考拉解析
实用指南(A Practical Guide)
Pandas is considered a de-facto data analysis library written in python. Most of the data scientists or machine learning engineers start with Pandas and Numpy before moving to other libraries. No once can debate around the use of Pandas as a standard data processing library. There are a lot of benefits of using Pandas however one key bottleneck of Pandas API to adapt with distributed processing. Solutions like Modin and Dask solve this problem to some extent.
P andas被认为是用python编写的事实数据分析库。 大多数数据科学家或机器学习工程师都先从Pandas和Numpy开始,然后才转移到其他图书馆。 关于将熊猫作为标准数据处理库的使用,没有人可以争论过。 使用Pandas有很多好处,但是Pandas API的一个关键瓶颈就是要适应分布式处理。 像Modin和Dask这样的解决方案在某种程度上解决了这个问题。
When it comes to using distributed processing frameworks, Spark is the de-facto choice for professionals and large data processing hubs. Recently, Databricks’s team open-sourced a library called Koalas to implemented the Pandas API with spark backend. This library is under active development and covering more than 60% of Pandas API. To read more about using Koalas, refer to my earlier article Spark-ifying Pandas: Databrick’s Koalas with Google Colab.
在使用分布式处理框架时,Spark是专业人士和大型数据处理中心的实际选择。 近日,Databricks的团队开源的一个名为库树熊来实现的火花后端大熊猫API。 该库正在积极开发中,涵盖了熊猫API的60%以上。 要了解有关使用Koalas的更多信息,请参阅我之前的文章Spark-ifying Pandas:带有Google Colab的Databrick的Koalas 。
In this tutorial, I will walk you through to perform exploratory data analysis using Koalas and PySpark to build a regression model using the Spark distributed framework. There are a lot of benefits of using Koalas instead of Pandas API when dealing with large datasets. Some of the key points are
在本教程中,我将指导您使用Koalas和PySpark执行探索性数据分析,以使用Spark分布式框架构建回归模型。 处理大型数据集时,使用Koalas代替Pandas API有很多好处。 一些关键点是
- Big data processing made easy大数据处理变得容易
- Quick transformation from Pandas to Koalas从熊猫快速转变为考拉
- Integration with PySpark is seamless与PySpark的集成是无缝的
The objective of this tutorial is to leverage the Spark backend for a complete machine learning development cycle using Koalas. The working google collaboratory will be embedded.
本教程的目的是利用Spark后端使用Koalas进行完整的机器学习开发周期。 可以使用的Google合作实验室将被嵌入。
在Google合作实验室中设置Spark 3.0.1 (Setting up Spark 3.0.1 in the Google Colaboratory)
As a first step, I configure the google colab runtime with spark installation. For details, readers may read my article Getting Started Spark 3.0.0 in Google Colab om medium.
第一步,我使用spark安装配置google colab运行时。 有关详细信息,读者可以阅读我在Google Colab om介质中的文章Spark 3.0.0入门。
We will install the below programs
我们将安装以下程序
- Java 8Java 8
- spark-3.0.1 星火3.0.1
- Hadoop3.2 Hadoop3.2
Findspark
Findspark
you can install the LATEST version of Spark using the below set of commands.
您可以使用以下命令集安装最新版本的Spark。
# Run below commands
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q http://apache.osuosl.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz
!tar xf spark-3.0.1-bin-hadoop3.2.tgz
!pip install -q findspark环境变量 (Environment Variable)
After installing the spark and Java, set the environment variables where Spark and Java are installed.
安装spark和Java之后,设置环境变量安装Spark和Java的位置。
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.0.1-bin-hadoop3.2"火花安装测试 (Spark Installation test)
Let us test the installation of spark in our google colab environment.
让我们在Google colab环境中测试spark的安装。
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
# Test the spark
df = spark.createDataFrame([{"hello": "world"} for x in range(1000)])
df.show(3, False)/content/spark-3.0.1-bin-hadoop3.2/python/pyspark/sql/session.py:381: UserWarning: inferring schema from dict is deprecated,please use pyspark.sql.Row instead
warnings.warn("inferring schema from dict is deprecated,"
+-----+
|hello|
+-----+
|world|
|world|
|world|
+-----+
only showing top 3 rows安装考拉 (Install Koalas)
After installing spark and making sure, it is working, we can now install the databrick’s Koalas using pip.
在安装spark并确保它可以正常工作之后,我们现在可以使用pip安装databrick的Koalas。
! pip install koalasRequirement already satisfied: koalas in /usr/local/lib/python3.6/dist-packages (1.2.0)
Requirement already satisfied: numpy<1.19.0,>=1.14 in /usr/local/lib/python3.6/dist-packages (from koalas) (1.18.5)
Requirement already satisfied: matplotlib<3.3.0,>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from koalas) (3.2.2)
Requirement already satisfied: pyarrow>=0.10 in /usr/local/lib/python3.6/dist-packages (from koalas) (0.14.1)
Requirement already satisfied: pandas<1.1.0,>=0.23.2 in /usr/local/lib/python3.6/dist-packages (from koalas) (1.0.5)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib<3.3.0,>=3.0.0->koalas) (2.4.7)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib<3.3.0,>=3.0.0->koalas) (0.10.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib<3.3.0,>=3.0.0->koalas) (1.2.0)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib<3.3.0,>=3.0.0->koalas) (2.8.1)
Requirement already satisfied: six>=1.0.0 in /usr/local/lib/python3.6/dist-packages (from pyarrow>=0.10->koalas) (1.15.0)
Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas<1.1.0,>=0.23.2->koalas) (2018.9)
Requirement already satisfied: pyarrow in /usr/local/lib/python3.6/dist-packages (0.14.1)
Requirement already satisfied: numpy>=1.14 in /usr/local/lib/python3.6/dist-packages (from pyarrow) (1.18.5)
Requirement already satisfied: six>=1.0.0 in /usr/local/lib/python3.6/dist-packages (from pyarrow) (1.15.0)# Install compatible version of pyarrow
! pip install pyarrowimport seaborn as sns/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tmimport databricks.koalas as ks机器学习开发周期 (Machine Learning Development Cycle)
The standard practice for developing machine learning models is to perform the exploratory data analysis, perform feature engineering, and build a model. I will try to touch basis on the above point using Koalas. I believe most of the ML engineers/scientists use Pandas API to perform EDA and Feature engineering. I demonstrate the use of Koalas to do the job and use PySpark to build the model.
开发机器学习模型的标准做法是执行探索性数据分析,执行特征工程和构建模型。 我将尝试使用考拉触及以上几点。 我相信大多数ML工程师/科学家都使用Pandas API来执行EDA和功能工程。 我演示了使用Koalas来完成这项工作并使用PySpark构建模型。
I will use the Combined Cycle Power Plant data set to predict the net hourly electrical output (EP). I have uploaded the data to my GitHub so that users can reproduce the results.
我将使用联合循环电厂数据集来预测每小时的净电力输出(EP)。 我已将数据上传到我的GitHub,以便用户可以重现结果。
使用Koalas进行探索性数据分析 (Exploratory Data Analysis using Koalas)
As a first step, I want to explore the given data, its distribution, and dependency using Koalas API. I will include a simple example to demonstrate the idea, users can extend it for the problem in-hand.
第一步,我想使用Koalas API探索给定的数据,其分布和依赖性。 我将提供一个简单的示例来演示该想法,用户可以将其扩展用于解决问题。
Download the data and saved it locally
下载数据并保存在本地
# Downloading the clustering dataset
!wget -q 'https://raw.githubusercontent.com/amjadraza/blogs-data/master/spark_ml/ccpp.csv'Read the data using the Koalas read_csv method. To read more about the API follow the Koalas official documentation
使用read_csv方法读取数据。 要了解有关API的更多信息,请遵循Koalas官方文档
# Read the iris data
kdf_ccpp = ks.read_csv("ccpp.csv")kdf_ccpp.columnsIndex(['AT', 'V', 'AP', 'RH', 'PE'], dtype='object')kdf_ccpp.head()
Just like Pandas, Koalas has a feature to plot data to understand the variables. In the below example, I plotted the original data and smoother versions of it. This example demonstrates the use of plot and rolling window methods
就像熊猫一样,考拉也具有绘制数据以了解变量的功能。 在下面的示例中,我绘制了原始数据和更平滑的版本。 本示例演示了plot和rolling窗口方法的使用
kdf_ccpp['AT'].plot(figsize=(12,6))
kdf_ccpp['AT'].rolling(window=20).mean().plot()
kdf_ccpp['AT'].rolling(window=200).mean().plot()
Just like the above plotting, users can plot all the columns. See below command
就像上面的绘图一样,用户可以绘制所有列。 见下面的命令
kdf_ccpp.plot(figsize=(12,6))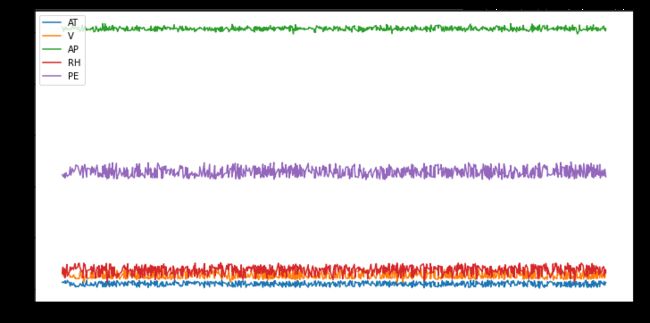
Plotting all columns using a moving average of 20 data points.
使用20个数据点的移动平均值绘制所有列。
kdf_ccpp.rolling(window=20).mean().plot(figsize=(12,6))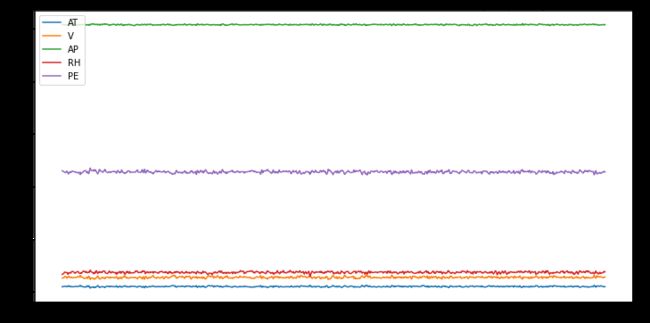
The below command is to demonstrate the use of describe a method similar to in Pandas API.
下面的命令演示了describe方法的使用,该方法类似于Pandas API。
kdf_ccpp.describe()
特征工程(Feature Engineering)
The feature engineering step usually comes in junction with EDA. Users prepare the features with an objective to have the most predictive and nicely distributed feature set. In this article, I will demonstrate the use of Koalas to perform feature engineering.
特征工程步骤通常与EDA结合在一起。 用户以目标为特征来准备特征,以使其具有最可预测的且分布最均匀的特征集。 在本文中,我将演示如何使用Koalas进行特征工程。
To understand the relationship between different variables, paiprplot function seaborn is widely used. Use the below command to plot the pairplot of variables in the dataset. Since Seaborn does not support the Koala dataframe, users have to convert it into a pandas dataframe before calling pairplot.
为了理解不同变量之间的关系,广泛使用了paiprplot函数seaborn 。 使用以下命令在数据集中绘制变量对图。 由于Seaborn不支持Koala数据框,因此用户必须在调用pairplot之前将其转换为pandas数据框。
sns.pairplot(kdf_ccpp.to_pandas())
By looking at the above figure, we can see a lot of outliers and for some variable relationship with Target is not clear. To remove the outliers, the simplest solution is to calculate the moving average and I demonstrate that using Koalas.
通过查看上图,我们可以看到很多异常值,并且与目标之间的某些可变关系尚不清楚。 要消除异常值,最简单的解决方案是计算移动平均线,而我演示了如何使用考拉。
sns.pairplot(kdf_ccpp.rolling(window=20).mean().to_pandas())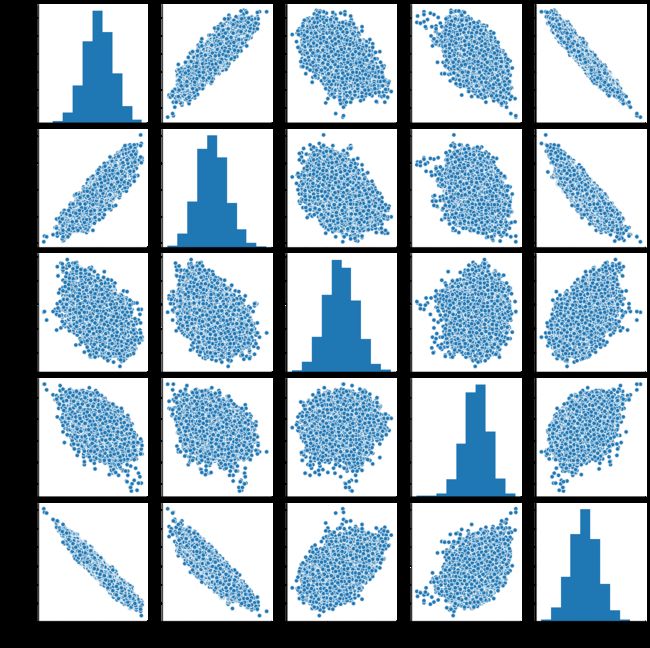
Looks like the 20-day moving average has a better relationship with the Target variable hence using the 20-day average features makes more sense.
看起来20天移动平均线与目标变量具有更好的关系,因此使用20天移动平均线更有意义。
使用PySpark建立模型 (Model Building using PySpark)
Once the EDA and Feature engineering done, it is time to build the predictive model. One of the benefits of using the Koalas dataframe is that users can create a Spark dataframe seamlessly. In the below section, I demonstrate the use of PySpark API to build and train Gradient Boosting Machines (GBM).
一旦完成了EDA和功能工程,就可以构建预测模型了。 使用Koalas数据框的好处之一是用户可以无缝创建Spark数据框。 在以下部分中,我将演示如何使用PySpark API来构建和训练Gradient Boosting Machines(GBM)。
# Create the moving average features
kdf = kdf_ccpp.rolling(window=20, min_periods=1).mean()# Convert the Koalas DataFrame into Spark DataFrame
sdf = kdf.to_spark()sdf.show(5,False)+------------------+------+------------------+-----------------+-----------------+
|AT |V |AP |RH |PE |
+------------------+------+------------------+-----------------+-----------------+
|14.96 |41.76 |1024.07 |73.17 |463.26 |
|20.07 |52.36 |1022.055 |66.125 |453.815 |
|15.083333333333334|48.04 |1018.7566666666667|74.79666666666667|465.3966666666667|
|16.5275 |50.36 |1016.6275 |75.2575 |460.6675 |
|15.386000000000001|47.788|1015.1479999999999|79.53 |463.314 |
+------------------+------+------------------+-----------------+-----------------+
only showing top 5 rowsNow, build the model using PySpark API. For more details on building models using PySpark refer to my article Machine Learning With Spark.
现在,使用PySpark API构建模型。 有关使用PySpark构建模型的更多详细信息,请参阅我的文章《使用Spark进行机器学习》 。
from pyspark.ml.regression import LinearRegression
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.regression import GBTRegressorPrepare the features compatible with PySpark models
准备与PySpark模型兼容的功能
# Create the feature column using VectorAssembler class
vectorAssembler = VectorAssembler(inputCols =["AT", "V", "AP", "RH"], outputCol = "features")
vpp_sdf = vectorAssembler.transform(sdf)vpp_sdf.show(2, False)+-----+-----+--------+------+-------+-----------------------------+
|AT |V |AP |RH |PE |features |
+-----+-----+--------+------+-------+-----------------------------+
|14.96|41.76|1024.07 |73.17 |463.26 |[14.96,41.76,1024.07,73.17] |
|20.07|52.36|1022.055|66.125|453.815|[20.07,52.36,1022.055,66.125]|
+-----+-----+--------+------+-------+-----------------------------+
only showing top 2 rowsCreate the tarin and test splits
创建tarin并测试拆分
# Define train and test data split
splits = vpp_sdf.randomSplit([0.7,0.3])
train_df = splits[0]
test_df = splits[1]Build and train the model
建立和训练模型
# Define the GBT Model
gbt = GBTRegressor(featuresCol="features", labelCol="PE")
gbt_model = gbt.fit(train_df)
gbt_predictions = gbt_model.transform(test_df)Evaluate the model accuracy
评估模型准确性
# Evaluate the GBT Model
gbt_evaluator = RegressionEvaluator(labelCol="PE", predictionCol="prediction", metricName="rmse")
gbt_rmse = gbt_evaluator.evaluate(gbt_predictions)
print("The RMSE of GBT Tree regression Model is {}".format(gbt_rmse))The RMSE of GBT Tree regression Model is 1.077464978110743Converting prediction back to Koalas DataFrame
将预测转换回Koalas DataFrame
kdf_predictions = ks.DataFrame(gbt_predictions)kdf_predictions.head()
Let us plot the actual and predictions from the model.
让我们绘制模型的实际和预测。
kdf_predictions[['PE', 'prediction']].plot(figsize=(12,8))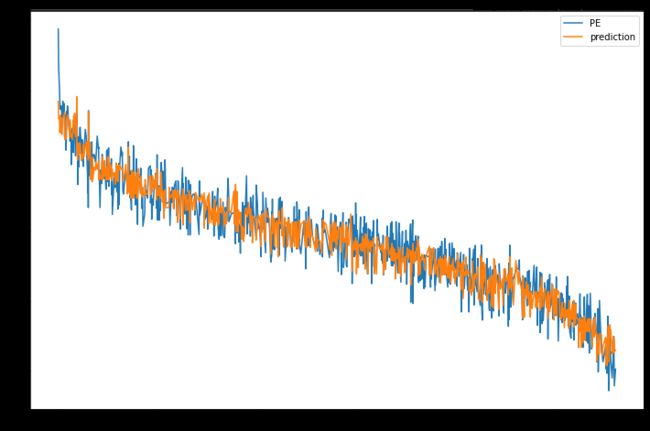
运作中的Google Colab(A working Google Colab)
Below is the working google colab notebook to recreate the tutorial. Give it a try and develop machine learning algorithms on top of the presented use of Koalas as Pandas replacement where possible.
以下是可正常使用的Google colab笔记本,用于重新创建该教程。 在可能的情况下,尝试使用考拉作为熊猫的替代品来开发机器学习算法。
结论 (Conclusions)
In this tutorial, I have demonstrated the use of Koalas to perform exploratory data analysis and feature engineering. For Pandas users, switching to Koalas is straight forward with the benefit of using Spark backend for distributed computations. Below the key points discussed
在本教程中,我演示了如何使用Koalas进行探索性数据分析和特征工程。 对于Pandas用户而言,使用Spark后端进行分布式计算的好处是可以直接切换到Koalas。 下面讨论的重点
- Koalas use to perform EDA考拉用来执行EDA
- Feature Engineering using Koalas 使用考拉进行特征工程
- PySpark integration with KoalasPySpark与Koalas集成
参考读物/链接(References Readings/Links)
https://spark.apache.org/docs/latest/ml-features.html
https://spark.apache.org/docs/latest/ml-features.html
https://koalas.readthedocs.io/en/latest/?badge=latest
https://koalas.readthedocs.io/en/latest/?badge=latest
https://towardsdatascience.com/machine-learning-with-spark-f1dbc1363986
https://towardsdatascience.com/machine-learning-with-spark-f1dbc1363986
https://medium.com/analytics-vidhya/getting-started-spark3-0-0-with-google-colab-9796d350d78
https://medium.com/analytics-vidhya/getting-started-spark3-0-0-with-google-colab-9796d350d78
https://medium.com/analytics-vidhya/spark-ifying-pandas-databricks-koalas-with-google-colab-93028890db5
https://medium.com/analytics-vidhya/spark-ifying-pandas-databricks-koalas-with-google-colab-93028890db5
翻译自: https://towardsdatascience.com/koalas-ml-4807f2c56e98
考拉解析