SpringCloud Alibaba - 基于 FeignClient 整合 Sentinel,实现“线程隔离”和“熔断降级”
目录
一、FeignClient 整合 Sentinel
1.1、整合原因
1.2、实现步骤
1.2.1、修改 OrderService 中的 application.yml 文件
1.2.2、给 FeignClient 编写失败后的降级逻辑
二、线程隔离
2.1、线程隔离的两种方式
2.1.1、线程池隔离
2.1.2、信号量隔离(Sentinel 默认采用方式)
2.2、实现线程隔离(舱壁模式)
a)添加流控规则
b)使用 JMeter 进行测试
c)分析结果
三、熔断降级
3.1、什么是熔断降级
3.2、熔断策略——慢调用
a)在 Sentinel 上给远程调用添加降级规则
b)在浏览器中连续刷新,分析结果
3.3、熔断策略——异常比例、异常数
a)在 Sentinel 上给远程调用添加降级规则
b)在浏览器中连续刷新,分析结果
一、FeignClient 整合 Sentinel
1.1、整合原因
前面我们学习到的限流虽然可以避免因高并发引起的服务故障,但是服务还是可能会因为其他原因故障. 如果要将这些故障控制住,避免雪崩,就需要靠线程隔离和熔断降级的了.
但不管是线程隔离还是熔断降级,都是对 客户端(调用方)的保护,避免服务的调用者被故障的服务拖垮,因此我们要就需要在微服务发起远程调用的时候去做隔离和降级,也就是说通过 Feign 整合 Sentinel 去做 隔离和降级.
1.2、实现步骤
1.2.1、修改 OrderService 中的 application.yml 文件
在 application.yml 中开启 Feign 的 Sentinel 功能.
feign:
sentinel:
enabled: true # 开启Feign的Sentinel功能
1.2.2、给 FeignClient 编写失败后的降级逻辑
这里有一下两种方式实现降级逻辑.
- FallbackClass:无法对远程嗲用的异常做处理.
- FallbackFactory:可以对远程调用的异常做处理.
这里我们选择第二种方式,具体实现如下:
a)在 feign-api 项目中自定义类 UserClientFallbackFactory ,实现 FallbackFactory 接口
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public User findById(Long id) {
//记录异常信息
log.error("查询用户失败!");
//根据业务需求返回数据,这里返回一个空对象
return new User();
}
};
}
}
b)在 feign-api 项目的 配置类 中,将 UserClientFallbackFactory 注册为一个 Bean
@Bean
public UserClientFallbackFactory userClientFallbackFactory() {
return new UserClientFallbackFactory();
}
c)在 feign-api 项目中的 UserClient 接口(feign 远程调用接口)中使用 UserClientFallbackFactor.
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
二、线程隔离
2.1、线程隔离的两种方式
2.1.1、线程池隔离
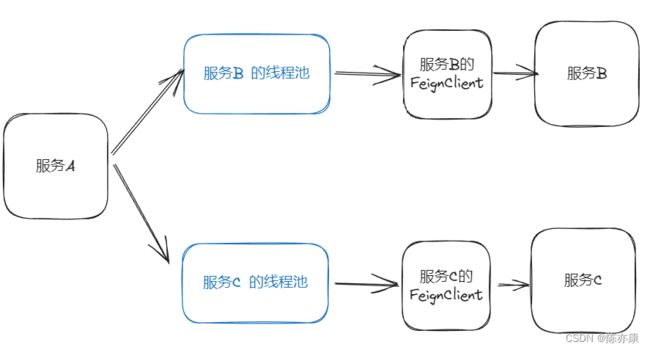
线程隔离就是给每个业务划分独立的线程池,实现隔离.
比如说,我现在有 a、b、c 三个服务,而 a 依赖 b 形成一个业务,a 依赖 c 形成一个业务,那么线程池隔离就会给每个业务所依赖的服务都创建一个线程池,也就说这里创建两个线程池,一个给b,一个给 c. 当有请求到达 a 的时候,不会去使用请求本身的这个线程,而是去这两个池子里分别去取线程,此时这个线程就可以去调用 feign 的客户端,发起远程调用.
这样就把两个服务给隔离开了.如果服务 b 出现了故障,那么最多也就是把他这边池子里的线程给用完,如果还有新的请求还想访问这个服务,但是池子满了,他还能进来了吗?这样一来就不会把服务 a 里面的资源给耗尽了.
优点
1. 支持主动超时:线程池模式会给每一个远程调用分配一个独立的线程,也就意味着可以通过线程池来控制他. 如果发现有一个请求耗时久了,就可以立即终止这个线程.
2. 支持异步调用:每次调用都是线程池分配的一个独立的线程,不是原来处理 tomcat 请求的线程,而不同的服务又是不同的线程池,因此可以在给某一个服务处理的请求的同时,再给其他服务处理远程调用.
缺点
1. 线程的额外开销比较大:每次调用都有独立的线程,线程越多,开销越大,别的不说,光是 cpu 上下文切换也是比较耗时的.
适用场景
1.适用于 “低扇出”:低扇出就是指,我这里有一个服务依赖于其他服务,依赖的服务越多,扇出越高. 每次远程调用都有独立的线程,因此为了避免多线程开销问题,更适用于低扇出场景.
2.1.2、信号量隔离(Sentinel 默认采用方式)
信号量就相当于之前所讲到过的 Semaphore.
比如说我有服务a 和 服务b,服务a 依赖于 服务b. 现在又请求到 a 了,那么信号量不会去创建独立的线程,而是去使用你原本处理请求的线程,直接去调用 Feign 客户端,那他是怎么做到隔离的呢?他维持了一个计数器,每次请求来了都做一个判断,判断计数器里还有没有.
比如计数器总量是 10,每进入一个请求,计数器都会减一,请求处理完了都会加一. 如果当有 10 个请求同时来访问的的时候,那么10 个信号都被取完了,此时如果再来新的请求,就会直接拒绝,因此也能起到故障隔离的作用.
优点
1. 轻量级,没有额外开销:实际上就是给线程池做了一个弥补,因为他只是一个计数器,不需要开启线程.
缺点
1. 不支持主动超时:请求来了以后,只是判断一下信号量有没有,如果就给你分配一个,但是信号量就不受控制了,没法中途停掉,只能依赖于 Feign 本身的超时时间,所有不能做主动超时.
2. 不支持异步调用:都没有独立的线程,更不用提异步调用了.
适用场景
1. 高频调用,高扇出:因为 信号量 开销低. 网关 就是一个高扇出的场景 ,他把请求路由到你的各个微服务当中,扇出相当的庞大,因此网关也基本上都是用的是 信号量模式(也是 sentinel 为什么适用信号量模式的原因).
2.2、实现线程隔离(舱壁模式)
在 Sentinel 控制台中,添加先流规则时,可以选择两种阈值类型:
- QPS:每秒请求数,之前演示过了.
- 线程数:该资源能使用的 tomcat 线程数的最大值. 通过限制线程数,实现舱壁模式.
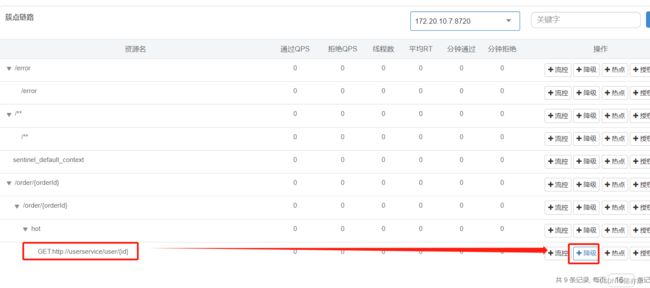
这里通过一个案例演示:给 UserClient 的查询用户接口设置流控规则,线程数不能超过 2.
由于前面已经配置 FeignClient 整合 Sentinel,访问查询订单资源,就可以在 Sentinel 中看到如下远程调用资源.

a)添加流控规则

b)使用 JMeter 进行测试


c)分析结果
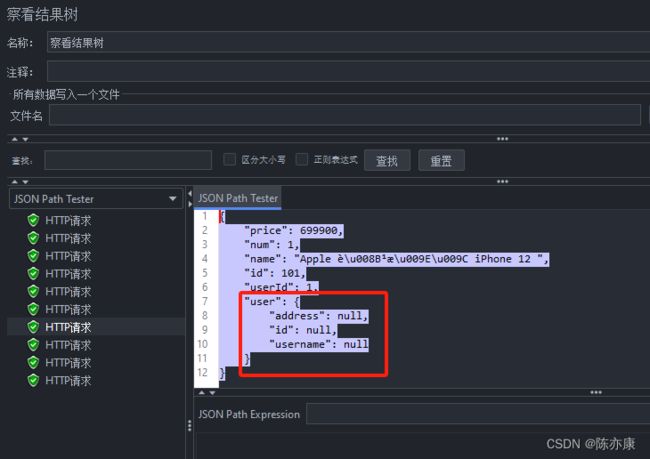
在结果树中可以看到所有请求成功了,这是因为我们基于 Feign 整合了 Sentinel 保护机制,而保护的策略就是“打印异常日志,返回空对象”.
可以看到前面几个请求时成功返回信息,而后面的请求都返回的是空对象,是因为触发了 Sentinel 的刚刚配置的流控机制.

也可以在 IDEA 上看到日志的打印
三、熔断降级
3.1、什么是熔断降级
熔断降级就是通过一个短路器取统计服务调用的时候 “异常比例、慢调用比例、异常数量”,比如说统计的是异常比例,那么如果异常比例过高,触发了阈值就会熔断该服务,这样就把故障的服务隔离开了.
这就像是古代的武侠人士,手被毒蛇咬了,赶紧手起刀落,把手砍断,防止毒扩散到全身,但是这把手砍了算不了什么本事啊,能接回来才是真本事.
而 Sentinel 就可以在服务恢复时,让熔断器放行访问该服务的请求.
具体的,熔断器有以下三种状态:

3.2、熔断策略——慢调用
慢调用就指看你的响应时间如果过长,超过了指定的时间,那么就认为你这个请求的很慢,占用额外资源,会拖慢整个服务.
因此,如果慢调用的比例达到阈值,也就是说每次服务调用你都很慢,那就会触发熔断.
在 Sentinel 的控制台中可有新增降级规则,这里就描述了,何时触发熔断,例如

解读:RT(ResponseTIme 响应时间)超过 500ms 就是慢调用,统计最近 10000ms 内的请求,如果慢调用的比例超过 0.5,就会触发熔断,熔断时常为 5s. 之后进入 half-open(半打开)状态,放行一次请求做测试.
这里我用一个案例来演示:给 UserClient 查询用户接口设置降级规则,RT为 50ms,统计时间 1s,最小请求数量为 5,失败阈值比例为 0.4,熔断时长为 5s.
注意:这里为了触发慢调用规则,我修改了 UserService 中的业务,增加业务耗时.

a)在 Sentinel 上给远程调用添加降级规则
在簇点链路中即可配置
规则如下

b)在浏览器中连续刷新,分析结果
快速刷新几次之后,就可以看到已经发生熔断,触发降级策略,也就是返回空用户信息.

随后,过 5 秒后,在发送一次请求,就会发现进入 half-open 模式,给你一次测试的机会.

3.3、熔断策略——异常比例、异常数
异常比例:就是统计在指定之间内,调用的次数到达指定的请求数,并且出现的异常超过设置的比例,那么就会触发熔断.
异常数(和异常比例差不多,这里就不演示了):顾名思义就是统计指定时间内,调用的次数到达指定请求数,并且超过异常数阈值,就会触发熔断.
例如:
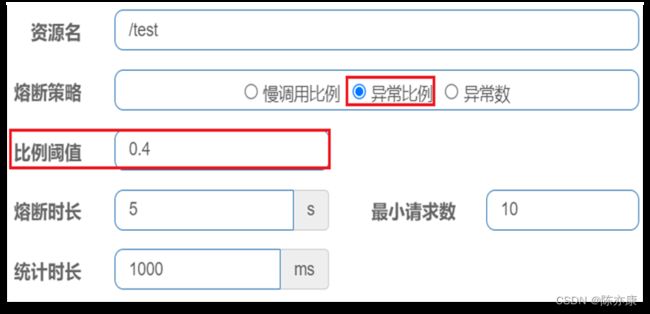
解读:统计最近 1000 ms 内请求,如果请求量超过 10 次,且异常比例不低于 0.5,则触发熔断,熔断的时间为 5s.
这里我用一个案例来演示 异常比例:给 UserClient的查询用户接口设置降级规则,统计时间为 1 秒,最小请求数量为 5 ,失败阈值比例为 0.4 ,熔断时长为 5 s
注意,为了触发异常统计,我修改了 UserService 中的业务,抛出异常.

a)在 Sentinel 上给远程调用添加降级规则

b)在浏览器中连续刷新,分析结果
连续刷新 5 次,就可以观察到,触发熔断.

5 秒后恢复,这里需要在换成 /order/101 的请求,这样远程调用的也是获取 id = 1 的用户,否则继续使用 /order/102 请求,远程调用 id = 2 的用户会继续引发异常,而当前还处于 half-open 状态,就有又回到 open 熔断状态了.

