Python 中 openpyxl 模块封装,读写 Excel 文件中自动化测试用例数据
只有测试数据和错误提示信息不同,其他代码都是一样的,不这样不易修改数据和维护,会有两点痛点
1.代码冗余极其严重, 程序可读性不佳
2.程序拓展性很差
往往我们在自动化测试汇总,会将数据放在 Excel 文件、CSV文件、数据库
Python 中处理 excel 数据的模块非常多,比如: xlxd(只读)、xlwd(只写)、openpyxl(可读写)
我们会 采用数据驱动思想,使用 openpyxl 当中的 load_workbook 来处理已存在的 Excel 文件数据,只能读写已 .xlsx 为拓展名的文件;openpyxl 当中的 workbook 方法,用于新建 excel, 几乎不用
以 .xlsx 为拓展名的文件,为一个 Excel 文件对象,一个 excel 对象中, 往往会有多个表单,一个表单中,有多个单元格对象;
重点:
- 从 excel 文件中获取的 整数 为 int 类型、获取的 小数 为 float 类型
- 除了 数字类型(小数、整数、浮点数)为 int、float 类型 以外, 其他所有有写内容的位置,获取的数据全部为 字符串 类型
- 如果是 空 的单元格不写任何内容,读取的是 空 类型
- 在单元各种写入 FALSE 显示为大写,格式为 bool,跟单元格的格式有关系
问:对 excel 相关操作使用类来封装? 封装有什么好处呢?
痛点:
- 每个接口每次都要打开文件,定位表单,获取数据,如果有100个那么每个都需要这几步
封装好处:
- 利于扩展、更简洁、可读性好,让程序的拓展性更好,让代码更加简洁,复用性高
- 封装后只要导入封装好的类,然后指定 Excel 文件名 和 表单名,就能够获取到所有的测试用例就两行代码
1、以字典(键值对的形式)数据类型,发起请求;
2、在 Excel 中写 字典 还是 json 好?
- 从 Excel 中读取出来就是字符串,不管是传给data、params,还是 json 也好,都是用 json 格式的参数,写在 Excel 中最方便;
- json 参数一目了然;取出来是字符串,方便转换;
一、基本的使用
Excel 文件和下面的py文件代码一定要在同一个文件夹内,不然需要指定具体的 Excel 文件路径-------大家都是大佬我就不多说了
读取数据不需要关闭文件,写入必须关闭文件;
from openpyxl import load_workbook
# 第一步. 打开 excel 文件:使用load_workbook(译:楼的我的不可)传入文件名
wb = load_workbook("cases.xlsx") # 返回创建一个Workbook的对象, 相当是一个excel文件# 获取所有的表单名# print(wb.sheetnames)
# 第二步. 定位表单两种方式
# active(译:艾克体舞)是默认第一个表单
# ws = wb.active # 默认获取第一个激活的表单, 会创建一个Worksheet对象, 相当于一个表单
# 也可以指定表单【'表单名'】
ws = wb['multiply']
# 第三步. 定位单元格 cell(译:赛欧),row:(译:肉)行、column:(译:犒劳木)列
one_cell = ws.cell(row=2, column=2) # 会创建一个Cell对象, 相当于一个单元格
# 使用 Cell(译:赛欧)对象中的 value 属性, 能获取单元格中的值
# print(one_cell.value) # 也可以 a = ws.cell(2, 2).value print(a)
# 方法一: 定位单元格后,使用value属性,将数据写入到指定的单元格
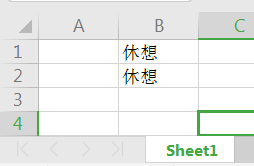
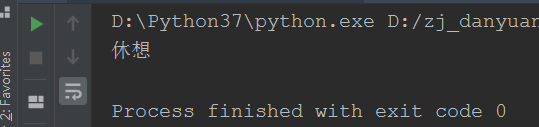
one_cell.value = "休想" # 修改单元格的值
# 方法二: 定位表单,使用cell方法,将数据写入到指定的单元格
ws.cell(row=2, column=3, value="休想")
# 保存 excel 文件 save(译:赛乌)
# 写入如果报错:PermissionError: [Errno 13] Permission denied: 'cases.xlsx' ,一定是excel文件未关闭
wb.save("cases.xlsx")
Excel 文件及打印结果:
二、获取下面表单中数据
方法一:cell 方法:
—不推荐使用,因为只能获取固定的行到行、列到列之间的数据
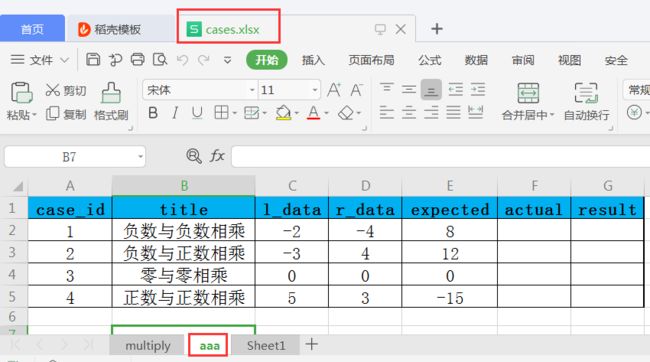
from openpyxl import load_workbook # 对已经存在的excel进行读写操作
# 1. 打开excel文件
wb = load_workbook("cases.xlsx") # 会创建一个Workbook的对象, 是一个excel文件
# 2. 定位表单
ws = wb['aaa']
# 3. 定位单元格
# 方法一:获取表单中数据:使用ws(译:我可谁特)当中的cell(译:赛欧)方法
# range(译:软解)
# min_row(译:敏.绕)代表最小行号:max_row(译:马克思.肉):最大行号
# min_column(译:敏.犒劳木)最小列号、max_column(译:敏.犒劳木):最大列号
for row in range(ws.min_row+1, ws.max_row+1): # 获取行号,range中最后一位取不到,需要+1
for col in range(ws.min_column, ws.max_column+1): # 获取列号
data = ws.cell(row, col).value # 获取值,使用value属性
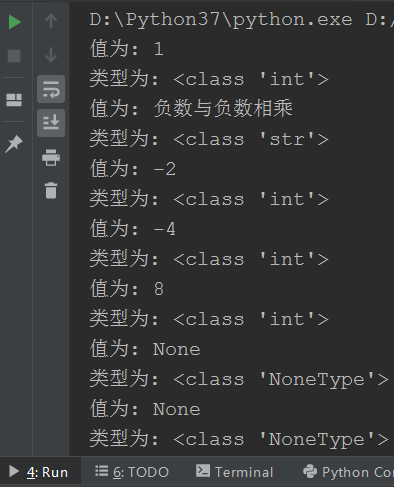
print("值为: {}\n类型为: {}".format(data, type(data))) # 打印结果
代码执行结果文档第一行:
方法二:使用 load_workbook 中 iter_rows(译:艾特.肉死)方法 + zip 函数 获取表单中数据
-----推荐使用这用,在自动化测试过程中每执行一条测试用例,都可以使用表头来获取具体的值
from openpyxl import load_workbook # 对已经存在的excel进行读写操作
# 1. 打开excel文件
wb = load_workbook("cases.xlsx") # 会创建一个Workbook的对象, 是一个excel文件
# 2. 定位表单
ws = wb['aaa']
# min_row(译:敏.绕)代表最小行号:max_row(译:马克思.肉):最大行号
# min_column(译:敏.犒劳木)最小列号、max_column(译:敏.犒劳木):最大列号
# 3. 定位单元格
# 方法二:使用 load_workbook 中 iter_rows(译:艾特.肉死)方法获取表单中数据
# openpyxl 版本为2.6以上,要不没有参数:values_only
# 获取的是单元格位置 使用 values_only = False 属性默认获取单元格对象
# 获取的是单元格位置 使用 values_only = True 后获取的是单元格的值
# 获取表头元祖,表头位置为0,表头为第一行,最小行号可以不写1,因为最大行号是1
# 结果为生成器对象,需要使用 tuple 转换为元祖,转换后为嵌套元祖的元祖,使用 位置 0 来获取表头第一个元素
head_data_tuple = tuple(ws.iter_rows(min_row=1, max_row=1, values_only=True))[0]
print(head_data_tuple)
# 获取除表头外测试用例数据,和获取表头一样,最大行,最小列可以不写
for one_tuple in tuple(ws.iter_rows(min_row=2, max_row=5, min_col=1, max_col=7, values_only=True)):
print(one_tuple)
# 表头和测试数据结果
# ('case_id', 'title', 'l_data', 'r_data', 'expected', 'actual', 'result')
# (1, '负数与负数相乘', -2, -4, 8, None, None)
# (2, '负数与正数相乘', -3, 4, 12, None, None)
# (3, '零与零相乘', 0, 0, 0, None, None)
# (4, '正数与正数相乘', 5, 3, -15, None, None)
head_data_tuple1 = tuple(ws.iter_rows(min_row=1, max_row=1, values_only=True))[0]
one_list1 = []
for one_tuple1 in tuple(ws.iter_rows(min_row=2, max_row=5, min_col=1, max_col=7, values_only=True)):
# 表头的元祖和数据元祖,使用 zip 方法进行转换(返回zip的生成器对象)
# 在使用 dict(译:迪克特)转换成字典
# 使用 append(译:额喷的)添加到列表当中,获取到一个嵌套字典的列表
one_list1.append(dict(zip(head_data_tuple1, one_tuple1)))
print(one_list1) # 打印结果
# 结果:
# [{'case_id': 1, 'title': '负数与负数相乘', 'l_data': -2, 'r_data': -4, 'expected': 8, 'actual': None, 'result': None},
# {'case_id': 2, 'title': '负数与正数相乘', 'l_data': -3, 'r_data': 4, 'expected': 12, 'actual': None, 'result': None},
# {'case_id': 3, 'title': '零与零相乘', 'l_data': 0, 'r_data': 0, 'expected': 0, 'actual': None, 'result': None},
# {'case_id': 4, 'title': '正数与正数相乘', 'l_data': 5, 'r_data': 3, 'expected': -15, 'actual': None, 'result': None}]
三、openpyxl 模块的封装:
使用 ddt 进行数据驱动,会将嵌套字典的列表进行拆包为不同的字典,每一个字典就是一条用例数据,取出预期结果和实际结果,msg;
那么以后就可以写一个实例方法就可以测试多条用例,因为每一个实例方法之间只有数据不同其他的代码都相同;
from openpyxl import load_workbook
class HandleExcel:
"""
封装excel文件处理类
"""
def __init__(self, filename, sheetname=None):
""" 定义构造方法
:param filename: 文件名=实例属性
:param sheetname: 表单名,如果表单名只有一个可以设置为默认值
"""
self.filename = filename
self.sheetname = sheetname
def get_cases(self):
"""
获取所有的测试用例,实例方法
:return:为嵌套字典的列表
"""
# 打开文件:使用load_workbook(楼的我的不可)传入文件名
wb = load_workbook(self.filename) # 返回创建一个Workbook的对象, 相当是一个excel文件
if self.sheetname is None: # 定位表单,判断是否制定表单默认空,为第一个表单
ws = wb.active # active 获取第一个表单
else:
ws = wb[self.sheetname] # 否则获取指定的表单
# min_row = 最小行号,max_row=最大行号(可以不写)
# min_col = 最小列号,max_col=最大列号
# values_only = 获取单元格的值
# 获取表头的信息,使用 iter_rows(艾特木肉丝)方法,嵌套元祖的元祖,省略最小行号
head_data_tuple = tuple(ws.iter_rows(max_row=1, values_only=True))[0]
one_list = []
for one_tuple in tuple(ws.iter_rows(min_row=2, values_only=True)): # 不需要表头最小行号为2,不需要最大行号,最大最小列号
# zip 函数将表头的元祖与每一行用例所在的元祖进行拼接,dict(译:迪克特) 转换为字典后,添加到列表当中 one_list = []
one_list.append(dict(zip(head_data_tuple, one_tuple)))
return one_list # 为嵌套字典的列表
def get_one_case(self, row):
"""
获取某一条测试用例
:param row: 行号
:return:嵌套字典的列表,使用位置进行获取
"""
return self.get_cases()[row - 1]
def write_result(self, row, actual, result):
"""
(维泽。瑞走特)写入数据到测试用例指定的行列中
:param row: 行号
:param actual: 实际结果
:param result: 用例执行的结果(Pass或者Fail)
:return:
"""
# 同一个Workbook对象, 如果将数据写入到多个表单中, 那么只有最后一个表单能写入成功,需要创建不同的对象
other_wb = load_workbook(self.filename) # 创建对象 = 打开一个文件
if self.sheetname is None:
other_ws = other_wb.active
else:
other_ws = other_wb[self.sheetname]
# 写入
if isinstance(row, int) and (2 <= row <= other_ws.max_row): # 不能修改表头,下一行开始,行号大于2,小于最大的行号
other_ws.cell(row=row, column=6, value=actual) # 在第六行写入实际结果
other_ws.cell(row=row, column=7, value=result) # 在第七行写入用例执行的结果
other_wb.save(self.filename) # save 保存文件
other_wb.close() # close(译:科楼司)关闭 ----- 读数据的时候不需要关闭,写数据的时候可关闭或不关闭
else: # 如果不是整数,行号小于2,并且大于最大的行号
print("传入的行号有误, 行号应为大于1的整数")
if __name__ == '__main__': # 自己写的模块自己用使用 main 函数
filename = "cases.xlsx"
sheetname = "Sheet1" # 指定第二个表单名
# 创建一个对象,filename=文件名和sheetname=表单名可以不传
# do_excel = HandleExcel(filename) # 传文件名,不传默认第一个表单
do_excel = HandleExcel(filename, sheetname)
# 获取所有的测试用例cases,使用对象调用实例方法
cases = do_excel.get_cases()
print(cases)
# 写入在第二行写入"初心", "青柠"
a = do_excel.write_result(2, "初心7", "青柠")
print(a)
最后:下方这份完整的自动化测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取 【保证100%免费】

