004-MYSQL练习——子查询+组合查询内容
一、子查询
select c_id from deposite where b_id='B0004';
select salary from customer where c_id in(101002,101003,101004);
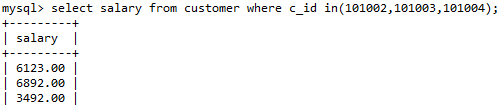
等同于
select salary from customer where c_id in(select c_id from deposite where b_id='B0004');
二、联结
多表查询会有重复的数据出现,没有确定关联性,只是单纯的拼接,需要用join on 的语句进行查询链接
将两个表中相同的字段作为筛选条件,最后跟上对应的具体条件
join相当于等号
where customer.c_id=deposite.c_id——只筛选2个表相同的内容
where customer.c_id=deposite.c_id(+)——显示deposite表中所有的内容,可能会有空的情况
where customer.c_id(+)=deposite.c_id——显示customer表中所有的内容,可能会有空的情况
例如:查询ID101006下的所有账户的相关信息
select * from deposite
join customer using(c_id)
join bank using(b_id)
where c_id='101006';
// join using 替代了join on——join on的语句
//要完整写出customer.c_id=deposite.c_id,用using更加简化
select * from deposite,customer,bank
where deposite.c_id=customer.c_id and bank.b_id=deposite.b_id and c_id='101006';

select * from deposite,bank where deposite.b_id=bank.b_id order by bank_name;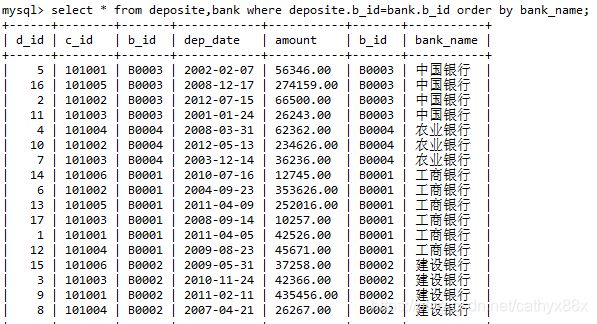
要避免出现‘笛卡尔积’的情况——没有联结条件的表的结果,导致多出很多其他的数据
多个查询练习:
查询日期为2011-04-05这一天进行过存款的客户ID,客户姓名,银行名称,存款金额

查询工商银行存款大于等于一万的客户
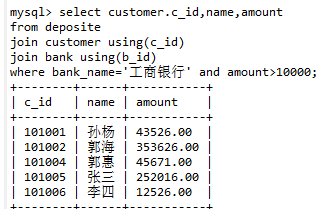
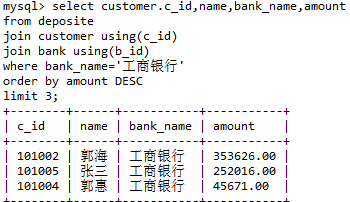
查询在工商银行存款前3名的客户存款信息
——实际工商银行共有6位用户存款,需要筛选出前3(使用amount进行降序排行DESC,在返回前3行limit )
查询所有账户的内容(没有筛选条件)
多个函数结合查询——例如找出amount最大的账户的信息,若是使用MAX函数,则如下:

简单的可以用order by DESC然后limit
三、组合查询
UNION——相同的列、表达式或聚集函数,2条以上的select语句,之间都必须有单独的一个union
UNION ALL——不会剔除重复值,可多表可单表
(若是在这样过的组合中使用order by等排序,即时在最后出现,也是对整个搜索进行排序)
例子:表1存2017年收入,表2存2018年收入,有月份(201X0X),收入两列,求两年的收入明细
——思路:列出2017年和2018年的月份和收入,用UNION ALL进行合并
select month,income from tab1
union all
select month,income from tab2;
若是要计算总和,则可以使用:
select sum(income) from(
select month,income from tab1 union all
select month,income from tab2) t;
//对于派生出的表,是需要随便给个别名t即可(如果是oracle就不需要)
1、核算表里面的列
select *,(c_id+amount) as sum from deposite order by c_id;