自定义数据类型----->结构、枚举、联合
通过一段时间的学习,我们已经了解了C语言的内置类型,也懂得怎么用内置类型去描述一些事物,但是在现实的生活情景里,仅仅用内置类型是无法准确描述一些事物的特征的!比如描述一个学生的信息,学生的信息是一个复杂的集合体,不可能仅仅通过某种单一的内置类型就可以准确地描述出来,为了解决这一问题,C语言设计者给我们设计了自定义的数据类型--->结构、枚举、联合。接下来,我们就仔细探究这三种类型。
一、结构体类型:
以描述学生的信息为案例,一个学生有如下的信息:姓名、性别、年龄这三个信息,那么姓名和性别用字符数组来存储,成绩用整型来存储的这样的一个信息综合体,每一个信息都是互相独立的,这种应用场景下我们应该使用结构体来存储,首先我们先来看结构体的声明的语法形式:
struct typename{
member 1;
member 2;
};
首先,struct是结构体关键字,表示接下来声明的类型是结构体类型!其次,紧挨着struct的是声明的结构体类型的名字,花括号里的是该结构体对应的成员的名字,接下来我们就创建一个学生结构体
//学生结构体的创建
struct Stu
{
char name[20];
char sex[10];
int age;
};这段代码声明的就是一个名为Stu的结构体,他有三个成员:name sex score
前两个分别是字符数组,最后一个是整型元素
了解了结构体的创建,接下来我们来看一看结构体变量应该如何使用!
#define _CRT_SECURE_NO_WARNINGS 1
#include
struct Stu
{
char name[20];
char sex[10];
int age;
};
//结构体变量的使用
void test()
{ //结构体变量的初始化方式:花括号初始化
struct Stu s1= { "zhangsan","Male",75 };
//结构体成员访问:结构体变量使用.来访问结构体成员
printf("姓名:%s\n", s1.name);
printf("性别:%s\n", s1.sex);
printf("年龄: %d\n", s1.age);
}
int main()
{
test();
return 0;
} 运行结果如下:
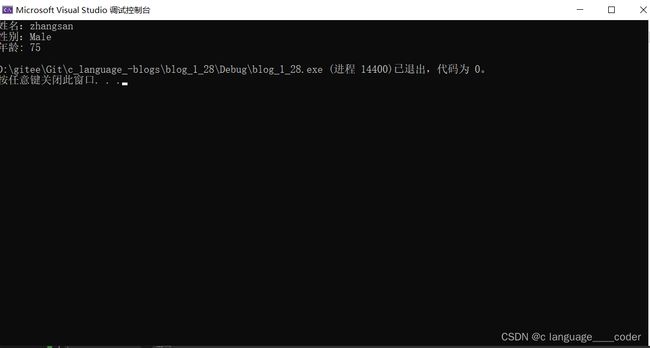
而假设你要用结构体指针,那么有两种访问结构体成员的方式:
strcut Stu* ps=&s1;//ps是一个结构体指针,指向s1
方式一:对指针解引用找到对应的结构体变量,再用.去访问结构体成员
(*ps).name;//使用方式一访问name成员,注意.的优先级高于*,所以要把*ps括起来才能拿到对应的结构体变量!
方式二:直接使用就“->”进行访问
ps->name;//直接就可以访问name成员
注意:在使用学生结构体的时候,类型是struct Stu而不是Stu,如果仅仅只想使用Stu作为结构体的类型名需要对struct进行typedef,即
typedef struct Stu Stu;
Stu s1;//正确,此时Stu等价与struct Stu,如果没有typedef则会编译出错!
第二:结构体成员不能包括同类型的成员,但可以包括同类型的指针,同样以学生结构体为例
struct Stu{
int age;
struct Stu stu;//错误,编译器无法确定要开辟多大的内存空间
struct Stu* ps;//正确,指针的大小是固定的,编译器能够明确应开辟多大的空间
}
补充:数据结构中的链表就是存储同类型指针的一种结构体,等到了数据结构的分析我们会介绍链表,这里先稍微提一提。
重点:结构体大小的计算
这是非常重要的知识点,关于结构体大小的计算,结构体的大小并不是简单的成员大小总和的叠加,它遵循的是内存对齐的规则!
对齐的规则如下:
1.结构体的第一个成员,存放在结构体开始的位置偏移量为0的偏移处
2.从第二个成员开始,每个成员都要对齐到对齐数的整数倍的地址处
3.结构体大小必须是最大对齐数的整数倍
最大对齐数:是所有成员中对齐数最大的!
对齐数:是指自身的类型大小和默认对齐数二者中的较小值,在vs环境下,默认对齐数是8
接下来我们来通过两个案例来尝试计算结构体的大小:
#define _CRT_SECURE_NO_WARNINGS 1
#include
//结构体大小的计算
struct A
{
char c1;//0
int i;//4-7 4
char c2;//8--12
};
int main()
{
printf("%u\n", sizeof(struct A));
return 0;
} 我们的分析如图所示:

我们分析的结果是12个字节,那么程序运行的结果是否和我们预料的一样呢?
程序运行结果如下:

确实结果和我们预期的一致,说明确实结构体在内存中存在内存对齐的现象,那么为什么会结构体需要在存储数据的时候采用内存对齐的方式呢?具体的原因大致有两点:
1.早期的计算机的寄存器只能在特定位置读取数据,所以在读取数据之前,编译器会对数据进行两次对齐处理以便于数据能够放置在特定的位置便于读取,而如果在存储的时候就采取内存对齐的方式,那么只需要在读取之前就只要在对齐一次就可以了,这样提高了效率!
2.采取内存对齐的方式也有利于一些结构体的拷贝操作等等
位段:
这也是一种结构体内部数据的存储形式,具体来讲就是按位进行存储
//位段
struct A
{
char _a : 2;
char _b : 4;
char _c : 3;
};
int main()
{
printf("%u\n", sizeof(struct A));
return 0;
}这里的结果是2,首先开辟了1个字节,a,b两个数据一共占用了6个比特位,剩下的比特位不够存放数据c,所以又开辟了1个字节的空间给c,所以最后一共开辟了两个字节。
接下来看这样一段代码:
//位段的使用
struct A
{
char _a : 2;
char _b : 4;
char _c : 3;
};
int main()
{
printf("%u\n", sizeof(struct A));
struct A a;
a._a = 2;
a._b = 10;
a._c = 7;
return 0;
}
我们预测内存会发生如下的变化,最后在内存窗口存储的值如图所示:

打开内存窗口观察结果如下:

发现结果和我们预期的是一样的,所以说在vs环境下,当一个位段大于剩余的比特位的时候,编译器会另外开辟1个字节,在新的字节里处理信息!不过对于位段有以下几个注意点:
1.使用位段只能是char,unsigned char,int ,unsigned int这几种数据类型
2.使用位段式存储读取的数据是按有符号数还是无符号数理解是标准没有规定的
3.不同的机子对应的数据的比特位是不同的,所以位段不具有跨平台性!
二、枚举类型:
在生活中,一些场景下的可能性是可以被枚举出来的,C语言提供了可以描述可被枚举的类型的集合---->枚举类型,关键字是enum,我们以枚举一周7天的可能性为例:
#include
enum Date
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{ //枚举变量d,并初始化为Mon
enum Date d = Mon;
return 0;
} 这就是枚举的语法格式,在使用枚举类型的时候有以下几个注意的点
1.枚举类型的每种可能取值都是有对应的整型值的:
如果没有指定值,第一个枚举的值默认是0,如案例里的Mon的值就是0
2.给某个枚举的可能取值指定初始值以后,后面的值以这个值为基准值而变化,以上面的枚举类型的值为例:
#include
enum Date
{
Mon,
Tues,
Wed,
Thur=5,
Fri,
Sat,
Sun
};
int main()
{
printf("Fri=%d\n", Fri);
printf("Sat=%d\n", Sat);
printf("Sun=%d\n", Sun);
return 0;
} 我们将Fri,Sat,Sun的值打印出来看看是否收到了影响:运行结果如下:
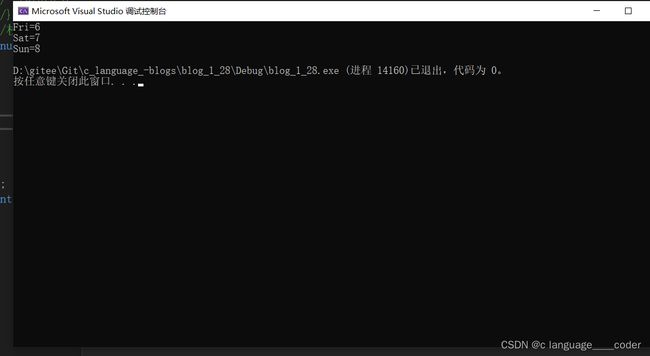
可以看出,Fri,Sat,Sun的值变成了6,7,8。因为Thur变成了5,所以向后的枚举类型的值依次加一。
3.枚举类型的值是常量,不能够修改!而枚举的内部我们的Thur=5并不是修改的值,而是初始化,因为常量也必须有一个初始值。
注意:在C语言编译器下,给枚举类型的变量赋整型初始值并不会报错,但不代表这是正确的!
在C++编译器下,枚举类型的变量必须用枚举类型的值赋值,否则就会报错!所以在使用枚举类型变量的时候,要用枚举类型的常量赋值才是正确的!
三、联合体
在C语言里,还有一类自定义的数据类型----->联合体,那么联合体有什么特别之处?联合体的应用场景又是什么样的呢?别急,听我慢慢和你说。
我们来看这样一段代码:
//联合体
union A
{
char c;
int i;
};
int main()
{
union A a;
printf("%p\n", &a);
printf("%p\n", &(a.c));
printf("%p\n", &(a.i));
return 0;
}
我们发现,联合体变量a,成员c,i的地址都是相同的,这个结果说明,成员c和成员i共用了一部分空间!事实上,联合体的特殊之处就是成员共用一部分空间!
那么联合体的大小应该怎么计算呢?联合体主要遵寻两个规则
1.联合体的大小至少是最大的成员的大小
2.联合体大小遵循对齐规则,大小是最大对齐数的整数倍数
就拿代码里的联合体做例子来说,联合体的大小最小是整型i的大小4,然后最大对齐数是4,因为4刚好是最大对齐的整数倍,所以该联合体的大小就是4
或许聪明的你已经猜到了联合体不能同时使用两个成员!因为成员共享一部分内存空间的原因,对其中一个成员的改变一定会改变另一个成员,所以联合体不能同时使用两个成员!
那么联合体有没有什么具体的使用场景呢?有,在你明确两种选择中你只会使用其中一种的情况下,可以使用联合体不能同时使用的特点来设计!下面我用联合体来研究计算机的大小端字节序。
首先先来回顾大小端存储的概念:
小端存储:地址低端的数据放在低端,地址高端的数据放在高端的存储模式
大端存储:地址高端的数据放在低端,地址低端的数据放在低端的存储模式
曾经我们使用的是利用的是指针类型的意义来研究,今天我们来使用联合体来研究:
00000000 00000000 00000000 00000001----->1的32进制表示形式
00000001----->1的16进制表示形式
假设左边是低地址,右边是高地址,
小端存储:01 00 00 00
大端存储:00 00 00 01
我们可以看到,大小端不同的地方就是第一个字节,而联合体的成员的地址都是相同的,那么不妨我们定义一个联合体,该联合体有一个char类型和int类型的成员,我们往int类型的成员放置1,在访问char类型的成员,这样就可以获取第一个字节的内容来判断存储模式!
#include
//联合体的应用---->判断大小端字节序
int check_sys()
{
union A
{
char c;
int i;
};
union A a={0};
a.i = 1;
return a.c;
}
int main()
{
int ret = check_sys();
if (1 == ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
} 运行结果如下:

可以看到,程序依旧运行出了正确的结果,对于这段代码还可以进行一点点的小优化,因为这个结构体我们仅仅使用了一次,所以我们可以利用匿名联合体只能使用一次的特性来优化代码:
#include
int check_sys()
{ //联合体仅仅使用一次,那么就可以使用匿名联合体
union
{
char c;
int i;
}a;
a.i = 1;
return a.c;
}
int main()
{
int ret = check_sys();
if (1 == ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
} 这就是联合体在探究大小端字节序的应用。
以上就是自定义数据类型的一些知识的整理,希望对大家的学习有所帮助,祝大家新年快乐!
