal from emp where deptno !=30;
select ename,sal from emp where deptno <>30;
5.2.3 大于 >
#案例:查询工资大于2000的员工编号和员工姓名
select ename,empno from emp where sal>2000;
5.2.4 小于<
#案例:查询工资小于2000的员工编号和员工姓名
select ename,empno from emp where sal<2000;
5.2.5 在...之间 包括端点值 between...and...
等同于 ... 大于等于>= ... and ... 小于等于<=...
#查询工资在1250 到 2850的员工姓名和工资
select ename,sal from emp where sal between 1250 and 2850;
select ename,sal from emp where sal >=1250 and sal <=2850;
5.2.6 null 的使用
#案例:找出emp表中那些人没有津贴,输出员工姓名
select ename from emp where comm is null or comm = 0;
#补充 null和0的区别:
null是取不到,没有值;0是取得到值,值为0
5.2.7 and/or的使用
#找出薪水大于2000,并且部门编号为20或者30的员工姓名
select ename from emp where sal>2000 and (deptno=20 or deptno=30);
易错点:select ename from emp where sal>2000 and deptno=20 or deptno=30,此书写是错的; 记得加括号,此为从左到右运算
5.28 in/not in
#找出工作岗位是经理或者销售的员工姓名和入职日期
select ename,hiredate from emp where job = 'manager' or job = 'salesman';
select ename,hiredate from emp where job in ('manager' , 'salesman');
#案例:找出部门编号不是10或者20的员工名称
select ename from emp where deptno!=10 and deptno!=20;
select ename from emp where deptno not in (10,20);
5.2.8模糊查询
% 任意多个字符
_ 任意单个字符
#案例1:找出姓名中带‘A’的员工姓名
select ename from emp where ename like '%A%';
#注意:'A%'表示的是名字的首字母为A
#案例2:找出名字第二个字母为A的员工姓名
select ename from emp where ename like '_A%';
#练习:找出名字第三个字母为A的员工姓名
select ename from emp where ename like '__A%';
#练习:找出名字倒数第二个字母为‘R’的员工姓名
select ename from emp where ename like '%R_';
第六章:数据排序
6.1 升降序
order by默认升序
升序:asc
以上两个都可以为作为升序
降序:desc
语法:select 字段 from 表名 where 条件 order by 排序字段 升序/降序;
#案例:按照员工的工资升序排序,并输出所有的员工信息
select*from emp order by sal asc;
select*from emp order by sal;
此处并未要求需要筛选或者过滤掉某种信息,所以不用where
#案例:找出部门编号为30的员工信息,并按照薪水降序排序
select * from emp where deptno = 30 order by sal desc;
#练习:按照员工的工资降序排序并输出职业为经理或者销售的员工信息。
select * from emp where job in ('manager','salesman') order by sal desc;
6.2 多字段排序
案例:按照员工的部门编号降序,如果编号相同那么按照薪资升序排序,最后显示所有员工信息
select * from emp order by deptno desc,sal asc ;
#有的同学说可不可以这样↓
select * from emp order by sal asc,deptno desc ;
#答:虽然结果不会报错,但是这样写表示的是先按照工资升序排序,如果工资相同再按照部门编号降序
第七章:聚合函数(分组函数)
聚合函数语法格式:select 聚合函数(字段/*) from 表名; ----------不可以!!直接!!使用在where子句中
7.1 count 计数
#求emp表中一共有多少人
select count(*) from emp;
select count(*),字段1 from emp group by 字段1;
#聚合函数一般和group by连用时,分组除聚合函数外的字段都需要加在group by后面
select count(ename) from emp;
7.2 sum 求和
#所有员工的工资和
select sum(sal) from emp;
注:()里面不能加*
7.3 avg 平均值
#求所有员工的平均薪资
select avg(sal) from emp;
注:()里面不能加*
7.4 max 最大值
#求最高工资
select max(sal) from emp;
#求出最晚的员工入职时间
select max(hiredate) from emp;
7.5 min 最小值
select min(sal) from emp;
聚合函数一共有五个,又名:多行聚合函数
特点:处理多行数据,返回一行结果(如果不分组的话,为单行函数);不计入字段数量
7.6 聚合函数直接忽略null,不忽略0
#公司一共多少员工
select count(*) from emp;
7.7 count(*)和count(字段)的区别
count(*):是统计表中有多少条(行)数据
count(字段):统计这个字段有多少个非空值
#count(字段1,字段2...),给各个字段都计数,这样书写也可以
7.8 任何数据+null=null
9999/null=null
#案例:emp表中每个员工的总收入是多少?
select sal +comm from emp;
#注意:上面的sql不能求出员工的总收入因为没有加班费的最后计算结果都为null
解决方法:使用ifnull函数
ifnull:空处理函数(可能会为null的字段,被当做什么处理)
#案例:emp表中每个员工的总收入是多少?
select sal+ifnull(comm,0) 总收入 from emp;
#练习:emp表中所有员工的年薪是多少?
select (sal+ifnull(comm,0))*12 年薪 from emp;
7.9 分组函数 不可以!直接!使用在where子句中
#求出员工工资大于平均工资的员工姓名
mysql> select ename from emp where sal>avg(sal);
ERROR 1111 (HY000): Invalid use of group function
#会报错,如何不报错,后面讲!
7.10 聚合函数可以组合使用
案例:输出emp表中的最高工资,最低工资和平均工资。
select max(sal) 最高工资,min(sal) 最低工资,avg(sal)平均工资 from emp;
7.11group by 按照某个字段进行分组
语法:select 字段 from 表名 group by 分组字段;
#按照job对emp表中的数据进行分组,显示emp表中有哪些工作
select job from emp group by job;
#按照deptn对emp表中的数据进行分组,显示emp表中有哪些部门编号
select deptno from emp group by deptno;
注意:一般来说我们不会在一个sql里去单独使用group by,单独使用的效果和去重distinct()无异。
那分组函数用在哪里/怎么用呢?往下看
#和聚合函数一起使用
#案例:找到每个工作岗位的最高薪资
select max(sal),job from emp group by job;
#练习:找到每个部门的最高薪资
select max(sal),empno from emp group by empno;
7.12 having 的应用
语法:select 字段 from 表名 where 条件 group by分组字段 having 过滤条件;
having在某种情况下和where的意思相同,但是having能用在group by的后面,且having后面既可以接条件,也可以接聚合函数。
where 和having 的区别:过滤对象不同
where是初筛-选出满足条件的;having是进一步细分筛选
或者说,where子句是对被选择的列进行过滤,having子句是对group by 子句所产生的组进行过滤
#案例找出每个部门的最高薪资,要求显示部门最高薪资大于3500的
select max(sal),empno from emp group by empno having max(sal)>3500;
一个完整语句的执行顺序:
select 5
from 1
where 2
group by 3
having 4
order by 6
limit 7
注意:select中,不能查询没有被分组(聚合)的字段
如:
select 字段1 from 表 group by 字段1; -----√
select 字段1 字段2 字段3 from 表 group by 字段1;----×
select 字段1 字段2 字段3 from 表 group by 字段1 字段2 字段3; ---√
例如:找出每个月工作岗位的最高薪资,同时输出员工姓名
select max(sal),deptno,ename from emp group by deptno;
+----------+--------+-------+
| max(sal) | deptno | ename |
+----------+--------+-------+
| 3000.00 | 20 | SMITH |
| 2850.00 | 30 | ALLEN |
| 5000.00 | 10 | CLARK |
+----------+--------+-------+
#虽然可能不会报错,但是结果必然是错的。比如上表clark的工资实际不是5000
修正思路1:select max(sal),deptno from emp group by deptno;
修正思路2:select max(sal),deptno,ename from emp group by deptno,ename;----注:5种聚合函数不算字段
7.13多字段联合分组
#案例,找出每个部门不同工作岗位的最高薪资,输出部门编号/工作岗位/最高薪资
#提示:在sql题中,遇到‘每个’,‘不同’这两个词的时候,要立马想到分组 group by
select max(sal),deptno,job from emp group by deptno,job;
7.14 distinct 数据去重
案例:emp表中工种有哪些
select distinct(job) from emp;
练习:emp表中薪资有哪些
select distinct(sal) from emp;
#补充:涉及到id之类的,distinct可以直接写上去
第八章:单行函数
返回值是一条记录的时候,成为单行函数
单行函数包括五种:
1.字符函数(有6个)
2.数字函数(有4个)
3.日期函数(有6个)
4.其他函数
5.流程控制
8.1字符函数(有6个)
8.1.1 length 长度
#查询'smith'的长度
select length ('smith') from dual;
+-----------------+
| length('smith') |
+-----------------+
| 5 |
+-----------------+
#注:dual是一个虚拟表,只有一行一列
select length('世纪') from dual;
+-----------------+
| length ('世纪') |
+-----------------+
| 4 |
+-----------------+
#一个汉字占3/2个字节,一个字母占一个字节
#至于汉字占2还是3个字符,由字符集决定。
select length('123456') from dual;
+------------------+
| length('123456') |
+------------------+
| 6 |
+------------------+
#一个数字占一个字节
8.1.2 concat 字符串拼接
语法:select concat(字段1,链接符号,字段2) from 表名;
#将emp表中的员工姓名和对应的职业链接输出,并使用下划线链接
select concat(ename,'_',job) from emp;
+-----------------------+
| concat(ename,'_',job) |
+-----------------------+
| SMITH_CLERK |
| ALLEN_SALESMAN |
| WARD_SALESMAN |
| JONES_MANAGER |
| MARTIN_SALESMAN |
| BLAKE_MANAGER |
| CLARK_MANAGER |
| SCOTT_ANALYST |
| KING_PRESIDENT |
| TURNER_SALESMAN |
| ADAMS_CLERK |
| JAMES_CLERK |
| FORD_ANALYST |
| MILLER_CLERK |
+-----------------------+
select concat(ename,'_',job) as 姓名_职业 from emp;
+-----------------+
| 姓名_职业 |
+-----------------+
| SMITH_CLERK |
| ALLEN_SALESMAN |
| WARD_SALESMAN |
| JONES_MANAGER |
| MARTIN_SALESMAN |
| BLAKE_MANAGER |
| CLARK_MANAGER |
| SCOTT_ANALYST |
| KING_PRESIDENT |
| TURNER_SALESMAN |
| ADAMS_CLERK |
| JAMES_CLERK |
| FORD_ANALYST |
| MILLER_CLERK |
+-----------------+
8.1.3大小写转换
1.转大写upper
2.转小写lower
#案例 将‘hello world'转成大写
select upper('hello world') from dual;
+----------------------+
| upper('hello world') |
+----------------------+
| HELLO WORLD |
+----------------------+
#练习:将’HELLO WORLD‘转成小写
select lower('HELLO WORLD') from dual;
+----------------------+
| lower('HELLO WORLD') |
+----------------------+
| hello world |
+----------------------+
8.1.4 substr 字符截取函数
语法:substr(字符串,开始的索引位置,取得长度)
如果不写取的长度,默认取到最后
mysql中索引从左往右由1开始
例子:’人生苦短,我爱mysql’取出mysql
select substr('人生苦短,我爱mysql',8,5) from dual;
+----------------------------------+
| substr('人生苦短,我爱mysql',8,5) |
+----------------------------------+
| mysql |
+----------------------------------+
#练习:从 ’人生苦短,我爱mysql ’ 中取出苦短
select substr('人生苦短,我爱mysql',3,2) from dual;
+----------------------------------+
| substr('人生苦短,我爱mysql',3,2) |
+----------------------------------+
| 苦短 |
+----------------------------------+
#案例:把emp表中所有员工名字中的第一个字母提取出来
select substr(ename,1,1) from emp;
+-------------------+
| substr(ename,1,1) |
+-------------------+
| S |
| A |
| W |
| J |
| M |
| B |
| C |
| S |
| K |
| T |
| A |
| J |
| F |
| M |
+-------------------+
其实,索引也可以从后往前找,从-1开始
#案例:把emp表中所有员工名字中的最后一个字母提取出来
select substr(ename,-1,1) from emp;
+--------------------+
| substr(ename,-1,1) |
+--------------------+
| H |
| N |
| D |
| S |
| N |
| E |
| K |
| T |
| G |
| R |
| S |
| S |
| D |
| R |
+--------------------+
#练习:把emp表中所有员工名字中的倒数第二个字母提取出来
select substr(ename,-2,1) from emp;
+--------------------+
| substr(ename,-2,1) |
+--------------------+
| T |
| E |
| R |
| E |
| I |
| K |
| R |
| T |
| N |
| E |
| M |
| E |
| R |
| E |
+--------------------+
8.1.5 replace 替换
语法:select replace(字符串,被替换的值,替换后的值) from dual
#案例:将’人生苦短,我爱mysql‘中的mysql换成python
select replace('人生苦短,我爱mysql','mysql','python') from dual;
+------------------------------------------------+
| replace('人生苦短,我爱mysql','mysql','python') |
+------------------------------------------------+
| 人生苦短,我爱python |
+------------------------------------------------+
8.1.6 trim 去除空格
#案例:去除’ 世纪 ‘的空格
select trim(' 世纪 ') from dual;
+---------------------+
| trim(' 世纪 ') |
+---------------------+
| 世纪 |
+---------------------+
ltrim:去左边空格
rtrim:去右边空格
8.2 数学函数(有4个)
8.2.1 round 四舍五入
--保留整数
select round(3.5555);
+---------------+
| round(3.5555) |
+---------------+
| 4 |
+---------------+
--保留小数点后两位
select round(3.5555,2);
+-----------------+
| round(3.5555,2) |
+-----------------+
| 3.56 |
+-----------------+
--保留整数到百位
select round(12345.44,-2);
+--------------------+
| round(12345.44,-2) |
+--------------------+
| 12300 |
+--------------------+
8.2.2 truncate 截取 无四舍五入
select truncate(1.19999,1);
+---------------------+
| truncate(1.19999,1) |
+---------------------+
| 1.1 |
+---------------------+
select truncate(12345.9,-3);
+-----------------------+
| truncate(12345.9,-3) |
+-----------------------+
| 12000 |
+-----------------------+
truncate以小数点为端点,从右(+)/ 左(-)第一个数字开始截取:
小数点往右开始为正数,从1开始
小数点从右往左截取,小数点往左开始为负数,从0开始
8.2.3 ceil 向上取整 floor 向下取整
向上取整:返回大于该值的最小整数
select ceil(6.66);
+------------+
| ceil(6.66) |
+------------+
| 7 |
+------------+
select ceil(-0.1);
+------------+
| ceil(-0.1) |
+------------+
| 0 |
+------------+
向下取整:返回小于该值的最大整数
select floor(6.55);
+-------------+
| floor(6.55) |
+-------------+
| 6 |
+-------------+
select floor(-6.55);
+--------------+
| floor(-6.55) |
+--------------+
| -7 |
+--------------+
8.2.4 mod 取余
10/3=3…1,此时取余为1
select mod(10,3);
+-----------+
| mod(10,3) |
+-----------+
| 1 |
+-----------+
8.3 日期函数(有6个)
8.3.1 now() 返回当前的系统日期+时间
select now() from dual;
+---------------------+
| now() |
+---------------------+
| 2022-06-02 09:21:10 |
+---------------------+
8.3.2 curdate() 返回当前系统的日期
select curdate() from dual;
+------------+
| curdate() |
+------------+
| 2022-06-02 |
+------------+
8.3.3 curtime() 返回当前系统的时间
select curtime() from dual;
+-----------+
| curtime() |
+-----------+
| 09:22:29 |
+-----------+
8.3.4 year(时间字段) 获取年份,month(时间字段) 获取月份
--获取今年的年份
select year(now()) from dual;
+-------------+
| year(now()) |
+-------------+
| 2022 |
+-------------+
--获取现在的月份
select month(now()) from dual;
+--------------+
| month(now()) |
+--------------+
| 6 |
+--------------+
--获取现在月份名称
select monthname(now()) from dual;
+------------------+
| monthname(now()) |
+------------------+
| June |
+------------------+
补充:日day 小时hour 分钟minute 秒second
8.3.5 str_to_date 将系统日期转换为字符串格式
语法:str_to_date(字符串格式,字符串的日期格式)
#案例:将字符串'01-01-2022' 转换成标准的日期格式
select str_to_date('01-01-22','%m-%d-%y') from dual;
+------------------------------------+
| str_to_date('01-01-22','%m-%d-%y') |
+------------------------------------+
| 2022-01-01 |
+------------------------------------+
select str_to_date('01-01-22','%m-%d-%Y') from dual;
+------------------------------------+
| str_to_date('01-01-22','%m-%d-%Y') |
+------------------------------------+
| 2022-01-01 |
+------------------------------------+
#Y要大写,Y小写的话就是年份的后两位。
Y大写时
select str_to_date('01-01-2022','%m-%d-%Y') from dual;
Y小写时
select str_to_date('01-01-22','%m-%d-%y') from dual;
8.3.6 date format 将日期格式转换为字符串格式
语法:date_format(日期,具有日期格式的字符串)
案例:将系统日期转换为字符串格式’2022年6月1日
select date_format('2022年6月1日','%Y年%m月%d日') from dual;
+--------------------------------------------+
| date_format('2022年6月1日','%Y年%m月%d日') |
+--------------------------------------------+
| NULL |
+--------------------------------------------+
8.3.7 TimeStampDiff 时间间隔函数/时间差函数
语法:timestampdiff(间隔类型,前一个日期,后一个日期)
间隔类型有:second秒,minute分,hour时,day天,week周,month月,quarter季度,year年
例如:距离现在差了多少年:timestampdiff(year, 前一个日期, now())
#例题1:给任职日期超过30年的员工加薪10%。
#思路:
update emp set sal=sal*1.1 where 任职日期 > 30年;
即:
update emp
set sal = sal * 1.1
where timestampdiff(year, hiredate, now()) > 30;
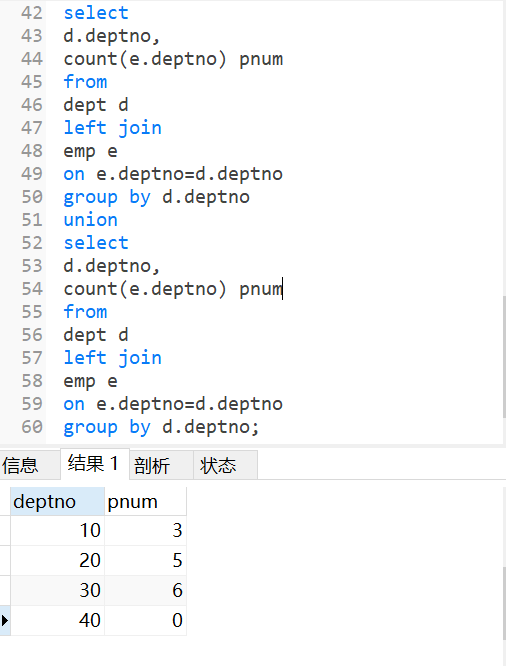
#例题2:列出在每个部门工作的员工数量,平均工资,平均服务期限。
#思路:使用外连接。
select d.deptno, count(e.ename) ‘人数’, ifnull(avg(e.sal), 0) ‘平均月薪’, ifnull(avg(timestampdiff(year, e.hiredate, now())), 0) ‘平均服务年数’from emp e right join dept d on e.deptno = d.deptno group by d.deptno;
8.4流程控制函数
8.4.1 case...when...语句
语法格式1
select 字段,
case 要判断的字段或者表达式
when 常量1 then 要显示的值1或者语句1
when 常量2 then 要显示的值2或者语句2...
else 要显示的值n或者语句n
end as 别名--最终要显示的数据
from 表名;
#案例:查询员工工资,要求:部门编号为10的上涨0.1倍,部门编号为20的上涨0.2倍,部门编号为30的上涨0.3倍,输出:员工姓名、薪水、部门编号
select ename,sal,deptno, case deptno when 10 then sal*1.1 when 20 then sal*1.2 when 30 then sal*1.3 else sal end as 涨薪后的薪水 from emp;
语法格式2
select 字段,
case
when 条件1 then 值1或语句1
when 条件2 then 值2或语句2
else 要显示的值n或者语句n
end as 别名--最终要显示的数据
from 表名
注:条件中可以加函数
#案例:查询员工的工资情况,如果工资大于3000,则显示等级A,如果工资大于2000,则显示等级B,如果工资大于1000,显示等级C,否则显示等级D。要求输出:员工姓名,薪资,和薪资等级
select ename,sal,case when sal >=3000 then 'A' when sal>=2000 then 'B' when sal>=1000 then 'C' else 'D' end as salgrade from emp;
即:
select ename,sal,
case
when sal >=3000 then 'A'
when sal>=2000 then 'B'
when sal>=1000 then 'C'
else 'D'
end as salgrade
from emp;
注: case后面加不加字段,是根据when后面接的是常量,还是条件决定的 。
--常量就是可以具体表达出来的某个数据,条件可能会展示出来一个范围
--何老师上的课
case ... when 条件1 then 结果1
when 条件2 then 结果2
when ... then ...
else 以上条件的否定结果
end as 别名...
#'case...when...else...end as 别名'中的'as 别名'中的as一定要写
#when后面可以加聚合函数
语法:
select case when (条件1) then (结果1) else (以上条件的否定结果) end as 别名 from 表名;
select 字段, case when (条件1) then (结果1) else (以上条件的否定结果) end as 别名 from 表名;
#例如:
select case when 姓名='李世继' then'女' else '暂不展示' end as 性别 from 点名表;
即:
select case when 姓名='李世继' then'女'
else '暂不展示'
end as 性别
from 点名表;
#案例:查询部门号为20的个数
select sum(部门号) from (select deptno,case when deptno=20 then 1 else 0 end as 部门号 from emp) a;
#案例:

分4类,分别是不及格,及格,良,优秀的数量
8.4.2 if函数
在if函数中有三个参数
语法格式:
if(表达式,True时返回的结果,False时返回的结果)
mysql> select if(10>5,'大','小');
+--------------------+
| if(10>5,'大','小') |
+--------------------+
| 大 |
+--------------------+
#案例:查询emp表中的员工是否有津贴,如果有津贴返回'happy',没有返回'sad',要求输出员工的姓名,津贴和心情
select ename,comm,if(comm>0,'happy','sad') from emp;
#优化:
select ename,comm,if(comm!=0 and comm is not null,'happy','sad') 心情 from emp;
--何老师上的课
if(条件,条件满足时的结果,条件不满足的结果)
#案例:工资大于1000为工资高,否则为工资低
select sal,if(sal>1000,'工资高','工资低') from emp;
第九章:链接查询
链接查询:也可以叫做跨表查询,需要关联多个表进行查询。
9.1 SQL92语法 (自链接)不常用不推荐
案例:显示每个员工的姓名和部门名称
select ename,dname from emp,dept;
以上输出不正确,输出了56条数据,就是两个表记录的乘积,这种情况我们称为 笛卡尔积
笛卡尔积的场景,例如:
1 4
2 5
3 6
(14 15 16 24 25 26 34 35 36 共有9种可能)
出现错误的原因:没有指定链接条件
#指定链接条件:emp.deptno=dept.deptno
正确:select ename,dname from emp,dept where emp.deptno=dept.deptno;
以上结果输出正确,因为假如了正确的链接条件,即:emp.deptno=dept.deptno,上面的查询也可以成为‘内链接’,只查询相等的数据(链接条件相等的数据)
#练习:查询员工名字和工作地点
#链接条件 emp.deptno=dept.deptno
select emp.ename,dept.loc from emp,dept where emp.deptno=dept.deptno;
#我们还可以给表起别名(在from后的表名后面先空格,再用单字母起名)
select e.ename,d.loc from emp e,dept d where e.deptno=d.deptno;
即:
select
e.ename,d.loc
from
emp e,dept d
where
e.deptno=d.deptno
#查询员工姓名和直属领导姓名
select e.ename 员工姓名,m.ename 直属领导姓名 from emp e,emp m where e.mgr=m.empno;
即:
select
e.ename 员工姓名,m.ename 直属领导姓名
from
emp e,emp m
where
e.mgr=m.empno
#上面链接的方式称为‘自连接’,因为实际只有一张表,具体查询方法就是把一张表看成两张表,如上面的例子,第一个表时emp e 代表员工表,第二个emp m代表了领导表
9.2 SQL99语法(自链接)
语法:select 字段 from 表a join 表b on 链接条件 where 查询条件
注意:
from 和 join 里的字段位置前后可以换;
内连接 join,取得是交集
#案例:显示薪资大于2000的员工姓名并显示薪水和部门名称
92写法:(不推荐)
select e.ename,e.sal, d.dname from emp e,dept d where e.deptno=d.deptno and e.sal>2000;
99写法:(常用写法)
select e.ename,e.sal, d.dname from emp e join dept d on e.deptno=d.deptno where e.sal>2000;
92和99结合写法:
select e.ename,e.sal, d.dname from emp e join dept d where e.deptno=d.deptno and e.sal>2000;
#sql92和sql99语法区别:sql99语法能做到链接条件和查询条件分离,特别是多个表链接的时候会比sql92结构清晰
9.3 left/right (outer) join(外链接)
例如:
表1 表2
世纪(有宿舍) A
明飞(有宿舍) B
顺哥(无宿舍) C
(表1 left join 表2) (表1 right join 表2)
世纪A 世纪A
明飞B 明飞B
顺哥C Cnull
#案例:查询员工姓名,并显示员工部门名称和薪资,如果部门没有员工,该部门也要显示出来
select e.ename 员工姓名,e.sal 薪资,d.dname 员工部门 from dept d left join emp e on e.deptno=d.deptno;
select e.ename 员工姓名,e.sal 薪资,d.dname 员工部门 from emp e right join dept d on e.deptno=d.deptno;
即:
select
e.ename 员工姓名,e.sal 薪水,d.dname 员工部门
from
emp e
right join
dept d
on
e.deptno=d.deptno;
+----------+---------+------------+
| 员工姓名 | 薪资 | 员工部门 |
+----------+---------+------------+
| MILLER | 1300.00 | ACCOUNTING |
| KING | 5000.00 | ACCOUNTING |
| CLARK | 2450.00 | ACCOUNTING |
| FORD | 3000.00 | RESEARCH |
| ADAMS | 1100.00 | RESEARCH |
| SCOTT | 3000.00 | RESEARCH |
| JONES | 2975.00 | RESEARCH |
| SMITH | 800.00 | RESEARCH |
| JAMES | 950.00 | SALES |
| TURNER | 1500.00 | SALES |
| BLAKE | 2850.00 | SALES |
| MARTIN | 1250.00 | SALES |
| WARD | 1250.00 | SALES |
| ALLEN | 1600.00 | SALES |
| NULL | NULL | OPERATIONS |
+----------+---------+------------+
左链接能完成的功能,右链接一定可以完成
小结:
链接分类:
1.内连接:
语法:表1 innner join 表2 on 链接条件(where查询条件)
注意:做链接查询的时候一定要写上关联条件,inner可以省略
2.外链接:
语法:表1 left/right outer join 表2 on 关联条件(where查询条件)
注意:做链接查询的时候一定要写上关联条件,outer可以省略
左外链接和右外链接的区别:
左链接以左边的表为准和右边的表链接,右表与左表相等和不等的结果都会显示出来,右表符合条件的显示,不符合条件的为null;
右链接以右边的表为准和左边的表链接,左表与右表相等和不等的结果都会显示出来,左表符合条件的显示,不符合条件的为null;
#补充:主表的数据一定会展示,但副表的数据不一定
9.4三张表及以上的链接
案例:查询员工姓名和部门名称和薪资等级
select e.ename,d.dname,s.grade from emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal;
即:
select
e.ename,d.dname,s.grade
from
emp e
join dept d on e.deptno=d.deptno
join salgrade s on e.sal betweem s.losal and s.hisal;
+--------+------------+-------+
| ename | dname | grade |
+--------+------------+-------+
| SMITH | RESEARCH | 1 |
| ALLEN | SALES | 3 |
| WARD | SALES | 2 |
| JONES | RESEARCH | 4 |
| MARTIN | SALES | 2 |
| BLAKE | SALES | 4 |
| CLARK | ACCOUNTING | 4 |
| SCOTT | RESEARCH | 4 |
| KING | ACCOUNTING | 5 |
| TURNER | SALES | 3 |
| ADAMS | RESEARCH | 1 |
| JAMES | SALES | 1 |
| FORD | RESEARCH | 4 |
| MILLER | ACCOUNTING | 2 |
+--------+------------+-------+
#练习:查询员工姓名、领导名、部门名称、薪资等级
select e.ename, m.ename,d.dname,s.grade from emp e join emp m on e.mgr=m.empno join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal;
第十章 嵌套子查询
什么是子查询??
子查询就是嵌套的select语句,可以理解为子查询是一张表、
方法:用此方法时,可以参照英语断句把需求分解再组合
10.1 在where语句中使用子查询
其实就是在where语句中假如select语句
#案例:查询为管理者的员工编号和姓名
(断句:查询哪些是管理者,再查出姓名)
#用之前学过的知识做法:
select distinct(empno) 员工编号,m.ename 管理者姓名 from (select m.empno,m.ename from emp e join emp m on e.mgr=m.empno) m ;
#新思路:
1.首先查询管理者的empno
select distinct(mgr) from emp where mgr is not null;
2.查询员工编号和姓名在1的查询结果之内的
select ename,empno from emp where empno in(select distinct(mgr) from emp where mgr is not null);
==================================
1.首先查询管理者的empno
select mgr from emp;
+------+
| mgr |
+------+
| 7902 |
| 7698 |
| 7698 |
| 7839 |
| 7698 |
| 7839 |
| 7839 |
| 7566 |
| NULL |
| 7698 |
| 7788 |
| 7698 |
| 7566 |
| 7782 |
+------+
去重
select distinct(mgr) from emp;
+------+
| mgr |
+------+
| 7902 |
| 7698 |
| 7839 |
| 7566 |
| NULL |
| 7788 |
| 7782 |
+------+
去空值
select distinct(mgr) from emp where mgr is not null;
+------+
| mgr |
+------+
| 7902 |
| 7698 |
| 7839 |
| 7566 |
| 7788 |
| 7782 |
+------+
上面这六个empno就是六个领导的empno
2.从emp里找到有这六个编号的人名
select ename,empno from emp where empno in(select distinct(mgr) from emp where mgr is not null);
+-------+-------+
| ename | empno |
+-------+-------+
| FORD | 7902 |
| BLAKE | 7698 |
| KING | 7839 |
| JONES | 7566 |
| SCOTT | 7788 |
| CLARK | 7782 |
+-------+-------+
============================================
#练习:查询哪些人的薪水高于员工的平均薪水,显示员工号,员工姓名,员工薪水
(断句:查询员工的平均薪水,再查那些人高于平均薪水的员工号,员工姓名,员工薪水)
select empno,ename,sal from emp where sal>(select avg(sal) from emp);
+-------+-------+---------+
| empno | ename | sal |
+-------+-------+---------+
| 7566 | JONES | 2975.00 |
| 7698 | BLAKE | 2850.00 |
| 7782 | CLARK | 2450.00 |
| 7788 | SCOTT | 3000.00 |
| 7839 | KING | 5000.00 |
| 7902 | FORD | 3000.00 |
+-------+-------+---------+
10.2 在from后面使用子查询
可以将子查询看成一张表
#案例:查询为管理者的员工编号和姓名
第一步:先查询管理者去重后的员工编号
select distinct(mgr) from emp where mgr is not null;
+------+
| mgr |
+------+
| 7902 |
| 7698 |
| 7839 |
| 7566 |
| 7788 |
| 7782 |
+------+----------------------m
把它看作临时表起名为 m,这个表有一个mgr字段
#sql92写法(不推荐)
select e.empno,e.ename from emp e,(select distinct(mgr)from emp where mgr is not null) m where m.mgr=e.empno;
#sql99写法(常用)
select e.empno,e.ename from emp e join(select distinct(mgr)from emp where mgr is not null) m on m.mgr=e.empno;
即:
select
e.empno,e.ename
from
emp e
join
(select distinct(mgr) from emp where mgr is not null) m
on
m.mgr=e.empno
#练习:查询各个部门平均薪水等级,需要显示部门号,平均薪水和薪水等级
思路:
1.首先查询各个部门的平均薪水
select avg(sal) pj,deptno from emp group by deptno;
+-------------+--------+
| pj | deptno |
+-------------+--------+
| 2175.000000 | 20 |
| 1566.666667 | 30 |
| 2916.666667 | 10 |
+-------------+--------+-----------------a表
2.将部门的平均薪水作为一张a表和salgrade表建立链接,取得等级
+-------+-------+-------+
| GRADE | LOSAL | HISAL |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+--------------salgrade表
select a.deptno,a.pj,s.grade from (select avg(sal) pj,deptno from emp group by deptno) a join salgrade s on a.pj between s.losal and s.hisal
即:
select
a.deptno,a.pj,s.grade
from
(select avg(sal) pj,deptno from emp group by deptno) a
join
salgrade s
on
a.pj between s.losal and s.hisal
+--------+-------------+-------+
| deptno | pj | grade |
+--------+-------------+-------+
| 20 | 2175.000000 | 4 |
| 30 | 1566.666667 | 3 |
| 10 | 2916.666667 | 4 |
+--------+-------------+-------+
简单总结:大多数情况下,where后面子查询是一个字段(一列,一列的数据,一组值)或者一个值;from后面的子查询是一个表。
10.3 select语句中使用子查询(了解)
#查询员工信息显示员工所属部门名称和员工名
select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno;
#第二种:select语句中使用子查询
select e.ename,(select d.dname from dept d where e.deptno=d.deptno) as dname from emp e;
第十一章:limit分页
语法:select 字段 from 表名 where 条件 group by 字段 order by 字段 limit m,n;
m:记录开始的索引值,索引值是从0开始的,表示第一条记录
n:表示从m+1条开始的记录,取n条
#案例:取emp表中数据的第四和第五条
select*from emp limit 3,2;
#查询工资前五名的员工信息
select*from emp order by sal desc limit 0,5;
select*from emp order by sal desc limit 5;
#查询工资在5-10名的员工信息
select*from emp order by sal desc limit 4,6;
#查询工资在3-8名的员工信息
select*from emp order by sal desc limit 2,6;
补充一点:如果m为0,可以省略
#例如:查询工资前五名的员工信息
select*from emp order by sal desc limit 5;
第十二章 union
union可以将结果相加合并
#找出emp表工作岗位是销售或经理的员工名
第一种 or
select ename from emp where job ='manager' or job='salesman';
第二种 in
select ename from emp where join in ('manager','salesman');
第三种 union
select ename from emp where job='manager'
union
select ename from emp where job='salesman';
1.字段类型数量必须一致
(字段类型:int,float,date,char,varchar,numeric,bit)
2.select时,字段顺序要保持完全一致
union 去重连接
union all 不去重连接
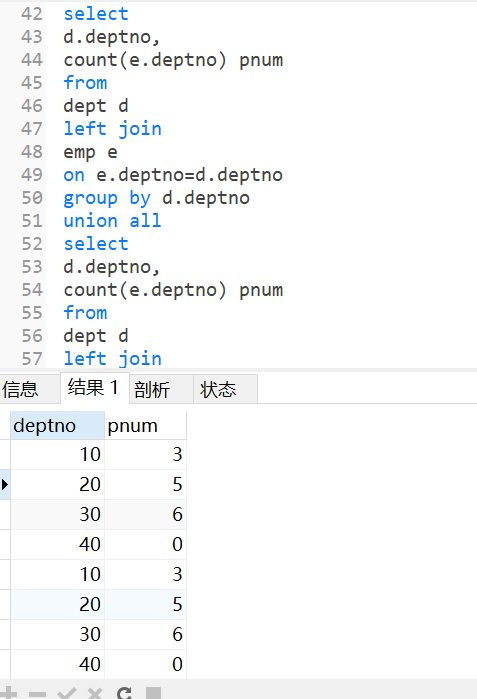
#union 上下拼,join 左右拼
第十三章 窗口函数 over
注:针对排名,如成绩排名,薪资排名等
语法:
select 字段, 分析函数()over(partition by 字段 order by 字段) from 表名;
13.1 分析函数
分析函数分为两类:排名类和聚合类
13.1.1 排名类与over()连用
1.row_number() :
按照值排序产生一个自增编号,不会重复1,2,3,4,5...(不用于成绩类排名)
案:1:给emp表中的sal字段进行降序排序,并添加一个自增序号
select sal,row_number()over(order by sal desc) 薪资排名 from emp;
案例2:统计每个部门的sal(薪资排名),并添加一个自增编号
select sal,deptno,row_number()over(partition by deptno order by sal desc) 薪资排名 from emp;
2.rank() :
跳跃排序,按照值排序产生一个自增编号,值相等时这个编号会重复,同样产生空位 1,2,3,4,4,4,7
案例:给emp表中sal字段进行降序排序,输出名次,薪资相同排名相同
select sal,rank()over(order by sal desc) 薪资排名 from emp;
select sal,deptno,rank()over(partition by deptno order by sal desc) 薪资排名 from emp;
3.dense_rank() :
连续排序,按照值排序产生一个自增编号,值相等时会重复,但是不会产生空位 1,2,2,3,3,3,3,4
案例:给emp表中的sal字段进行降序排序,输出名次,要求不许有间隔
select sal,dense_rank()over(order by sal desc) 薪资 排名 from emp;
select sal,deptno,dense_rank()over(partition by deptno order by sal desc) 薪资排名 from emp;
13.1.2 聚合类与over()连用
聚合函数:
1.count 计数
--案例1:统计emp表中记录的数量并在随后新增一个字段显示
select*,count(*)over() 总人数 from emp;
--案例2:统计emp表中每个部门的人数并在随后新增一个字段显示
select*,count(*)over(partition by deptno) 部门人数 from emp;
--案例3:统计emp表中记录的数量,并根据empno进行累计计数
select*,count(*)over(order by empno) 总人数 from emp;
--案例4:按照deptno进行分组,要求显示每个组内根据empno进行累计计数
select*,count(*)over(partition by deptno order by empno) 部门人数 from emp;
2.sum 求和
3.avg 平均
4.max 最小
5.min 最大
13.2 partiton by
用法和 group by 一样,只能在窗口函数中使用,搭配分析函数时,分析函数按照每一组去进行计算
13.3 over() 窗口函数
注意 窗口函数中:可以不分组,可以不排序
第十四章 索引
14.1 索引原理
索引被用来快速找出在一个列上用一特定值的行。
如果没有索引,Mysql不得不首先从第一条记录开始,找出相关的行然后读完整个表,表越大,花费的时间越多。
比如:我们查询工资大于1500 的薪资
select sal from emp where sal>1500;
+---------+
| sal |
+---------+
| 1600.00 |
| 2975.00 |
| 2850.00 |
| 2450.00 |
| 3000.00 |
| 5000.00 |
| 3000.00 |
+---------+
现在我们没有使用索引,找到这些记录是通过全表查找
explain select sal from emp where sal>1500;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 33.33 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
Extra
Using where
什么时候需要给表中字段添加索引?
1.表中该字段数据量庞大
2.经常被查询,经常出现在where子句中的字段
3.经常被DML(delete insert update)操纵的字段不建议添加索引
优点:索引相当于一本书的目录,主键会自动添加索引,所以我们以后查询的时候通过主键查询效率会更快
14.2 创建索引格式
create index 索引名 on 表名(字段名);
--案例 给emp表中的sal字段添加一个索引,索引名为sindex
create index sindex on emp11(sal);
14.3 查看索引
show index from 表名;
--查看emp表中的索引
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| emp11 | 1 | sindex | 1 | SAL | A | 12 | NULL | NULL | YES | BTREE | | | YES | NULL |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
添加索引后再来查询工资大于1500的薪资
select sal from emp where sal>1500;
explain select sal from emp where sal>1500;
+----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | emp | NULL | range | sindex | sindex | 9 | NULL | 7 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+--------------------------+
此时查询结果出现了:Using index
14.4 删除索引
drop index 索引名 on 表名;
案例:删除emp表中的索引sindex
drop index sindex on emp;
证明:
show index from emp;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| emp | 0 | PRIMARY | 1 | EMPNO | A | 14 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
第十五章 视图
老板
一张表
奶茶名字 售价 甜度 成本 受欢迎等级 顾客评价 杯盈利
针对不同的对象,展示不同的字段结果
15.1 什么是视图
视图是站在不同的角度去看待同一份数据,它是一张虚拟表,本身不存数据,简单说就是获取想要看到的和使用的表的局部数据
视图的好处:
1.访问数据表的简单
2.可用来对不同用户显示不同的表中内容
视图的作用:
1.提高效率
2.隐藏表的实现细节
3.提供了数据的独立性,让用户不知道数据来源是什么
15.2 视图的创建和删除
创建视图:
create view 视图名称 as select 字段 from 表名;
删除视图:
drop view 视图名称;
15.3 视图的增删改
对视图的增删改会影响到原表中的数据,有一些业务需要通过视图的形式对原表中的数据进行增删改,但是又不能直接访问原表
--将emp表复制出一个emp1表
create table emp1 as select*from emp;
select*from emp1;
--给emp表创建视图eview 包含字段empno,enamel,job,sal
create view 视图名称 as select 字段 from 表名;
create view eview as select empno,ename,job,sal from emp;
--查看视图中的数据
select*from eview;
-修改视图中姓名为smith工资为90000
update eview set sal=90000 where ename='smith';
--查看原表中的数据(原表的smith薪资已经通过视图eview被修改)
select*from emp1;
--删除视图
drop view eview;
--删除emp1
drop table emp1;
第十六章 存储引擎
16.1 存储引擎的使用
数据库中的每个表都(在被创建的时候)被指定了存储引擎来处理
服务器可用的引擎依赖于以下因素:
1.mysql版本
2.服务器在开发时如何配置
3.启动选项
16.2 查看存储引擎
show engines \G;
#案例:查看某个表使用了哪个存储引擎
show create table 表名\G;
MyISAM:mysql默认的存储引擎
*************************** 6. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
InnoDB:用于事务的处理,事务的支持
*************************** 7. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
16.3 补充
在创建表时可使用engine选项,为表指定存储引擎
create table 表名(字段 字段类型...) engine=存储引擎名;
如果在创建表时没有指定存储引擎,则该表使用当前默认的存储引擎
(默认的存储引擎和字段的default一样,可以设置修改)
第十七章 事务
我 国庆
10000 0
10000-8000 0+8000--怎么保证这两项操作是同时成功???需要事务
概念:
事务可以保证多个操作的原子性,要么全成功,要么全失败。对于数据库来说事务保证批量的DML(insert delete upate)要么全部成功,要么全部失败。
17.1 事务的四个特征:ACID
a. 原子性(Atomicity):整个事务中所有的操作,必须作为一个单元全部完成(全部取消)。
c. 一致性:在事务开始之前和事务开始扣数据库保持一致状态
i. 隔离性:一个事务不会影响其它事务的运行
d. 持久性:在事务完成后,该事务对数据库所做的更改将持久的保存在数据库找那个,不会被回滚
17.2 事务的一些概念
事务:(transaction)
开启事务:start transaction
提交事务:commit
回滚事务:rollback
注意 关于回滚要注意,只能回滚insert,delete和update,不能回滚select(回滚select没意义)
17.3 事务的提交和回滚演示
1.建表
create table stu (id int(5),name varchar(10));
2.查询表中数据
select*from stu;
--结果:Empt set(0.00 sec)
3.插入数据
insert into stu values (1,'张三');
4.开启事务
start transaction;
--结果:Query OK, 0 rows affected (0.00 sec)
5.插入数据
insert into stu values (2,'世纪');
6.查看数据
select*from stu;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 世纪 |
+------+------+
7.回滚rollback
rollback;
8.查看数据
select*from stu;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
+------+------+
17.4 事务的隔离级别
当多个用户并发地访问同一个表时,可能会出现下面的问题:
1.脏读取(read uncommitted)
一个事务开始读取了某行数据,但是另外一个事务已经更新了但没提交,就会出现脏读
2.不可重复读(read committed,r u)
在同一个事务中,同一个读操作对同一个数据前后两次读取产生了不同的结果,这就是不可重复读
3.幻像读(r r)
指在一个事务中以前没有的行,由于其他事务提交而出现新的行
17.5 InnoDB实现的四个隔离级别
1.读未提交
read uncommitted
--隔离级别:窗户纸
--会出现脏读取和可重复读
【a与b可以同时修改数据,也可以彼此同步看到彼此修改的数据】
2.读已提交
read committed
--隔离级别:墙
--可重复读
【a与b可以同时修改数据,直到b进行commit后,a才能看到b修改的数据】
3.可重复读
repeatable read
--隔离级别:钢门
--幻像读
【a与b可以同时修改数据,直到a进行commit后,a才能看到b修改的数据】
4.串行化(序列化)
--隔离级别:完全隔离
设置隔离级别:set global transaction isolation level + 上面的1/2/3/4
【a与b不能同时修改数据,直到a进行commit后,b才能查看数据】