python中print的本质_python数据分析、挖掘常用工具,让你看到不一样的数据分析...
Python语言:
简要概括一下Python语言在数据分析、挖掘场景中常用特性:
- 列表(可以被修改),元组(不可以被修改)
- 字典(结构)
- 集合(同数学概念上的集合)
- 函数式编程(主要由lambda()、map()、reduce()、filter()构成)
Python数据分析常用库:
Python资源共享群:626017123
Python数据挖掘相关扩展库
NumPy
提供真正的数组,相比Python内置列表来说速度更快,NumPy也是Scipy、Matplotlib、Pandas等库的依赖库,内置函数处理数据速度是C语言级别的,因此使用中应尽量使用内置函数。
示例:NumPy基本操作
import numpy as np # 一般以np为别名a = np.array([2, 0, 1, 5])print(a)print(a[:3])print(a.min())a.sort() # a被覆盖print(a)b = np.array([[1, 2, 3], [4, 5, 6]])print(b*b)输出:
[2 0 1 5][2 0 1]0[0 1 2 5][[ 1 4 9] [16 25 36]]Scipy
NumPy和Scipy让Python有了MATLAB味道。Scipy依赖于NumPy,NumPy提供了多维数组功能,但只是一般的数组并不是矩阵。比如两个数组相乘时,只是对应元素相乘。Scipy提供了真正的矩阵,以及大量基于矩阵运算的对象与函数。
Scipy包含功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解等常用计算。
示例:Scipy求解非线性方程组和数值积分
# 求解方程组from scipy.optimize import fsolvedef f(x): x1 = x[0] x2 = x[1] return [2 * x1 - x2 ** 2 - 1, x1 ** 2 - x2 - 2]result = fsolve(f, [1, 1])print(result)# 积分from scipy import integratedef g(x): # 定义被积函数 return (1 - x ** 2) ** 0.5pi_2, err = integrate.quad(g, -1, 1) # 输出积分结果和误差print(pi_2 * 2, err)输出:
[ 1.91963957 1.68501606]3.141592653589797 1.0002356720661965e-09Matplotlib
Python中著名的绘图库,主要用于二维绘图,也可以进行简单的三维绘图。
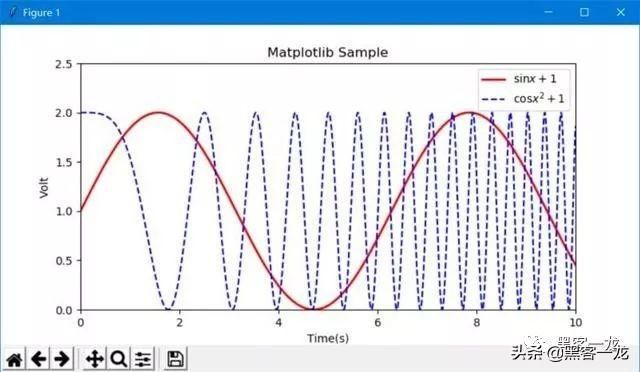
示例:Matplotlib绘图基本操作
import matplotlib.pyplot as pltimport numpy as npx = np.linspace(0, 10, 10000) # 自变量x,10000为点的个数y = np.sin(x) + 1 # 因变量yz = np.cos(x ** 2) + 1 # 因变量zplt.figure(figsize=(8, 4)) # 设置图像大小# plt.rcParams['font.sans-serif'] = 'SimHei' # 标签若有中文,则需设置字体# plt.rcParams['axes.unicode_minus'] = False # 保存图像时若负号显示不正常,则添加该句# 两条曲线plt.plot(x, y, label='$sin (x+1)$', color='red', linewidth=2) # 设置标签,线条颜色,线条大小plt.plot(x, z, 'b--', label='$cos x^2+1$')plt.xlim(0, 10) # x坐标范围plt.ylim(0, 2.5) # y坐标范围plt.xlabel("Time(s)") # x轴名称plt.ylabel("Volt") # y轴名称plt.title("Matplotlib Sample") # 图的标题plt.legend() # 显示图例plt.show() # 显示作图结果输出:
Pandas
Pandas是Python下非常强大的数据分析工具。它建立在NumPy之上,功能很强大,支持类似SQL的增删改查,并具有丰富的数据处理函数,支持时间序列分析功能,支持灵活处理缺失数据等。
Pandas基本数据结构是Series和DataFrame。Series就是序列,类似一维数组,DataFrame则相当于一张二维表格,类似二维数组,它每一列都是一个Series。为定位Series中的元素,Pandas提供了Index对象,类似主键。
DataFrame本质上是Series的容器。
示例:Pandas简单操作
import pandas as pds = pd.Series([1, 2, 3], index=['a', 'b', 'c'])d = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]], columns=['a', 'b', 'c'])d2 = pd.DataFrame(s)print(s)print(d.head()) # 预览前5行print(d.describe())# 读取文件(路径最好别带中文)df=pd.read_csv("G:data.csv