NoSQL之Redis配置搭建部署与优化
NoSQL之Redis配置搭建部署与优化
- Redis概念
-
- Redis 具有的优点
- 缓存概念
- 系统缓存
-
- buffer与cache:
- 缓存保存位置及分层结构
- DNS缓存
- 应用层缓存
- 数据层缓存
- 硬件缓存
- Redis-关系型数据库和 NoSQL 非关系型数据库
-
- redis 特性
- 单线程
- 关系数据库与非关系型数据库
-
- 关系型数据库和非关系型数据库区别
- 关系型数据库产生背景
- 非关系型数据库产生背景
- Redis为什么这么快?
- 为什么redis需要持久化?
- Redis数据库 安装部署搭建
-
- Redis 命令工具
-
- redis-cli 命令行工具
- redis-benchmark 测试工具
- Redis数据库常用命令
-
- 使用 [ set、get ] 创建和获取键值数据
- 使用 [ keys * ] 查看当前库中所有键的数据
- 使用 [ keys B* ] 查看当前库中以B开头的所有键的数据
- 使用 [ keys A? ] 查看当前库中以A开头后面包含任意一位字符的键
- 使用 [ keys B?? ] 查看当前库中以A开头后面包含任意两位字符的键
- 使用 [ keys A??? ] 查看当前库中以A开头后面包含任意三位字符的键
- 使用 [ exists ] 判断键是否存在,1表示存在,0表示不存在
- 使用 [ del ] 删除当前库中的指定key
- 使用 [ type ] 查看键值的数据类型
- 五大数据类型以及增、查、删除命令
- 使用 [ rename ] 重命名,无论库中的key是否存在都会进行重命名,所要修改的key会覆盖库中的key
- 使用 [ renamenx ] 重命名,进行重命名时会检测库中的key是否与其修改的key名称相同,如若相同则不进行重名(不覆盖)
- 使用 [ dbsize ] 查看key数量
- 设置、登录、查看与清空密码
- 多数据库切换
- 多数据库之间移动数据[ move ]
- 清除数据库内的数据 [ flushdb、flushall ]
- 什么是RDB操作?
-
- RDB的优点与缺点
- 如何恢复rdb文件?
- 什么是AOF操作?
-
- AOF的优点和缺点
- 主从复制
-
- 主从复制的作用
-
- 实验:Redis主从复制(一主双从)
- Redis 哨兵模式
-
- 哨兵的核心功能:
- 哨兵模式原理:
- 哨兵模式的作用:
- 故障转移机制:
- 主节点的选举:
- 实验:Redis哨兵模式(一主双从)
- Redis集群模式
-
- 集群的作用
- Redis集群的数据分片:
- 以3个节点组成的集群为例:
- Redis集群的主从复制模型
- 实验:Redis集群模式(三主三从,单台机器演示)
- 总结
Redis概念
Redis (Remote Dictionary Server)在2009年发布,开发者Salvatore Sanfilippo是意大利开发者,他本想为自己的公司开发一个用于替换MySQL的产品Redis,但是没有想到他把Redis开源后大受欢迎,短短几年,Redis就有了很大的用户群体,目前国内外使用的公司众多,比如:阿里,百度,新浪微博,知乎网,GitHub,Twitter 等。
Redis是一个开源的、遵循BSD协议的、基于内存的而且目前比较流行的键值数据库(key-value database),是一个非关系型数据库,redis 提供将内存通过网络远程共享的一种服务,提供类似功能的还有memcached,但相比memcached,redis还提供了易扩展、高性能、具备数据持久性等功能。
Redis(远程字典服务器) 是一个开源的、使用 C 语言编写的 NoSQL 数据库。
Redis 基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。即:在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程即可。
Redis 具有的优点
(1)具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
(2)支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Sorted Sets 等数据类型操作。
(3)支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性:Redis 所有操作都是原子性的。
(5)支持数据备份:即 master-salve 模式的数据备份。
缓存概念
缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存,甚至是物理服务器的raid 卡有也缓存,都是为了起到加速CPU 访问硬盘数据的目的,因为CPU的速度太快了,CPU需要的数据由于硬盘往往不能在短时间内满足CPU的需求,因此CPU缓存、内存、Raid 卡缓存以及硬盘缓存就在一定程度上满足了CPU的数据需求,即CPU 从缓存读取数据可以大幅提高CPU的工作效率。
系统缓存
buffer与cache:
buffer:缓冲也叫写缓冲,一般用于写操作,可以将数据先写入内存再写入磁盘,buffer 一般用于写缓冲,用于解决不同介质的速度不一致的缓冲,先将数据临时写入到里自己最近的地方,以提高写入速度,CPU会把数据先写到内存的磁盘缓冲区,然后就认为数据已经写入完成看,然后由内核在后续的时间在写入磁盘,所以服务器突然断电会丢失内存中的部分数据。
cache:缓存也叫读缓存,一般用于读操作,CPU读文件从内存读,如果内存没有就先从硬盘读到内存再读到CPU,将需要频繁读取的数据放在里自己最近的缓存区域,下次读取的时候即可快速读取。
缓存保存位置及分层结构
互联网应用领域,提到缓存为王
- 用户层: 浏览器DNS缓存,应用程序DNS缓存,操作系统DNS缓存客户端
- 代理层: CDN,反向代理缓存
- Web层: Web服务器缓存
- 应用层: 页面静态化
- 数据层: 分布式缓存,数据库
- 系统层: 操作系统cache
- 物理层: 磁盘cache, Raid Cache
DNS缓存
浏览器的DNS缓存默认为60秒,即60秒之内在访问同一个域名就不在进行DNS解析
应用层缓存
Nginx、PHP等web服务可以设置应用缓存以加速响应用户请求,另外有些解释性语言,比如:
PHP/Python/Java不能直接运行,需要先编译成字节码,但字节码需要解释器解释为机器码之后才能执
行,因此字节码也是一种缓存,有时候还会出现程序代码上线后字节码没有更新的现象。所以一般上线
新版前,需要先将应用缓存清理,再上线新版。
另外可以利用动态页面静态化技术,加速访问,比如:将访问数据库的数据的动态页面,提前用程序生成静态
页面文件html 电商网站的商品介绍,评论信息非实时数据等皆可利用此技术实现。
数据层缓存
- 分布式缓存服务
Redis
Memcached
- 数据库
MySQL 查询缓存
innodb缓存、MYISAM缓存
硬件缓存
- CPU缓存(L1的数据缓存和L1的指令缓存)、二级缓存、三级缓存
- 磁盘缓存:Disk Cache
- 磁盘阵列缓存: Raid Cache,可使用电池防止断电丢失数据
Redis-关系型数据库和 NoSQL 非关系型数据库
数据库主要分为两大类:关系型数据库与 NoSQL 数据库。
关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库
中的数据。主流的 MySQL、Oracle、MS SQL Server 和 DB2 都属于这类传统数据库。
NoSQL 数据库,全称为 Not Only SQL,意思就是适用关系型数据库的时候就使用关系型数据库,不适
用的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储。主要分为临时性键
值存储(memcached、Redis)、永久性键值存储(ROMA、Redis)、面向文档的数据库(MongoDB、CouchDB)、面向列的数据库(Cassandra、HBase),每种 NoSQL 都有其特有的使用场景及优点。
Oracle,mysql 等传统的关系数据库非常成熟并且已大规模商用,为什么还要用 NoSQL 数据库呢?
主要是由于随着互联网发展,数据量越来越大,对性能要求越来越高,传统数据库存在着先天性的缺
陷,即单机(单库)性能瓶颈,并且扩展困难。这样既有单机单库瓶颈,却又扩展困难,自然无法满足
日益增长的海量数据存储及其性能要求,所以才会出现了各种不同的 NoSQL 产品,NoSQL 根本性的优
势在于在云计算时代,简单、易于大规模分布式扩展,并且读写性能非常高。
(一)、关系型数据库
关系型数据库是一个结构化的数据库,创建在关系模型 (二维表格模型) 基础上,一般面向于记录。
SQL语句 (标准数据查询语言) 就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括Oracle、MySQL、SQL Server、Microsoft Access、DB2等。
(二)、非关系型数据库
NoSQL (NoSQL=NotOnlySQL),意思是“不仅仅是SQL”,是非关系型数据库的总称。
除了主流的关系型数据库外的数据库,都认为是非关系型。
主流的 NoSQL 数据库有Redis、 MongBD、 Hbase、 Memcached 等。
(三)、关系型数据库和非关系型数据库区别
(1)、数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
① 关系型:依赖于关系模型E-R图,同时以表格式的方式存储数据
② 非关系型:除了以表格形式存储之外,通常会以大块的形式组合在一起进行存储数据
(2)、扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来克服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器 (节点) 来分担负载。
① 关系:纵向(天然表格式)
② 非关:横向(天然分布式)
(3)、对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
① 关系型:特别适合高事务性要求和需要控制执行计划的任务
② 非关系:此处会稍显弱势,其价值点在于高扩展性和大数据量处理方面
(四)、非关系型数据库产生背景
可用于应对Web2.0纯动态网站类型的三高问题。
(1) High performance-------对数据库高并发读写需求
(2) HugeStorage--------------对海量数据高效存储与访问需求
(3) High Scalability && High Availability------- 对数据库高可扩展性与高可用性需求
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给Web2.0的数据库发展带来新的思路。让关系数据库关注在关系上,非关系型数据库关注在存储上。例如,在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
Mysql 高热数据——》redis
web ——》redis ——》mysql
CPU——》内存/缓存 ——》磁盘
总结:
关系型数据库:
实例–>数据库–>表(table)–>记录行(row)、数据字段(column)——》存储数据
非关系型数据库:
实例–>数据库–>集合(collection) -->键值对(key-value)
workdir=/usr/local/mysql
redis 特性
- 速度快: 10W QPS,基于内存,C语言实现
- 单线程
- 持久化
- 支持多种数据结构
- 支持多种编程语言
- 功能丰富: 支持Lua脚本,发布订阅,事务,pipeline等功能
- 简单: 代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用简单
- 主从复制
- 支持高可用和分布式
单线程
Redis 6.0版本前一直是单线程方式处理用户的请求
单线程为何如此快?
- 纯内存
- 非阻塞
- 避免线程切换和竞态消耗
关系数据库与非关系型数据库
●关系型数据库:
关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。
SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2、PostgreSQL 等。
以上数据库在使用的时候必须先建库建表设计表结构,然后存储数据的时候按表结构去存,如果数据与表结构不匹配就会存储失败。
●非关系型数据库
NoSQL(NoSQL = Not Only SQL ),意思是“不仅仅是 SQL”,是非关系型数据库的总称。
除了主流的关系型数据库外的数据库,都认为是非关系型。
不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
主流的 NoSQL 数据库有 Redis、MongBD、Hbase、Memcached 等。
关系型数据库和非关系型数据库区别
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
(2)扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多克服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限个表,这都需要通过提高计算机性能来。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
关系:纵向 比如说硬件中添加内存
非关:横向 天然分布式
3、对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
关系型数据库产生背景
关系型数据库的产生背景可以追溯到20世纪60年代,当时IBM研究员Edgar F. Codd提出了关系模型的概念,将数据组织为表格形式,并通过关系代数来进行操作和查询。这一模型的出现解决了传统文件系统管理数据的不足,如数据冗余、数据不一致等问题,成为了现代数据库系统的基础。随着计算机技术的发展和商业应用的需求,关系型数据库得到了广泛的应用和发展。
非关系型数据库产生背景
非关系型数据库产生的背景主要是因为传统的关系型数据库在应对大规模数据、高并发访问和分布式部署等方面存在一些瓶颈和限制。随着互联网和移动互联网的快速发展,数据量呈现爆炸式增长,传统的关系型数据库已经无法满足这些需求。因此,非关系型数据库应运而生,通过采用不同的数据模型和存储方式,以及更灵活的数据结构和查询方式,来解决传统数据库所遇到的问题。非关系型数据库的出现和发展,使得数据处理和管理变得更加高效和可扩展,成为了大数据时代中不可或缺的一部分。
Redis为什么这么快?
1、Redis是一款纯内存结构,避免了磁盘I/o等耗时操作。
2、Redis命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。
3、采用了 I/O 多路复用机制,大大提升了并发效率。
注:在 Redis 6.0 中新增加的多线程也只是针对处理网络请求过程采用了多线性,而数据的读写命令,仍然是单线程处理的。
为什么redis需要持久化?
Redis是内存数据库,如果不将内存数据库保存到磁盘,那么服务器进程退出,服务器中的数据状态也会消失,所以Redis提供了持久化功能!
Redis数据库 安装部署搭建
[root@localhost ~]# systemctl stop firewalld.service && setenforce 0
## 关闭防火墙
[root@localhost ~]# systemctl status firewalld.service
## 查看防火墙状态是否关闭中
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since 三 2023-03-29 14:55:22 CST; 2s ago
Docs: man:firewalld(1)
Process: 4642 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 4642 (code=exited, status=0/SUCCESS)
3月 29 14:55:06 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...).
3月 29 14:55:06 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...e.
3月 29 14:55:06 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...e.
3月 29 14:55:06 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...).
3月 29 14:55:06 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...).
3月 29 14:55:07 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...).
3月 29 14:55:07 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...).
3月 29 14:55:07 localhost.localdomain firewalld[4642]: WARNING: COMMAND_FAILED: '/usr/sbin/i...).
3月 29 14:55:22 localhost.localdomain systemd[1]: Stopping firewalld - dynamic firewall daemon...
3月 29 14:55:22 localhost.localdomain systemd[1]: Stopped firewalld - dynamic firewall daemon.
Hint: Some lines were ellipsized, use -l to show in full.
[root@localhost ~]# cat /etc/sysconfig/selinux
## 查看SELINUX的模式情况
SELINUX=enforcing 是指在 Linux 操作系统中启用了 SELinux 安全模块,并将其设置为强制执行模式。
SELINUX=disabled 表示在 Linux 操作系统中,SELinux 安全模块被禁用了。
需要把SELINUX=enforcing 改成 SELINUX=disabled
=========================================================================================================
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=enforcing
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@localhost ~]# sudo vi /etc/selinux/config
## 进入配置文件改SELINUX=enforcing 修改成 SELINUX=disabled
=========================================================================================================
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted

[root@localhost ~]# cat /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@localhost ~]# yum install -y gcc gcc-c++ make
##安装 gcc gcc-c++ make 是为了编译和构建其他软件需要的工具链和依赖项
[root@localhost ~]# ls
anaconda-ks.cfg redis-5.0.7.tar.gz 模板 图片 下载 桌面
initial-setup-ks.cfg 公共 视频 文档 音乐
[root@localhost ~]# mv redis-5.0.7.tar.gz /opt/
[root@localhost ~]# cd /opt/
[root@localhost opt]# ls
redis-5.0.7.tar.gz rh
[root@localhost opt]# tar zxvf redis-5.0.7.tar.gz
[root@localhost opt]# ls
redis-5.0.7 redis-5.0.7.tar.gz rh
[root@localhost opt]# cd redis-5.0.7/
[root@localhost redis-5.0.7]# ls
00-RELEASENOTES COPYING Makefile redis.conf runtest-moduleapi src
BUGS deps MANIFESTO runtest runtest-sentinel tests
CONTRIBUTING INSTALL README.md runtest-cluster sentinel.conf utils
[root@localhost redis-5.0.7]# make
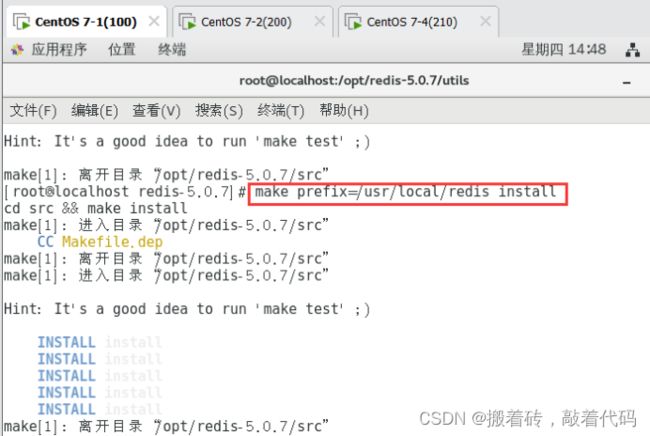
[root@localhost redis-5.0.7]# make prefix=/usr/local/redis install
#### 由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
cd src && make install
make[1]: 进入目录“/opt/redis-5.0.7/src”
CC Makefile.dep
make[1]: 离开目录“/opt/redis-5.0.7/src”
make[1]: 进入目录“/opt/redis-5.0.7/src”
Hint: It's a good idea to run 'make test' ;)
INSTALL install
INSTALL install
INSTALL install
INSTALL install
INSTALL install
make[1]: 离开目录“/opt/redis-5.0.7/src”
[root@localhost redis-5.0.7]# ls
00-RELEASENOTES COPYING Makefile redis.conf runtest-moduleapi src
BUGS deps MANIFESTO runtest runtest-sentinel tests
CONTRIBUTING INSTALL README.md runtest-cluster sentinel.conf utils
[root@localhost redis-5.0.7]# cd utils/
[root@localhost utils]# ls
build-static-symbols.tcl graphs redis-copy.rb speed-regression.tcl
cluster_fail_time.tcl hashtable redis_init_script whatisdoing.sh
corrupt_rdb.c hyperloglog redis_init_script.tpl
create-cluster install_server.sh redis-sha1.rb
generate-command-help.rb lru releasetools
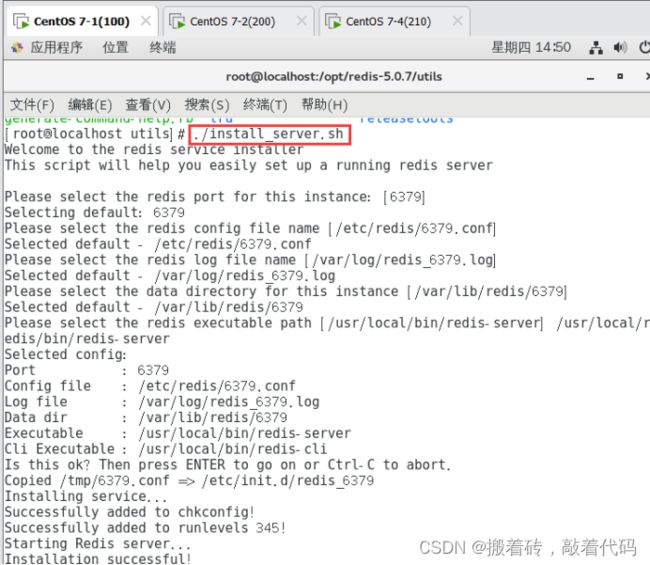
[root@localhost utils]# ./install_server.sh
## 执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379]
########## 回车 ##########
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf]
########## 回车 ##########
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log]
########## 回车 ##########
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379]
########## 回车 ##########
Selected default - /var/lib/redis/6379
Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server
### 需要手动修改为/usr/local/redis/bin/redis-server ,要注意要一次性正确输入
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!

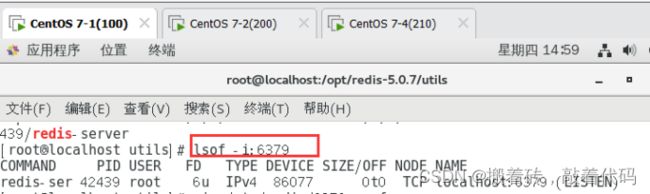
[root@localhost utils]# netstat -antp|grep redis
## 当 install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认监听端口为 6379
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 42439/redis-server
[root@localhost utils]# lsof -i:6379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 42439 root 6u IPv4 86077 0t0 TCP localhost:6379 (LISTEN)
[root@localhost utils]# vim /etc/redis/6379.conf
## 在后面添加本机ip地址
70行 bind 127.0.0.1 20.0.0.100




[root@localhost utils]# /etc/init.d/redis_6379 restart
###重启
Stopping ...
Redis stopped
Starting Redis server...
[root@localhost utils]# redis-cli
### 进入redis成功
127.0.0.1:6379> PING
PONG
127.0.0.1:6379> exit
| Redis 服务控制 | 含义 |
|---|---|
| /etc/init.d/redis_6379 stop | 停止 |
| /etc/init.d/redis_6379 start | 启动 |
| /etc/init.d/redis_6379 restart | 重启 |
| /etc/init.d/redis_6379 status | 状态 |
Redis 命令工具
| Redis命令工具 | 含义 |
|---|---|
| redis-server | 用于启动 Redis 的工具 |
| redis-benchmark | 用于检测 Redis 在本机的运行效率 |
| redis-check-aof | 修复 AOF 持久化文件 |
| redis-check-rdb | 修复 RDB 持久化文件 |
| redis-cli | Redis 命令行工具 |
redis-cli 命令行工具
基本语法:
redis-cli -h host -p port -a password
redis-cli -h 20.0.0.100 -p 6379
| 缩写 | 含义 |
|---|---|
| -h | 指定远程主机 |
| -p | 指定 Redis 服务的端口号 |
| -a | 指定密码,未设置数据库密码可以省略-a 选项 |
若不添加任何选项表示,则使用 127.0.0.1:6379 连接本机上的 Redis 数据库
[root@localhost utils]# redis-cli -h 20.0.0.100 -p 6379
20.0.0.100:6379> exit
redis-benchmark 测试工具
redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
基本的测试语法:
redis-benchmark [选项] [选项值]
| 缩写 | 含义 |
|---|---|
| -h | 指定服务器主机名 |
| -p | 指定服务器端口 |
| -s | 指定服务器 socket |
| -c | 指定并发连接数 |
| -n | 指定请求数 |
| -d | -d |
| -k | -k |
| -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 |
| -P | 通过管道传输请求 |
| -q | 强制退出 redis,仅显示 query/sec 值 |
| –csv | 以 CSV 格式输出 |
| -l | 生成循环,永久执行测试 |
| -t | 仅运行以逗号分隔的测试命令列表 |
| -I | Idle 模式,仅打开 N 个 idle 连接并等待 |
实验:向 IP 地址为 20.0.0.100、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
[root@localhost utils]# redis-benchmark -h 20.0.0.100 -p 6379 -c 100 -n 100000
====== PING_INLINE ======
100000 requests completed in 0.81 seconds
100 parallel clients
3 bytes payload
keep alive: 1
94.42% <= 1 milliseconds
99.50% <= 2 milliseconds
99.91% <= 3 milliseconds
100.00% <= 3 milliseconds
123456.79 requests per second
====== PING_BULK ======
100000 requests completed in 0.83 seconds
100 parallel clients
3 bytes payload
keep alive: 1
95.09% <= 1 milliseconds
99.48% <= 2 milliseconds
99.84% <= 3 milliseconds
99.90% <= 5 milliseconds
99.92% <= 6 milliseconds
100.00% <= 7 milliseconds
120192.30 requests per second
====== SET ======
100000 requests completed in 0.76 seconds
100 parallel clients
3 bytes payload
keep alive: 1
94.63% <= 1 milliseconds
99.07% <= 2 milliseconds
99.73% <= 3 milliseconds
99.90% <= 4 milliseconds
99.94% <= 5 milliseconds
100.00% <= 5 milliseconds
131233.59 requests per second
====== GET ======
100000 requests completed in 0.81 seconds
100 parallel clients
3 bytes payload
keep alive: 1
94.07% <= 1 milliseconds
99.20% <= 2 milliseconds
99.59% <= 3 milliseconds
99.74% <= 4 milliseconds
99.87% <= 5 milliseconds
99.98% <= 6 milliseconds
100.00% <= 6 milliseconds
124069.48 requests per second
====== INCR ======
100000 requests completed in 0.77 seconds
100 parallel clients
3 bytes payload
keep alive: 1
95.54% <= 1 milliseconds
99.36% <= 2 milliseconds
99.76% <= 3 milliseconds
99.90% <= 8 milliseconds
100.00% <= 8 milliseconds
130039.02 requests per second
====== LPUSH ======
100000 requests completed in 0.79 seconds
100 parallel clients
3 bytes payload
keep alive: 1
95.32% <= 1 milliseconds
99.46% <= 2 milliseconds
99.74% <= 3 milliseconds
99.78% <= 4 milliseconds
99.89% <= 5 milliseconds
99.90% <= 6 milliseconds
99.94% <= 7 milliseconds
99.97% <= 8 milliseconds
100.00% <= 8 milliseconds
127388.53 requests per second
====== RPUSH ======
100000 requests completed in 0.77 seconds
100 parallel clients
3 bytes payload
keep alive: 1
94.91% <= 1 milliseconds
99.55% <= 2 milliseconds
99.84% <= 3 milliseconds
99.85% <= 5 milliseconds
99.86% <= 6 milliseconds
99.90% <= 7 milliseconds
99.99% <= 8 milliseconds
100.00% <= 8 milliseconds
129198.97 requests per second
====== LPOP ======
100000 requests completed in 0.81 seconds
100 parallel clients
3 bytes payload
keep alive: 1
94.68% <= 1 milliseconds
99.34% <= 2 milliseconds
99.72% <= 3 milliseconds
99.80% <= 4 milliseconds
99.88% <= 5 milliseconds
99.90% <= 6 milliseconds
99.97% <= 7 milliseconds
100.00% <= 7 milliseconds
122850.12 requests per second
====== RPOP ======
100000 requests completed in 0.77 seconds
100 parallel clients
3 bytes payload
keep alive: 1
95.20% <= 1 milliseconds
99.28% <= 2 milliseconds
99.67% <= 3 milliseconds
99.79% <= 4 milliseconds
99.85% <= 5 milliseconds
99.97% <= 6 milliseconds
100.00% <= 6 milliseconds
130378.09 requests per second
====== SADD ======
100000 requests completed in 0.79 seconds
100 parallel clients
3 bytes payload
keep alive: 1
94.83% <= 1 milliseconds
99.42% <= 2 milliseconds
99.93% <= 3 milliseconds
100.00% <= 4 milliseconds
100.00% <= 4 milliseconds
126903.55 requests per second
====== HSET ======
100000 requests completed in 0.78 seconds
100 parallel clients
3 bytes payload
keep alive: 1
95.40% <= 1 milliseconds
99.54% <= 2 milliseconds
99.88% <= 3 milliseconds
99.90% <= 6 milliseconds
99.98% <= 7 milliseconds
100.00% <= 7 milliseconds
128865.98 requests per second
====== SPOP ======
100000 requests completed in 0.77 seconds
100 parallel clients
3 bytes payload
keep alive: 1
96.24% <= 1 milliseconds
99.67% <= 2 milliseconds
99.89% <= 3 milliseconds
99.96% <= 4 milliseconds
100.00% <= 4 milliseconds
129533.68 requests per second
====== LPUSH (needed to benchmark LRANGE) ======
100000 requests completed in 0.77 seconds
100 parallel clients
3 bytes payload
keep alive: 1
95.84% <= 1 milliseconds
99.32% <= 2 milliseconds
99.79% <= 3 milliseconds
99.80% <= 4 milliseconds
99.90% <= 5 milliseconds
99.90% <= 6 milliseconds
100.00% <= 6 milliseconds
130378.09 requests per second
====== LRANGE_100 (first 100 elements) ======
100000 requests completed in 2.02 seconds
100 parallel clients
3 bytes payload
keep alive: 1
55.40% <= 1 milliseconds
91.84% <= 2 milliseconds
97.58% <= 3 milliseconds
99.11% <= 4 milliseconds
99.49% <= 5 milliseconds
99.63% <= 6 milliseconds
99.81% <= 7 milliseconds
99.93% <= 8 milliseconds
99.99% <= 9 milliseconds
100.00% <= 9 milliseconds
49578.58 requests per second
====== LRANGE_300 (first 300 elements) ======
100000 requests completed in 4.82 seconds
100 parallel clients
3 bytes payload
keep alive: 1
0.10% <= 1 milliseconds
14.17% <= 2 milliseconds
75.11% <= 3 milliseconds
85.59% <= 4 milliseconds
90.93% <= 5 milliseconds
94.90% <= 6 milliseconds
97.24% <= 7 milliseconds
98.68% <= 8 milliseconds
99.31% <= 9 milliseconds
99.64% <= 10 milliseconds
99.85% <= 11 milliseconds
99.95% <= 12 milliseconds
99.99% <= 13 milliseconds
100.00% <= 13 milliseconds
20759.81 requests per second
====== LRANGE_500 (first 450 elements) ======
100000 requests completed in 6.52 seconds
100 parallel clients
3 bytes payload
keep alive: 1
0.05% <= 1 milliseconds
3.78% <= 2 milliseconds
27.03% <= 3 milliseconds
69.00% <= 4 milliseconds
80.81% <= 5 milliseconds
86.67% <= 6 milliseconds
91.24% <= 7 milliseconds
94.92% <= 8 milliseconds
97.03% <= 9 milliseconds
98.15% <= 10 milliseconds
98.97% <= 11 milliseconds
99.37% <= 12 milliseconds
99.63% <= 13 milliseconds
99.84% <= 14 milliseconds
99.94% <= 15 milliseconds
99.98% <= 16 milliseconds
100.00% <= 17 milliseconds
100.00% <= 17 milliseconds
15330.37 requests per second
====== LRANGE_600 (first 600 elements) ======
100000 requests completed in 8.42 seconds
100 parallel clients
3 bytes payload
keep alive: 1
0.05% <= 1 milliseconds
0.96% <= 2 milliseconds
8.44% <= 3 milliseconds
33.91% <= 4 milliseconds
64.65% <= 5 milliseconds
75.53% <= 6 milliseconds
82.08% <= 7 milliseconds
86.71% <= 8 milliseconds
90.73% <= 9 milliseconds
94.05% <= 10 milliseconds
96.16% <= 11 milliseconds
97.41% <= 12 milliseconds
98.19% <= 13 milliseconds
98.77% <= 14 milliseconds
99.13% <= 15 milliseconds
99.40% <= 16 milliseconds
99.60% <= 17 milliseconds
99.78% <= 18 milliseconds
99.87% <= 19 milliseconds
99.91% <= 20 milliseconds
99.95% <= 21 milliseconds
99.98% <= 22 milliseconds
99.99% <= 23 milliseconds
100.00% <= 23 milliseconds
11882.13 requests per second
====== MSET (10 keys) ======
100000 requests completed in 1.07 seconds
##### 1.07秒内完成100000请求 #####
100 parallel clients
##### 100个字节 #####
3 bytes payload
##### 3个字节有效负载 #####
keep alive: 1
##### 保持正常状态 #####
70.80% <= 1 milliseconds
98.29% <= 2 milliseconds
99.44% <= 3 milliseconds
99.69% <= 4 milliseconds
99.85% <= 5 milliseconds
99.90% <= 8 milliseconds
99.99% <= 9 milliseconds
100.00% <= 9 milliseconds
93896.71 requests per second
##### 每秒内有93896.71个请求 #####
实验:测试存取大小为 100 字节的数据包的性能
[root@localhost utils]# redis-benchmark -h 20.0.0.100 -p 6379 -q -d 100
PING_INLINE: 122699.39 requests per second
PING_BULK: 112233.45 requests per second
SET: 116822.43 requests per second
GET: 120481.93 requests per second
INCR: 128040.97 requests per second
LPUSH: 120772.95 requests per second
RPUSH: 126262.62 requests per second
LPOP: 127551.02 requests per second
RPOP: 116279.07 requests per second
SADD: 131406.05 requests per second
HSET: 124843.95 requests per second
SPOP: 119474.31 requests per second
LPUSH (needed to benchmark LRANGE): 109649.12 requests per second
LRANGE_100 (first 100 elements): 37707.39 requests per second
LRANGE_300 (first 300 elements): 13927.58 requests per second
LRANGE_500 (first 450 elements): 9225.94 requests per second
LRANGE_600 (first 600 elements): 6857.30 requests per second
MSET (10 keys): 84530.86 requests per second
#### 每秒 84530.86个请求 ####
实验:测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能
[root@localhost utils]# redis-benchmark -t set,lpush -n 100000 -q
SET: 132802.12 requests per second
LPUSH: 128369.71 requests per second
Redis数据库常用命令
| 命令 | 含义 |
|---|---|
| set | 存放数据,命令格式为set key(键) value(值) |
| get | 获取数据,命令格式为get key (键) |
| KEYS * | 查看当前数据库中所有键 |
| KEYS v* | 查看当前数据库中以v开头的数据 |
| KEYS v? | 查看当前数据库中以v开头后面包含任意一位的数据 |
| KEYS v?? | 查看当前数据库中以v开头 后面包含任意两位的数据 |
| exists | 判断键值是否存在 |
| del | 删除 |
| config set requirepass [密码] | 创建密码 |
| auth [密码] | 密码登录 |
| move | 移动 |
| flushdb | 清空当前库的数据 |
| flushall | 清空所有数据 |
使用 [ set、get ] 创建和获取键值数据
[root@localhost utils]# redis-cli
127.0.0.1:6379> set teacher zhangsan
OK
127.0.0.1:6379> get teacher
"zhangsan"
使用 [ keys * ] 查看当前库中所有键的数据
127.0.0.1:6379> set A1 1
OK
127.0.0.1:6379> set A2 2
OK
127.0.0.1:6379> set A3 3
OK
127.0.0.1:6379> set B1 1
OK
127.0.0.1:6379> set B2 2
OK
127.0.0.1:6379> set B3 3
OK
127.0.0.1:6379> set B323 3
OK
127.0.0.1:6379> set A222 3
OK
127.0.0.1:6379> set A452 3
OK
127.0.0.1:6379> set B99 2
OK
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "key:__rand_int__"
4) "B99"
5) "A222"
6) "counter:__rand_int__"
7) "teacher"
8) "A3"
9) "B323"
10) "B2"
11) "A1"
12) "B3"
13) "myset:__rand_int__"
14) "A452"
15) "mylist"
使用 [ keys B* ] 查看当前库中以B开头的所有键的数据
127.0.0.1:6379> keys B*
1) "B1"
2) "B323"
3) "B2"
4) "B3"
使用 [ keys A? ] 查看当前库中以A开头后面包含任意一位字符的键
127.0.0.1:6379> keys A?
1) "A2"
2) "A3"
3) "A1"
使用 [ keys B?? ] 查看当前库中以A开头后面包含任意两位字符的键
127.0.0.1:6379> keys B??
1) "B99"
使用 [ keys A??? ] 查看当前库中以A开头后面包含任意三位字符的键
127.0.0.1:6379> keys A???
1) "A222"
2) "A452"
使用 [ exists ] 判断键是否存在,1表示存在,0表示不存在
127.0.0.1:6379> exists teacher
(integer) 1
127.0.0.1:6379> exists teache
(integer) 0
127.0.0.1:6379> exists A1
(integer) 1
127.0.0.1:6379> exists A
(integer) 0
使用 [ del ] 删除当前库中的指定key
127.0.0.1:6379> del A1
(integer) 1
使用 [ type ] 查看键值的数据类型
127.0.0.1:6379> type teacher
string
127.0.0.1:6379> type A1
none
127.0.0.1:6379> type B1
string
五大数据类型以及增、查、删除命令
| 五大数据类型 | 增 | 查 | 删除 |
|---|---|---|---|
| String | set | get | del |
| List | lpush | lrange | del |
| Hash | hset | hget | hdel |
| Set | sadd | smembers | del |
| Sorted Set | zadd | zrank | del |
使用 [ rename ] 重命名,无论库中的key是否存在都会进行重命名,所要修改的key会覆盖库中的key
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "key:__rand_int__"
4) "B99"
5) "A222"
6) "counter:__rand_int__"
7) "teacher"
8) "A3"
9) "B323"
10) "B2"
11) "B3"
12) "myset:__rand_int__"
13) "A452"
14) "mylist"
127.0.0.1:6379> rename B3 B789
OK
127.0.0.1:6379> get B3
(nil)
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "key:__rand_int__"
4) "B99"
5) "A222"
6) "counter:__rand_int__"
7) "teacher"
8) "A3"
9) "B789"
10) "B323"
11) "B2"
12) "myset:__rand_int__"
13) "A452"
14) "mylist"

使用 [ renamenx ] 重命名,进行重命名时会检测库中的key是否与其修改的key名称相同,如若相同则不进行重名(不覆盖)
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "key:__rand_int__"
4) "B99"
5) "A222"
6) "counter:__rand_int__"
7) "teacher"
8) "A3"
9) "B789"
10) "B323"
11) "B2"
12) "myset:__rand_int__"
13) "A452"
14) "mylist"
127.0.0.1:6379> renamenx A3 A2
(integer) 0
127.0.0.1:6379> renamenx A3 A777
(integer) 1
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "A777"
4) "key:__rand_int__"
5) "B99"
6) "A222"
7) "counter:__rand_int__"
8) "teacher"
9) "B789"
10) "B323"
11) "B2"
12) "myset:__rand_int__"
13) "A452"
14) "mylist"

使用 [ dbsize ] 查看key数量
127.0.0.1:6379> dbsize
(integer) 14
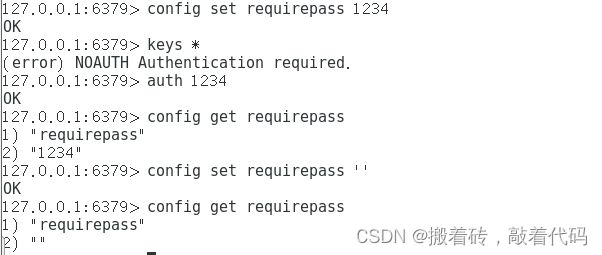
设置、登录、查看与清空密码
127.0.0.1:6379> config set requirepass 1234
## 设置登录密码
OK
127.0.0.1:6379> keys *
## 需要先登录才能进行操作
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 1234
## 输入密码进行登录
OK
127.0.0.1:6379> config get requirepass
## 查看密码
1) "requirepass"
2) "1234"
127.0.0.1:6379> config set requirepass ''
## 清空密码
OK
127.0.0.1:6379> config get requirepass
##密码已被清空
1) "requirepass"
2) ""
多数据库切换
redis支持多数据库切换,redis默认有16个数据库,数据库由数字0-15来依次命名。
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> select 4
OK
127.0.0.1:6379[4]> select 6
OK
多数据库之间移动数据[ move ]
[root@localhost utils]# redis-cli
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "A777"
4) "key:__rand_int__"
5) "B99"
6) "A222"
7) "counter:__rand_int__"
8) "teacher"
9) "B789"
10) "B323"
11) "B2"
12) "myset:__rand_int__"
13) "A452"
14) "mylist"
127.0.0.1:6379> move B2 2
(integer) 1
127.0.0.1:6379> select 2
OK
127.0.0.1:6379[2]> keys *
1) "B2"

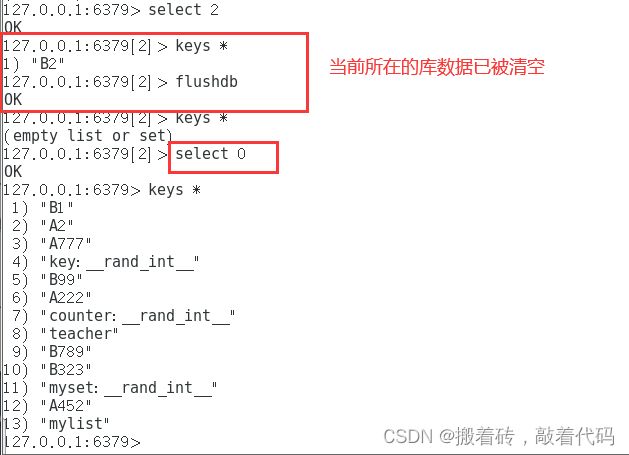
清除数据库内的数据 [ flushdb、flushall ]
flushdb:清空当前数据库数据
127.0.0.1:6379> select 2
OK
127.0.0.1:6379[2]> keys *
1) "B2"
127.0.0.1:6379[2]> flushdb
OK
127.0.0.1:6379[2]> keys *
(empty list or set)
127.0.0.1:6379[2]> select 0
OK
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "A777"
4) "key:__rand_int__"
5) "B99"
6) "A222"
7) "counter:__rand_int__"
8) "teacher"
9) "B789"
10) "B323"
11) "myset:__rand_int__"
12) "A452"
13) "mylist"
flushall:清空所有数据库的数据,慎用
127.0.0.1:6379[2]> select 0
OK
127.0.0.1:6379> keys *
1) "B1"
2) "A2"
3) "A777"
4) "key:__rand_int__"
5) "B99"
6) "A222"
7) "counter:__rand_int__"
8) "teacher"
9) "B789"
10) "B323"
11) "myset:__rand_int__"
12) "A452"
13) "mylist"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> flushall
OK
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> keys *
(empty list or set)

什么是RDB操作?
在指定的时候内,把数据以快照的形式写入磁盘,它恢复时将快照文件读取到内存里

RDB的优点与缺点
优点:正式文件不会执行IO操作,效率高,并且适合大规模数据的恢复
缺点:如果最后一个快照写入时,redis服务器宕机,那么所有数据都会丢失,fork的过程会占用内存空间。 默认的持久化配置就是RDB,在config配置中,默认的是900秒只要修改了一次key就会生成RDB文件(dump.rdb文件)
如何恢复rdb文件?
1)只需要将rdb文件存放在redis启动目录下就可以
2)查看需要存放位置的目录 (config get dir) 如果在这个目录下面redis查到存在dump.rdb文件,redis会自动恢复其中的数据
什么是AOF操作?
将我们所有的命令都记录下来保存到文件,恢复的时候把这个文件都执行一遍。
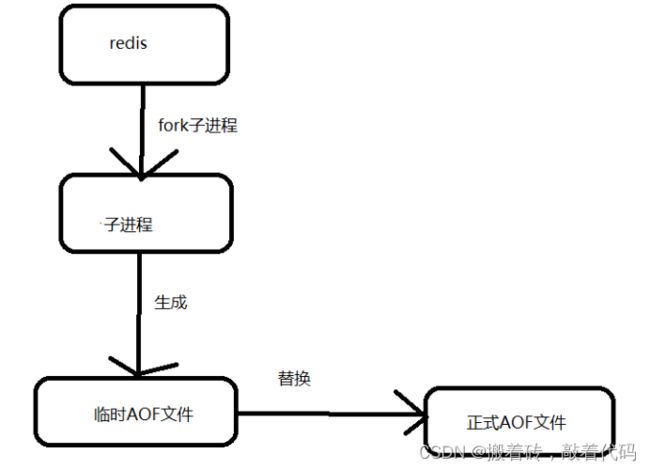
AOF的优点和缺点
优点:
1)每一次修改都可以同步,文件完整性更好!
2)每秒同步一次,可能会丢失一秒的数据
3)从不同步,效率更高
缺点:
1)修复数据把RDB慢
2)AOF运行效率也比RDB慢
主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用
●数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
●故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
●负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
●高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
实验:Redis主从复制(一主双从)
实验机器:虚拟机三台
| 机器 | ip地址 |
|---|---|
| Master节点 | 20.0.0.100 |
| Slave1节点 | 20.0.0.200 |
| Slave2节点 | 20.0.0.210 |
实验步骤:
①三台虚拟机需先安装redis
②修改 Redis 配置文件(Master节点操作-主)和修改 Redis 配置文件(Slave节点操作-从)
③验证主从效果
==================================================================================================
①三台虚拟机需先安装redis
[root@localhost ~]# systemctl stop firewalld.service && setenforce 0
## 关闭防火墙
[root@localhost ~]# yum install -y gcc gcc-c++ make
##安装 gcc gcc-c++ make 是为了编译和构建其他软件需要的工具链和依赖项
[root@localhost ~]# ls
## 将redis-5.0.7.tar.gz 压缩包放入到家目录中
anaconda-ks.cfg redis-5.0.7.tar.gz 模板 图片 下载 桌面
initial-setup-ks.cfg 公共 视频 文档 音乐

[root@localhost ~]# tar zxvf redis-5.0.7.tar.gz -C /opt/
[root@localhost /]# wget -p /opt http://download.redis.io/releases/redis-5.0.9.tar.gz

[root@localhost opt]# cd redis-5.0.7/
##切换到 redis-5.0.7/路径中
[root@localhost redis-5.0.7]# make
## 编译
[root@localhost redis-5.0.7]# make prefix=/usr/local/redis install
#### 由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
[root@localhost redis-5.0.7]# cd utils/
## 切换到utils/路径中
[root@localhost utils]# ./install_server.sh
## 执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379]
########## 回车 ##########
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf]
########## 回车 ##########
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log]
########## 回车 ##########
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379]
########## 回车 ##########
Selected default - /var/lib/redis/6379
Please select the redis executable path
[/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server
### 需要手动修改为/usr/local/redis/bin/redis-server ,要注意要一次性正确输入
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!
[root@localhost utils]# netstat -antp|grep redis
## 当 install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认监听端口为 6379

[root@localhost utils]# lsof -i:6379
[root@localhost ~]# ln -s /usr/local/redis/bin/* /usr/local/bin/
#把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
==================================================================================================
②修改 Redis 配置文件(Master节点操作-主)和修改 Redis 配置文件(Slave节点操作-从)
修改 Redis 配置文件(Master节点操作-主-20.0.0.100)
[root@localhost ~]# vim /etc/redis/6379.conf
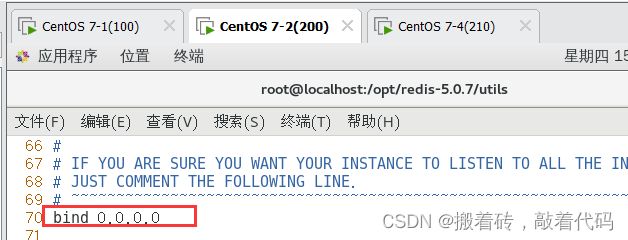
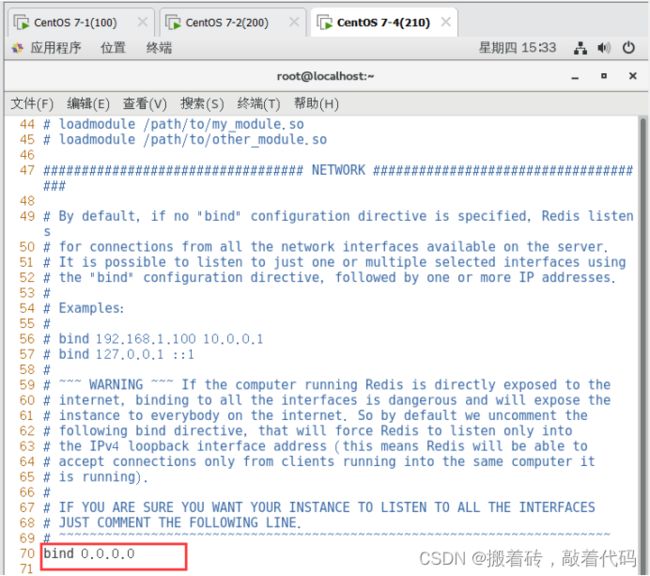
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0

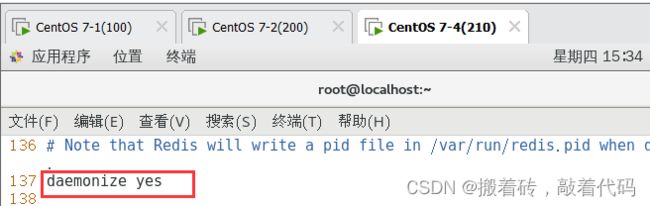
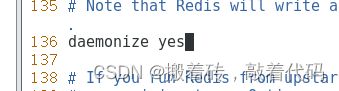
daemonize yes #137行,开启守护进程

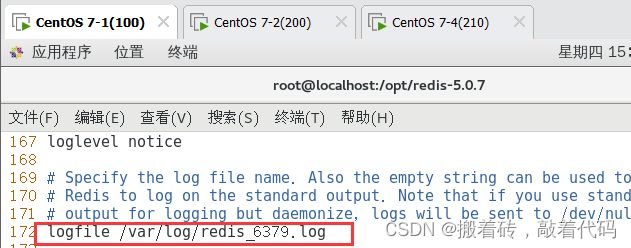
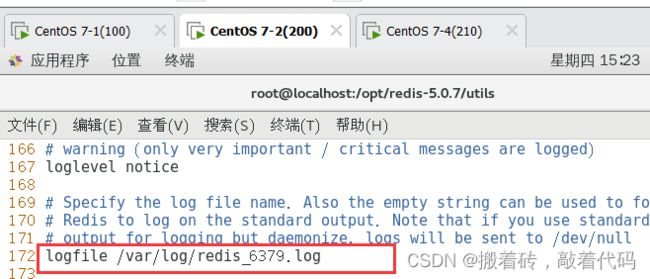
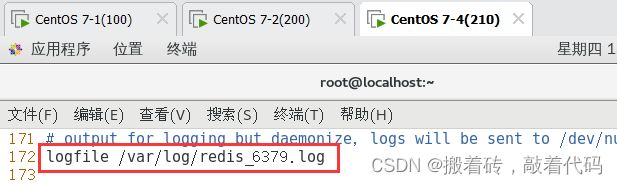
logfile /var/log/redis_6379.log #172行,指定日志文件目录
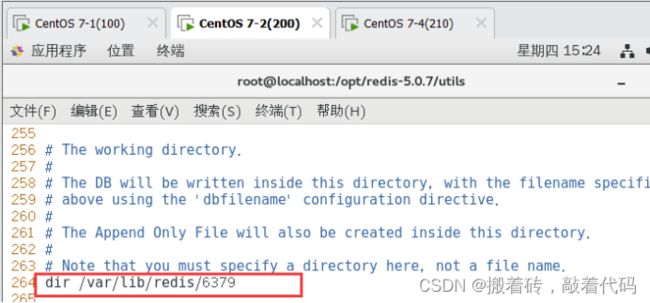
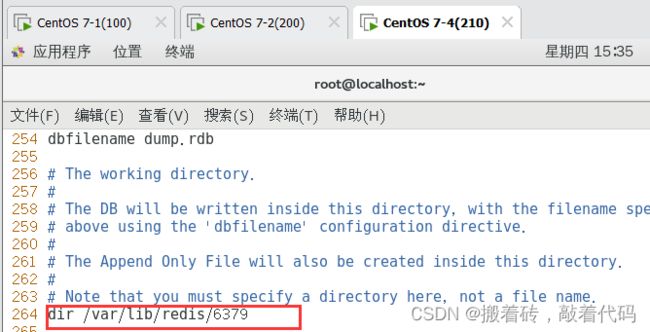
dir /var/lib/redis/6379 #264行,指定工作目录

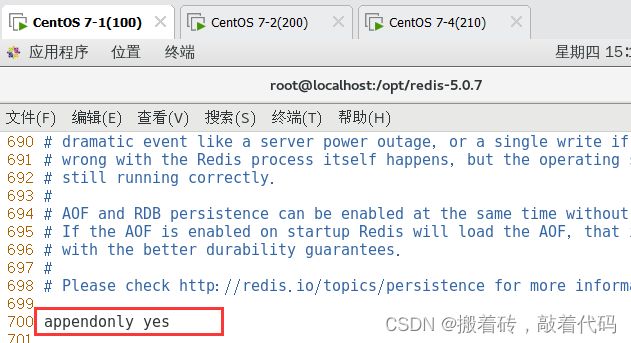
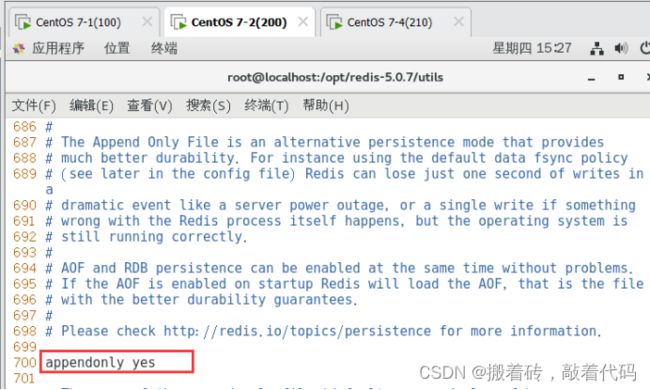
appendonly yes #700行,开启AOF持久化功能
[root@localhost ~]# /etc/init.d/redis_6379 restart
###重启
Stopping ...
Redis stopped
Starting Redis server...
修改 Redis 配置文件(Slave节点操作-从-20.0.0.200)
[root@localhost ~]# vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
daemonize yes #137行,开启守护进程

logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
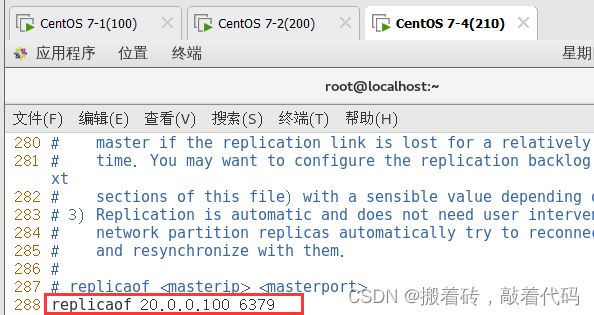
replicaof 192.168.10.22 6379 #288行,指定要同步的Master节点IP和端口
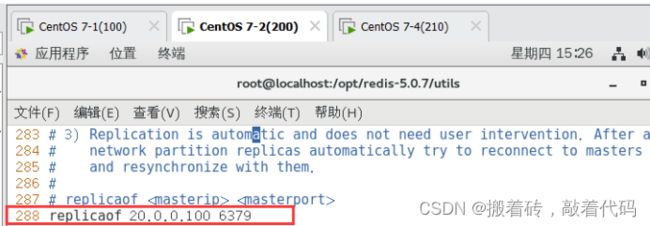
appendonly yes #700行,开启AOF持久化功能
[root@localhost ~]# /etc/init.d/redis_6379 restart
##重启
Stopping ...
Redis stopped
Starting Redis server...
修改 Redis 配置文件(Slave节点操作-从-20.0.0.210)
[root@localhost ~]# vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
replicaof 192.168.10.22 6379 #288行,指定要同步的Master节点IP和端口
appendonly yes #700行,开启AOF持久化功能

[root@localhost ~]# /etc/init.d/redis_6379 restart
##重启
Stopping ...
Redis stopped
Starting Redis server...
==================================================================================================
③验证主从效果
在Master节点上看日志:
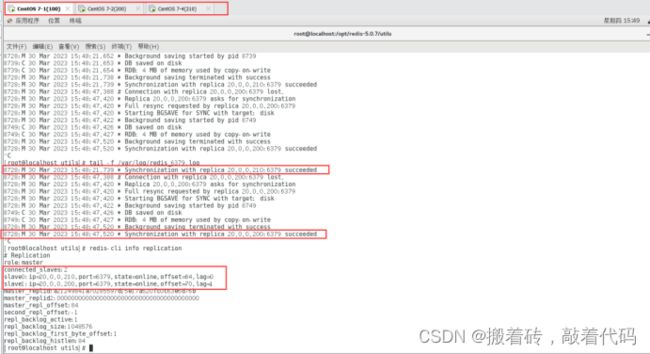
[root@localhost utils]# tail -f /var/log/redis_6379.log
8728:M 30 Mar 2023 15:48:21.739 * Synchronization with replica 20.0.0.210:6379 succeeded
8728:M 30 Mar 2023 15:48:47.388 # Connection with replica 20.0.0.200:6379 lost.
8728:M 30 Mar 2023 15:48:47.420 * Replica 20.0.0.200:6379 asks for synchronization
8728:M 30 Mar 2023 15:48:47.420 * Full resync requested by replica 20.0.0.200:6379
8728:M 30 Mar 2023 15:48:47.420 * Starting BGSAVE for SYNC with target: disk
8728:M 30 Mar 2023 15:48:47.422 * Background saving started by pid 8749
8749:C 30 Mar 2023 15:48:47.426 * DB saved on disk
8749:C 30 Mar 2023 15:48:47.427 * RDB: 4 MB of memory used by copy-on-write
8728:M 30 Mar 2023 15:48:47.520 * Background saving terminated with success
8728:M 30 Mar 2023 15:48:47.520 * Synchronization with replica 20.0.0.200:6379 succeeded
在Master节点上验证从节点:
[root@localhost utils]# redis-cli info replication
# Replication
role:master
connected_slaves:2
slave0:ip=20.0.0.210,port=6379,state=online,offset=84,lag=0
slave1:ip=20.0.0.200,port=6379,state=online,offset=70,lag=1
master_replid:a21249841a70285597d15e17a520fc0c63e6d76b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:84
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:84
Redis 哨兵模式
主从切换技术的方法是:当服务器宕机后,需要手动一台从机切换为主机,这需要人工干预,不仅费时费力而且还会造成一段时间内服务不可用。为了解决主从复制的缺点,就有了哨兵机制。
哨兵的核心功能:
在主从复制的基础上,哨兵引入了主节点的自动故障转移。
哨兵模式原理:
哨兵(sentinel):是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 Master并将所有slave连接到新的 Master。所以整个运行哨兵的集群的数量不得少于3个节点。
哨兵模式的作用:
●监控:哨兵会不断地检查主节点和从节点是否运作正常。
●自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其它从节点改为复制新的主节点。
●通知(提醒):哨兵可以将故障转移的结果发送给客户端。
哨兵结构由两部分组成,哨兵节点和数据节点:
●哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
●数据节点:主节点和从节点都是数据节点。
故障转移机制:
1.由哨兵节点定期监控发现主节点是否出现了故障
每个哨兵节点每隔1秒会向主节点、从节点及其它哨兵节点发送一次ping命令做一次心跳检测。如果主节点在一定时间范围内不回复或者是回复一个错误消息,那么这个哨兵就会认为这个主节点主观下线了(单方面的)。当超过半数哨兵节点认为该主节点主观下线了,这样就客观下线了。
2.当主节点出现故障,此时哨兵节点会通过Raft算法(选举算法)实现选举机制共同选举出一个哨兵节点为leader,来负责处理主节点的故障转移和通知。所以整个运行哨兵的集群的数量不得少于3个节点。
3.由leader哨兵节点执行故障转移,过程如下:
●将某一个从节点升级为新的主节点,让其它从节点指向新的主节点;
●若原主节点恢复也变成从节点,并指向新的主节点;
●通知客户端主节点已经更换。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
主节点的选举:
1.过滤掉不健康的(已下线的),没有回复哨兵 ping 响应的从节点。
2.选择配置文件中从节点优先级配置最高的。(replica-priority,默认值为100)
3.选择复制偏移量最大,也就是复制最完整的从节点。
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式
实验:Redis哨兵模式(一主双从)
实验机器:虚拟机三台
| 机器 | ip地址 |
|---|---|
| Master节点 | 20.0.0.100 |
| Slave1节点 | 20.0.0.200 |
| Slave2节点 | 20.0.0.210 |
实验步骤:
①按上面的方法部署搭建redis
②修改 Redis 哨兵模式的配置文件(所有节点操作)
③启动哨兵模式,先启master,再启slave,查看哨兵信息
④故障模拟
==================================================================================================
①按上面的方法部署搭建redis
操作前需先关闭防火墙
systemctl stop firewalld && setenforce 0
[root@localhost ~]# systemctl stop firewalld && setenforce 0
==================================================================================================
②修改 Redis 哨兵模式的配置文件(所有节点操作,先同时设置20.0.0.100为主机器)
[root@localhost ~]# vim /opt/redis-5.0.7/sentinel.conf
protected-mode no #17行,关闭保护模式
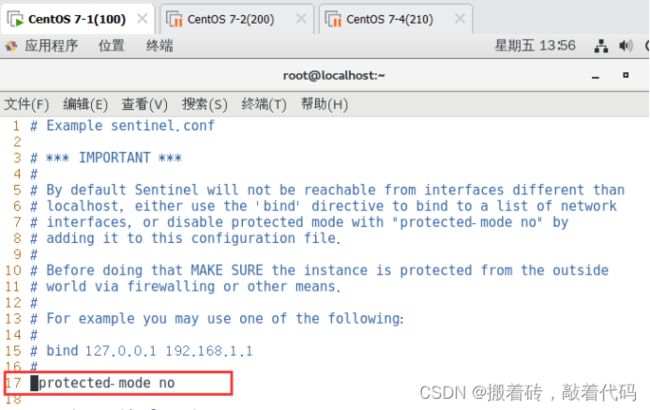
daemonize yes #26行,指定sentinel为后台启动
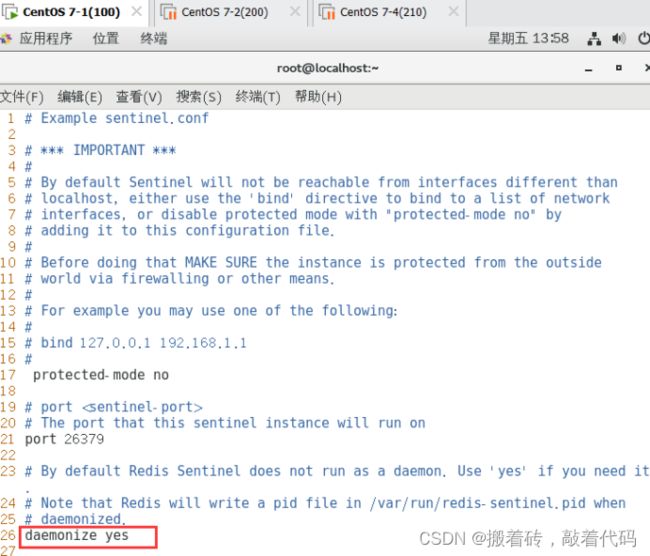
logfile "/var/log/sentinel.log" #36行,指定日志存放路径
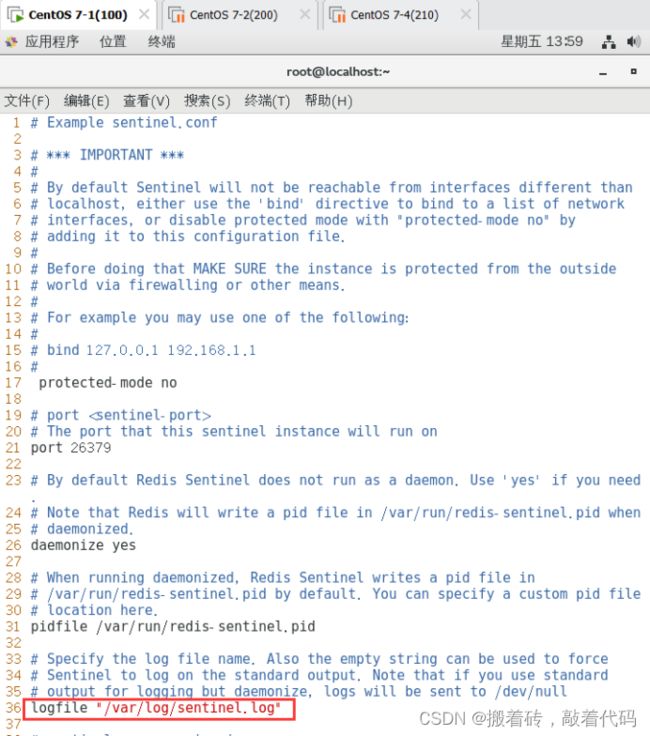
dir "/var/lib/redis/6379" #65行,指定数据库存放路径
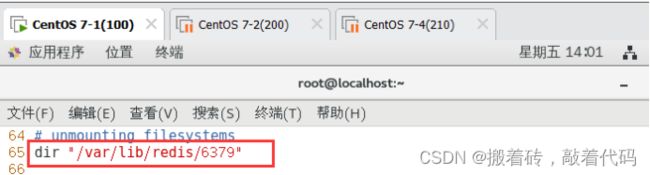
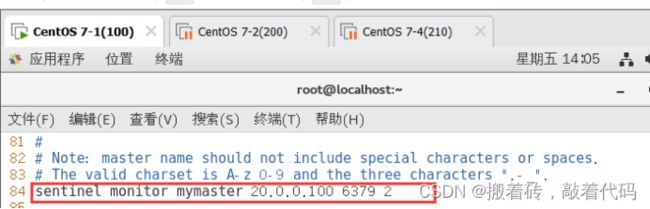
sentinel monitor mymaster 20.0.0.100 6379 2 #84行,修改 指定该哨兵节点监控20.0.0.100:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移

==================================================================================================
③启动哨兵模式,先启master,再启slave,查看哨兵信息
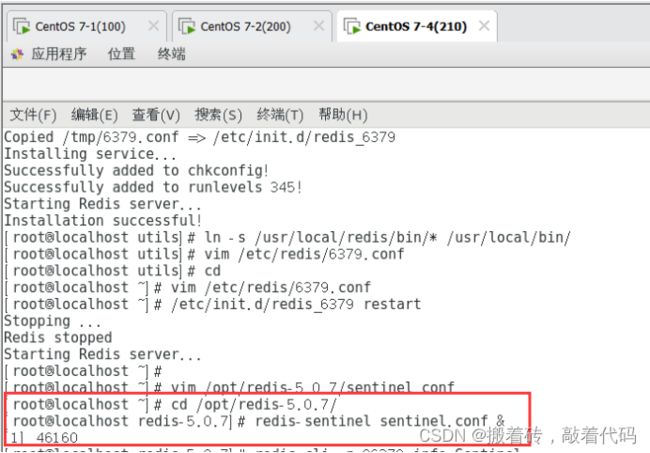
[root@localhost utils]# cd /opt/redis-5.0.7/
[root@localhost redis-5.0.7]# redis-sentinel sentinel.conf &


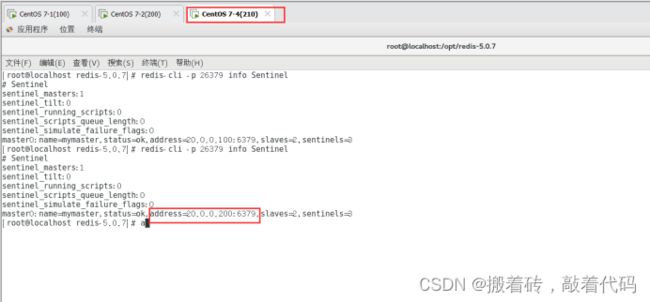
查看哨兵信息
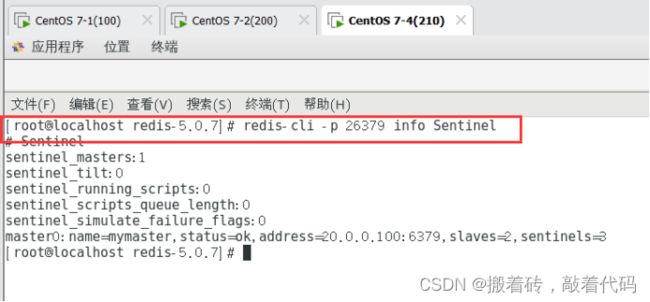
[root@localhost redis-5.0.7]# redis-cli -p 26379 info Sentinel


==================================================================================================
④故障模拟
查看redis-server进程号
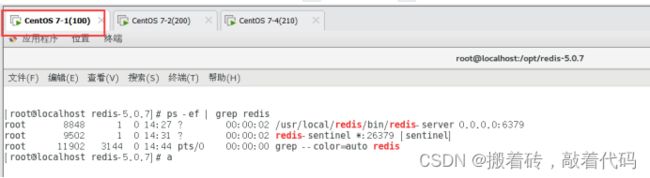
[root@localhost redis-5.0.7]# ps -ef |grep redis
杀死 Master 节点上redis-server的进程号
[root@localhost redis-5.0.7]# kill -9 8848
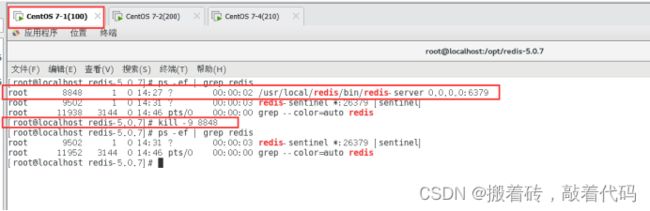
验证结果(现在主哨兵从100改为200,主机器100出现故障,转移到200成为新的主机器)
[root@localhost redis-5.0.7]# tail -f /var/log/sentinel.log
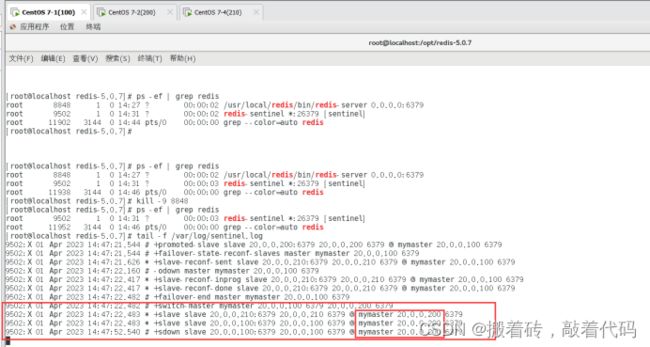

Redis集群模式
集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。
集群由多个节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
集群的作用
可以归纳为两点:
(1)数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
(2)高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
Redis集群的数据分片:
Redis集群引入了哈希槽的概念
Redis集群有16384个哈希槽(编号0-16383)
集群的每个节点负责一部分哈希槽
每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
以3个节点组成的集群为例:
节点A包含0到5460号哈希槽
节点B包含5461到10922号哈希槽
节点C包含10923到16383号哈希槽
Redis集群的主从复制模型
集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。
为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为的主节点继续服务。当B和B1都失败后,集群将不可用。
实验:Redis集群模式(三主三从,单台机器演示)
redis的集群一般需要6个节点,3主3从。
实验机器:虚拟机一台
实验步骤:
①按上面的方法部署搭建redis
②方便起见,这里所有节点在同一台服务器上模拟:以端口号进行区分:3个主节点端口号:6001/6002/6003,对应的从节点端口号:6004/6005/6006。
③开启群集功能,其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
④启动redis节点,分别进入那六个文件夹,执行命令:redis-server redis.conf ,来启动redis节点
⑤启动集群,测试群集
⑥测试群集
==================================================================================================
①按上面的方法部署搭建redis
==================================================================================================
②方便起见,这里所有节点在同一台服务器上模拟:以端口号进行区分:3个主节点端口号:6001/6002/6003,对应的从节点端口号:6004/6005/6006。
[root@localhost /]# mkdir data
[root@localhost /]# cd data
[root@localhost data]# vim redis-cluster.sh
cd /etc/redis/
mkdir -p redis-cluster/redis600{1..6}
for i in {1..6}
do
cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
done

[root@localhost data]# bash redis-cluster.sh
[root@localhost data]# ls /etc/redis/redis-cluster/
redis6001 redis6002 redis6003 redis6004 redis6005 redis6006
[root@localhost data]# cd /etc/redis/redis-cluster/
[root@localhost redis-cluster]# cd redis6001/
[root@localhost redis6001]# ls
redis-cli redis.conf redis-server
==================================================================================================
③开启群集功能,其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
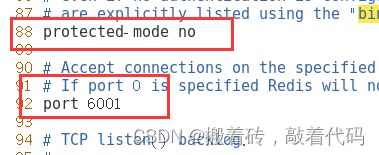
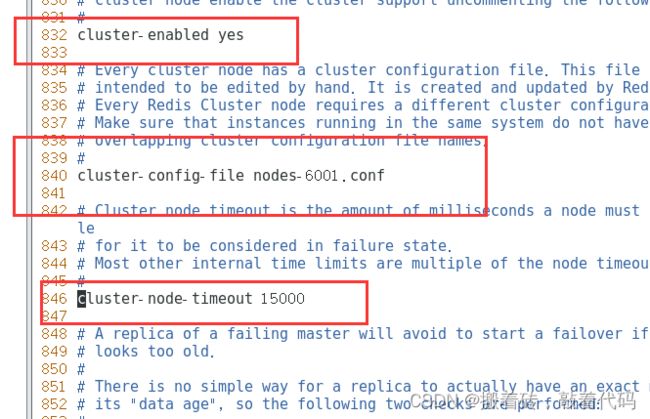
[root@localhost redis6001]# vim redis.conf

![]()
[root@localhost redis6001]# cp redis.conf ../redis6002/
cp:是否覆盖"../redis6002/redis.conf"? yes
[root@localhost redis6001]# cp redis.conf ../redis6003/
cp:是否覆盖"../redis6003/redis.conf"? yes
[root@localhost redis6001]# cp redis.conf ../redis6004/
cp:是否覆盖"../redis6004/redis.conf"? yes
[root@localhost redis6001]# cp redis.conf ../redis6005/
cp:是否覆盖"../redis6005/redis.conf"? yes
[root@localhost redis6001]# cp redis.conf ../redis6006/
cp:是否覆盖"../redis6006/redis.conf"? yes
[root@localhost redis6001]# vim ../redis6002/redis.conf

[root@localhost redis6001]# vim ../redis6003/redis.conf

[root@localhost redis6001]# vim ../redis6004/redis.conf

[root@localhost redis6001]# vim ../redis6005/redis.conf

[root@localhost redis6001]# vim ../redis6006/redis.conf

[root@localhost redis6001]# ln -s /etc/redis/redis-cluster/redis6001/redis-cli /usr/local/bin/
[root@localhost redis6001]# ln -s /etc/redis/redis-cluster/redis6001/redis-server /usr/local/bin/
==================================================================================================
④启动redis节点,分别进入那六个文件夹,执行命令:redis-server redis.conf ,来启动redis节点
[root@localhost redis-cluster]# for d in {1..6};do cd /etc/redis/redis-cluster/redis600$d ; redis-server redis.conf; done
[root@localhost redis6006]# ps -ef|grep redis
==================================================================================================
⑤启动集群
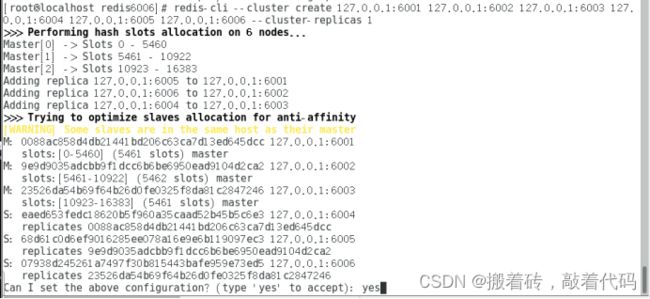
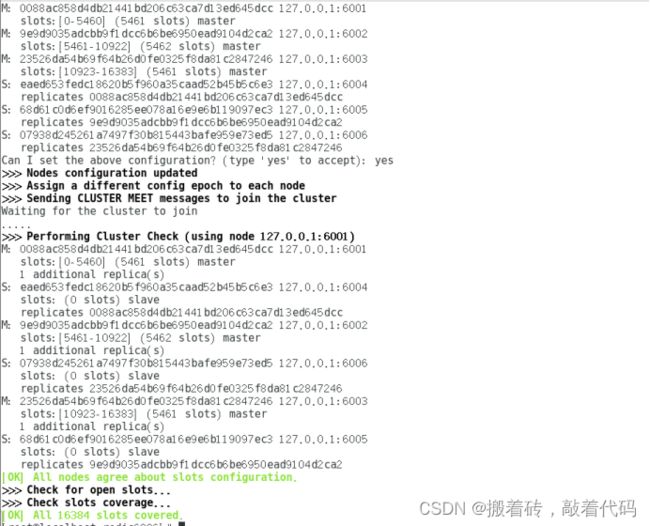
[root@localhost redis6006]# redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1
#六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候 需要输入 yes 才可以创建。
--replicas 1 表示每个主节点有1个从节点。
==================================================================================================
⑥测试集群
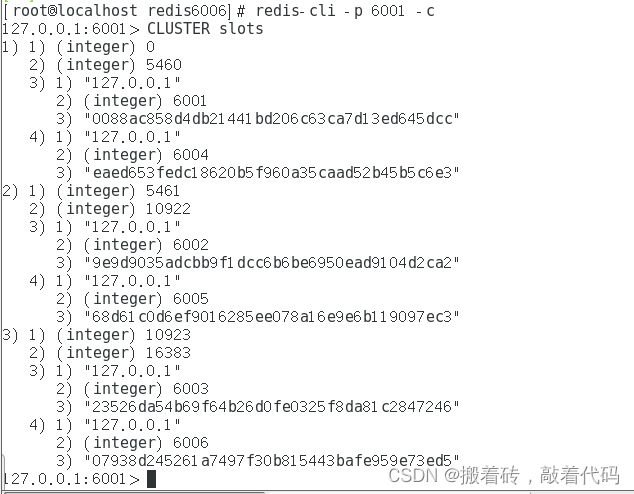
[root@localhost redis6006]# redis-cli -p 6001 -c
127.0.0.1:6001> CLUSTER slots
总结
非关系数据库
1、数据保存在缓存中,利于读取速度/查询数据
2、架构中位置灵活
3、分布式、扩展性高
关系数据库
1、安全性高(持久化)
2、事务处理能力强
3、任务控制能力强
4、可以做日志备份、恢复、容灾的能力更强一点。
关系型数据库:
实例–>数据库–>表(table)–>记录行(row)、数据字段(column)------》存储数据
非关系型数据库:
实例–>数据库–>集合(collection)–>键值对(key-value)
非关系型数据库不需要手动建数据库和集合(表)