《R语言数据挖掘》读书笔记:六、高级聚类算法
第六章、高级聚类算法
1. DBSCAN算法和电子商务客户分类分析
1.1DBSCAN算法
通过定义数据点空间的密度和密度度量,这些类可以建模成数据空间中具有某种密度的截面。
在有噪声的情况下基于密度的空间聚类应用算法(Density Based Spatial Clustering of Applications with Noise,DBSCAN)是最流行的基于密度的聚类算法之一。
DBSCAN算法的主要特征:擅长处理具有噪声的大型数据集、可以处理形状各异的类。
DBSCAN算法的基本思想: 算法的本质是一个发现类簇并不断扩展类簇的过程。
DBSCAN算法基于对数据集中数据点划分为核心数据点、边界数据点和噪声数据点,并支持使用点与点之间的密度关系,这些点包括直接密度可达(directly density-reachable)、密度可达(density-reachable)和密度相连(density-connected)的点。
算法详细解析: https://blog.csdn.net/huacha__/article/details/81094891
更易理解的图解: https://www.cnblogs.com/lyr2015/p/7439586.html
1.2 电子商务客户分类分析
电子商务的一般分析过程是:数据收集——>分析——>推荐——>行动——>数据收集 的循环过程。
2. OPTICS算法和网页聚类
2.1 OPTICS算法
OPTICS算法的难点在于维护核心点的直接可达点的有序列表。
OPTICS(Ordering points to identify the clustering structure)是一基于密度的聚类算法,OPTICS算法是DBSCAN的改进版本,因此OPTICS算法也是一种基于密度的聚类算法。在DBCSAN算法中需要输入两个参数:ϵ和MinPts,选择不同的参数会导致最终聚类的结果千差万别,因此DBCSAN对于输入参数过于敏感。OPTICS算法的提出就是为了帮助DBSCAN算法选择合适的参数,降低输入参数的敏感度。OPTICS主要针对输入参数ϵ ϵϵ过敏感做的改进,OPTICS和DBSCNA的输入参数一样(ϵ和MinPts),虽然OPTICS算法中也需要两个输入参数,但该算法对ϵ输入不敏感(一般将ϵ固定为无穷大),同时该算法中并不显式的生成数据聚类,只是对数据集合中的对象进行排序,得到一个有序的对象列表,通过该有序列表,可以得到一个决策图,通过决策图可以不同ϵ参数的数据集中检测簇集,即:先通过固定的MinPts和无穷大的ϵ得到有序列表,然后得到决策图,通过决策图可以知道当ϵ取特定值时(比如ϵ=3)数据的聚类情况。
算法详细解析: https://blog.csdn.net/SHNU_PFH/article/details/78769440
较易理解的算法图解: https://www.cnblogs.com/zhangruilin/p/5817784.html
2.2 网页聚类
网页聚类可以用来对相关的文本或者文章分组,作为监督学习的预处理步骤。它能自动分类。网页时通用且具有不同的结构和内容。
3. DENCLIUE算法和浏览器缓存中的访客分析
3.1 DENCLUE算法(density-based clustering)
基于密度的聚类方法,它依赖于密度分布函数的支持。
基础名词:影响函数、密度函数、梯度和密度吸引点
算法详解: https://blog.csdn.net/qq_40793975/article/details/82838253
3.2 浏览器缓存中的访客分析
4——6均是基于网格的聚类算法
4. 推荐系统和STING算法
4.1 STING算法
统计信息网格(Statistical Information Grid,STING)是一种基于网格的聚类算法。
STING算法的基本思想:首先将样本按层次(维度或属性)进行一定的划分,每个层次上我们根据维度或者概念分层不同的cell,实际上这里的每个层次对应的是样本的一个分辨率(这里我认为是某一属性的稀疏度)。根据预先设定的阈值进行分块(将上层的大cell切成小的cell),从而丢弃掉一些不符合密度阈值的数据,实现根据特定属性和阈值进行聚类的目的。因为算法的每一层都会抛弃掉一些不相关的样本,所需的计算量也会越来越少,那么速度就会很快。
STING算法的特征:独立于查询的结构、本质上是并行的、效率高。
STING算法详细解析【讲的真的很不错】(机器学习:基于网格的聚类算法,张蓓): https://cloud.tencent.com/developer/article/1005263
4.2 推荐系统
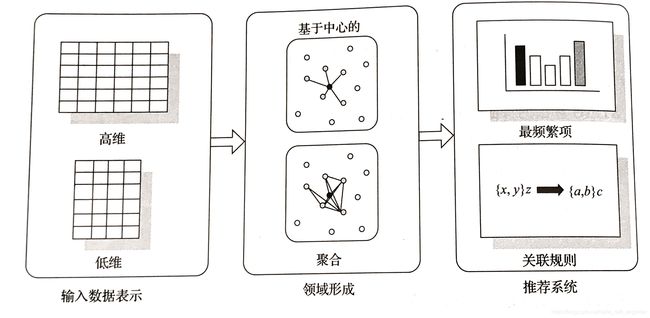
根据统计、数据挖掘和知识发现技术,推荐系统正在被大多数的电子商务网站使用,使消费者更容易找到需要购买的商品。三个主要的部分是:输入数据表示、邻域形成和推荐生成。
5. CLIQUE算法和网络情感分析
5.1 CLIQUE算法(Clustering in Quest)
CLIQUE算法是一个自上而下的基于网格的聚类算法。该算法的思想是Apriori特征,即密度单元相对于维度的单调性。如果一组数据点S是k维投影空间中的一个类,那么S包括在任意(k-1)维投影空间上的一个类中。该算法一层一层处理,一维密集单元通过便利一次数据而产生,使用候选生成程序和第(k-1)步得到的确定的(k-1)维密集单元来生成k维候选单元。
CLIQUE算法的特征:①对高维数据集有效 ②结果的可解释性 ③可拓展性和可用性
对一个数据集聚类CLIQUE算法包含3个步骤:①选择一组子空间(可以按照每个维度来划分)来对数据集聚类;②在每个子空间上独立执行聚类(按一定方法);③以析取范式表达式形式生成每个类的说明(将各维度的聚类结果结合起来)。
CLIQUE算法详细解析【讲的真的很不错】(机器学习:基于网格的聚类算法,张蓓): https://cloud.tencent.com/developer/article/1005263
5.2 网络情感分析
网络情感分析可以用来识别文字背后的理念或者思想,例如,Twitter上的微博情感分析。用于情感判断的一个简单例子就是比较发布的内容与预定义的词标记列表。另一个例子是可以通过竖起大拇指或者大拇指朝下来评价一个影评。网络情感分析还用于新闻报道的偏见分析,关于具体的观点和新闻组的评估等。
6. WAVE聚类算法和观点挖掘
6.1 WAVE聚类算法
WAVE聚类算法是一种基于网格的聚类算法,它依赖于空间数据集和多维信号间的关系。其思想是在多维空间数据集中的类在小波变换(也就是将小波应用于输入数据或者预处理后的数据集,具体的变换方法在下面链接中详细描述了)后会变得更易区分。在变换结果中,由稀疏区域划分的密集部分表示类。
WAVE聚类算法的特征如下:①对大型数据集有效②高效查找各种形状的类③对噪声或者异常不敏感④对于数据集的输入顺序不敏感⑥由小波变换引入的多分辨率 ⑦适用于任何数值数据集
WAVE聚类算法只需执行几个步骤:第一步,创建一个网格,并将来自输入数据集的每一个数据对象分配给网格中的一个单元;第二步,通过应用小波变换函数将数据变换到一个新的空间;第三步,寻找新空间中的连通分支,将与原数据空间相关的数据对象映射为类标签。(理解好下面网址中的小波变换到簇的空间映射的过程就好了)
WAVE算法详细解析【讲的真的很不错】(机器学习:基于网格的聚类算法,张蓓): https://cloud.tencent.com/developer/article/1005263
6.2 观点挖掘
观点挖掘是指挖掘关于研究中的对象或者实体的某种特征的观点。最简单的情形就是判断观点是积极的还是消极的。
7. EM算法和用户搜索意图
7.1 EM算法(Expectation Maximization,EM)【目前理解不到位,以后遇到可以再仔细学习一下】
最大期望算法是一种基于概率模型的聚类算法,它依赖于混合模型,在混合模型中,数据通过简单模型的混合进行建模。与这些模型有关的参数通过极大似然估计法(Maximum Likelihood Estimation,MLE)进行估计。
EM算法详解(比较简明易懂的好文章): https://blog.csdn.net/zouxy09/article/details/8537620
EM算法详解(EM算法推导过程,理论性很强): https://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
7.2 用户搜索意图
就搜索和查询而言,确定用户意图相对于稀疏数据的获得是一个重要却困难的问题。
用户意图有广泛的应用,聚类查询修正、用户意图概况以及网络搜索意图归纳。给定网络搜索引擎查询,寻找用户意图也是一个关键和需求。为了确定用户的兴趣和偏好,关于搜索结果的点击序列可以作为好的基础数据。网络搜索个性化是用户搜索意图的另一个重要应用,这与用户的语境和意图相关。随着用户意图的应用,将提供更多有效且高效的信息。
8. 高维数据聚类和客户购买数据分析
对于高维数据空间聚类,存在两个问题:效率和质量。需要新的算法来处理这种类型的数据集。有两种流行的策略应用于此,一种是子空间聚类策略,以便找到原始数据集空间的子空间中的类。另一种是降维策略,它创建一个较低维度的数据空间以便进一步聚类。
8.1 MAFIA算法
MAFIA算法是一种有效且可扩展的子空间聚类算法,可用于高维和大型数据集。
算法总结:

8.2 SURFING算法
surfing算法从数据集的原始属性中选择感兴趣的特征。
8.3 客户购买数据分析
客户购买数据分析包括了很多应用,如客户满意度分析。
根据客户购买数据分析,其中一个应用可以帮助发现不必要的消费或者用户的购买行为。
9. 网络数据聚类与SNS和图
9.1 SCAN算法
图和网络数据的聚类在现代生活中有着广泛的应用,比如社交网络。然而,更多的挑战伴随着需求意外的出现。高计算成本、复杂的图形和高维稀疏和策略主要的问题。运用一些特殊的变换,这些问题可以转化为图切割问题。
用于网络的结构聚类算法(Structural Clustering Algorithm for Network,SCAN)是其中一种算法,它通过搜索图中连接密切的分支作为类。
9.2 社交网络服务
社交网络已经成为当今最流行的在线交流方式。由于安全、业务和控制等的需求,社交网络服务(Social Networking Service,SNS)分析变得很重要。社交网络的服务的基础是图论,特别是对于社交网络服务挖掘,如寻找社交社团、为了不良目的滥用社交网络服务等。
社交网络服务聚类是寻找社区的一种内在的应用。随机游走是用于社交网络服务分析的另一个关键技术,并用于寻找社区。
下一章:将介绍与异常值检测及其算法有关的主要话题,并讨论一些实例。