python爬虫---百度翻译的爬取及可视化
实现的效果
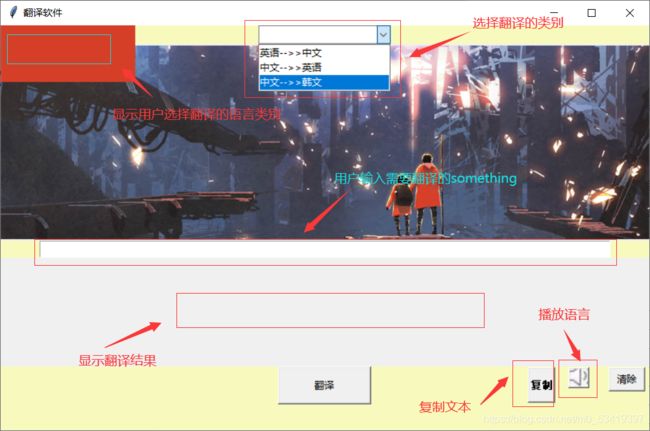
可视化界面由于作者的审美有限,所以有点丑,但是还是讲究可以看一下,主要的功能没有改变,博友们也可以根据自己的喜好改变一下。
原理

这里我们使用百度翻译网页,对上面的翻译内容进行爬取,至于音频,我们也可以将其爬取下来,并进行本地保存和播放。
一、翻译内容以及播放的音频的爬取
(1)找到目标网页
一、翻译结果
我们先对目标网页进行踩点,我们先使用F12进行检查,打开network,然后随便输入一个词语,观看网页返回信息的变化。当我们在查看XHR里的内容时,发现了我们需要的信息。
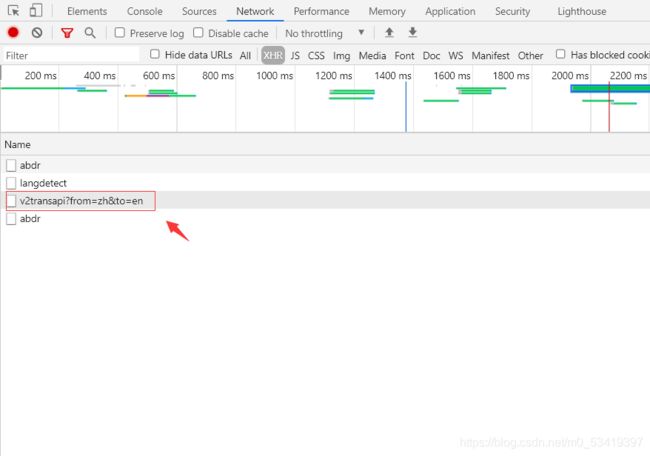
点击右侧的preview,在trans_result中看到了我们需要的信息。

所以这个就是我们的目标网页。
二、语言
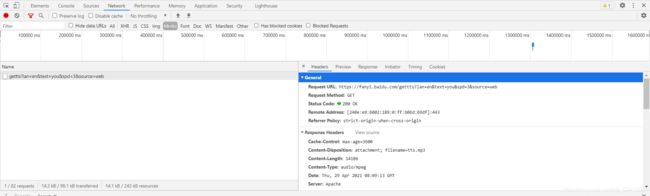
我们在media中找到语言,观看结构,很简单,只需要提供自己所翻译的信息就行了。并没有进行什么加密。
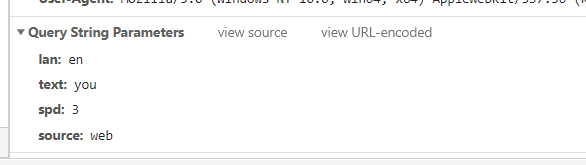
(2)对目标网页的信息进行观测
我们重点观察网页的url,可以发现这个是通过post方法获得信息的,然后我们在看form Data。
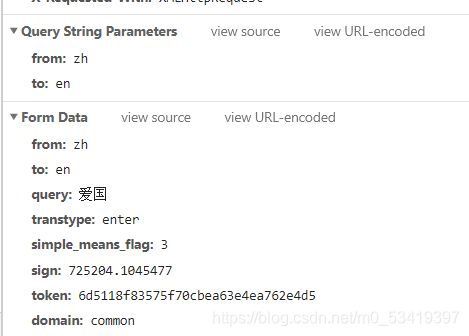
其中发现sign和token是比较棘手的。
我们在随便输入一个值,翻译看一下form Data有什么变化。
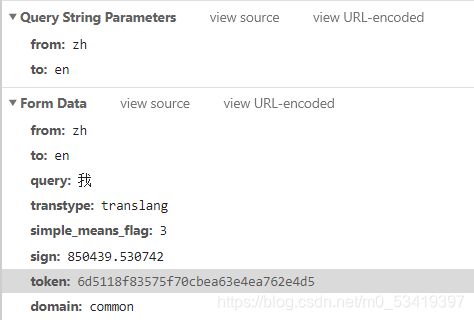
明显token没有发生变化,但是sign发生了变化,初步判断该网页使用了加密。
我们进行search。查看资源中是否含有sign的信息。
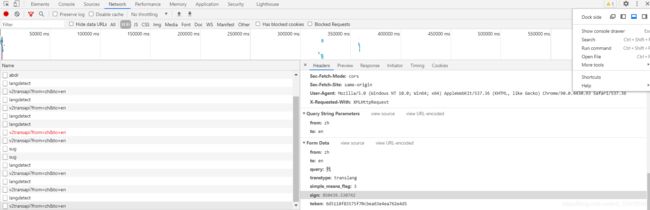
我们发现有很多的assign,很明显不对,我们继续寻找。
终于,我们找到了我们需要的sign,然后对此处进行断点。
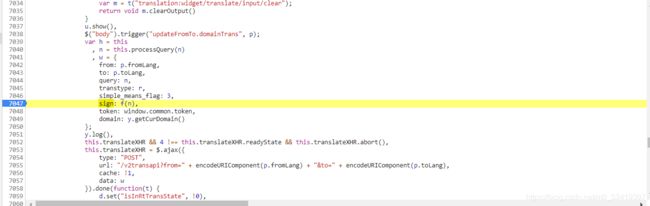
然后我们按F11,查看f(n)对其进行复制到python进行执行。
import execjs
with open("百度翻译.js", "r", encoding="utf-8") as f:
js = execjs.compile(f.read())
sign = js.call("e", "你")
但是很遗憾他报错了,说 i not defind。
我们接下来就是找到i,我们使用watch对i进行监听。
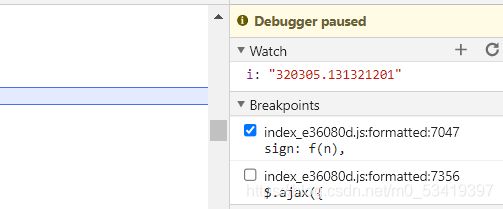
发现他是一个定值,我们直接把i加到最前面。大功告成!!!
再次执行,没有报错。
接下来就简单了,直接使用js获得sign关键信息,使用request进行网页的获取,获得翻译结果。
代码如下。
一、js代码
var i = "320305.131321201"
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
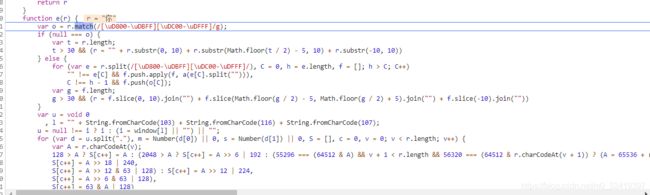
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = null !== i ? i : (i = window[l] || "") || "";
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
二、python代码
其中我们只需要改你网页中的cookie和user—agent
import requests
import execjs
from urllib.parse import urlencode
parame = {
'from': 'en',
'to': 'zh'
}
base_url = 'https://fanyi.baidu.com/v2transapi?'
filename = './en2zh/'
def readJS(path):
f = open(path, 'r')
code = f.read()
f.close()
return code
def get_result(sign, trans):
url = base_url + urlencode(parame)
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '137',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': '==你网页中的cookie==',
'Host': 'fanyi.baidu.com',
'Origin': 'https://fanyi.baidu.com',
'Referer': 'https://fanyi.baidu.com/?aldtype=16047',
'sec-ch-ua': '"Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': '你的user——agent',
'X-Requested-With': 'XMLHttpRequest',
}
data = {
'from': 'en',
'to': 'zh',
'query': trans,
'transtype': 'enter',
'simple_means_flag': '3',
'sign': sign,
'token': 'e50ff9d3cbb60de4a3f82ce244617327',
'domain': 'common',
}
response = requests.post(url, headers=headers, data=data)
response = response.json()
try:
return response["trans_result"]['data'][0]['dst']
except KeyError:
pass
def get_sound(text):
parame = {
'lan': 'zh',
'text': text,
'spd': 3,
'source': 'web'
}
url = 'https://fanyi.baidu.com/gettts?' + urlencode(parame)
response = requests.get(url)
with open(filename + 'result' + '.mp3', 'wb') as f:
f.write(response.content)
f.close()
def result(trans):
ctx = execjs.compile(readJS('./sign.js'))
sign = ctx.call('e', trans)
result = get_result(sign=sign, trans=trans)
get_sound(result)
return result
其他的语言翻译也如法炮制,我们只需要更改一些信息就可以办到,因为sign都是一样的
二、用户界面的实现
这里我们使用了tkinter,他是python自带的,使用起来也很简单,在这里,我就上代码就完事了。
import tkinter as tk
from PIL import Image, ImageTk
from en2zh import result # english to chinese
from zh2en import result2 # chinese to english
from tkinter import ttk
from zh2kor import result3 # chinese to kor
import os
import pyperclip
def xFunc(event):
global my_flage
global var_choice
my_choice = com.get() # 获取选中的值方法1
if my_choice == '英语-->>中文':
my_flage = 'en2zh'
var_choice.set(my_choice)
elif my_choice == '中文-->>英语':
my_flage = 'zh2en'
var_choice.set(my_choice)
elif my_choice == '中文-->>韩文':
my_flage = 'zh2kor'
var_choice.set(my_choice)
def en2zh():
global flage
try:
if flage and my_flage == 'en2zh':
trans = e.get()
fruit = result(trans)
var.set(fruit)
elif flage and my_flage == 'zh2en':
trans = e.get()
fruit = result2(trans)
var.set(fruit)
elif flage and my_flage == 'zh2kor':
trans = e.get()
fruit = result3(trans)
# pyperclip.copy(fruit)
var.set(fruit)
except NameError:
print('Pleace choose the Language!!')
def clear():
global text
text = l.cget('textvariable')
if text is not None:
var.set('')
else:
pass
def sound():
try:
os.system(r'D:\Laf\爬虫\爬虫实战\baiduifanyi' + '/' + my_flage + '/' + 'result' + '.mp3')
except NameError:
print('Worning!!')
def copy_():
pyperclip.copy(var.get())
print("Ok to copy to the local!")
# 设置主题窗户
root = tk.Tk()
root.geometry('800x500')
root.configure(background='#f8fabd')
root.title('翻译软件')
root.resizable(False, True)
var_choice = tk.StringVar()
xVariable = tk.StringVar() # #创建变量,便于取值
com = ttk.Combobox(root, textvariable=xVariable) # #创建下拉菜单
com["value"] = ('英语-->>中文', '中文-->>英语', '中文-->>韩文') # #给下拉菜单设定值
com.bind("<>" , xFunc)
# 设置条形框,插入图片
img = Image.open("1.jpg")
width = img.size[0] # 获取宽度
height = img.size[1]
img = img.resize((int(width*0.25), int(height*0.25)), Image.ANTIALIAS)
photo1 = ImageTk.PhotoImage(img)
var = tk.StringVar()
imgs = Image.open("sound.png")
width = imgs.size[0] # 获取宽度
height = imgs.size[1]
imgs = imgs.resize((int(width*1), int(height*1)), Image.ANTIALIAS)
photo_sound = ImageTk.PhotoImage(imgs)
l = tk.Label(root, textvariable=var, height=4, width=80, font=('Arial Bold', 20))
Lab = tk.Label(root, textvariable=l.cget('textvariable'), image=photo1)
e = tk.Entry(root, show=None, width=100)
flage = True
choose_label = tk.Label(root, textvariable=var_choice, height=4, width=20, font=('Arial Bold', 10), bg='#d53f27')
b = tk.Button(root, text='翻译', width=15, height=2, command=en2zh)
b1 = tk.Button(root, text='清除', width=5, height=1, command=clear)
b1.place(x=750, y=422) # 设置清除按钮
b2 = tk.Button(root, image=photo_sound, width=20, height=20, command=sound)
b3 = tk.Button(root, text='复制', width=3, height=2, font=('Arial Bold', 10), command=copy_)
b3.place(x=650, y=422)
b2.place(x=700, y=422) # 设置清除按钮
com.pack() # #将下拉菜单绑定到窗体
Lab.pack() # 设置主界面
e.pack() # 翻译输入文本
l.pack() # 显示翻译结果的Label
b.pack() # 翻译按钮
choose_label.place(x=0, y=0)
root.mainloop()
这是我的文件的大概结构。
这里我只提供了三种语言的转化,有要求的hxd可以自行将其他的补充完整,同时界面的美化也可以自己完成,欢迎大家和我交流。