Linux内核中的链表——struct list_head
Linux内核中经典链表 list_head 常见使用方法解析_风亦路的博客-CSDN博客_init_list_head 做内核驱动开发经常会使用linux内核最经典的双向链表 list_head, 以及它的拓展接口(或者宏定义): list_add , list_add_tail, list_del , list_entry ,list_for_each , list_for_each_entry ...... 每次看到这些接口,感觉都很像,并且陈老师的那本书《深入理解linux内核》(UL...https://blog.csdn.net/wanshilun/article/details/79747710
我们之前认为的链表和写的链表 是这样定义的:
这种方法就是将数据结构嵌入链表
struct list_node{
char buf[128];
int num;
struct list_node *prev;
struct list_node *next;
}我们这样定义一个链表的节点,这个节点包含了 char buf[128] 和 int num 这两个数据就是数据域
prev和next就是指针域
可见我们是把数据结构放在了链表里,这样子就有一个问题:我们定义的list_node 的复用率很低。因为如果在其他场景需要使用链表 但是每个节点需要添加一个char name 那我们就要重新编写一个
struct list_node ! 这种低效率的方法 内核肯定是不会使用的!
Linux内核中的链表
内核中的链表的使用是将链表嵌入到数据结构中的!
内核中的标准链表是环形双向链表:

双向环形链表就像一个圈一样,所以每一个节点都可以作为头结点、尾结点
内核版本:4.1.15, 在目录include/linux/types.h中定义了list_head结构:
struct list_head {
struct list_head *next, *prev;
};
next指针指向下一个链表节点,prev指针指向前一个节点。
可以看到,很简单,Linux内核中不是将数据结构嵌入链表,而是将链表嵌入数据结构。
list_head本身其实并没有意义——它需要被嵌入到你自己的数据结构中才能生效!
举个例子:
struct data_struct{
char buf[128];
int num;
struct list_head node;
}我们将链表嵌入数据结构,将链表的节点和数据分离开来,这样对于不同的数据域需求 我们都可以通过list_head作为链表的节点。
contianer_of ()宏
container of()函数简介_叨陪鲤的博客-CSDN博客_container_of函数 在linux 内核编程中,会经常见到一个宏函数container_of(ptr,type,member), 但是当你通过追踪源码时,像我们这样的一般人就会绝望了(这一堆都是什么呀? 函数还可以这样定义??? 怎么还有0呢??? 哎,算了,还是放弃吧。。。)。 这就是内核大佬们厉害的地方,随便两行代码就让我们怀疑人生,凡是都需要一个过程,慢慢来吧。 其实,原理很简单: ...https://blog.csdn.net/s2603898260/article/details/79371024
container_of宏的作用:
通过:
1.指向该结构体中的成员member的指针ptr
2.该结构体类型type
3.成员member
来获得该数据结构的起始地址
(上面说的成员member 就比如我数据结构体定义的是:struct data{ struct list_head list } 那list就可以作为成员member传入 作为container_of的第三个参数)
使用宏container_of()我们可以很方便地从链表指针找到父结构中包含的任何变量。这时因为在C语言中,一个给定结构体中的变量偏移在编译时地址就被ABI固定下来了。

container_of宏的定义:
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
* */
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})/*member的地址减去size就得到该数据结构
的起始地址*/
其次为 offserof 函数原型:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)看下container_of宏的注释:
(1)根据结构体重的一个成员变量地址导出包含这个成员变量mem的struct地址。
(2)参数解释:
ptr : 成员变量mem的地址
type: 包含成员变量mem的宿主结构体的类型
member: 在宿主结构中的mem成员变量的名称
container_of(ptr, type,member)函数的实现包括两部分:
1. 判断ptr 与 member 是否为同一类型
2. 计算size大小,结构体的起始地址 = (type *)((char *)ptr - size) (注:强转为该结构体指针)
现在我们知道container_of()的作用就是通过一个结构变量中一个成员的地址找到这个结构体变量的首地址。
container_of(ptr,type,member),这里面有ptr,type,member分别代表指向成员的指针、数据结构类型、成员。
list_entry()宏
我们可以使用通过contianer_of()宏实现的方法 list_entry()来访问链表嵌入的数据结构中的数据域:
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)struct student {
char name[20];
int age;
struct list_head list;
};
int main()
{
//struct list_head stu_head = {&stu_head, &stu_head};
struct list_head stu_head;
INIT_LIST_HEAD(&stu_head);
struct student *stu1;
stu1 = malloc(sizeof(*stu1));
strcpy(stu1->name, "jack");
stu1->age = 20;
struct student *stu2;
stu2 = malloc(sizeof(*stu2));
strcpy(stu2->name, "bob");
stu2->age = 30;
struct student *stu3;
stu3 = malloc(sizeof(*stu3));
strcpy(stu3->name, "bobc");
stu3->age = 31;
list_add(&stu1->list, &stu_head);
list_add(&stu2->list, &stu_head);
list_add(&stu3->list, &stu_head);
struct student *stu;
list_for_each_entry(stu, &stu_head, list) {
printf("stu->name=%s\n",stu->name);
}
return 0;
}
输出如下:
stu->name=bobc
stu->name=bob
stu->name=jack
同时问题也来了:
1.假设我们有一个保存data_struct结构体的链表。我们之前那种定义的方式 只要访问到链表的节点就可以访问到数据域,但是现在使用list_head 后 我们访问node->prev 也就是访问到了链表的前一个节点,也就是访问到了前一个data_struct结构体中的node成员。那我们怎么访问到数据?答:
使用container_of宏,我们定义一个简单的函数便可返回包含list_head的父类型结构体:
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
依靠list_entry()方法,内核提供了创建、操作以及其他链表管理的各种例程,所有这些方法都不需要知道list_head所嵌入的对象数据结构。
2.使用list_head 这种方式来构建链表,那么链表的不同节点嵌入的数据结构是不是可以不一样?
比如:
struct data_struct{
char buf[128];
int num;
struct list_head node;
}struct data2_struct{
char buf2[128];
int num2;
struct list_head node;
}相关的操作函数和宏定义
Linux内核中经典链表 list_head 常见使用方法解析_风亦路的博客-CSDN博客_init_list_head 做内核驱动开发经常会使用linux内核最经典的双向链表 list_head, 以及它的拓展接口(或者宏定义): list_add , list_add_tail, list_del , list_entry ,list_for_each , list_for_each_entry ...... 每次看到这些接口,感觉都很像,并且陈老师的那本书《深入理解linux内核》(UL...https://blog.csdn.net/wanshilun/article/details/79747710
1.INIT_LIST_HEAD()/LIST_HEAD()
初始化链表节点 让其指向自己
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}常使用INIT_LIST_HEAD()这个函数 或者 LIST_HEAD()这个宏来初始化链表的节点!
可以如下
1:
LIST_HEAD(head);
2:
struct list_head head;
LIST_HEAD_INIT(head);我们可以创建一个数据结构,然后在此结构中再嵌套mylist字段,宿主结构又有其它的字段(进程描述符 task_struct,页面管理的page结构,等就是采用这种方法创建链表的)。为简便理解,定义如下:
struct my_task_list {
int val ;
struct list_head mylist;
}创建第一个节点
struct my_task_list first_task =
{ .val = 1,
.mylist = LIST_HEAD_INIT(first_task.mylist)
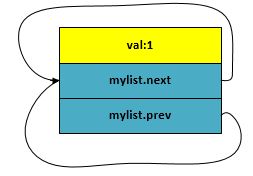
};这样mylist 就prev 和 next指针分别指向mylist自己了,如下图:
2.list_add():
向传入的链表节点后插入节点!
如下所示。 根据注释可知,是在链表头head后方插入一个新节点new。
并且还说了一句:可以利用这个接口实现堆栈 (why? 稍后再做分析)
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}list_add再调用__list_add接口
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}其实就是在head 链表头后和链表头后第一个节点之间插入一个新节点。然后这个新的节点就变成了链表头后的第一个节点了。
举个例子:
依然用上面的my_task_list结构体举例子
首先我们创建一个链表头 header_task
LIST_HEAD(header_task);
然后再创建实际的第一个节点
struct my_task_list my_first_task =
{ .val = 1,
.mylist = LIST_HEAD_INIT(my_first_task.mylist)
};接着把这个节点插入到header_task之后
list_add(&my_first_task.mylist, &header_task);
然后在创建第二个节点,同样把它插入到header_task之后
struct my_task_list my_second_task =
{ .val = 2,
.mylist = LIST_HEAD_INIT(my_second_task.mylist)
};其实还可以用另外一个接口 INIT_LIST_HEAD 进行初始化(参数为指针变量), 如下:
struct my_task_list my_second_task;
my_second_task.val = 2;
INIT_LIST_HEAD(&my_second_task.mylist);list_add(&my_second_task.mylist, &header_task)
以此类推,每次插入一个新节点,都是紧靠着header节点,而之前插入的节点依次排序靠后,那最后一个节点则是第一次插入header后的那个节点。最终可得出:先来的节点靠后,而后来的节点靠前,“先进后出,后进先出”。所以此种结构类似于 stack“堆栈”, 而 header_task就类似于内核stack中的栈顶指针esp, 它都是紧靠着最后push到栈的元素。
也就是说使用list_add()向链表中添加节点 就是将新节点插入到头节点和它的next节点之间!
这样的链表实现方式 就满足“先进后出“ 这也就是为什么我们前面说可以通过这个接口来实现堆栈!
2.list_add_tail ( ) :
向传入的链表节点前插入节点!
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}从注释可得出:(1)在一个特定的链表头前面插入一个节点
(2)这个方法很适用于队列(先进先出)的实现 (why?)
进一步把__list_add ()展开如下:
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}所以,很清楚明了, list_add_tail就相当于在链表头前方依次插入新的节点(也可理解为在链表尾部开始插入节点,此时,header节点既是为节点,保持不变)
利用上面分析list_add接口的方法可画出数据结构图形如下。
(1)创建一个 链表头(实际上应该是表尾), 同样可调用 LIST_HEAD(header_task);
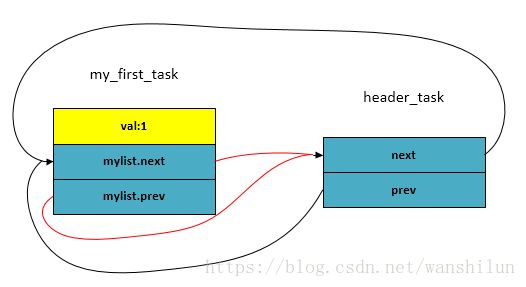
(2)插入第一个节点 my_first_task.mylist , 调用 list_add_tail(& my_first_task.mylist, & header_task);
(3) 插入第二个节点my_second_task.mylist,调用list_add_tail(& my_second_task.mylist, &header_task);
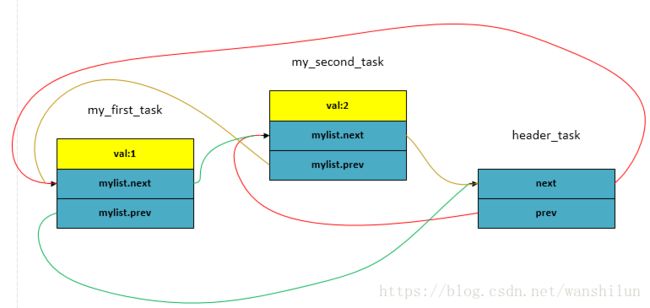
依此类推,每次插入的新节点都是紧挨着 header_task表尾,而插入的第一个节点my_first_task排在了第一位,my_second_task排在了第二位,可得出:先插入的节点排在前面,后插入的节点排在后面,“先进先出,后进后出”,这不正是队列的特点吗(First in First out)!
总结
1.
不管是list_add()还是list_add_tail()都需要传入一个head参数
1.对于list_add()这个参数就是个链表中的节点 我们添加新节点就是 往这个节点后插入节点!类似于 ------> 往这个方向
2.对于list_add_tail()这个参数就是个链表中的节点 我们添加新节点就是 往这个节点前插入节点!类似于 <------往这个方向
有个问题:head这个参数不是头结点或者尾结点吗?它当然可以是头节点和尾结点。但是考虑一种情况,我们只有一个链表中的一个任意节点,要往这个链表添加节点。这时我们就是传入这个节点作为head参数,可以调用list_add()或者list_add_tail()来向前或者向后插入节点
(也可以这么认为 链表中的每一个)
这也就是为什么最好把
1.list_add()的作用理解成 向传入的链表节点后插入节点!
2.list_add_tail()的作用理解成向传入的链表节点前插入节点!
2.
使用这两个函数构建的链表都是双向环形链表!
这是因为我们使用INIT_LIST_HEAD()/LIST_HEAD( ) 一个节点的时候都让它的prev和next都指向自己了!且一开始只有一个链表头 我们初始化这个链表头 后 添加一个新节点
这个新节点的next指向 链表头(使用list_add_tail()添加的节点)或者链表头的next(使用list_add()添加的节点)这就构成环状了!
且 后面添加的新节点都是在头节点和第一次添加的新节点之间插入!这样依旧保持环状!
就相当于 用一只手抓住橡皮泥的两头这就是环状 我们在头尾之间拉长橡皮泥 但是他还是保持环状 就类似于插入新节点 。不得不说真是妙啊!
3.list_del()
删除链表
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}利用list_del(struct list_head *entry) 接口就可以删除链表中的任意节点了,但需注意,前提条件是这个节点是已知的,既在链表中真实存在,切prev,next指针都不为NULL。
list_for_each_entry():
遍历链表嵌入的数据结构
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define list_for_each_entry(pos, head, member) \ //遍历head
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
可见list_each_entry() 其调用的是 list_entry() 也就是container_of() 遍历了整个链表嵌入的数据结构