java性能优化(JVM调优+Tomcat调优+数据库调优+代码优化)

JVM运行时数据区

HotSpot内存布局:

程序计数器

堆

虚拟机栈

本地方法栈
类似Java虚拟机栈,与Java虚拟机区别在于:服务对象,即Java虚拟机栈为执行 Java 方法服务;本地方法栈为执行 Native方法服务
方法区

其内部包含一个运行时常量池,具体介绍如下

调优工具:
- Jconsole,jdk自带,可以在系统有一定的负荷的情况下使用,对垃圾回收算法有很详细的跟踪
- JProfiler,收费工具
- VisualVM,JDK自带,与JProfiler功能类似,分析dump文件
- Mat(Eclipse工具专门姬姓静态内存分析工具)适用于大文件
调优目的:减少GC的频率和FullGC的次数
会对整个堆进行整理,包括Young、Tenured和Perm。
Full GC因为需要对整个堆进行回收,所以比较慢,因此应该尽可能减少Full GC的次数。
导致Full GC的原因:
1)年老代(Tenured)被写满
调优时尽量让对象在新生代GC时被回收、让对象在新生代多存活一段时间和不要创建过大的对象及数组避免直接在旧生代创建对象 。
2)持久代Pemanet Generation空间不足
增大Perm Gen空间,避免太多静态对象 , 控制好新生代和旧生代的比例
3)System.gc()被显示调用
垃圾回收不要手动触发,尽量依靠JVM自身的机制
判断是否需要优化
- GC事件时间超过1-3秒,或者频繁GC,必须优化
- Minor GC执行时间不到50ms;Minor GC执行不频繁,约10秒一次;Full GC执行时间不到1s;Full GC执行频率不算频繁,不低于10分钟1次;则不需要优化
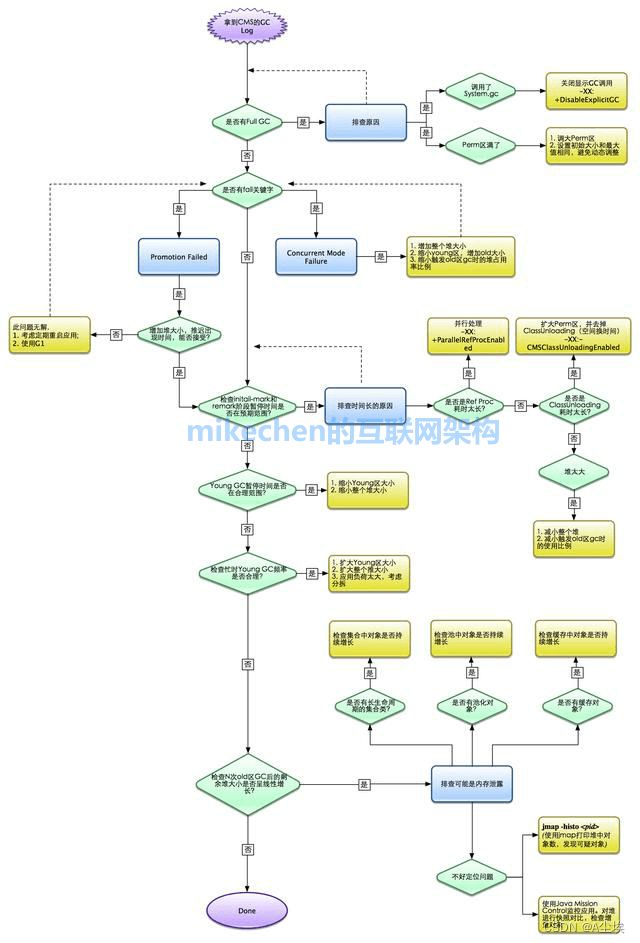
JVM调优
堆内存调优参数
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -Xmn:新生代大小
- -XX:NewRatio:新生代和老年代的比例
- -XX:SurvivorRatio:Eden区和Survivor区的比例
GC调优参数
- -XX:+UseSerialGC:使用串行垃圾回收器
- -XX:+UseParallelGC:使用并行垃圾回收器
- -XX:+UseConcMarkSweepGC:使用GMS垃圾回收器
- -XX:UseG1GC:使用G1垃圾回收器
- -XX:MaxGCPauseMillis:最大GC停顿时间
- -XX:+UseAdaptiveSizePolicy:自适应GC策略
线程调优参数
- -Xss:每个线程的堆栈大小
- -XX:ParallelThreads:并行处理的线程数
- -XX:+UseThreadPriorities:启用线程优先级
- -XX:+UseCondCardMark:使用条件卡片标记
类加载调优参数
- -XX:MaxPermSize:最大方法区大小
- -XX:+CMSClassUnloadingEnabled:启用CMS类卸载
- -XX:+UseCompressedOops:使用压缩对象指针
其他调优参数
-XX:+UseBiasedLocking:启用偏向锁
-XX:+OptimizeStringConcat:启用字符串拼接优化
-XX:MaxTenuringThreshold:对象晋升老年代的年龄阈值
-XX:CompileThreshold:JIT编译阈值
-XX:+PrintGCDetails:打印GC详细信息
1.针对JVM堆的设置,一般可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,通常把最大、最小设置为相同的值。
2.年轻代和年老代将根据默认的比例(1:2)分配堆内存, 可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代。
3.年轻代和年老代设置多大才算合理
1)更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
2)更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
项目背景:高 QPS 压力的 web 服务,单机 QPS 一直维持在 1.5K 以上,配置的堆大小是 8G,其中 young 区是 4G,垃圾回收器用的是 parNew + CMS
首先是查看当前 GC 的情况,主要是使用 jstat 查看 GC 的概况,再查看 gc log,分析单次 gc 的详细状况
使用 jstat -gcutil pid 1000 每隔一秒打印一次 gc 统计信息

S0: 新生代中Survivor space 0区已使用空间的百分比
S1: 新生代中Survivor space 1区已使用空间的百分比
E: 新生代已使用空间的百分比
O: 老年代已使用空间的百分比
P: 永久带已使用空间的百分比
YGC: 从应用程序启动到当前,发生Yang GC 的次数
YGCT: 从应用程序启动到当前,Yang GC所用的时间【单位秒】
FGC: 从应用程序启动到当前,发生Full GC的次数
FGCT: 从应用程序启动到当前,Full GC所用的时间
GCT: 从应用程序启动到当前,用于垃圾回收的总时间【单位秒】
接着查看 gc log,打印 gc log 需要在 JVM 启动参数里添加以下参数:
-XX:+PrintGCDateStamps:打印 gc 发生的时间戳。
-XX:+PrintTenuringDistribution:打印 gc 发生时的分代信息。
-XX:+PrintGCApplicationStoppedTime:打印 gc 停顿时长
-XX:+PrintGCApplicationConcurrentTime:打印 gc 间隔的服务运行时长
-XX:+PrintGCDetails:打印 gc 详情,包括 gc 前/内存等。
-Xloggc:…/gclogs/gc.log.date:指定 gc log 的路径

分析和调整
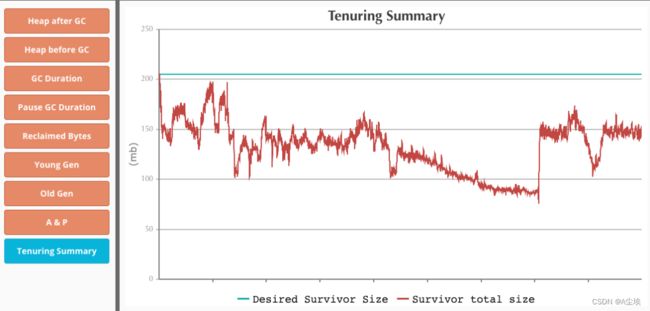
YGC 频繁,借用一些可视化工具来帮助我们分析, gceasy 是个挺不错的网站,我们把 gc log 上传上去后, gceasy 可以帮助我们生成各个维度的图表帮助分析。
查看 gceasy 生成的报告,发现我们服务的 gc 吞吐量是 95%,它指的是 JVM 运行业务代码的时长占 JVM 总运行时长的比例,这个比例确实有些低了,运行 100 分钟就有 5 分钟在执行 gc。幸好这些 GC 中绝大多数都是 YGC,单次时长可控且分布平均,这使得我们服务还能平稳运行。
解决这个问题要么是减少对象的创建,要么就增大 young 区。前者不是一时半会儿都解决的,需要查找代码里可能有问题的点,分步优化。而后者虽然改一下配置就行,但以我们对 GC 最直观的印象来说,增大 young 区,YGC 的时长也会迅速增大。
YGC 的耗时是由 GC 标记 + GC 复制 组成的,相对于 GC 复制,GC 标记是非常快的。而 young 区内大多数对象的生命周期都非常短,如果将 young 区增大一倍,GC 标记的时长会提升一倍,但到 GC 发生时被标记的对象大部分已经死亡, GC 复制的时长肯定不会提升一倍,所以我们可以放心增大 young 区大小,堆大小调整到了 12G,young 区保留为 8G。
分代调整
GC 太频繁之外,GC 后各分代的平均大小也需要调整
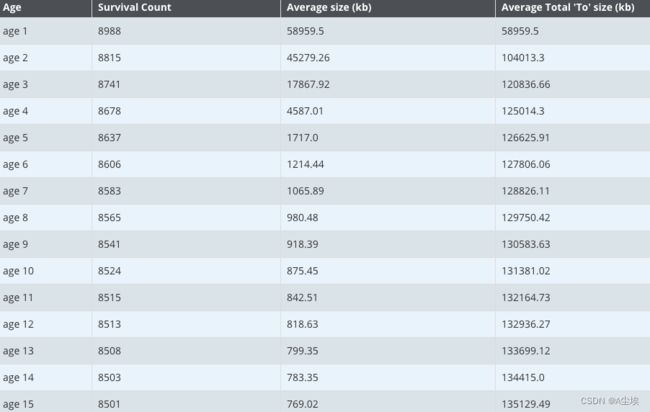
MaxTenuringThreshold 的对象提升到老年代
JVM 还有动态年龄计算的规则:按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值,但看各代总的内存大小,是达不到 survivor 区的一半的
所以这十五个分代内的对象会一直在两个 survivor 区之间来回复制,再观察各分代的平均大小,可以看到,四代以上的对象已经有一半都会保留到老年区了,所以可以将这些对象直接提升到老年代,以减少对象在两个 survivor 区之间复制的性能开销。
所以我把 MaxTenuringThreshold 的值调整为 4,将存活超过四代的对象直接提升到老年代。
偏向锁停顿
还有一个问题是 gc log 里有很多 18ms 左右的停顿,有时候连续有十多条,虽然每次停顿时长不长,但连续多次累积的时间也非常可观。
1.8 之后 JVM 对锁进行了优化,添加了偏向锁的概念,避免了很多不必要的加锁操作,但偏向锁一旦遇到锁竞争,取消锁需要进入 safe point,导致 STW。
解决方式很简单,JVM 启动参数里添加 -XX:-UseBiasedLocking 即可。
结果:
调整完 JVM 参数后先是对服务进行压测,发现性能确实有提升,也没有发生严重的 GC 问题,之后再把调整好的配置放到线上机器进行灰度,同时收集 gc log,再次进行分析。
由于 young 区大小翻倍了,所以 YGC 的频率减半了,GC 的吞量提升到了 97.75%。平均 GC 时长略有上升,从 60ms 左右提升到了 66ms,还是挺符合预期的。
由于 CMS 在进行 GC 时也会清理 young 区,CMS 的时长也受到了影响,CMS 的最终标记和并发清理阶段耗时增加了,也比较正常。
另外我还统计了对业务的影响,之前因为 GC 导致超时的请求大大减少了。
数据库调优
一、SQL调优:主要集中在索引、减少跨表与大数据join查询
二、数据端架构设计(读写分离、分库分表解决数据库连接池瓶颈问题)
三、连接池调优(通过具体的连接池监控数据)
四、通过缓存
数据量小,并且不会频繁地增长又清空(这会导致频繁地垃圾回收),那么可以选择本地缓存
如果需要策略支持(比如缓存满的逐出策略)考虑使用Ehcache,如果不需要,可以考虑HashMap
如果需要考虑多线程并发,使用ConcurentHashMap
① 给缓存服务,选择合适的缓存逐出算法,比如最常见的LRU。
② 针对当前设置的容量,设置适当的警戒值,比如10G的缓存,当缓存数据达到8G的时候,就开始发出报警,提前排查问题或者扩容。
③ 给一些没有必要长期保存的key,尽量设置过期时间。
Web网站性能优化
一、尽可能减少HTTP请求:图片合并(css sprites),Js脚本文件合并、CSS文件合并
二、减少DNS查询
三、将css放在页面最上面,将js放在页面最下面
四、压缩js和css,减少文件体积,去除不必要的空白符、格式符、注释
五、把js和css提取出来放在外部文件中
六、避免重定向,会增加服务器和浏览器之间的往返次数
重定向状态码:301永久重定向 302临时重定向 304 not modified并不是真的重定向,告诉浏览器get请求的文件在缓存中,避免重新下载
七、使用Gzip压缩
八、使用CDN(内容分发网络)
九、数据请求改为异步
额外开辟线程或使用线程池,在IO线程处理之外的线程处理响应的任务,在IO线程中让response先返回
如果异步线程处理的任务设计的数量巨大,可以引入阻塞队列BlockingQueue作进一步优化
使用消息队列MQ,MQ天生就是异步的
===============================================================
代码优化
- 抽取公用方法
- 抽个工具类
- 反射
- 泛型
- 继承和多态
- 设计模式
- 函数式Lambda
- AOP切面
一、抽取公用方法
public class TianLuoExample{
public static void main(){
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "TianLuo");
System.out.println("Uppercase Names:");
for (String name : names) {
String uppercaseName = name.toUpperCase();
System.out.println(uppercaseName);
}
System.out.println("Lowercase Names:");
for (String name : names) {
String lowercaseName = name.toLowerCase();
System.out.println(lowercaseName);
}
}
}
显然,都是遍历names过程,代码是重复冗余的,只不过转化大小写不一样而已。
抽个公用方法processNames,优化成这样:
Function
public class TianLuoExample{
public static void processNames(List<String> names,Function<String,String> ameProcessor,String processType){
System.out.println(processType + " Names:")
for(String name:names){
String processedName = nameProcessor.apply(name);
System.out.println(processName);
}
}
public static void main(String[] args){
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "TianLuo");
processNames(names,String::toUpperCase,"Uppercase");
processNames(names,String::toLowerCase,"Lowercase");
}
}
二、抽工具类
抽一个公用方法后,如果发现这个方法有更多共性,就可以把公用方法升级为一个工具类。比如这样的业务场景:注册,修改邮箱,重置密码等,都需要校验邮箱
实现注册功能时,用户会填邮箱,需要验证邮箱格式
public class RegisterServiceImpl implements RegisterService{
private static final String EMAIL_REGEX = "^[A-Za-z0-9+_.-]+@(.+)$";
public boolean registerUser(UserInfoReq userInfo){
String email = userInfo.getEmail();
Pattern pattern = Pattern.compile(EMAIL_REGEX);
Matcher emailMatcher = pattern.matcher(email);
if(!emailMatcher.matches()){
System.out.println("Invalid email address.");
return false;
}
// 进行其他用户注册逻辑,比如保存用户信息到数据库等
// 返回注册结果
return true;
}
}
在密码重置流程中,通常会向用户提供一个链接或验证码,并且需要发送到用户的电子邮件地址。在这种情况下,也需要验证邮箱格式合法性:
public class PasswordServiceImpl implements PasswordService{
private static final String EMAIL_REGEX =
"^[A-Za-z0-9+_.-]+@(.+)$";
public void resetPassword(PasswordInfo passwordInfo) {
Pattern pattern = Pattern.compile(EMAIL_REGEX);
Matcher emailMatcher = pattern.matcher(passwordInfo.getEmail());
if (!emailMatcher.matches()) {
System.out.println("Invalid email address.");
return false;
}
//发送通知修改密码
sendReSetPasswordNotify();
}
}
对于上面的重复性验证,抽取一个校验工具
public class EmailValidatorUtil{
private static final String EMAIL_REGEX = "^[A-Za-z0-9+_.-]+@(.+)$";
private static final Pattern pattern = Pattern.compile(EMAIL_REGEX);
public static boolean isValid(String email){
Matcher matcher = pattern.matcher(email);
return matcher.matches();
}
}
注册的代码可以简化
public class RegisterServiceImpl implements RegisterService{
public boolean registerUser(UserInfoReq userInfo){
if(!EmailValidatorUtil.isValid(userInfo.getEmail())){
System.out.println("Invalid email address.");
return false;
}
// 进行其他用户注册逻辑,比如保存用户信息到数据库等
// 返回注册结果
return true;
}
}
三、反射
需要进行PO、DTO和VO的转化
//DTO 转 VO
public UserInfoVO convert(UserInfoDTO userInfoDTO){
UserInfoVO userInfoVO = new UserInfoVO();
userInfoVo.setUserName(userInfoDTO.getUserName());
userInfo.setAge(uerInfoDTP.getAge());
return userInfoVO;
}
//PO 转 DTO
public UserInfoDTO convert(UserInfoPO userInfoPO){
UserInfoDTO userInfoDTO = new UserInfoDTO();
userInfoDTO.setUserName(userInfoPO.getUserName());
userInfoDTO.setAge(userInfoPO.getAge());
return userInfoDTO;
}
可以使用BeanUtils.copyProperties() 去除重复代码
BeanUtils.copyProperties()底层就是使用了反射:
public UserInfoVO convert(UserInfoDTO userInfoDTO){
UserInfoVO userInfoVO = new UserInfoVO();
BeanUtils.copyProperties(userInfoDTO,userInfoVO)
return userInfoVO;
}
public UserInfoDTO convert(UserInfoPO userInfoPO) {
UserInfoDTO userInfoDTO = new UserInfoDTO();
BeanUtils.copyProperties(userInfoPO,userInfoDTO);
return userInfoDTO;
}
四、泛型
转账明细
这两块代码,流程功能看着很像,但是就是不能直接合并抽取一个公用方法,因为类型不一致。
private void getAndUpdateBalanceResultMap(String key,Map<String,List<TransferBalanceDTO>> compareResultListMap,List<TransferBalanceDTO> balanceDTOs){
List<TransferBalanceDTO> tempList = compareResultListMap.getOrDefault(key, new ArrayList<>());
tempList.addAll(balanceDTOs);
compareResultListMap.put(key, tempList);
}
private void getAndUpdateDetailResultMap(String key, Map<String, List<TransferDetailDTO>> compareResultListMap,
List<TransferDetailDTO> detailDTOS) {
List<TransferDetailDTO> tempList = compareResultListMap.getOrDefault(key, new ArrayList<>());
tempList.addAll(detailDTOS);
compareResultListMap.put(key, tempList);
}
单纯类型不一样的话,我们可以结合泛型处理,因为泛型的本质就是参数化类型.优化为这样:
private <T> void getAndUpdateResultMap(String key,Map<String,List<T>> compareResultListMap, List<T> accountingDTOS){
List<T> tempList = compareResultListMap.getOrDefault(key, new ArrayList<>());
tempList.addAll(accountingDTOS);
compareResultListMap.put(key, tempList);
}
五、继承与多态
开发一个电子商务平台,需要处理不同类型的订单,例如普通订单和折扣订单
每种订单都有一些共同的属性(如订单号、购买商品列表)和方法(如计算总价、生成订单报告),但折扣订单还有特定的属性和方法。
//普通订单
public class Order{
private String orderNumber;
private List<Product> products;
public double calculateTotalPrice() {
double total = 0;
for (Product product : products) {
total += product.getPrice();
}
return total;
}
public String generateOrderReport() {
return "Order Report for " + orderNumber + ": Total Price = $" + calculateTotalPrice();
}
}
//折扣订单
public class DiscountOrder {
private String orderNumber;
private List<Product> products;
private double discountPercentage;
public DiscountOrder(String orderNumber, List<Product> products, double discountPercentage) {
this.orderNumber = orderNumber;
this.products = products;
this.discountPercentage = discountPercentage;
}
public double calculateTotalPrice() {
double total = 0;
for (Product product : products) {
total += product.getPrice();
}
return total - (total * discountPercentage / 100);
}
public String generateOrderReport() {
return "Order Report for " + orderNumber + ": Total Price = $" + calculateTotalPrice();
}
}
使用继承和多态去除重复代码,让DiscountOrder去继承Order
public class Order{
private String orderNumber
private List<Product> products;
public Order(String orderNumber, List<Product> products) {
this.orderNumber = orderNumber;
this.products = products;
}
public double calculateTotalPrice() {
double total = 0;
for (Product product : products) {
total += product.getPrice();
}
return total;
}
public String generateOrderReport() {
return "Order Report for " + orderNumber + ": Total Price = $" + calculateTotalPrice();
}
}
//折扣订单继承普通订单
public class DiscountOrder extends Order {
private double discountPercentage;
public DiscountOrder(String orderNumber, List<Product> products, double discountPercentage) {
super(orderNumber, products);
this.discountPercentage = discountPercentage;
}
@Override
public double calculateTotalPrice() {
double total = super.calculateTotalPrice();
return total - (total * discountPercentage / 100);
}
}
六、使用设计模式
https://editor.csdn.net/md/?articleId=128459370
七、自定义注解或AOP切面
开发一个Web应用程序,需要对不同的Controller方法进行权限检查。
每个Controller方法都需要进行类似的权限验证,但是重复的代码会导致代码的冗余和维护困难
public class MyController{
public void viewData(){
if(!User.hasPermission("read")){
throw new SecurityException("Insufficient permission to access this resource.");
}
//Method implementation
}
public void modifyData(){
if (!User.hasPermission("write")) {
throw new SecurityException("Insufficient permission to access this resource.");
}
// Method implementation
}
}
每个需要权限校验的方法中都需要重复编写相同的权限校验逻辑,即出现了重复代码.我们使用自定义注解的方式能够将权限校验逻辑集中管理,通过切面来处理,消除重复代码
@Aspect
@Component
public class PermissionAspect{
@Before("@annotation(requiresPermission)")
public void checkPermission(RequiresPermisssion requiresPermission){
String permission = requiresPermission.value();
if (!User.hasPermission(permission)) {
throw new SecurityException("Insufficient permission to access this resource.");
}
}
}
public class MyController {
@RequiresPermission("read")
public void viewData() {
// Method implementation
}
@RequiresPermission("write")
public void modifyData() {
// Method implementation
}
}
不管多少个Controller方法需要进行权限检查,你只需在方法上添加相应的注解即可。权限检查的逻辑在切面中集中管理,避免了在每个Controller方法中重复编写相同的权限验证代码。
八、函数式接口和Lambda表达式
根据不同的条件来过滤一组数据
public class DataFilter {
public List<Integer> filterPositiveNumbers(List<Integer> numbers) {
List<Integer> result = new ArrayList<>();
for (Integer number : numbers) {
if (number > 0) {
result.add(number);
}
}
return result;
}
public List<Integer> filterEvenNumbers(List<Integer> numbers) {
List<Integer> result = new ArrayList<>();
for (Integer number : numbers) {
if (number % 2 == 0) {
result.add(number);
}
}
return result;
}
}
通过函数式接口进行过滤
public class DataFilter{
public List<Integer> filterNumbers(List<Integer> numbers,Predicate<Integer> predicate){
List<Integer> result = new ArrayList<>();
for(Integer number:numbers){
if(predicate.test(number)){
result.add(number);
}
}
return result;
}
}
将过滤的核心逻辑抽象出来。该方法接受一个 Predicate函数式接口作为参数,以便根据不同的条件来过滤数据。然后,我们可以使用Lambda表达式来传递具体的条件