浏览器输入 URL 并回车发生了什么
本文节选自我的博客:浏览器输入 URL 并回车发生了什么
- 作者简介:大家好,我是MilesChen,偏前端的全栈开发者。
- CSDN主页:爱吃糖的猫
- 我的博客:爱吃糖的猫
- Github主页: MilesChen
- 支持我:点赞+收藏⭐️+留言
- 介绍:The mixture of WEB+DeepLearning+Iot+anything
前言
这是前端面试中的高频问题,文章有点长,若你耐心读完一定有所收获。若你在面试中能简单描述出完整过程,一定会令面试官耳目一新。但其中涉及的细节也是相当多,读者还需要主动探索,不然还是禁不起大厂面试官的深挖。
- 大致流程:URL 解析>DNS 查询>TCP 连接>服务器处理请求>浏览器接收响应>渲染页面>四次断开
- 渲染页面的过程:构造文档对象模型(DomTree),构造CSS 对象模型(CSSOM),生成渲染树、排版、分层、绘制
URL解析
如果是非 URL 结构的字符串,则会用浏览器默认的搜索引擎搜索该字符串。(UTF-8)
![]()
URL 主要由 协议、主机、端口、路径、查询参数、锚点6部分组成!
输入URL后,浏览器会解析出协议、主机、端口、路径等信息,并构造一个HTTP请求。
- 浏览器发送请求前,根据请求头的
expires和cache-control判断是否命中(包括是否过期)强缓存策略,如果命中,直接从缓存获取资源,并不会发送请求。如果没有命中,则进入下一步。 - 没有命中强缓存规则,浏览器会发送请求,根据请求头的
If-Modified-Since和If-None-Match判断是否命中协商缓存,如果命中,直接从缓存获取资源。如果没有命中,则进入下一步。 - 如果前两步都没有命中,则直接从服务端获取资源。
HSTS:由于安全隐患,会使用 HSTS 强制客户端使用 HTTPS 访问页面。
DNS查询
通过 DNS 来查询 IP 地址,DNS 先查本地、后查运营商、逐级网上查。
查询的方式分为两种:
- 递归查询:
递归查询是一种DNS服务器的查询模式,在该模式下DNS服务器接收到客户机请求,必须使用一,
个准确的查询结果回复客户机。如果DNS服务器本地没有存储查询DNS信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。 - 迭代查询
DNS服务器另外一种查询方式为迭代查询,当客户机发送查询请求时,DNS服务器并不直接回复查询结果,而是告诉客户机另一台DNS服务器地址,客户机再向这台DNS服务器提交请求,依次循环直到返回查询的结果为止。
总结:一般情况下,从PC客户端到本地DNS服务器是属于递归查询。而DNS服务器之间就是的交互查询就是迭代查询。
访问经过迭代查询后,会在本地的DNS服务器缓存DNS映射,以便下次再次打开此网页(一般会缓存两天,防止服务器挂掉),本地DNS服务器就是路由器
TCP连接
三次握手四次挥手默认都了解,这里不再展开
服务器处理请求
通常是Apache和Nginx服务器去处理请求,HTTP请求一般可以分为两类,静态资源 和 动态资源。
第一次请求通常是静态资源,请求index.html文件,这时Nginx会直接拿这个文件资源响应回去。
动态资源会回委托给后端程序处理,通常会经过一层层中间件(过滤非法请求、异常请求、跨域请求、重定向请求),路由分发到具体的业务代码去处理,比如数据库操作,在处理过程中可能出现非法请求参数,做异常处理,最后将处理结果响应给前端。

浏览器接收响应
浏览器接收到来自服务器的响应资源后,会对资源进行分析。首先查看响应头( Response header),根据不同状态码做不同的事(比如上面提到的重定向)。如果响应资源进行了压缩(比如 gzip),还需要进行解压。然后,对响应资源做缓存。
渲染页面
浏览器拿到数据,如何渲染?浏览器是如何渲染UI的?

这张图相信你一定不陌生,但你真的理解这张图了吗?接着看下去,带你来一步步吃透彻这张图!
渲染页面的关键步骤就叫 关键渲染路径
关键渲染路径:构造文档对象模型(DomTree),构造CSS 对象模型(CSSOM),生成渲染树、排版、分层、绘制
构造文档对象模型(DomTree)
- 二进制解析:从网络读取HTML原始字节;根据文件指定编码UTF-8
- 词法分析,将字符串转换为一个个token如div、body
- 语法分析,将token转成为对象,这些对象定义了它们的属性和规则。
- 构造DomTree,根据HTML文档中的token关系构建树

构造CSS 对象模型(CSSOM)
CSS文件和HTML处理流程差不多,CSS 文件经过转化为字符,然后进行分词、转化为节点最终拼接为一个树状的 CSSOM。构造过程中还做了标准化计算值(例如,color单词形式转化为rgb,em单位转化为px)

将CSS构造成树形,便于下上寻找CSS继承样式
生成渲染树(也叫 布局树)
上面生成的两棵树都是互相独立的两个树状对象。这一步实现将两个树组成一个具有所有可见节点样式和内容的 Render Tree
渲染树的构建过程大概分为以下三个步骤: DomTree + CssomTree = RenderTree
- 从 DomTree 开始遍历,遍历每一个可见节点。
- 一些脚本标签、元标签等节点是不可见的,由于它们未反映在页面的呈现中所以会被被省略。
- 同时对于一些通过 CSS 隐藏的节点,也会从渲染树中省略。比如,上述 HTML 中的 span 节点在上面的例子中会在渲染树中丢失,因为它明确的设置了
“display: none”属性。
- 对于 DomTree 中的每个可见节点,在 CSSOM 中找到合适的匹配 CSSOM 规则并应用它们。
- 最终在
Render Tree上挂载这些带有内容以及样式的可见节点。
前三个步骤总结:

排版(layout)
布局计算:
计算出每个节点在对应设备(屏幕)上确切的位置和大小。布局过程的输出是一个“盒子模型”,它精确地捕获视口内每个元素的确切位置和大小:所有相对测量值px都转换为屏幕上的绝对像素 。
分层(layer)
处理层叠问题:包括普通图层 和 复合图层 的处理
分层:根据复杂的3d转换,页面滚动,还有z-idex属性都会形成单独图层,把图层按照正确顺序排列。生成分层树
图层
以B站举例,打开浏览器调试工具的图层,可以发现网页被切割为一块块图层。

图层上下文
什么是图层上下文?
- 让HTML元素在2D平面堆叠出3D的视觉效果,根据层叠规则将哪个元素置于视觉最近处,哪个次之,以此类推,堆叠而成的部分就是一个图层。且每个层叠上下文对象都是一个渲染图层。
如何形成层叠上下文?
- 文档根元素、position不为初始值且z-index不为0或auto、opacity属性值小于1、flex布局元素、transform不为none等等
层叠顺序?(层叠等级的比较只有在当前层叠上下文元素中才有意义)
- 同一层叠上下文的层叠顺序为:z-index>0 > z-index:auto/z-index:0 > inline/inline-block水平盒子 > float浮动盒子 > block块级水平盒子 > z-index<0 > background/border
普通图层(渲染图层)与复合图层
浏览器渲染的图层一般包含两大类:普通图层(渲染图层)以及复合图层
- 普通图层:是页面的普通的文档流,我们虽然可以使用绝对定位相对定位来脱离文档流,但是它仍属于默认复合层,都公用同一个绘画上下文对象
- 复合图层:它会单独分配系统资源,每个复合图层都有一个独立的图形上下文(当然也会脱离文档流,这样一来,不管复合图层中如何变化,都不会影响默认图层内的重绘重排),硬件加速就用在了这里
如何创建复合图层?
- 3D转换:translate3d,translateZ依此类推;
- video,canvas,iframe元件
- transform、opacity经由СSS过渡和动画;
- 该元素在复合层上面渲染会自动创建
- CSS具有 will-change 属性
- 等等
复合图层作用?
交给GPU处理速度更快、回流不影响其他层速度更快、GPU与CPU并行更加高效;
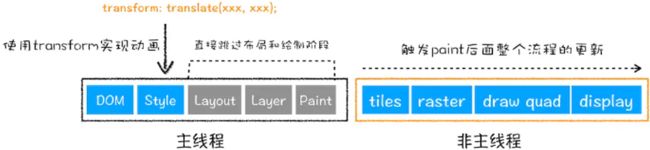
从上面的对比可以看出,我们使用了CSS的transform:translate来实现动画效果,这可以避开重排和重绘阶段,直接在非主线程上执行合成动画操作。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。其实这就是硬件加速
绘制(paint)

完成了图层的构建,接下来要做的工作就是图层的绘制了。图层的绘制跟我们日常的绘制一样,每次都会把一个复杂的图层拆分为很小的绘制指令,然后再按照这些指令的顺序组成一个绘制列表; Chrome 开发者工具中在设置栏中展开 more tools, 然后选择Layers面板,就能看到绘制列表;然后将这个绘制列表提交给 合成线程 :专门负责绘制操作

tiles(分块)
合成线程分块:一个页面可能很长,需要滚动显示,每次显示在视口中的只是页面的一小部分。对于这种情况,绘制出一整个长页,会产生太大的开销,而且也没必要。合成线程会将图层划分为图块。这样可以大大加速页面的首屏展示。
raster(光栅化)
栅格化线程地中将图快转化为位图,栅格化过程都会使用 GPU 来加速生成
draw quad
一旦所有图块都被生成位图,合成线程就会生成一个绘制图块位图的命令—— DrawQuad,然后将该命令提交给浏览器主进程。
display
浏览器主进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上。
内存到屏幕的过程:
无论是 PC 显示器还是手机屏幕,都有一个固定的刷新频率,一般是 60 HZ,即 60 帧,也就是一秒更新 60 张图片,一张图片停留的时间约为 16.7 ms。而每次更新的图片都来自显卡的前缓冲区。而显卡接收到浏览器进程传来的页面后,会合成相应的图像,并将图像保存到后缓冲区,然后系统自动将前缓冲区和后缓冲区对换位置,如此循环更新。
渲染页面中需要注意的几个问题
Css Parse 和 Dom Parse不是并行关系
注意:大多数人认为Css Parse 和 Dom Parse 是并行的关系,其实并不是
当 HTML Parse 遇到 link 标签的 stylesheet 时并不会等待 stylesheet 下载并解析完毕后才会解析后续 Dom。而是在网络进程加载 style 脚本的同时可以继续去解析后续 Dom。(严格来说是非阻塞关系,CSS解析不会阻塞HTML解析,而JS解析会阻塞)当网络进程加载完样式脚本后,主线程中仍然需要存在一个 parse styleSheet 的操作,这一步就是解析 link 脚本中的样式内容从而生成(添加)Cssom 上的节点。
parse styleSheet 的操作是在主线程中进行操作的。这也就意味着它会和 parse Html 抢占主线程资源(同一时间只能进行一个操作)。
JS parse 和 Css Parse 、 Dom Parse 的关系
在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM 树构建完成。并且构建 CSSOM 树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的 CSS 选择器,执行速度越慢。
当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM。
css加载是否会阻塞dom树渲染?
我们都知道:css是由单独的下载线程异步下载的。
结论:
- css加载不会阻塞DOM树解析(异步加载时DOM照常构建)
- 但会阻塞render树渲染(渲染时需等css加载完毕,因为render树需要css信息)
思考:这种阻塞render树本质是减少重绘与回流;不然就会出现CSS解析频繁触发重绘与回流
JS加载会阻塞dom树解析
js会阻塞DOM解析, 因为浏览器不知道js脚本会写些什么,如果有删除dom操作,那提前解析dom就是无用功。不过浏览器也会先“偷看”下html中是否有碰到如link、script和img等标签时,它会帮助我们先行下载里面的资源,不会傻等到解析到那里时才下载。
defer和async异步进行js的解析的区别