Page Cache引起的业务问题处理
在工作中,你可能遇见过与 Page Cache 有关的场景,比如:
- 服务器的 load 飙高;
- 服务器的 I/O 吞吐飙高;
- 业务响应时延出现大的毛刺;
- 业务平均访问时延明显增加。
这些问题,很可能是由于 Page Cache 管理不到位引起的,因为 Page Cache 管理不当除了会增加系统 I/O 吞吐外,还会引起业务性能抖动,我在生产环境上处理过很多这类问题。
什么是 Page Cache?

通过这张图片你可以清楚地看到,红色的地方就是 Page Cache,很明显,Page Cache 是内核管理的内存,也就是说,它属于内核不属于用户。
那咱们怎么来观察 Page Cache 呢?其实,在 Linux 上直接查看 Page Cache 的方式有很多,包括 /proc/meminfo、free 、/proc/vmstat 命令等,它们的内容其实是一致的。我们可以通过 /proc/meminfo 看一下:
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...
当然了,有的人可能会说,内核的 Page Cache 这么复杂,我不要不可以么?如果不用内核管理的 Page Cache,那有两种思路来进行处理:
- 第一种,应用程序维护自己的 Cache 做更加细粒度的控制,比如 MySQL 就是这样做的,你可以参考MySQL Buffer Pool ,它的实现复杂度还是很高的。对于大多数应用而言,实现自己的 Cache 成本还是挺高的,不如内核的 Page Cache来得简单高效。
- 第二种,直接使用 Direct I/O 来绕过 Page Cache,不使用 Cache了。这种方法可行么?那我们继续用数据说话,看看这种做法的问题在哪儿?
为什么需要 Page Cache
我们看一个具体的例子。首先,我们来生成一个 1G 大小的新文件,然后把 Page Cache 清空,确保文件内容不在内存中,以此来比较第一次读文件和第二次读文件耗时的差异。具体的流程如下。
先生成一个 1G 的文件:
dd if=/dev/zeroof=/home/jian/test/dd.outbs=4096count=((1024*256))
其次,清空 Page Cache,需要先执行一下 sync 来将脏同步到磁盘再去 drop cache:
sync && echo 3 > /proc/sys/vm/drop_caches
第一次读取文件的耗时如下:
$ time cat /home/jian/test/dd.out &> /dev/null
real 0m5.733s
user 0m0.003s
sys 0m0.213s
再次读取文件的耗时如下:
$ time cat /home/jian/test/dd.out &> /dev/null
real 0m0.132s
user 0m0.001s
sys 0m0.130s
通过这样详细的过程你可以看到,第二次读取文件的耗时远小于第一次的耗时,这是因为第一次是从磁盘来读取的内容,磁盘 I/O 是比较耗时的,而第二次读取的时候由于文件内容已经在第一次读取时被读到内存了,所以是直接从内存读取的数据,内存相比磁盘速度是快很多的。这就是 Page Cache 存在的意义:减少 I/O,提升应用的 I/O 速度。所以,如果你不想为了很细致地管理内存而增加应用程序的复杂度,那你还是乖乖使用内核管理的 Page Cache 吧,它是 ROI(投入产出比) 相对较高的一个方案。
Page Cache 是如何“诞生”的?
Page Cache 的产生有两种不同的方式:
- Buffered I/O(标准 I/O);
- Memory-Mapped I/O(存储映射 I/O)。
这两种方式分别都是如何产生 Page Cache 的呢?来看下面这张图:
对于存储映射 I/O 而言,则是直接将 Pagecache Page 给映射到用户地址空间,用户直接读写 Pagecache Page 中内容。而标准 I/O 是写的用户缓冲区,然后再将用户缓冲区里的数据拷贝到内核缓冲区 ;如果是读的 话则是先从内核缓冲区拷贝到用户缓冲区,再从用户缓冲区读数据,也就是 buffer 和文件内容不存在任何映射关系。显然,存储映射 I/O 要比标准 I/O 效率高一些,毕竟少了“用户空间到内核空间互相拷贝”的过程。这也是很多应用开发者发现,为什么使用内存映射 I/O 比标准 I/O 方式性能要好一些的主要原因。
到这里,我们知道IO会产生page cache ,具体过程参考下图:
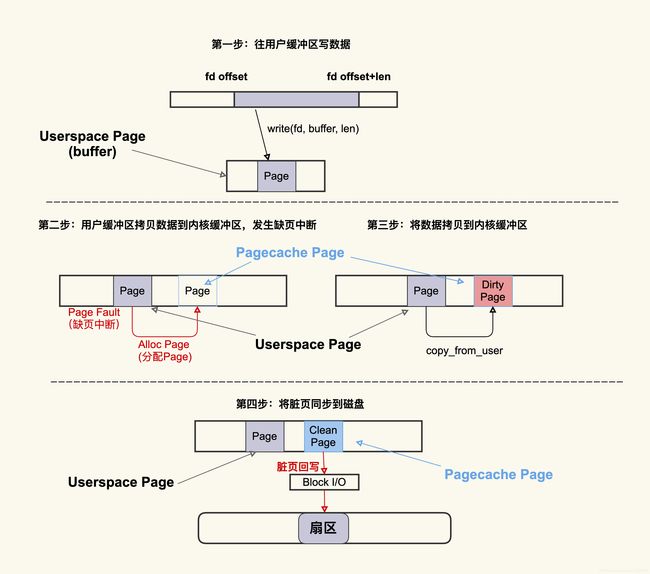
这个过程大致可以描述为:首先往用户缓冲区 buffer(这是 Userspace Page) 写入数据,然后 buffer 中的数据拷贝到内核缓冲区(这是 Pagecache Page),如果内核缓冲区中还没有这个 Page,就会发生 Page Fault 会去分配一个 Page,拷贝结束后该 Pagecache Page 是一个 Dirty Page(脏页),然后该 Dirty Page 中的内容会同步到磁盘,同步到磁盘后,该 Pagecache Page 变为 Clean Page 并且继续存在系统中。
Page Cache 是如何“死亡”的?
你可以把 Page Cache 的回收行为 (Page Reclaim) 理解为 Page Cache 的“自然死亡”。言归正传,我们知道,服务器运行久了后,系统中 free 的内存会越来越少,用 free 命令来查看,大部分都会是 used 内存或者 buff/cache 内存,比如说下面这台生产环境中服务器的内存使用情况:
$ free -g
total used free shared buff/cache available
Mem: 125 41 6 0 79 82
Swap: 0 0 0
free 命令中的 buff/cache 中的这些就是“活着”的 Page Cache,那它们什么时候会“死亡”(被回收)呢?我们来看一张图:

你可以看到,应用在申请内存的时候,即使没有 free 内存,只要还有足够可回收的 Page Cache,就可以通过回收 Page Cache 的方式来申请到内存,回收的方式主要是两种:直接回收和后台回收。
直接内存回收会引起 load 飙高或者业务时延抖动
直接内存回收是指在进程上下文同步进行内存回收,那么它具体是怎么引起 load 飙高的呢?因为直接内存回收是在进程申请内存的过程中同步进行的回收,而这个回收过程可能会消耗很多时间,进而导致进程的后续行为都被迫等待,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起 load 飙高。我们详细地描述一下这个过程,为了尽量不涉及太多技术细节,我会用一张图来表示,这样你理解起来会更容易:

从图里你可以看到,在开始内存回收后,首先进行后台异步回收(上图中蓝色标记的地方),这不会引起进程的延迟;如果后台异步回收跟不上进程内存申请的速度,就会开始同步阻塞回收,导致延迟(上图中红色和粉色标记的地方,这就是引起 load 高的地址),如果直接内存回收过程中遇到了正在往慢速 I/O 设备回写的 page,就可能导致非常大的延迟。。
到这里,我们知道直接回收内存会影响到我们的业务,那么,针对直接内存回收引起 load 飙高或者业务 RT 抖动的问题,一个解决方案就是及早地触发后台回收来避免应用程序进行直接内存回收,那具体要怎么做呢?
控制脏页数量
那如何解决这类问题呢?一个比较省事的解决方案是控制好系统中积压的脏页数据。很多人知道需要控制脏页,但是往往并不清楚如何来控制好这个度,脏页控制的少了可能会影响系统整体的效率,脏页控制的多了还是会触发问题,所以我们接下来看下如何来衡量好这个“度”。
dwj@dwj-pc:~$ sar -r 1
Linux 4.4.0-189-generic (dwj-pc) 2021年03月03日 _x86_64_ (4 CPU)
17时36分14秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
17时36分15秒 303940 7701584 96.20 2361872 1828552 7338972 26.21 3061600 2395712 784
17时36分16秒 303376 7702148 96.21 2361872 1828560 7338972 26.21 3061612 2395712 816
平均时间: 303658 7701866 96.21 2361872 1828556 7338972 26.21 3061606 2395712 800
dwj@dwj-pc:~$ ^C
dwj@dwj-pc:~$
kbdirty 就是系统中的脏页大小,它同样也是对 /proc/vmstat 中 nr_dirty 的解析。你可以通过调小如下设置/proc/sys/vm的以下参数来将系统脏页个数控制在一个合理范围:
dirty_background_bytes = 0
dirty_background_ratio = 10
dirty_bytes = 0
dirty_expire_centisecs = 3000
dirty_ratio = 20
调整这些配置项有利有弊,调大这些值会导致脏页的积压,但是同时也可能减少了 I/O 的次数,从而提升单次刷盘的效率;调小这些值可以减少脏页的积压,但是同时也增加了 I/O 的次数,降低了 I/O 的效率。
Page Cache回收导致的问题
Page Cache 太容易回收而引起的一些问题:
- 误操作而导致 Page Cache 被回收掉,进而导致业务性能下降明显;
- 内核的一些机制导致业务 Page Cache 被回收,从而引起性能下降。
我们先从一个相对简单的案例说起,一起分析下误操作导致 Page Cache 被回收掉的情况,它具体是怎样发生的。
我们知道,对于 Page Cache 而言,是可以通过 drop_cache 来清掉的,很多人在看到系统中存在非常多的 Page Cache 时会习惯使用 drop_cache 来清理它们,但是这样做是会有一些负面影响的,比如说这些 Page Cache 被清理掉后可能会引起系统性能下降。
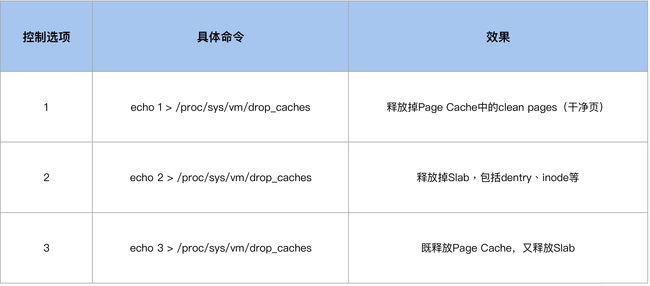
在系统内存紧张的时候,运维人员或者开发人员会想要通过 drop_caches 的方式来释放一些内存,但是由于他们清楚 Page Cache 被释放掉会影响业务性能,所以就期望只去 drop slab 而不去 drop pagecache。于是很多人这个时候就运行 echo 2 > /proc/sys/vm/drop_caches,但是结果却出乎了他们的意料:Page Cache 也被释放掉了,业务性能产生了明显的下降。
由于 drop_caches 是一种内存事件,内核会在 /proc/vmstat 中来记录这一事件,所以我们可以通过 /proc/vmstat 来判断是否有执行过 drop_caches。
$ grep drop /proc/vmstat
drop_pagecache 3
drop_slab 2
如何避免 Page Cache 被回收而引起的性能问题?
我们在分析一些问题时,往往都会想这个问题是我的模块有问题呢,还是别人的模块有问题。也就是说,是需要修改我的模块来解决问题还是需要修改其他模块来解决问题。与此类似,避免 Page Cache 里相对比较重要的数据被回收掉的思路也是有两种:
- 从应用代码层面来优化
- 从系统层面来调整
从应用程序代码层面来解决是相对比较彻底的方案,因为应用更清楚哪些 Page Cache 是重要的,哪些是不重要的,所以就可以明确地来对读写文件过程中产生的 Page Cache 区别对待。比如说,对于重要的数据,可以通过 mlock来保护它,防止被回收以及被 drop;对于不重要的数据(比如日志),那可以通过 madvise告诉内核来立即释放这些 Page Cache。我们来看一个通过 mlock来保护重要数据防止被回收或者被 drop 的例子:
#include 在有些情况下,对应用程序而言,修改源码是件比较麻烦的事,如果可以不修改源码来达到目的那就最好不过了。Linux 内核同样实现了这种不改应用程序的源码而从系统层面调整来保护重要数据的机制,这个机制就是 memory cgroup protection。它大致的思路是,将需要保护的应用程序使用 memory cgroup 来保护起来,这样该应用程序读写文件过程中所产生的 Page Cache 就会被保护起来不被回收或者最后被回收。memory cgroup protection 大致的原理如下图所示:

如上图所示,memory cgroup 提供了几个内存水位控制线 memory.{min, low, high, max} 。
- memory.max这是指 memory cgroup 内的进程最多能够分配的内存,如果不设置的话,就默认不做内存大小的限制。
- memory.high如果设置了这一项,当 memory cgroup 内进程的内存使用量超过了该值后就会立即被回收掉,所以这一项的目的是为了尽快的回收掉不活跃的 Page Cache。
- memory.low这一项是用来保护重要数据的,当 memory cgroup 内进程的内存使用量低于了该值后,在内存紧张触发回收后就会先去回收不属于该 memory cgroup 的 Page Cache,等到其他的 Page Cache 都被回收掉后再来回收这些 Page Cache。
- memory.min这一项同样是用来保护重要数据的,只不过与 memoy.low 有所不同的是,当 memory cgroup 内进程的内存使用量低于该值后,即使其他不在该 memory cgroup 内的 Page Cache 都被回收完了也不会去回收这些 Page Cache,可以理解为这是用来保护最高优先级的数据的。
那么,如果你想要保护你的 Page Cache 不被回收,你就可以考虑将你的业务进程放在一个 memory cgroup 中,然后设置 memory.{min,low} 来进行保护;与之相反,如果你想要尽快释放你的 Page Cache,那你可以考虑设置 memory.high 来及时的释放掉不活跃的 Page Cache。
Linux 问题的典型分析手段
我们可以利用内核预置的相关 tracepoint 来做细致的分析。

我们继续以内存规整 (memory compaction) 为例,来看下如何利用 tracepoint 来对它进行观察:
#首先来使能compcation相关的一些tracepoing
$ echo 1 > /sys/kernel/debug/tracing/events/compaction/mm_compaction_begin/enable
$ echo 1 > /sys/kernel/debug/tracing/events/compaction/mm_compaction_end/enable
#然后来读取信息,当compaction事件触发后就会有信息输出
$ cat /sys/kernel/debug/tracing/trace_pipe
<...>-49355 [037] .... 1578020.975159: mm_compaction_begin:
zone_start=0x2080000 migrate_pfn=0x2080000 free_pfn=0x3fe5800
zone_end=0x4080000, mode=async
<...>-49355 [037] .N.. 1578020.992136: mm_compaction_end:
zone_start=0x2080000 migrate_pfn=0x208f420 free_pfn=0x3f4b720
zone_end=0x4080000, mode=async status=contended