Redis
Redis
1.为什么要学习Redis?
当我们的系统引入了传统的缓存框架,比如(ehcache),因为ehcache等框架只是一个内置的缓存框架,所以前端的缓存和后台的(每一个web server)的缓存都是独立存在的,假如一个缓存中的数据发生了更新,其他缓存是不可能知道的,这样对于乐观锁,总会提示失败。
2.出现上面的问题我们需要如何解决?
解决方法有两个:
1.同步缓存数据【在分布式环境下,缓存是不能同步】
2.让缓存集中处理(大家使用同一个缓存服务)。就是说我们需要一个类似于MYSQL这样可以通过服务来提供第三方的缓存工具(缓存服务器).
目前比较流行的缓存服务器有:memcache【不常用】/redis。

3.什么是Redis?
Redis----REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value【键值对】存储系统(可以把redis想象成一个巨大的MAP)。
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis和ehcache不一样的是,ehcache可以看做一个嵌入式的缓存框架,而redis是一个独立的应用服务(像MYSQL一样),既可以提供缓存功能,还可以把数据持久化到磁盘上(redis也可以提供持久化的功能,在某些情况下,redis也可以作为数据库存在)。
Redis提供了一些丰富的数据结构,包括 lists, sets, ordered sets 以及 hashes ,当然还有 strings结构.Redis当然还包括了对这些数据结构的丰富操作。
4.理解Redis
Redis可以看成一个Map(key-value),在redis中,所有的KEY都可以理解为byte.
VALUE?在memcache中,value也只能是byte;------>Map
在redis中,value的可选类型很多,String,list,set,orderset,hash
Map
redis是一个key-value的内存存储应用(使用redis主要还是把数据存在内存中,这个可以最大的使用redis的性能优势);
redis可以把数据存储在内存中,也可以持久化到磁盘上;
redis不是一个适用于任何场景的存储应用;
理解:我们之前介绍数据库:关系型数据库、面向对象数据库、NoSQL(Not only SQL)—>(KEY-VALUE)内存数据库;redis不光可以作为一个缓存,他还是一个高效的内存数据库;可以在某些情况下,高效的替换到传统的关系型数据库,非常好的处理好高并发,高请求的场景.
5.Redis的优势
1.性能极高 – Redis能支持超过 10W次每秒的读写频率。
2.丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
3.原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行(简单的事务)。
4.丰富的特性 – Redis还支持 publish/subscribe(发布/订阅), 通知, key 过期等等特性。
使用Redis的公司github,blizzard,stackoverflow,flickr,国内有新浪微博【拥有全球最大的Redis集群】,淘宝,腾讯微博。
6.如何学习Redis
redis 中文资料站: http://www.redis.cn/
redis 命令手册: http://www.redisdoc.com/en/latest/index.html
了解try.redis
http://try.redis.io/
我们所有的操作都可以在这个上面操作。不用安装Redis服务器。
我们输入TUTORIAL 回车就可以开始学习了

结果:

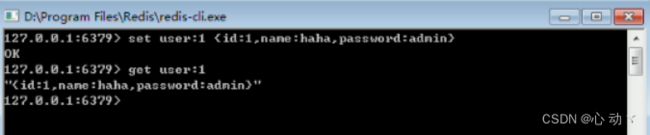
向Redis中保存一个键值对数据【set server:name “dox”】
Set—redis保存数据的命令;
Server:name—就是一个键
“dox”----就是一个值

运行结果:

从Redis中获取指定键的数据值 【get server:name】

运行结果:

以上是给大家演示了一下Redis中存取数据的基本操作
7.理解这两个最基本的redis命令
SET KEY VALUE:把VALUE保存到redis中KEY对应的值;
GET KEY:取出redis中KEY对应的值;
在上面的实例中KEY的值为server:name,这个就代表server的name,这是Redis中KEY取名的一个规范。
理解一下“server:name”这种KEY取名规范:
我们之前说到redis不光是一个缓存,还可以看成一个数据库,这种数据库和传统的关系型数据库最大的区别就在于,传统的关系型数据库,在保存数据之前,都已经有一个固定的数据表;内容是保存在这个数据表中不同行的数据;所有的数据都存在这一张指定的表中,所有的内容都对应表里面一个指定的行,每一个行都有固定的数据类型,所以当我们在使用关系型数据库表现一个对象(数据结构的时候),我们能够事前通过数据库表规范好这个对象的数据结构;
比如,要表现User这个对象,只需要创建一个user表,在表里面创建id,name,password三个列,在保存数据的时候,就是直接把数据保存到这个表中对应的列中;要查询id为1的user,可以通过select语句去表的内容里面进行结构化的筛选;但是对于redis来说,整个数据库就是一个Map,没有任何结构可言,所有通过set等方法扔到redis中的数据,可以简单理解为就是所有的数据乱七八糟的放在一个map中。
那么问题来了:
1、在redis中,怎么存储一个User对象数据?
首先Redis就是一个巨大的Map,在Map中我们是不能通过value来查询数据的,所以在Redis中能够被查询的数据,都必须通过KEY来表示,换句话说,redis的key的作用:1,反映数据的结构,2反映查询的内容。
Set user:1
Set user:name:1
例如:我们在Redis中保存一个User对象型数据
Public class User{
private int id;
private String name;
private String password;
getXXXX() / setXXXX();
}
User user=new User();
user.setId(1);
user.setNme(“zhangsan”);
user.setPassword(“123456”);
将上面的User对象保存在Redis中,首先我们先确定这个User对象是保存到Redis中的第1个对象数据;
set user:1:id 1
OK
set user:1:name zhangsan
OK
set user:1:password 123456
OK
在上面的操作中set user:1:password 123456 ,“user:1:password ”就是一个key
获取指定属性的数据值:
get user:1:name
“zhangsan”
还有一种方式【可以通过json数据保存数据】:
set user:2 {id:2,name:lisi,password:111111}
OK
8.Redis的版本
Redis 使用标准版本标记进行版本控制:major.minor.patchlevel。偶数的版本号表示稳定的版本, 例如 1.2,2.0,2.2,2.4,2.6,2.8,奇数的版本号用来表示非标准版本,例如2.9.x是非稳定版本,它的稳定版本是3.0。
目前的稳定版本是5.0,Redis 5.0 是第一个加入流数据类型(stream data type )的版本.
Redis是*Unix应用;我们在开发中使用的windows版本【Redis-x64-2.8.2104.msi】不是官方的,是微软开源提供的,每一个版本都对应着一个linux版本的Redis【Redis-x64-2.8.2104.zip】;准生产环境是不会使用windows版本的。我们学习Redis的时候就先使用windows安装版本。
注意32和64位版本的区别。
9.windows环境下安装Redis[Redis-x64-2.8.2104.msi]



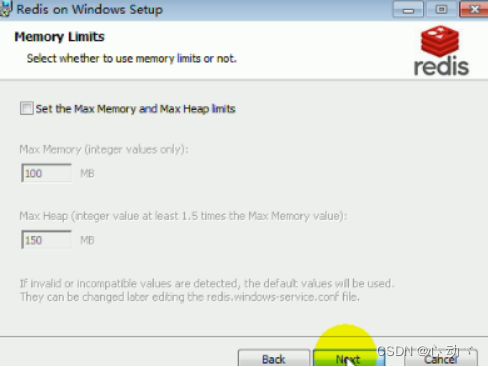
上图中是要设置Redis的初始内存大小和堆内存大小。

安装完成.
安装完后的安装目录中有几个常用的文件:
1.redis.windows.conf文件–当我我们安装成功以后如果启动redis的时候有错误,那么我们需要打开这个文件修改maxheap配置属性的数据值和maxmemory配置属性的数据值。
2.redis-server.exe文件–启动redis服务【默认安装成功以后机会自动启动】
3.redis-cli.exe文件–redis客户端窗口启动。
10.Redis中的一些基本概念
1.database数据库
1.1 redis也有数据库的概念,一个数据库中可以保存一组数据;
1.2各个数据库之间是相互隔离的,当然也可以在不同数据库之间复制数据;
1.3一般一个应用会单独使用一个数据库;
1.4每一个数据库都有一个id号,默认的数据库id为0;
1.5可以使用select命令选择当前使用的数据库;
1.6redis默认为我们创建16个数据库,这个参数可以在redis配置文件中使用databases修改;
例如:
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> select 1
2.Command(命令)
2.1.redis中提供了非常大量的命令来方便的操作数据库中的数据,还可以使用redis中的一些特性;
2.2.redis的命令可以简单理解为mysql的SQL命令;
2.3.redis命令分为
1.对数据的操作;
2.发布/订阅相关操作;
3.事务控制;
4.脚本命令;
5.连接服务器命令;
6.数据库服务相关命令;
3.KEY-VALUE
3.1key用来标记一个数据;一般在key中需要尽量标明数据的名字(还可以使用key来表明数据所属类型),比如用于标示一个对象的时候,可以使用user:1000来作为key,代表id为1000的用户对象;
3.2.value表示一个key对应的值;在redis中,数据可以是任何内容,redis把所有的value都作为byte处理;所以可以用来保存任何内容;
3.3.redis最突出的特点是提供了5种常用的数据存储类型(value的类型),深刻理解这5中数据结构和各自的使用场景,对redis的使用有很大帮助;
4.Query(检索)
4.1.在redis中,不支持对value进行任何形式的查询;
例如,保存一个user:
set user:1 ‘{name:“hello”,id:1}’
是无法通过redis去查询name为hello的user;要查询的内容,只能反映在key值上,所以如果要按照用户的name查询,只能再添加一条数据:
set user:name:stef 1
4.2.redis不是一个适用于任何场景的存储方案,考虑使用redis需要对业务进行考评,用redis的思想去重新设计数据结构;
5.存储
5.1.redis可以作为内存数据库,也可以把数据持久化到磁盘上;大部分情况下,都是把redis作为内存数据库;
5.2.默认情况下
#after 900 sec (15 min) if at least 1 key changed
#after 300 sec (5 min) if at least 10 keys changed
#after 60 sec if at least 10000 keys changed
在redis配置文件中:
save 900 1
save 300 10
save 60 10000
5.3.数据默认存储在安装目录下.rdb文件中(可以在配置文件中dbfilename dump.rdb配置);
5.4.redis也可以设置为append模式,每次key的修改都会append到文件中,这种方式有可能丢失60秒的数据;
5.4.1.通过配置:appendonly yes开启
5.4.2.appendfilename "appendonly.aof"设置append文件;
5.4.3.可以设置append的模式(类似于mysql的事务文件同步机制):
# appendfsync always:每次更新key及时同步到append文件;
appendfsync everysec:每一秒同步一次key的更新;
# appendfsync no:不管理append文件的更新,根据操作系统去定
11.redis中的数据结构
redis中丰富数据结构是redis区别memcache等其他NOSQL一个重要的优势;学习redis中的5中数据结构对使用redis有非常大的帮助;
怎么学习redis中的数据结构和相关的操作:
1.熟悉数据结构的意义,最简单方法和java的数据类型对比;
2.了解数据结构常用的一些命令(看文档,学会看懂文档中命令的意思和使用方式);
3.尝试使用一些这些命令,做简单的实验(可以不需要场景,就只是看结果);
4.了解该数据结构的使用场景(文档/网上资料),设计一个具体的场景,使用有效命令完成场景操作;
5.了解该数据结构的实现原理,了解该数据结构不同操作的执行效率(进阶)
浏览器中输入: http://www.redis.cn/

选择Strings,列举String的所有命令:
点击每一个具体命令,得到命令的具体解释:

12.redis中的string
1.redis中最常见的数据类型;内容可以是任何值(因为string对应着byte[]);
2.可以通过set key value添加一个值;
127.0.0.1:6379> set teststring “hello,world”
3.常见的字符串操作:
1.strlen key:返回key的value的值长度;
127.0.0.1:6379> strlen teststring
(integer) 11
2.getrange key X Y:返回key对应value的一个子字符串,位置从X到Y;
127.0.0.1:6379> getrange teststring 6 11
“world”
3.append key value:给key对应的value追加值,如果key不存在,相当于set一个新的值;
127.0.0.1:6379> append teststring “,nihao”
(integer) 17
127.0.0.1:6379> get teststring
“hello,world,nihao”
4.如果字符串的内容是数值(integer,在redis中,数值也是string)
1.incr key:在给定key的value上增加1;(常用于id);redis中的incr是一个原子操作,支持并发;如果key不存在,则相当于设置1;
127.0.0.1:6379> set intstring 20
OK
127.0.0.1:6379> get intstring
“20”
127.0.0.1:6379> incr intstring
(integer) 21
127.0.0.1:6379> get intstring
“21”
2.incrby key value:给定key的value上增加value值;相当于key=key.value+value;这也是一个原子操作;
127.0.0.1:6379> set userage 20
OK
127.0.0.1:6379> get userage
“20”
127.0.0.1:6379> incrby userage 5
(integer) 25
127.0.0.1:6379> get userage
“25”
3.decr:在给定key的value上减少1;
127.0.0.1:6379> get intstring
“21”
127.0.0.1:6379> decr intstring
(integer) 20
127.0.0.1:6379> get intstring
“20”
4.decrby key value:给定key的value上减少value值;
127.0.0.1:6379> get userage
“25”
127.0.0.1:6379> decrby userage 5
(integer) 20
127.0.0.1:6379> get userage
“20”
5.string最常见的使用场景:
存储json类型对象
incr user:id
set user:1 {id:1,name:xiaolong}
incr user:id
set user:2 {id:2,name:stef}
作为计数器, incr count;
优酷视频点赞
incr vediogoodcount
decr vediogoodcount
13.redis中的list
1.redis的LIST结构(想象成java中的List),是一个双向链表结构,可以用来存储一组数据;从这个列表的前端和后端取数据效率非常高;
2.list的常用操作:
1.RPUSH:在一个list最后添加一个元素 [从右向左添加,最后一个排在末尾]
127.0.0.1:6379> rpush wei “zhangliao”
(integer) 1
127.0.0.1:6379> rpush wei “xuchu”
(integer) 2
127.0.0.1:6379> rpush wei “dianwei”
(integer) 3
127.0.0.1:6379> rpush wei “xuhuang”
(integer) 4
127.0.0.1:6379> rpush wei “xiahou”
(integer) 5
2.LRANGE key start stop:获取列表中的一部分数据,两个参数,第一个参数代表第一个获取元素的位置(0)开始,第二个值代表截止的元素位置,如果第二个参数为-1,截止到列表尾部;
127.0.0.1:6379> lrange wei 0 -1
- “zhangliao”
- “xuchu”
- “dianwei”
- “xuhuang”
- “xiahou”
127.0.0.1:6379> lrange wei 1 -1 - “xuchu”
- “dianwei”
- “xuhuang”
- “xiahou”
3.LPUSH:在一个list最前面添加一个元素【从左向右添加,最后一个排在开头】
127.0.0.1:6379> lpush shu “guanxu”
(integer) 1
127.0.0.1:6379> lpush shu “zhangfei”
(integer) 2
127.0.0.1:6379> lpush shu “zhaoyun”
(integer) 3
127.0.0.1:6379> lpush shu “huangzhong”
(integer) 4
127.0.0.1:6379> lpush shu “machao”
(integer) 5
遍历集合
127.0.0.1:6379> lrange shu 0 -1 - “machao”
- “huangzhong”
- “zhaoyun”
- “zhangfei”
- “guanxu”
4.LLEN key: 返回一个列表当前长度
127.0.0.1:6379> llen shu
(integer) 5
127.0.0.1:6379> llen wei
(integer) 5
5.LPOP:移除list中第一个元素,并返回这个元素
127.0.0.1:6379> lpop shu
“machao”
127.0.0.1:6379> llen shu
(integer) 4
127.0.0.1:6379> lrange shu 0 -1 - “huangzhong”
- “zhaoyun”
- “zhangfei”
- “guanxu”
6.RPOP:移除list中最后一个元素,并返回这个元素;
127.0.0.1:6379> rpop wei
“xiahou”
127.0.0.1:6379> llen wei
(integer) 4
127.0.0.1:6379> lrange wei 0 -1 - “zhangliao”
- “xuchu”
- “dianwei”
- “xuhuang”
3.使用场景:
1.可以使用redis的list模拟队列,堆栈
2.朋友圈点赞;
规定:朋友圈内容的格式:
1.内容: user❌post:x content来存储;
2.点赞: post❌good list来存储;
1.创建一条微博内容:set user:1:post:91 ‘hello redis’;
2.点赞:
lpush post:91:good ‘{id:1,name:stef,img:xxx.jpg}’
lpush post:91:good ‘{id:2,name:xl,img:xxx.jpg}’
lpush post:91:good ‘{id:3,name:xm,img:xxx.jpg}’
3,查看有多少人点赞: llen post:91:good
4,查看哪些人点赞:lrange post:91:good 0 -1
思考,如果用数据库实现这个功能,SQL会多复杂??
示例2:回帖
1,创建一个帖子:set user:1:post:90 ‘wohenshuai’
2,创建一个回帖:set postreply:1 ‘nonono’
3,把回帖和帖子关联:lpush post:90:replies 1
4,再来一条回帖:set postreply:2 ‘hehe’
lpush post:90:replies 2
5,查询帖子的回帖:lrange post:90:replies 0 -1
get postreply:2
14.redis中的set
1.SET结构和java中差不多,数据没有顺序,并且每一个值不能重复;
2.SET结构的常见操作:
1.SADD:给set添加一个元素
127.0.0.1:6379> sadd myset “zhangsan”
(integer) 1
127.0.0.1:6379> sadd myset “lisi”
(integer) 1
127.0.0.1:6379> sadd myset “wangwu”
(integer) 1
127.0.0.1:6379> sadd myset “zhaoliu”
(integer) 1
2.SCARD:返回set的元素个数
127.0.0.1:6379> scard myset
(integer) 4
数据没有顺序,并且每一个值不能重复
127.0.0.1:6379> sadd myset “zhangsan”
(integer) 0
127.0.0.1:6379> scard myset
(integer) 4
3.SISMEMBER:判断给定的一个元素是否在set中,如果存在,返回1,如果不存在,返回0
127.0.0.1:6379> SISMEMBER myset “lisi”
(integer) 1
127.0.0.1:6379> SISMEMBER myset “hello”
(integer) 0
4.SMEMBERS:返回指定set内所有的元素,以一个list形式返回
127.0.0.1:6379> smembers myset
- “wangwu”
- “zhangsan”
- “lisi”
- “zhaoliu”
5.SUNION(并集):综合多个set的内容,并返回一个list的列表,包含综合后的所有元素;
127.0.0.1:6379> sadd myset “zhangsan”
(integer) 1
127.0.0.1:6379> sadd myset “lisi”
(integer) 1
127.0.0.1:6379> sadd myset “wangwu”
(integer) 1
127.0.0.1:6379> sadd myset “zhaoliu”
127.0.0.1:6379> scard myset
(integer) 4
——————————————————
127.0.0.1:6379> sadd testset “javase”
(integer) 1
127.0.0.1:6379> sadd testset “javaee”
(integer) 1
127.0.0.1:6379> sadd testset “javame”
(integer) 1
127.0.0.1:6379> scard testset
(integer) 3
——————————————————
127.0.0.1:6379> sunion testset myset - “javame”
- “javaee”
- “wangwu”
- “zhangsan”
- “lisi”
- “zhaoliu”
- “javase”
6.SREM:从set中移除一个给定元素
127.0.0.1:6379> SREM myset “zhangsan”
(integer) 1
127.0.0.1:6379> smembers myset - “wangwu”
- “lisi”
- “zhaoliu”
3.set的使用场景:
1.去重;
2.抽奖;
1.准备一个抽奖池:sadd luckdraws 1 2 3 4 5 6 7 8 9 10 11 12 13
2.抽3个三等奖:srandmember luckdraws 3
srem luckdraws 11 1 10
3.抽2个二等奖:
3.做set运算(好友推荐)
1.初始化好友圈
sadd user:1:friends ‘user:2’ ‘user:3’ ‘user:5’
sadd user:2:friends ‘user:1’ ‘user:3’ ‘user:6’
sadd user:3:friends ‘user:1’ ‘user:7’ ‘user:8’
2.把user:1的好友的好友集合做并集;
user:1 user:3 user:6 user:7 user:8
3.让这个并集和user:1的好友集合做差集;
user:1 user:6 user:7 user:8
4.从差集中去掉自己
user:6 user:7 user:8
5.随机选取推荐好友
15.redis中的sorted set
1.SET是一种非常方便的结构,但是数据无序,redis提供了一个sorted set,每一个添加的值都有一个对应的分数,可以通过这个分数进行排序;sorted set中的排名是按照分组升序排列
2.Sortedset的常用操作:
1.ZADD:添加一个带分数的元素,也可以同时添加多个:
127.0.0.1:6379> zadd myzset 12 “zhangsan”
(integer) 1
127.0.0.1:6379> zadd myzset 2 “lisi”
(integer) 1
127.0.0.1:6379> zadd myzset 10 “zhaoliu”
(integer) 1
127.0.0.1:6379> zadd myzset 8 “wangwu”
(integer) 1
——————————————————
127.0.0.1:6379> zadd myzset 6 “javase” 4 “javaee”
(integer) 2
2.ZCOUNT key min max :给定范围分数的元素个数:
127.0.0.1:6379> zcount myzset 1 10
(integer) 5
3.zrange key start stop:回存储在有序集合key中的指定范围的元素【从小到大排;】
127.0.0.1:6379> zrange myzset 0 -1
- “lisi”
- “javaee”
- “javase”
- “wangwu”
- “zhaoliu”
- “zhangsan”
3.sorted set的使用场景:sorted set算是redis中最有用的一种结构,非常适合用于做海量的数据的排行(比如一个巨型游戏的用户排名);sorted set中所有的方法都建议大家去看一下;sorted set的速度非常快;
示例1.天梯排名:
1.添加初始排名和分数:
2.查询fat在当前ladder中的排名:
3.查询ladder中的前3名:
4.jian增加了20ladder score:
示例2
LRU淘汰最长时间没使用;
LFU淘汰最低使用频率;
16.redis中的hash
1.hashes可以理解为一个map,这个map由一对一对的字段和值组成,所以,可以用hashes来保存一个对象:
2.hashes的常见操作:
1.HSET:给一个hashes添加一个field和value;
127.0.0.1:6379> hset mymap name “zhangsan”
(integer) 1
127.0.0.1:6379> hset mymap age 23
(integer) 1
127.0.0.1:6379> hset mymap address “xian”
(integer) 1
2.HGET可以得到一个hashes中的某一个属性的值:
127.0.0.1:6379> hget mymap address
“xian”
3.HGETALL:一次性取出一个hashes中所有的field和value,使用list输出,一个field,一个value有序输出;
127.0.0.1:6379> HGETALL mymap - “name”
- “zhangsan”
- “age”
- “23”
- “address”
- “xian”
4.HMSET:一次性的设置多个值(hashes multiple set)
127.0.0.1:6379> hmset mymap2 id 1001 name “lisi” age 23 address “xian”
OK
127.0.0.1:6379> hgetall mymap2 - “id”
- “1001”
- “name”
- “lisi”
- “age”
- “23”
- “address”
- “xian”
5.HMGET:一次性的得到多个字段值(hashes multiple get),以列表形式返回;
127.0.0.1:6379> hmget mymap2 name address - “lisi”
- “xian”
6.HINCRBY:给hashes的一个field的value增加一个值(integer),这个增加操作是原子操作
127.0.0.1:6379> hget mymap2 age
“23”
127.0.0.1:6379> HINCRBY mymap2 age 2
(integer) 25
127.0.0.1:6379> hget mymap2 age
“25”
7.HKEYS:得到一个key的所有fields字段,以list返回:
127.0.0.1:6379> hkeys mymap2 - “id”
- “name”
- “age”
- “address”
8.HDEL:删除hashes一个指定的filed;
127.0.0.1:6379> hdel mymap2 age
(integer) 1
127.0.0.1:6379> hget mymap2 age
(nil)
9.HVALS key 得到hashse中的所有值
127.0.0.1:6379> hvals mymap2 - “1001”
- “lisi”
- “xian”
3.使用场景:
1.使用hash来保存一个对象更直观;(建议不使用hash来保存)
2.分组
set user:id 1
set dept:id 1
HMSET ids user:id 1 dept:id 1 orderbill:id 1
HINCRBY ids user:id
HINCRBY ids dept:id
HMSET users user:1 “{id:1,name:xx}” user:2 “{id:2,name:xx}”
17.JAVA中对Redis进行操作
Jedis-Jedis是Redis官方推出的一款面向Java的客户端,提供了很多接口供Java语言调用,方便访问Redis的API
JDBC–官方推出的一款面向Java的客户端,提供了很多接口供Java语言调用,方便访问MySQL.
Redis—java—Jedis API
MySQL—java — JDBC API
Jedis就是访问Redis的API.
由于Jedis访问Redis的时候,比较麻烦【代码多】,所以我们使用Spring Data Redis框架来简化Jedis对Redis的访问。
Spring Data Redis框架
Spring-data-redis是spring大家族的一部分。提供了在srping应用中通过简单的配置访问redis服务,对reids底层开发包(Jedis, JRedis, and RJC)进行了高度封装,RedisTemplate提供了redis各种操作、异常处理及序列化,支持发布订阅,并对spring 3.1 cache进行了实现。
如果我们现在要使用Spring Data Redis框架访问Redis服务器,首先就需要得到RedisTemplate。
spring-data-redis针对jedis提供了如下功能:
1.连接池自动管理,提供了一个高度封装的“RedisTemplate”类
2.针对jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation接口
ValueOperations:简单K-V操作【String】
SetOperations:set类型数据操作【Set】
ZSetOperations:zset类型数据操作[sorted set]
HashOperations:针对map类型的数据操作 【hash】
ListOperations:针对list类型的数据操作【list】
Spring Data Redis入门小Demo
准备工作
(1)构建Maven工程 SpringDataRedisDemo
(2)引入Spring相关依赖、引入JUnit依赖 Jedis和SpringDataRedis依赖
4.0.0
com.click369.test
SpringDataRedisDemo
0.0.1-SNAPSHOT
org.springframework
spring-context
4.2.4.RELEASE
redis.clients
jedis
2.8.1
org.springframework.data
spring-data-redis
1.7.2.RELEASE
(4)在src/main/resources下创建properties文件夹,建立redis-config.properties
redis.host=127.0.0.1
redis.port=6379
redis.pass=
redis.database=0
redis.maxIdle=300
redis.maxWait=3000
redis.testOnBorrow=true
maxIdle :最大空闲数
maxWaitMillis:连接时的最大等待毫秒数
testOnBorrow:在提取一个jedis实例时,是否提前进行验证操作;如果为true,则得到的jedis实例均是可用的;
(5)在src/main/resources下创建spring文件夹 ,创建applicationContext.xml
值【String】类型操作
package test;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations=“classpath:applicationContext.xml”)
public class TestRedis {
@Autowired
private RedisTemplate redisTemplate;
/**
* 操作字符串数据
/
@Test
public void testRedisString(){
//保存String数据到Redis中
//redisTemplate.boundValueOps(“testName”).set(“网星软件”);
//取出指定的键对应的数据值
String value=(String)redisTemplate.boundValueOps(“testName”).get();
System.out.println(“testName==”+value);
//删除String数据
//redisTemplate.delete(“testName”);
}
}
值【Set】类型操作
/*
* Set类型操作
/
@Test
public void testRedisSet(){
//添加数据进入set
//add(Object… values)—可变参数
redisTemplate.boundSetOps(“myset”).add(“曹操”);
redisTemplate.boundSetOps(“myset”).add(“刘备”);
redisTemplate.boundSetOps(“myset”).add(“孙权”);
//提取set中的数据
Set myset=redisTemplate.boundSetOps(“myset”).members();
//遍历set集合
for(Object obj:myset){
String data=(String)obj;
System.out.println(data);
}
System.out.println(“-------------------------------”);
//添加数据进入set
Object names[]={“关羽”,“张飞”,“赵云”,“马超”,“黄忠”};
redisTemplate.boundSetOps(“myname”).add(names);
//{“myname”:[“关羽”,“张飞”,“赵云”,“马超”,“黄忠”]}
//删除set中的值
//remove(value)
//redisTemplate.boundSetOps(“myname”).remove(“赵云”);
//redisTemplate.boundSetOps(“myname”).remove(new Object[]{“马超”,“黄忠”});
//删除所有
redisTemplate.delete(“myname”);
//提取set中的数据
Set myname=redisTemplate.boundSetOps(“myname”).members();
//遍历set集合
for(Object obj:myname){
String data=(String)obj;
System.out.println(data);
}
}
值【List】类型操作
/*
* List类型操作
/
@Test
public void testRedisList(){
//右压栈—后添加的对象排在后边【从右向左压数据】
/
redisTemplate.boundListOps(“mylist1”).rightPush(“许褚”);
redisTemplate.boundListOps(“mylist1”).rightPush(“典韦”);
redisTemplate.boundListOps(“mylist1”).rightPush(“徐晃”);
redisTemplate.boundListOps(“mylist1”).rightPush(“张辽”);
redisTemplate.boundListOps(“mylist1”).rightPush(“夏侯惇”);
//返回存储在 key 的列表里指定范围内的元素
//range(start, end);
//start 和 end 偏移量都是基于0的下标,即list的第一个元素下标是0(list的表头),第二个元素下标是1,以此类推。
//偏移量也可以是负数,表示偏移量是从list尾部开始计数。 例如, -1 表示列表的最后一个元素,-2 是倒数第二个,以此类推。
List mylist1=redisTemplate.boundListOps(“mylist1”).range(0, -1);
for(Object obj:mylist1){
String data=(String)obj;
System.out.println(data);
}
/
//左压栈—后添加的对象排在前边[从左向右压数据]
redisTemplate.boundListOps(“mylist2”).leftPush(“许褚”);
redisTemplate.boundListOps(“mylist2”).leftPush(“典韦”);
redisTemplate.boundListOps(“mylist2”).leftPush(“徐晃”);
redisTemplate.boundListOps(“mylist2”).leftPush(“张辽”);
redisTemplate.boundListOps(“mylist2”).leftPush(“夏侯惇”);
//删除所有
//redisTemplate.delete(“mylist2”);
//根据索引查询元素
//String name=(String)redisTemplate.boundListOps(“mylist2”).index(3);
//System.out.println(“name===”+name);
//从存于 key 的列表里移除前 count 次出现的值为 value 的元素。
//这个 count 参数通过下面几种方式影响这个操作:
//count > 0: 从头往尾移除值为 value 的元素。
//count < 0: 从尾往头移除值为 value 的元素。
//count = 0: 移除所有值为 value 的元素。
Long l=redisTemplate.boundListOps(“mylist2”).remove(-2, “夏侯惇”);
System.out.println(“l===”+l);
List mylist2=redisTemplate.boundListOps(“mylist2”).range(0, -1);
for(Object obj:mylist2){
String data=(String)obj;
System.out.println(data);
}
}
值【Hash】类型操作
实际上就是在Redis这个巨大的Map中在保存一个小map.
最终的形式Map
/
* Hash类型操作
/
@Test
public void testRedisHash(){
//存入数据
/
redisTemplate.boundHashOps(“myhash1”).put(“a”,“唐僧”);
redisTemplate.boundHashOps(“myhash1”).put(“b”,“孙大圣”);
redisTemplate.boundHashOps(“myhash1”).put(“c”,“猪八戒”);
redisTemplate.boundHashOps(“myhash1”).put(“d”,“沙和尚”);
redisTemplate.boundHashOps(“myhash1”).put(“e”,“白龙马”);
/
/
//提取所有的KEY
Set keyset=redisTemplate.boundHashOps(“myhash1”).keys();
for(Object k:keyset){
System.out.println(“key==”+k);
}
//提取所有的VALUE
List valuelist=redisTemplate.boundHashOps(“myhash1”).values();
for(Object v:valuelist){
System.out.println(“value==”+v);
}
System.out.println(“---------------------”);
/
//存入数据
/
Map
m.put(“1”, “java”);
m.put(“2”, “java SE”);
m.put(“3”, “java EE”);
m.put(“4”, “java ME”);
redisTemplate.boundHashOps(“myhash2”).putAll(m);
*/
//提取所有的KEY
Set keyset2=redisTemplate.boundHashOps(“myhash2”).keys();
for(Object k:keyset2){
System.out.println(“key==”+k);
}
//提取所有的VALUE
List valuelist2=redisTemplate.boundHashOps(“myhash2”).values();
for(Object v:valuelist2){
System.out.println(“value==”+v);
}
//根据KEY提取值
String val=(String)redisTemplate.boundHashOps(“myhash2”).get(“2”);
System.out.println(“val==”+val);
//根据KEY移除值
Long l=redisTemplate.boundHashOps(“myhash2”).delete(“3”);
System.out.println(“l==”+l);
}