【C语言】IO流(文件操作)- scanf / printf没那么简单!
本篇文章目录
- 1. 为什么使用文件?
- 2. 什么是文件?
- 3. IO流的概念
- 4. 操作文件的步骤
-
- 文件指针
- 4.1 打开文件和关闭文件
- 4.2 读写文件(顺序读取)
-
- 4.2.1 字符输入输出
- 4.2.2 字符串(文本行)输入输出
- 4.2.3 格式化输入输出
- 4.2.4 二进制输入输出
- 5. C的标准输入输出流
- 6. 指定读取/随机读取
-
- 6.1 对比顺序读取
- 6.2 fseek 根据文件指针偏移量读取
- 6.2 ftell 返回相对起始位置的偏移量
- 6.3 rewind 文件指针回到文件起始位置
- 7. 判定文件读取结束
- 8. 文件缓冲区 & 为什么要有文件缓冲区?
1. 为什么使用文件?
当程序运行时数据是存放在内存中的,如果没有文件,程序退出时操作系统回收内存,那么数据就会丢失,等下次运行程序又要重新录入以往的数据,这样会非常麻烦。理应只有我们自己选择删除数据的时候,数据才不复存在。
这就涉及到了数据持久化的问题,我们一般数据持久化的方法有,把数据存放在磁盘文件、存放到数据库等方式。
注:数据库存储数据,实际上也是存储在磁盘文件上的,只是数据库对这些文件数据的操作做了很高层次的封装,使用起来更方便。
2. 什么是文件?
在程序设计中,我们一般谈的文件有两种(从文件功能的角度来分类的):
-
程序文件:包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境后缀为.exe)。
-
数据文件:件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件,或者输出内容的文件。
一个文件要有一个唯一的文件标识,以便用户识别和引用。
文件名包含3部分:文件路径+文件名主干+文件后缀
例如: c:\code\test.txt
为了方便起见,文件标识常被称为文件名。
3. IO流的概念
IO流即输入流和输出流,输入即“读”数据,输出即“写”数据。流即数据流,可以把数据想象成水一样流动。
流也是一种设计思想。键盘和磁盘是一种外部设备,外部设备也是有很多种的,每种外部设备的读写方式都不一样(如光盘和硬盘),对于程序员而言学会每种读写方式学习成本较高,所以C语言统一实现了这些方式,程序员不需要单独学习外部设备的读写方式。
scanf或printf所处理数据的输入输出都是以终端为对象的,即从终端的键盘输入数据(scanf从内存读取数据),运行结果显示到显示器上(printf输出数据)。
有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理的就是磁盘上文件。
不过文件流操作才是我们该学习的,输入即“从文件读取数据到程序内存”,输出即“把程序内存中数据写入到文件”,简称读数据和写数据。
4. 操作文件的步骤
- 打开文件;
- 读写文件;
- 关闭文件。
文件指针
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,使用者不必关心细节。一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等),这些信息是保存在一个结构体变量中的。不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异。
4.1 打开文件和关闭文件
- 文件在读写之前应该先打开文件,打开文件库函数原型如下:
FILE * fopen ( const char * filename, const char * mode );
- filename表示路径+文件名,路径可以用绝对路径或相对路径。
- mode表示打开方式,是以“读”的方式还是“写”的方式打开。
- 如果文件打开失败返回NULL指针。
文件打开方式:
| 方式 | 含义 |
|---|---|
| “w” | 输出数据到文本文件 |
| “r” | 从文本文件输入数据 |
| “a” | 向文本文件末尾追加数据 |
| “wb” | 输出数据到二进制文件 |
| “rb” | 从二进制文件输入数据 |
| “ab” | 向二进制文件末尾追加数据 |
| “w+” “r+” “a+” “wb+” “rb+” “ab+” | 以读和写的方式打开文件 |
如果以"w" “a” “wb” “w+” “wb+” "ab+"输出数据形式打开文件,如果文件不存在,C会调用系统指令创建这个文件;其余以输入数据形式打开文件方式,如果文件不存在则会报错。
- 文件在使用结束之后应该关闭文件,关闭文件库函数原型如下:
int fclose ( FILE * stream );
文件打开和关闭是一 一对应的,打开一个流,用完了就得把这个流关闭(自带flush操作)。
如果不关闭文件流会造成以下后果:
- 数据可能会丢失;
- 资源浪费,能打开文件流的数量不是无穷的。
4.2 读写文件(顺序读取)
字符、字符行以及格式化输入输出适用于所有输入输出流(无论是文件流还是C的标准输入输出流),二进制输入输出只能用于文件流。
4.2.1 字符输入输出
1. 写一个字符
int fputc ( int character, FILE * stream ); // 函数原型
void Testfputc()
{
// 1.以写文本数据形式打开文件
FILE* pfWrite = fopen("test.txt", "w");
if (pfWrite == NULL)
{
perror("Testfputc");
return;
}
// 2.向文件流写数据
for (int i = 'A'; i <= 'Z'; i++)
{
fputc(i, pfWrite);
}
// 3.关闭文件流
fclose(pfWrite);
pfWrite = NULL;
}
文件路径使用的是相对路径,运行后打开项目文件夹可以看到自动创建了一个test.txt文件,其中已有写入的数据。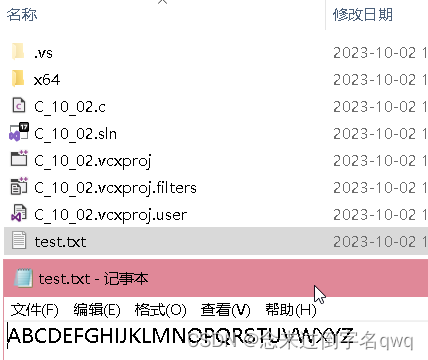
2. 读一个字符:
int fgetc ( FILE * stream ); // 函数原型
fgetc从指定的流中读取数据,一次操作读取一个字符,并且流中的指针指向下一个字符位置。- 如果已经读完了(读到了文件末尾),返回EOF(值为-1,全称end of file)。
void Testfgetc()
{
// 1.以读数据形式打开文件
FILE* pfRead = fopen("test.txt", "r");
if (pfRead == NULL)
{
perror("Testfgetc");
return;
}
// 2.从文件流中读取每个字符并输出到屏幕
int ch;
while ((ch = fgetc(pfRead)) != EOF)
{
printf("%c", ch);
}
// 3.关闭文件流
fclose(pfRead);
pfRead = NULL;
}
4.2.2 字符串(文本行)输入输出
1. 写一行字符串
int fputs ( const char * str, FILE * stream ); // 函数原型
- 写数据不会自动带换行,如果想要一行行写入的效果,字符串中应该带上换行符
'\n'。
void Testfputs()
{
FILE* pfWrite = fopen("test.txt", "w");
if (pfWrite == NULL)
{
perror("Testfputs");
return;
}
// 写
fputs("abc\n", pfWrite);
fputs("def\n", pfWrite);
fclose(pfWrite);
pfWrite = NULL;
}

2. 读一行字符串:
char * fgets ( char * str, int num, FILE * stream ); // 函数原型
- str:读取到的字符串拷贝到str;
- num:指定读取的字符个数;
- 读取失败或读到文件末尾返回NULL指针。
void Testfgets()
{
FILE* pfRead = fopen("test.txt", "r");
if (pfRead == NULL)
{
perror("Testfgets");
return;
}
// 读
char str[30] = { 0 };
while (fgets(str, 10, pfRead) != NULL)
{
printf("%s", str);
}
fclose(pfRead);
pfRead = NULL;
}
读取到每行并输出。
4.2.3 格式化输入输出
1. 写一个带格式化参数的字符串
int fprintf ( FILE * stream, const char * format, ... ); // 函数原型
struct Student
{
char gender;
int age;
char name[20];
};
void Testfprintf(struct Student* s)
{
FILE* pfWrite = fopen("test.txt", "w");
if (pfWrite == NULL)
{
perror("Testfprintf");
return;
}
// 写
fprintf(pfWrite, "%c %d %s", s->gender, s->age, s->name);
fclose(pfWrite);
pfWrite = NULL;
}
int main()
{
struct Student s = {'m', 20, "zhangsan"};
Testfprintf(&s);
return 0;
}

2. 读一个带格式化参数的字符串
int fscanf ( FILE * stream, const char * format, ... ); // 函数原型
void Testfpscanf(struct Student* s)
{
FILE* pfRead = fopen("test.txt", "r");
if (pfRead == NULL)
{
perror("Testfpscanf");
return;
}
// 读,并输出到屏幕
fscanf(pfRead, "%c %d %s", &s->gender, &s->age, s->name);
printf("%c %d %s\n", s->gender, s->age, s->name);
fclose(pfRead);
pfRead = NULL;
}
int main()
{
struct Student s = { 0 };
Testfpscanf(&s);
return 0;
}
4.2.4 二进制输入输出
1. 写二进制数据到文件
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
- ptr:一个有效的指针,且指向的内存地址中有数据,比如一个结构体指针;
- size:一次写多少字节,比如sizeof(结构体);
- count:一次写多少个ptr指向的数据,比如多少个结构体。
void Testfwrite(struct Student* s)
{
FILE* pfWrite = fopen("test.txt", "wb");
if (pfWrite == NULL)
{
perror("Testfwrite");
return;
}
// 写
for (int i = 0; i < 3; i++)
{
fwrite(s, sizeof(struct Student), 1, pfWrite);
}
fclose(pfWrite);
pfWrite = NULL;
}
int main()
{
struct Student s[3] = { {'m', 20, "zhangsan"}, {'m', 21, "lisi"}, {'m', 22, "wangwu"}};
Testfwrite(s);
return 0;
}

由于是二进制数据,记事本打开有些数据乱码也是正常的。
2. 从文件读二进制数据
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
void Testfread(struct Student* s)
{
FILE* pfRead = fopen("test.txt", "rb");
if (pfRead == NULL)
{
perror("Testfread");
return;
}
// 读并打印到屏幕
for (int i = 0; i < 3; i++)
{
fread(s + i, sizeof(struct Student), 1, pfRead);
printf("%c %d %s\n", (s+i)->gender, (s+i)->age, (s+i)->name);
}
fclose(pfRead);
pfRead = NULL;
}
int main()
{
struct Student s[3] = {0};
Testfread(s);
return 0;
}
5. C的标准输入输出流
对任何一个C程序,一旦运行起来就会默认打开三个流:
- 标准输入流:stdin,从键盘缓冲区读取数据;
- 标准输出流:stdout,将数据输出到屏幕;
- 标准错误流:stderr,将错误信息输出到屏幕。
而我们所常用的scanf和printf默认就是使用标准输入输出流,这也是为什么scanf数据会从键盘获取,printf会将数据输出到屏幕。
上面除了二进制文件流以外,其余的输入输出流函数都可以应用所有输入输出流,所以也可以使用stdin和stdout。
如:
int main()
{
// 从键盘获取一个字符(fgetc会返回这个字符),并且输出到屏幕
fputc(fgetc(stdin), stdout);
return 0;
}
6. 指定读取/随机读取
6.1 对比顺序读取
有一个txt文件,文件内容是abcdefg,如果对这个文件一个个字符顺序读取:
int main()
{
FILE* pfRead = fopen("test.txt", "rb");
if (pfRead == NULL)
{
perror("reading test.txt");
return;
}
int ch;
ch = fgetc(pfRead); // a
printf("%c\n", ch);
ch = fgetc(pfRead); // b
printf("%c\n", ch);
ch = fgetc(pfRead); // c
printf("%c\n", ch);
ch = fgetc(pfRead); // d
printf("%c\n", ch);
// ...或循环读也一样
fclose(pfRead);
pfRead = NULL;
return 0;
}
每读一次,文件指针都会指向下一个字符。
6.2 fseek 根据文件指针偏移量读取
int fseek ( FILE * stream, long int offset, int origin );
- offset代表偏移多少个字节;
- origin代表从哪里开始偏移(文件开始、文件指针当前指向位置、文件末尾)。
偏移起始位置分别有三个常量对应:SEEK_SET、SEEK_CUR、SEEK_END。
还是上面那个文件,内容是abcdefg,如果我只想读c和f,怎么读呢?
int main()
{
FILE* pfRead = fopen("test.txt", "rb");
if (pfRead == NULL)
{
perror("reading test.txt");
return;
}
int ch;
fseek(pfRead, 2, SEEK_SET);
ch = fgetc(pfRead); // c
printf("%c\n", ch);
fseek(pfRead, 2, SEEK_CUR); // f
ch = fgetc(pfRead);
printf("%c\n", ch);
fclose(pfRead);
pfRead = NULL;
return 0;
}
从文件开始偏移0个字节也就是字符a,偏移2位就是c;然后这时指针指向下一个字节,也就是字符d,然后从当前指针位置d的位置开始偏移2位,找到f。
6.2 ftell 返回相对起始位置的偏移量
long int ftell ( FILE * stream );
经过上面两次偏移之后:
printf("%d\n", ftell(pfRead)); // 6,也就是g的位置
6.3 rewind 文件指针回到文件起始位置
void rewind ( FILE * stream );
7. 判定文件读取结束
feof和ferror通常配合使用,用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束,也就是写在读文件之后,关闭文件之前。
// ... 读
// 判定具体原因
if (ferror(fp))
puts("I/O error when reading");
else if (feof(fp))
puts("End of file reached successfully");
fclose(fp);
-
如何判定文本文件读取结束?
fgetc读取到文件末尾会返回EOF,判断返回值是否是EOF;fgets读取到文件末尾会返回NULL,判断返回值是否是NULL。
-
如何判定二进制文件读取结束?
fread返回成功/实际读取的个数,判断返回值是否小于要读取个数。
8. 文件缓冲区 & 为什么要有文件缓冲区?
ANSIC 标准采用“缓冲文件系统”处理的数据文件的,系统自动地在内存中为程序中每一个正在使用的文件开辟一块“文件缓冲区”。
比如程序从文件读取数据,读取到的数据实际上是先放在缓冲区,最后缓冲区放满了,或者程序刷新了缓冲区(fflush或者fclose),程序才实际拿到数据。程序向文件写入数据也是一样的,要写入的数据也会先被放入缓冲区,后面才会从缓冲区逐个写入到文件。
缓冲区的大小根据C编译系统决定的,至于为什么要有文件缓冲区,那是因为有了文件缓冲区可以提高程序读写数据的效率。如果每次只读写一点点数据,比如几个字节的数据,操作系统都要帮程序进行读写操作,那太慢了,非常耗费性能!
因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文件。如果不做,可能导致读写文件的问题。