Redis简单动态字符串SDS
目录
前言
一.SDS定义
二.SDS与C字符串的区别
2.1 常数复杂度获取字符串的长度
2.2 杜绝缓冲区溢出
2.3 减少修改字符串时带来的内存重分配次数
2.3.1 空间预分配
2.3.2 惰性空间释放
2.4 二进制安全
2.5 兼容部分C字符串函数
2.6 总结
三.SDS缺点
前言
Redis没有直接使用C语言形式的字符串来表示,而是自己构建了一种名为简单动态字符串的抽象类型SDS(simple dynamic string)。并将SDS作为默认字符串。
在Redis中对于不会进行改变的字符串会使用C字符串,C字符串只会作为字符串字面量来使用。比如使用在打印日志。
举个例子:
在客户端输入命令 SET msg "hello world"
在Redis中会新建一个键值对,其中,键值对的键和值都是字符串类型,底层实现都是用的是SDS。因为键和值都可以进行改变。
处理字用来保存数据库的字符串值之外,SDS还可以被用作缓冲区,AOF模块中的AOF缓冲区,以及客户端状态的输入缓冲区。
一.SDS定义
在redis源码中,在sds.h/sdshdrxx表示不同大小的sds:sdshdrxx会根据字符串的实际长度,选取合适的结构,最大化节省内存空间。
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
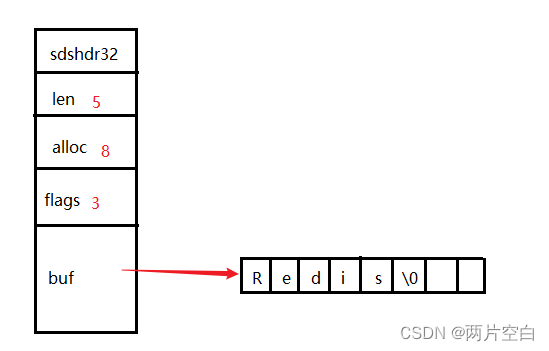
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};__attribute__ ((__packed__)):结构体对象在大小实际不是变量字节的累加,会存在内存对齐的情况。而__attribute__ ((__packed__))是告诉编译器,不需要进行内存对齐。
变量:
- len:记录buf数组中已使用字节数,等于SDS保存字符串长度,不包含'\0'。
- alloc:记录buf数组总共分配的内存大小,不包含'\0'。
- flags:记录当前字节数组的属性,使用的哪一个结构。前3位记录使用的SDS结构,后5位在sdshdr5中记录字符串长度。在其他结构中没有使用。
//flag定义
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7 //按位与,得到flags的低3位
#define SDS_TYPE_BITS 3 //用于右移动flags得到高5位。
//用来定义对应T结构SDS变量,s一般是buf的起始地址
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
//用来得到对应T结构SDS变量,s一般是buf的起始地址
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
//得到sdshdr5字符串长度
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)- buf:保存真正的字符串的值,以及最后一个'\0'。
SDS遵循C字符串以空字符结尾,保存空字符的一字节空间不计算在SDS的len里面,并且为空字符分配1字节的额外空间,以及添加空字符到字符串结尾等操作都是SDS自动完成的。
在SDS以空字符串结尾的好处是,可以使用C字符串里面的函数。
二.SDS与C字符串的区别
2.1 常数复杂度获取字符串的长度
因为C字符串并不记录自身的长度信息,所以获取一个C字符串的长度需要遍历整个字符串,知对遇到的每一个字符进行计数,知道遇到空字符串为止。时间复杂度为O(N)。
由于SDS在len字段记录了本身的长度,所以获取SDS字符串的长度复杂度为O(1)。
2.2 杜绝缓冲区溢出
C字符串使用C字符串函数进行拼接字符串时,当字符串的空间不够保存拼接的字符串,容易造成缓冲区溢出,还可能会修改其他字符串。
所以在进行C字符串拼接时,需要程序员判断空间是否够保存拼接的字符串。不够需要开辟足够的空间。
而SDS杜绝了缓冲区溢出的可能。在使用SDS API进行字符串拼接操作时。API会先检查SDS的剩余空间(alloc - len)是否满足修改的需求,通常会调用 sds.c/sdsMakeRoomFor 方法对 SDS 的剩余容量进行检查。不满足,API会自动将SDS的空间扩展到需要的大小,最后再进行修改操作。判断空间是否满足和修改SDS空间的大小都是SDS API自动完成的。
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t usable;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
reqlen = newlen = (len+addlen);
assert(newlen > len); /* Catch size_t overflow */
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
sdssetalloc(s, usable);
return s;
}2.3 减少修改字符串时带来的内存重分配次数
由于C字符串并不记录自身长度。在每次进行增长和缩短C字符串,程序总需要对这个C字符串进行一次内存重分配:
- 如果程序执行的是增长操作,那么在执行前,需要先进行内存重分配来扩展底层数组空间,否则会造成缓冲区溢出。
- 如果程序执行的是截断的操作,操作之后需要释放原来不使用的空间,否则会造成内存泄漏。
因为内存分配涉及复杂的算法,并且需要执行系统调用,所以它通常是一个比较耗时的操作。但是Redis作为数据库,经常被用于速度要求严苛,数据会被频繁修改的场合。如果每次修改字符串都需要重新分配内存,会对Redis的性能照成影响。
为了避免,Redis记录了字符串的长度和底层数组的长度。
2.3.1 空间预分配
空间预分配用于优化SDS的字符串增长操作。当SDS的API需要对底层数组进行空间扩展时,程序不仅会为SDS分配必须要的空间,还会分配额外未使用的空间。这样如果下一次增长字符串长度在剩余空间内,就不需要重新分配空间了。有效减少了空间分配次数。
分配策略:
- 当进行修改后,SDS的长度,也就是len的值小于1MB,那么程序会为SDS分配与拼接后的len值同样大小的未使用空间。即alloc-len = len。比如:进行拼接后SDS的len变成了13字节,那么程序也会分配13字节的未使用空间。SDS数组长度变成了13+13+1=27字节,最后一个字节保存空字符。
- 当进行修改后,SDS的长度,也就是len的值大于等于1MB,那么程序会分配1MB的未使用空间。比如:进行拼接后SDS的len变成了30MB,实际SDS的长度变成了30MB+1MB+1byte大小。
2.3.2 惰性空间释放
惰性空间释放用于优化SDS的字符串缩短操作。当SDS缩短保存的字符串时,程序并不立即使用内存重新分配回收缩短多出来的字节,而是修改len值,剩余的空间可以为之后拼接字符串使用。
通过惰性空间释放,即能避免缩短字符串的内存重新分配,还可以为将来的增长操作提供优化。
于此同时SDS也提供了API,让我们在有需要的时候,释放SDS未使用空间。
2.4 二进制安全
C字符串的字符必须符合某种编码,并且由于C字符串是以空字符串结尾的,中间如果出现空字符,会被当做字符串结尾。导致后面的字符被省略。使得C字符串只能保存文本数据,而不能保存图像,音频,视频,压缩文件等二进制文件。
而Redis的SDS的API是二进制安全的,所以API都会以处理二进制的方式来处理buf中的数据,程序不会对其中的数据做任何限制,过滤或者假设。数据在写入时什么样,读取时就什么样。
由于SDS使用的时len来保存字符串长度,支持了二进制安全的实现。Redis不仅可以保存文本数据,还可以保存任何格式的二进制数据。
2.5 兼容部分C字符串函数
虽然SDS是二进制安全的,但是它仍然遵循C字符串以空字符串结尾的管理。即API会自动在分配空间时,为空字符串分配一个空间,并且会在SDS保存的数据末尾设置空字符串。
这是为了让那些保存文本数据的SDS可以重用部分
2.6 总结
| C字符串 | SDS |
| 获取字符串长度时间复杂度O(N) | 获取字符串长度时间复杂度O(1) |
| API不安全,可能造成缓冲区溢出 | API安全,不会造成缓冲区溢出 |
| 修改字符串长度N此必然需要进行N次内存重新分配 | 修改字符串长度N此最多需要进行N次内存重新分配 |
| 只能保存文本数据 | 可以保存文本和二进制数据 |
| 可以使用所有 |
可以使用部分 |
三.SDS缺点
从SDS结构可以看出,SDS除了保存字符串,还需要保存其他的数据入长度,空间大小,标记等。所以SDS的一个缺点是占内存。典型的一个用空间来换时间的结构。