学习Java语法糖这一篇就够了(详细版)
不知道有多少人针对于java语法是死记硬背的,读完这一篇,让你真正的去理解每一个语法,理解完之后会发现你的技术层次又提高了一个等级。
文章当中泛型、自动装箱拆箱、字符串相加 这三个相对来说写的内容比较多,原因是我写这篇文章的时候,不仅仅想的是 要知道语言背后的转换,而且还想要知道为什么这么做。其次文章当中很多内容都是面试经常会问的。
本篇当中一共记录了十五个Java语法糖,相对来说比较全了,欢迎大家点赞收藏!
目录
-
- 一、语法糖是什么?
- 二、jad反编译工具
- 三、变长参数
- 四、枚举
- 五、泛型
-
- 5.1、Java与C#的泛型区别
- 5.2、泛型的历史背景
- 5.3、什么是裸类型?
- 5.4、如何实现裸类型的?
- 5.5、重载当中使用泛型
- 5.6、泛型类中如何获取传入的参数化类型
- 六、自动装箱、拆箱
-
- 6.1、什么是自动装箱,自动拆箱
- 6.2、值类型和引用类型的区别
- 6.3、有了值类型为什么还要有包装类
- 6.4、怎么就自动装箱,自动拆箱了呢?
- 6.5、为什么要自动装箱,自动拆箱?
- 6.6、什么情况会触发装箱和拆箱?
- 6.7、拆箱过程出现NPE
- 6.8、分析如下案例
- 6.9、总结
- 七、内部类
- 八、增强 for 循环
- 九、Switch 支持字符串和枚举
- 十、条件编译
- 十一、assert 断言
- 十二、try-with-resources
- 十三、字符串相加
-
- 13.1、字符串拼接背后的秘密
- 13.2、String不可变?
- 13.3、String常见面试题
- 13.4、String、StringBuffer和StringBuilder的区别
- 13.5、StringBuilder扩容机制
- 十四、数值字面量
- 十五、匿名内部类
- 十六、运算符
-
- 16.1、i=i++; 代码分析
- 16.2、常见面试题
- 十七、Lambda表达式
一、语法糖是什么?
语法糖(Syntactic Sugar),也称糖衣语法,指在计算机语言中添加的某种语法,这种语法对语言本身的功能来说没有什么影响,只是为了方便程序员进行开发,提高开发效率,使用这种语法写出来的程序可读性也更高。说白了,语法糖就是对现有语法的一个封装。
但其实,Java虚拟机是并不支持语法糖的,语法糖在程序编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。所以在Java中真正支持语法糖的是Java编译器。
在了解语法糖前,先了解一下Java编译期。Java当中分为以下三种编译:
前端编译器(叫“编译器的前端”更准确一些)把*.java文件转变成*.class文件的过程,典型的有JDK的Javac,Javac编译器是一个由Java语言编写的程序。ide当中target目录就是生成的字节码文件;而我们经常有时候代码没生效然后会使用mvn clean install,这个命令主要作用就是清理字节码文件并重新生成字节码文件然后进行打包。- Java虚拟机的
即时编译器(常称JIT编译器,Just In Time Compiler)运行期把字节码转变成本地机器 码的过程,典型的有HotSpot虚拟机的C1、C2编译器,Graal编译器。 - 还可能是指使用静态的提前编译器(常称AOT编译器,Ahead Of Time Compiler)直接
把程序编译成与目标机器指令集相关的二进制代码的过程,典型的有JDK的Jaotc(一般我们用不到这个,了解即可,真正一直用到的是上面两个)。
很多新生的Java语法特性,都是靠Javac编译器的“语法糖”来实现,而不 是依赖字节码或者Java虚拟机的底层改进来支持。包括我们所用到的泛型、自动装箱、Lamda等等,实际上都是由前端编译器在将.java文件转换成.class文件的过程 将泛型以及自动装箱等等进行了转换。而.class文件才是在虚拟机真正运行的文件。
Java虚拟机设计团队选择把对性能的优化全部集中到运 行期的即时编译器中,我们可以这样认为,Java中即时编译器在运行期的优 化过程,支撑了程序执行效率的不断提升;而前端编译器在编译期的优化过程,则是支撑着程序员的 编码效率和语言使用者的幸福感的提高。
二、jad反编译工具
我们想要真正了解语法糖,离不开反编译,反编译指的是将class文件进行编译成我们可以看懂的文件。因为正常.class文件我们是看不懂的,全是特殊符号。这个没试过的可以将class文件放到记事本看一下。
这里我用的jad工具对class文件进行的反编译。jad可以通过将class文件进行反编译成jad文件,为什么要用jad?虽然ider也可以打开class文件,但是ider反编译过后的class有很多地方并没有保留.class文件原样,并不是专用的反编译工具。而用jad反编译生成的jad文件,可以保留原样,基本上不会做什么修改。
反编译只是为了让我们能看懂class文件,了解class的目的就是为了看看.java文件在编译成.class文件之后发生了哪些改变。
jad工具用法:https://blog.csdn.net/weixin_43888891/article/details/122977886
ider当中是能打开jad文件的,绿记事本也是可以打开jad文件的。
三、变长参数
变长参数也是一个比较小众的用法,所谓变长参数,就是方法可以接受长度不定确定的参数。一般我们开发不会使用到变长参数,而且变长参数也不推荐使用,它会使我们的程序变的难以处理。但是我们有必要了解一下变长参数的特性。
public class VariableArgs {
public static void printMessage(String... args) {
for (String str : args) {
System.out.println("str = " + str);
}
}
public static void main(String[] args) {
VariableArgs.printMessage("l", "am", "cxuan");
}
}
首先通过javac命令生成class文件,然后通过jad工具进行反编译,生成jad文件:

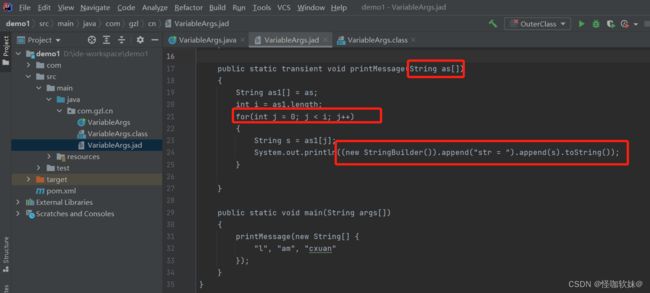
通过上面示例发现编译后有很多地方发生了变化:
- 可变长参数变成了数组
"str = " + str字符串拼接转换成了StringBuilder进行拼接- 增强for循环变成了原始的循环
可变长参数就是在编译的时候转换成了数组,使用变长参数有两个条件,一是变长的那一部分参数具有相同的类型,二是变长参数必须位于方法参数列表的最后面。
四、枚举
我们在日常开发中经常会使用到 enum 和 public static final … 这类语法。那么什么时候用 enum 或者是 public static final 这类常量呢?好像都可以。
在 Java 字节码结构中,并没有枚举类型。枚举只是一个语法糖,在编译完成后就会被编译成一个普通的类,也是用 Class 修饰。这个类继承于 java.lang.Enum,并被 final 关键字修饰。
我们举个例子来看一下:
一般我们使用枚举都是这样来用的,来记录一些状态等等。
public enum StatusEnum {
NO_COMMIT(0, "未提交"),
COMMIT(2, "已提交"),
;
private int code;
private String desc;
StatusEnum(int code, String desc) {
this.code = code;
this.desc = desc;
}
// get、set方法省略...
}
首先通过javac命令生成class文件,然后通过jad工具进行反编译,生成jad文件:

反编译过后如下:
package com.gzl.cn;
public final class StatusEnum extends Enum
{
public static StatusEnum[] values()
{
return (StatusEnum[])$VALUES.clone();
}
public static StatusEnum valueOf(String s)
{
return (StatusEnum)Enum.valueOf(com/gzl/cn/StatusEnum, s);
}
private StatusEnum(String s, int i, int j, String s1)
{
super(s, i);
code = j;
desc = s1;
}
public static final StatusEnum NO_COMMIT;
public static final StatusEnum COMMIT;
private int code;
private String desc;
private static final StatusEnum $VALUES[];
static
{
NO_COMMIT = new StatusEnum("NO_COMMIT", 0, 0, "未提交");
COMMIT = new StatusEnum("COMMIT", 1, 2, "已提交");
$VALUES = (new StatusEnum[] {
NO_COMMIT, COMMIT
});
}
}
从反编译结果我们可以看到,枚举其实就是一个继承于 java.lang.Enum 类的 class 。而里面的属性 NO_COMMIT 和 COMMIT 本质也就是 public static final 修饰的对象实例。
其次他的内部就是依靠static静态块 来对NO_COMMIT 和 COMMIT 赋值的,那也就是意味着只要类初始化,那两个静态对象就会实例化,于是我们就可以使用对象了。什么时候会类初始化?第一次使用NO_COMMIT或 COMMIT的时候,就会类初始化。
除此之外还有一个StatusEnum数组,这个数组在static静态块中,将内存指向了NO_COMMIT 和 COMMIT。
编译器还会为我们生成两个方法,values() 方法和 valueOf 方法,这两个方法都是编译器为我们添加的方法,通过使用 values() 方法可以获取所有的 Enum 属性值,说白了就是获取的那个数组。而通过 valueOf 方法用于获取单个的属性值。
五、泛型
泛型的本质是参数化类型(Parameterized Type)或者参数化多态(Parametric Polymorphism)的 应用。能够用在类、接口 和方法的创建中,分别构成泛型类、泛型接口和泛型方法。
Java的泛型直到今天依然作为Java 语言不如C#语言好用的“铁证”被众人嘲讽,Java选择这样的泛型实现,是出于当时语言现状的权衡,而不是语言先进性或者设计者水 平不如C#之类的原因。
5.1、Java与C#的泛型区别
Java选择的泛型实现方式叫作“类型擦除式泛型”,而C#选择的泛型实现 方式是“具现化式泛型”。
C#里面泛型无论在程序源码里面、编译后的中间语言表示里面,抑或是运行期的CLR里面都是切实存在的,List,它们由系统在运行期生成,有着自己独立的虚方法表和类型数据。
Java语言中的泛型则不同,它只在程序源码中存在,在编译后的字节码文件中,全部泛型都被替换 为原来的裸类型了。并且在相应的地方插入了强制 转型代码,因此对于运行期的Java语言来说,ArrayList。由 此读者可以想象“类型擦除”这个名字的含义和来源。
如果读者是一名C#开发人员,可能很难想象下面中的Java 代码都是不合法的。

5.2、泛型的历史背景
在没有泛型的时代,由于Java中的数组是支持协变(Covariant)的,对应的集合类 也可以存入不同类型的元素,如下面代码尽管不提倡,但是完全可以正常编译成 Class文件。
什么是协变?
在某些情况下,即使某个对象不是数组的基类型,我们也可以把它赋值给数组元素。这种属性叫做协变(covariance)

为了保证这些编译出来的Class文件可以在Java 5.0引入泛型之后继续运行,设计者面前大体上有两 条路可以选择:
- 需要泛型化的类型(主要是容器类型),以前有的就保持不变,然后平行地加一套泛型化版本 的新类型。
- 直接把已有的类型泛型化,即让所有需要泛型化的已有类型都原地泛型化,不添加任何平行于 已有类型的泛型版。
在这个分叉路口,C#走了第一条路,Java选择的第二条路。
Java选择的第二条路的原因:
在JDK 1.2时,遗留代码规模 尚小,Java就引入过新的集合类,并且保留了旧集合类不动。这导致了直到现在标准类库中还有 Vector(老)和ArrayList(新)、有Hashtable(老)和HashMap(新)等两套容器代码并存,如果当 时再摆弄出像Vector(老)、ArrayList(新)、Vector(老但有泛型)、ArrayList(新且有泛 型)这样的容器集合,可能叫骂声会比今天听到的更响更大。
5.3、什么是裸类型?
裸类型的概念主要来源于,新增泛型的时候,他必须要考虑如何兼容之前不带泛型的代码。
如果要兼容,就必须保证以前直接用ArrayList的代码在泛型新版本里必须还能继续用这同一个容 器,这
就必须让所有泛型化的实例类型,譬如ArrayList,否则类型转换就是不安全的。、ArrayList 这些全部自动成为 ArrayList的子类型才能可以
由此就引出了“裸类型”的概 念,裸类型应被视为所有该类型泛型化实例的共同父类型,只有这样,像下面代码中的赋值才是被系统允许的从子类到父类的安全转型。

5.4、如何实现裸类型的?
这里又有了两种选择:
-
一种是在运行期由Java虚拟机来自动 地、真实地构造出
ArrayList这样的类型,并且自动实现从ArrayList派生自ArrayList的继承关系来满足裸类型的定义; -
另外一种是索性简单粗暴地直接在编译时把
ArrayList还原 回ArrayList,只在元素访问、修改时自动插入一些强制类型转换和检查指令,这样看起来也是能满足 需要,这两个选择的最终结果大家已经都知道了。
如下代码是一段简单的Java泛型例子,我们可 以看一下它编译后的实际样子是怎样的。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Test1 {
public static void main(String[] args) {
List objects = new ArrayList<>();
objects.add(1);
objects.add(2);
Integer integer = objects.get(1);
System.out.println(integer);
Map map = new HashMap();
map.put("hello", "你好");
map.put("how are you?", "吃了没?");
System.out.println(map.get("hello"));
System.out.println(map.get("how are you?"));
}
}
首先通过javac命令生成class文件,然后通过jad工具进行反编译,生成jad文件:
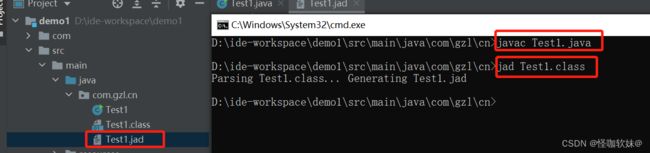
注意使用javac来编译class文件的时候,如果文件有中文,并且使用的编码不是GBK,可能在编译的时候会报错的。通过ider的右下角可以指定当前文件的编码类型。
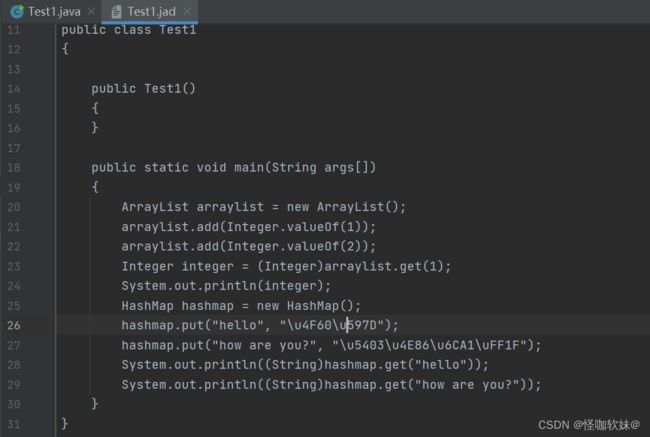
通过观察生成的jad文件,会发现我们所用的泛型就是假泛型,经过反编译后泛型就给去掉了,并且从map容器当中取值的时候就是通过类型强制转换的。
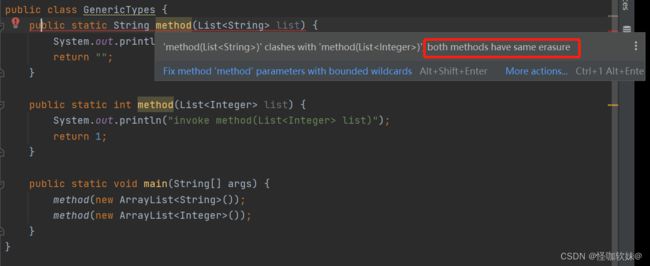
5.5、重载当中使用泛型
通过擦除法来实现泛型,还丧失了一些面向对象思想应有的优雅,带来了一些模 棱两可的模糊状况,例如下面代码:

这段代码是不能被编译的,因为参数List和List编译之后都被擦除了,变成了同一种的裸类型List, 类型擦除导致这两个方法的特征签名变得一模一样。我用的是JDK1.8。在JDK6下是可以编译的。JDK6可以编译主要原因是他保留在字节码的特征签名不一样即可。
什么是重载?
在Java语言中,要重载(Overload)一个方法,除了要与原方法具有相同的简单
名称之外,还要求必须拥有一个与原方法不同的特征签名。
什么是特征签名?
特征签名是指一个
方法中各个参数在常量池中的字段符号 引用的集合
《Java语言规范》第3版的8.4.2节中分别都定义了字节码层 面的方法特征签名以及Java代码层面的方法特征签名
- Java代码的方法特征签名只包括
方法名称、参数 顺序及参数类型,也正是因为返回值不会包含在特征签名之中,所以Java语言里面是无法仅仅依靠返回值 的不同来对一个已有方法进行重载的。 - 而字节码的特征签名还包括方法返回值以及受查异常表。
由此也可以得出JDK6保留在字节码的特征签名不一样即可(也就是方法参数和返回值任意一个不一样就可以),而JDK8是必须满足Java代码的方法特征签名不一样(参数不一样)。
5.6、泛型类中如何获取传入的参数化类型
Java中的泛型会被类型擦除,那为什么在运行期仍然可以使用反射获取到具体的泛型类型?
答案是在运行期只能获取当前class文件中包含泛型信息的泛型类型,而不能在运行时动态获取某个泛型引用的类型。

注意:上面示例是错误的,不会编译成功的。在T.class就是错误的。
在以上的代码中,假设泛型的信息没有被擦除,您在任何位置new出来的Test实例都会保存自己的“T”类型信息,那么getArray方法就可以获取到实际T的class信息。
而在类型擦除后,上面代码中是没有任何办法在getArray方法内部获取到T的类型信息的,这才是擦除后的实际效果。因为反射他获取的永远是编译后的.class,像上面的那种的使用泛型,都是属于动态的。
再举例来说:

在上面的代码中,您可以通过反射获取成员test的Integer泛型信息,但是无法获取item的实际类型。这部分我查看了OpenJDK 8的相关源码,从原理上讲,例子中的Test成员编译时会将Integer信息编译进class字节码,从而反射系统就可以获取到这个信息。
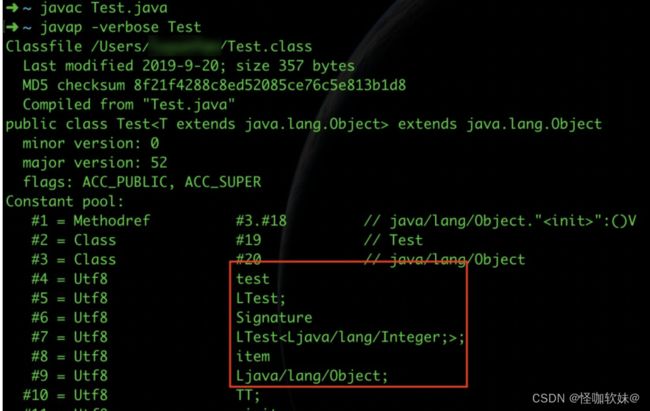
您可以看到,实际上test的泛型信息是直接被编译进字节码了。在OpenJDK 8中,您反射获取泛型的时候,您使用getDeclaredField来获取Field对象时,本质上系统会调用一个native方法:getDeclaredFields0来获取该class的信息。而它的实现在jvm.cpp的JVM_GetClassDeclaredFields方法中:
而这个方法本质上的操作是从已经加载好的class信息中获取fieldDescriptor,从而产生Field对象的oop,把class的field信息注入进去,返回给Java端的调用方。而再追溯class中产生fieldDescriptor的代码可以发现,事实上这个信息就是在JVM加载字节码的时候,JVM将解析到字节码的泛型信息保存下来的。
六、自动装箱、拆箱
就纯技术的角度而论,自动装箱、自动拆箱与遍历循环(for-each循环)这些语法糖,无论是实现 复杂度上还是其中蕴含的思想上都不能和上面介绍的泛型相提并论,两者涉及的难度和深度都有很 大差距。
6.1、什么是自动装箱,自动拆箱
这个问题在面试概率当中是非常大的。
定义:基本数据类型和包装类之间可以自动地相互转换
理解:装箱就是自动将基本数据类型转换为封装类型,拆箱就是自动将封装类型转换为基本数据类型。
以Integer为例,使用Integer.valueOf()方法实现装箱,使用Integer.intValue()方法实现拆箱。
6.2、值类型和引用类型的区别
- 在Java中,一切皆对象,但
八大基本类型却不是对象。 - 声明方式的不同,
基本类型无需通过new关键字来创建,而封装类型需new关键字。 - 存储方式及位置的不同,
基本类型是直接存储变量的值保存在堆栈中能高效的存取,封装类型需要通过引用指向实例,具体的实例保存在堆中。 初始值的不同,封装类型的初始值为null,基本类型的的初始值视具体的类型而定,比如int类型的初始值为0, boolean类型为false,默认值更多的指的是拿基本类型来当中成员变量来使用不赋值的情况下的默认值,在方法当中如果只声明基本类型而不初始化值,并且还要使用他,这时候会编译报错的;使用方式的不同,比如与集合类合作使用时只能使用包装类型。- 什么时候该用包装类,什么时候用基本类型,看基本的业务来定:这个字段允不允许null值,如果允许null值,则必然要用封装类,否则值类型就可以了,用到比如泛型和反射调用函数,就需要用包装类!
在阿里巴巴的规范里所有的POJO类必须使用包装类型,而在本地变量(本地变量又叫局部变量,指的是方法的形式参数以及在方法中定义的变量)推荐使用基本类型。
6.3、有了值类型为什么还要有包装类
日常开发中,靠这些基本数据类型几乎能够满足我们的需求,但是基本类型终究不是对象,往重了说不满足面向对象的开发思想,往轻了说就是使用不方便。怎么讲?例如做一些数据类型转换,获取int数据类型的取值范围等等。
类的优点在于它可以定义成员变量、成员方法,提供丰富便利的功能,因此Java在JDK1.0的时候就设计了基本数据类型的包装类,而在JDK1.5中引入了新特性:自动装箱和拆箱。
假如没有包装类,我想要通过String转换成int 会非常麻烦,而有包装类之后,我通过调用包装类提供的方法便可以完成类型转换。
public class Test {
public static void main(String[] args) {
// 数据库中的商品数量 number
String number = "666";
// 借助封装了 Integer 转换为 int
int intVal = Integer.valueOf(number);
// 借助封装了 Float 转换为 float
float floatVal = Float.valueOf(number);
// 借助封装了 Long 转换为 long
long longVal = Long.valueOf(number);
// 依次输出三个值的内容
System.out.println("int="+intVal);
System.out.println("floatVal="+floatVal);
System.out.println("longVal="+longVal);
}
}
一名话,包装类有更多的方法和用途,而这是基本类型没有的
6.4、怎么就自动装箱,自动拆箱了呢?
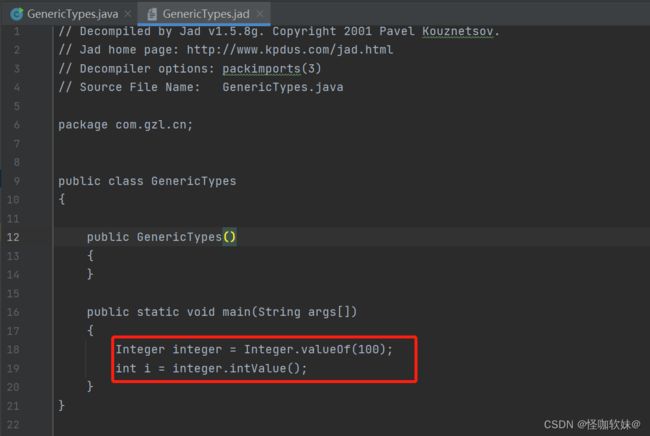
public class GenericTypes {
public static void main(String[] args) {
Integer a = 100;
int b = a;
}
}
通过编译成class文件,再将class文件反编译出来的结果是:
6.5、为什么要自动装箱,自动拆箱?
到现在应该知道什么是自动装箱跟拆箱了,但是为什么要自动拆箱跟装箱呢?
这应该是属于是java早年设计缺陷。基础类型是数据,不是对象,也不是Object的类。
所以想让他变成对象来使用,但是又不能直接丢掉他,于是出了基本类型的包装类。
但是包装类跟基本类型又紧密相连,我们在开发当中经常会遇到数字1,2等等,这都属于是基本类型,但是往往我们有时候会直接用Integer a = 1; 而并不是 int a = 1。要知道1他本身可不属于Integer类型,他可是基本类型,这样场景的代码太多了,于是Java想到了在编译的时候进行自动装箱拆箱,说白了就是在编译的时候,自动让他调用方法进行类型转换。以至于我们没真正去了解过装箱跟拆箱的人,会有时候误认为1既可以直接赋值给Integer,又可以赋值给int。
6.6、什么情况会触发装箱和拆箱?
虽然我们知道基本数据类型和包装类之间可以自动地相互转换的时候会发生装箱和拆箱,那更具体点,还有哪些会触发。这道题面试官经常有时候也会问的。
首先回答这个问题的时候拆箱和装箱要分开说:
-
装箱:在基本类型的值赋值给包装类型时触发。例如:Integer a = 1;
这时二进制文件中实际上是Integer a = Integer.valueOf(1); -
拆箱主要是有三种场景:
- 在包装类型赋值给基本类型时触发。
例如:Integer a = 1; // a 是Integer类型
int b = a; // 将Integer类型赋值给int类型,触发拆箱 - 在做运算符运算时触发(不管是system输出的时候出现计算也好,还是三目运算当中出现都会引发拆箱)。
例如:
Integer a = 1;
Integer b = 2;
System.out.print(a * b); //这时a*b在二进制文件中被编译成a.intValue() * b.intValue(); ==运算时,如果a 和 b 都是Integer类型,则不会拆箱,因为==也可以直接比较对象,表示a和b是否指向同一对象地址。因此这里并不是比较值是否相等了。而如果a 和 b 中有一个是int类型,另一个是Integer 类型,则会触发拆箱,然后对两个int值进行比较。
- 在包装类型赋值给基本类型时触发。
6.7、拆箱过程出现NPE
拆箱给我们带来便利的同时,有时候也会带来NPE的危害!如下提供了两个NPE案例。
错误示例一: 返回类型为基本数据类型,return 包装数据类型的对象时,自动拆箱有可能产生 NPE。
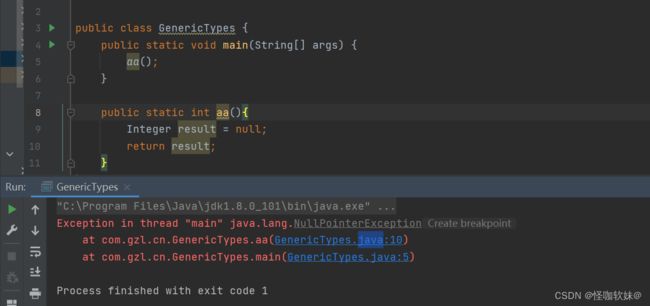
错误示例二: 包装类在发生符号运算的时候会进行拆箱,自动拆箱有可能产生 NPE。

三目运算符这块会变成 这样:
c = null,所以访问intValue方法报NPE。
Integer integer3 = Integer.valueOf(boolean1.booleanValue() ? integer.intValue() * integer1.intValue() : integer2.intValue());
阿里的开发规范当中也提了,尽量使用 JDK8 的 Optional 类来防止 NPE 问题。
6.8、分析如下案例
这些语法糖虽然看起来很简单,但也不见得就没有任何值得我们特别关注的地方,如下代码演示了自动装箱的一些错误用法。
public class GenericTypes {
public static void main(String[] args) {
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
System.out.println(c == d);
System.out.println(e == f);
System.out.println(c == (a + b));
System.out.println(c.equals(a + b));
System.out.println(g == (a + b));
System.out.println(g.equals(a + b));
}
}
上面代码如果你用的ide然后装有阿里的代码检查插件,会发现这块会提示不建议你这么写,但是不影响运行。
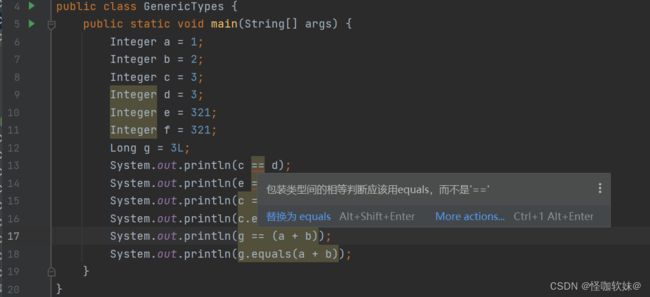
不妨思考两个问题:
- 一是这6句打印语句的输出是什么?
- 二是这6句打 印语句中,解除语法糖后参数会是什么样子?
编译后如下:
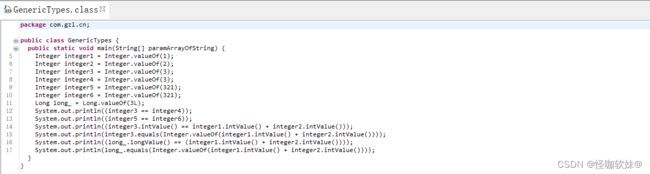
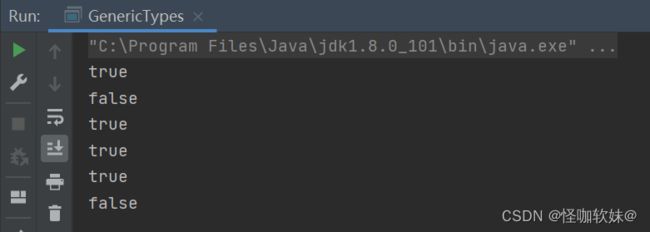
运行后的结果:
分析原因
为什么 c == d 返回了true ,而e == f 却返回了false?
1、先明确==号的作用
- 基础类型的时候,是比较的值
- 引用类型,比较的是地址
2、Integer a = 1; 和 Integer a = new Integer(1) 的区别
Java当中在以
Integer a = 1;这种赋值的时候,跟直接
Integer a = new Integer(1);是完全不一样的,Integer a = 1;在经过编译后会进行自动装箱变成Integer a = Integer.valueOf(1);,直接new也涉及不到基本类型直接的转换,自然没有装箱这一说了。可以观察Integer构造器会发现,参数就是以int基本类型来进行传参的。

3、Integer.valueOf(1)内部的秘密
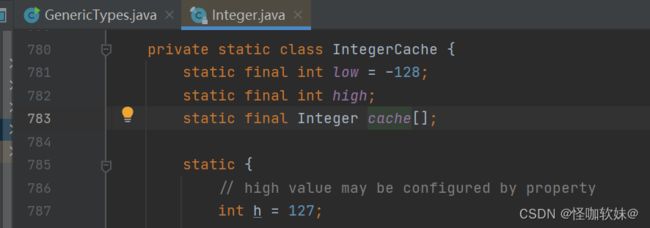
装箱就是调用的Integer的valueOf方法,并且是int传参,会发现它里面是个if判断,当传入的值是-127-128之间的时候,并不会去创建对象,而是直接返回了
IntegerCache.cache[i + (-IntegerCache.low)];缓存当中的值。
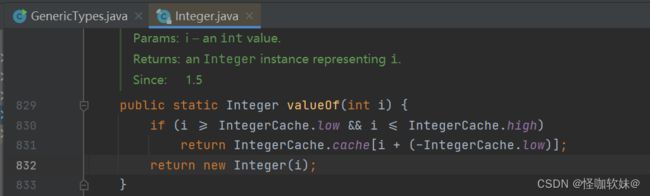
点进去IntegerCache会发现,他实际上就是Integer的一个内部类,而这个内部类当中有一个Integer数组,存着-127-128之间的值。
4、得出结论
c == d 返回了true ,是因为c和d都是3,并且是以Integer c = 3;这种赋值的,也就意味着装箱后,c和d此时在内存上指向了缓存上的3的地址。c == d判断的时候,他没有涉及到拆箱,也就意味着是比较的两个对象的内存地址。所以这里返回了true。
而e == f 返回了false,虽然e和f都是321相同的值,但是他并不是在缓存范围内,以至于他在装箱后也是走的new Integer(321);创建的对象。然后==判断的时候也并没有进行拆箱,所以判断的是两个对象内存,最后返回了false。
为什么 g == (a + b) 返回了true ,而g.equals(a + b) 却返回了false?

通过反编译结果会发现
g == (a + b)当中g、a、b这三个全都发生了拆箱动作,发生拆箱的原因是因为==的时候出现了算数运算符,将g和(a+b)整成了一个long值类型,和一个int值类型进行的 "=="比较,只要是值类型,双等比较的就是单纯的值,所以这里返回的true,没有疑问。
g.equals(a + b)返回false是因为 equals()方法不处理数据转型的关系,也就是g并没有进行拆箱,而a和b正常拆箱了,但是通过反编译结果会发现,他两虽然拆箱了,但是在运算完之后又装箱了。这是为什么呢?
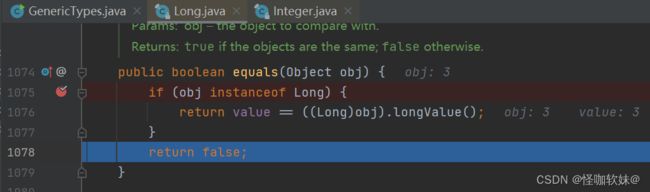
因为g并没有拆箱,意味着他还是Long类型的包装类,使用equals比较他会将右侧比较的值进行自动装箱的。导致出现了左侧是Long类型,右侧是Integer类型。
通过下面equals源码当中会发现:Integer类型和Long类型在equals比较的时候直接就会返回false,根本不管你值一样不一样。反过来一样,Long类型和Integer类型equals比较的时候也是直接就会返回false。
6.9、总结
在Integer类型比较的时候: 建议在实际编码中尽量避免System.out.println(c == d)两个Integer对象用==号判断。尽量使用equals进行比较。避免不在范围内导致生成两个不同的Integer对象,直接会==比较错误。
- 包装类 的“==”运算在不遇到算术运算的情况下不会自动拆箱
- equals()方法不处理数据转型的关系。
其次有一点还需要注意,就是不同类型之间不要用equals比较,会直接返回false。如果真的想比较,我想到了一个歪方法,如下,就是让他加0发生运算逼他进行拆箱,这样用==比较的就是两个值类型了:

七、内部类
内部类是 Java 一个小众 的特性,我之所以说小众,并不是说内部类没有用,而是我们日常开发中其实很少用到,但是翻看 JDK 源码,发现很多源码中都有内部类的构造。比如常见的 Integer源码中就有一个 IntegerCache 内部类;
Java 语言中之所以引入内部类,是因为有些时候一个类只想在一个类中有用,不想让其在其他地方被使用,也就是对外隐藏内部细节。
内部类其实也是一个语法糖,因为其只是一个编译时的概念,一旦编译完成,编译器就会为内部类生成一个单独的class 文件,名为 outer$innter.class。
下面我们就根据一个示例来验证一下。
public class OuterClass {
private String label;
class InnerClass {
public String linkOuter() {
return label = "inner";
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
System.out.println(innerClass.linkOuter());
}
}
上面这段编译后就会生成两个 class 文件,一个是 OuterClass.class ,一个是 OuterClass$InnerClass.class ,这就表明,外部类可以链接到内部类,内部类可以修改外部类的属性等。
我们来看一下内部类编译后的结果
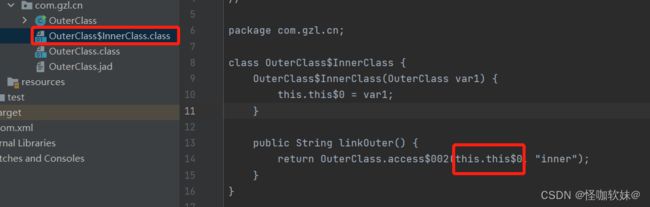
如上图所示,通过内部类的构造器会发现想要实例化一个内部类,必须传入外部类对象。
内部类经过编译后的 linkOuter() 方法通过构造器传入的外部类对象,会生成一个指向外部类的 this 引用,这个引用就是连接外部类和内部类的引用。然后就可以通过这个this引用外部类的属性了。
八、增强 for 循环
为什么有了普通的 for 循环后,还要有增强 for 循环呢?
首先普通 for 循环得需要知道遍历对象的长度,每次还需要知道数组的索引是多少,这种写法明显有些繁琐。增强 for 循环与普通 for 循环相比,功能更强并且代码更加简洁,你
无需知道遍历的次数和数组的索引即可进行遍历。
增强 for 循环的对象要么是一个数组,要么实现了 Iterable 接口。这个语法糖主要用来对数组或者集合进行遍历,其在循环过程中不能改变集合的大小。
代码示例:
public class ForTest {
public static void main(String[] args) {
String[] params = new String[]{"hello","world"};
//增强for循环对象为数组
for(String str : params){
System.out.println(str);
}
List lists = Arrays.asList("hello","world");
//增强for循环对象实现Iterable接口
for(String str : lists){
System.out.println(str);
}
}
}
经过反编译后:
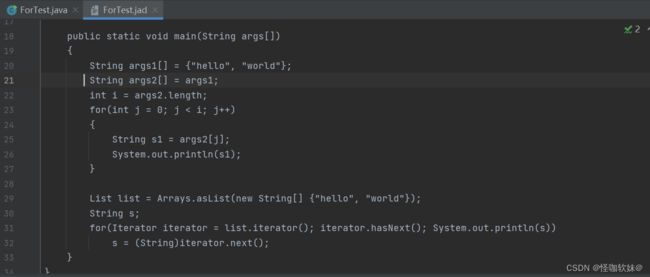
如果对数组进行增强 for 循环的话,其内部还是对数组进行遍历,只不过语法糖把你忽悠了,让你以一种更简洁的方式编写代码。
而对继承于 Iterator接口 的 进行增强 for 循环遍历的话,相当于是调用了 Iterator 的 hasNext() 和 next() 方法。
哪些类是继承于Iterator接口?
Collection接口我们应该都知道,list、et、Queue接口都继承于Collection接口,而Collection接口又继承了Iterator接口。只要继承了Iterator接口就意味着使用循环的时候可以使用迭代器。

九、Switch 支持字符串和枚举
switch 关键字原生只能支持整数类型。如果 switch 后面是 String 类型的话,编译器会将其转换成 String 的hashCode 的值,所以其实 switch 语法比较的是 String 的 hashCode 。
代码示例:
public class SwitchCaseTest {
public static void main(String[] args) {
String str = "cxuan";
switch (str) {
case "cuan":
System.out.println("cuan");
break;
case "xuan":
System.out.println("xuan");
break;
case "cxuan":
System.out.println("cxuan");
break;
default:
break;
}
}
}
经过反编译后:
public static void main(String[] var0) {
String var1 = "cxuan";
byte var3 = -1;
switch (var1.hashCode()) {
case 3064863:
if (var1.equals("cuan")) {
var3 = 0;
}
break;
case 3690474:
if (var1.equals("xuan")) {
var3 = 1;
}
break;
case 95119053:
if (var1.equals("cxuan")) {
var3 = 2;
}
}
switch (var3) {
case 0:
System.out.println("cuan");
break;
case 1:
System.out.println("xuan");
break;
case 2:
System.out.println("cxuan");
}
}
根据反编译后的结果可以看出,我们明明用的一个switch,经过反编译后却变成了两个,原因就是因为switch当中使用了字符串。他第一个switch主要做的工作就是将字符串转换为了hashCode,然后依靠hashcode然后再进行equals判断一遍,最后换成了0、1、2。
为什么他已经有了hashcode判断,还要用equals判断一遍?
因为字符串有可能会产生哈希冲突的现象。
然后下面那一个switch再根据0、1、2做对应的操作。
十、条件编译
条件编译,就是使用条件为常量的if语句。
使用 final + if 的组合就可以实现条件编译了。如下代码所示:
public class IfTest {
public static void main(String[] args) {
final boolean DEBUG = true;
if (DEBUG) {
System.out.println("Hello, world!");
} else {
System.out.println("nothing");
}
}
}
经过反编译后:
public class IfTest {
public static void main(String args[])
{
System.out.println("Hello, world!");
}
}
我们可以看到,我们明明是使用了 if …else 语句,但是编译器却只为我们编译了 DEBUG = true 的条件。
所以,Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的,编译器不会为我们编译分支为 false 的代码。
十一、assert 断言
你在 Java 中使用过断言作为日常的判断条件吗?
断言:也就是所谓的 assert 关键字,是 jdk 1.4 后加入的新功能。它主要使用在代码开发和测试时期,用于对某些关键数据的判断,如果这个关键数据不是你程序所预期的数据,程序就提出警告或退出。当软件正式发布后,可以取消断言部分的代码。它也是一个语法糖吗?现在我不告诉你,我们先来看一下 assert 如何使用。
public class AssertTest {
//这个成员变量的值可以变,但最终必须还是回到原值5
static int i = 5;
public static void main(String[] args) {
assert i == 5;
System.out.println("如果断言正常,我就被打印");
}
}
经过反编译后:
public static void main(String args[]) {
if (!$assertionsDisabled && i != 5) {
throw new AssertionError();
} else {
System.out.println("如果断言正常,我就被打印");
return;
}
}
如果要开启断言检查,则需要用开关 -enableassertions 或 -ea 来开启(通过启动参数来加)。其实断言的底层实现就是 if 判断,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。assert 断言就是通过对布尔标志位进行了一个 if 判断。
!$assertionsDisabled && i != 5
意思就是只要开启断言功能了,并且i不等于5直接报异常。
十二、try-with-resources
JDK 1.7 开始,java引入了 try-with-resources 声明,作用就是将省去手动关流,这其实是一种语法糖,在编译时会进行转化为 try-catch-finally 语句。
如下就是try-with-resources的使用方法,基本上项目当中很少用,我认为很少用主要是因为很多人没有去真正了解过他,但是说实话真的很方便。
public class TryWithResourcesTest {
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream(new File("xxx"))) {
inputStream.read();
} catch (Exception e) {
e.printStackTrace();
}
}
}
经过反编译后:
public static void main(String[] args) {
try {
FileInputStream var1 = new FileInputStream(new File("xxx"));
Throwable var2 = null;
try {
var1.read();
} catch (Throwable var12) {
var2 = var12;
throw var12;
} finally {
if (var1 != null) {
if (var2 != null) {
try {
var1.close();
} catch (Throwable var11) {
var2.addSuppressed(var11);
}
} else {
var1.close();
}
}
}
} catch (Exception var14) {
var14.printStackTrace();
}
}
可以看到,生成的 try-with-resources 经过编译后还是使用的 try…catch…finally 语句,只不过这部分工作由编译器替我们做了,这样能让我们的代码更加简洁,从而消除样板代码。
注意:使用try-with-resources来自动关流最主要的一点是变量必须是实现AutoCloseable接口。基本上涉及到流的都实现了,举个最典型的:InputStream、OutputStream
try-with-resources语句能放多个资源
try (ZipFile zf = new ZipFile(zipFileName);
BufferedWriter writer = newBufferedWriter(outputFilePath, charset)
) {
//执行任务
}
最后任务执行完毕或者出现异常中断之后是根据new的反向顺序调用各资源的close()的。例如这里先关闭writer再关闭zf。
十三、字符串相加
13.1、字符串拼接背后的秘密
这个想必大家应该都知道,字符串的拼接有两种,如果能够在编译时期确定拼接的结果,那么使用 + 号连接的字符串会被编译器直接优化为相加的结果,如果编译期不能确定拼接的结果,底层会直接使用 StringBuilder 的 append 进行拼接。
代码示例:
public class StringAppendTest {
public static void main(String[] args) {
String s1 = "I am " + "cxuan";
String s2 = "I am " + new String("cxuan");
String s3 = "I am ";
String s4 = "cxuan";
String s5 = s3 + s4;
}
}
经过反编译后:
这里有一点需要注意,反编译之后竟然变量名称发生了变化。
public static void main(String args[]) {
String s = "I am cxuan";
String s1 = (new StringBuilder()).append("I am ").append(new String("cxuan")).toString();
String s2 = "I am ";
String s3 = "cxuan";
String s4 = (new StringBuilder()).append(s2).append(s3).toString();
}
首先来看一下 s1 ,s1 因为 = 号右边是两个常量,所以两个字符串拼接会被直接优化成为 I am cxuan。
而 s2 由于在堆空间中分配了一个 cxuan 对象,所以 + 号两边进行字符串拼接会直接转换为 StringBuilder ,调用其 append 方法进行拼接,最后再调用 toString() 方法转换成字符串。
而由于 s5 进行拼接的两个对象在编译期不能判定其拼接结果,所以会直接使用 StringBuilder 进行拼接。
13.2、String不可变?
String类是不可变类,即一旦一个String对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁。
如下:
String a = "123";
a = "456";
// 打印出来的a为456
System.out.println(a)
这不是明明已经对他进行修改了吗?为什么还说他是一个不可变类呢?接下来就看一张上述a对象的内存存储空间图
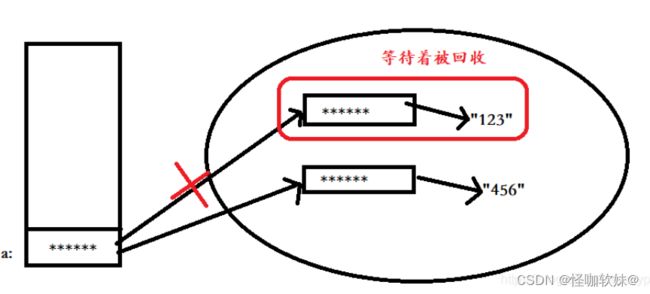
可以看出来,再次给a赋值时,并不是对原来堆中实例对象进行重新赋值,而是生成一个新的实例对象,并且指向“456”这个字符串,a则指向最新生成的实例对象,之前的实例对象仍然存在,如果没有被再次引用,则会被垃圾回收。
String底层存储的实际上是一个final修饰的char数组,数组属于引用类型,final修饰的数组一旦赋值就不可再让他指向别的对象。例如:
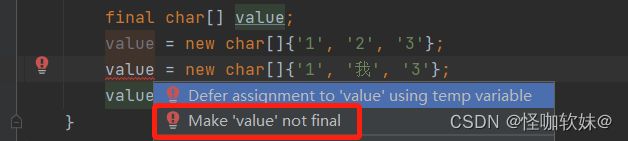
其次数组在实例化的时候必须知道其长度。所以一般我们说的不可变更多的是指,这个数组不可变,但是数组实例化之后我们是可以根据下标进行修改数组存的值的。但是string当中并没有对外提供修改string内部数组的方法,例如:
final char value[];
value = new char[]{'1', '2', '3'};
value[1] = '6';
String类是我们平常项目中使用频率非常高的一种对象类型,jvm为了提升性能和减少内存开销,避免字符的重复创建,其维护了一块特殊的内存空间,即字符串池,当需要使用字符串时,先去字符串池中查看该字符串是否已经存在,如果存在,则可以直接使用,如果不存在,初始化,并将该字符串放入字符创常量池中。
使用new String赋值不可以吗?可以,但是我们开发中不建议用new String()的方式去创建字符串,两种创建方法的区别:
- String str1= “abc”; 在编译期,JVM会去常量池来查找是否存在“abc”,如果不存在,就在常量池中开辟一个空间来存储“abc”;如果存在,就不用新开辟空间。
然后在栈内存中开辟一个名字为str1的空间,来存储“abc”在常量池中的地址值。(这个通过代码都可以证明的,其次是String str1= “abc”这种赋值,你会发现debug之后他根本没有走String的任何方法,就连构造器他都没有走,彻彻底底变成了个基本类型赋值) - String str2 = new String(“abc”) ;在编译阶段JVM先去常量池中查找是否存在“abc”,如果过不存在,则在常量池中开辟一个空间存储“abc”。在运行时期,通过String类的构造器
在堆内存中new了一个空间,然后将String池中的“abc”复制一份存放到该堆空间中,在栈中开辟名字为str2的空间,存放堆中new出来的这个String对象的地址值。
前者会将栈当中的变量值直接指向常量池,后者是将常量池当中的字符串,会复制一份到堆当中,而栈指向的是堆内存。
也就是说,前者在初始化的时候可能创建了一个对象,也可能一个对象也没有创建;后者因为new关键字,至少在内存中创建了一个对象,也有可能是两个对象。
总结:string之所以不可变是因为底层用了final修饰的数组来进行存储,final修饰的数组一旦被初始化赋值之后,是不可以再将它指向别的地址的。虽然可以通过下标的方式修改数组的内容,但是String并未对外提供修改的方法。由此得出String一旦赋值便不可再进行改变。
13.3、String常见面试题
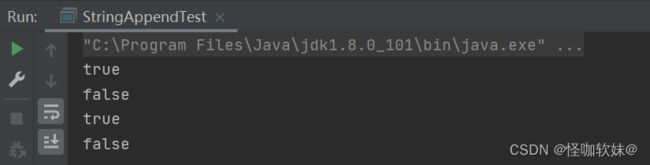
public class StringAppendTest {
public static void main(String[] args) {
//情况一
String a = "a2";
String a2 = "a" + 2;
//在编译期值是确定的就是a2。只有编译期变量a与变量a2值相等他们才相等
System.out.println(a == a2);
//情况二
String b = "b2";
int bb = 2;
String b2 = "b" + bb;
//在编译期变量b2的值不是确定的,因为bb是变量,变量在运行期才能确定值.所以b与b2不等
System.out.println(b == b2);
//情况三
String c = "c2";
final int cc = 2;
String c2 = "c" + cc;//在编译期c2的值是确定的,因为cc是个常量,值为2
System.out.println(c == c2);
//情况四
String d = "d2";
final int dd = getZ();
String d2 = "d" + dd;
//在编译器d2的值是不确定的,因为dd还没有确定,因为dd的值是靠方法返回来的,但是方法的结果是在运行期才能得到的
System.out.println(d == d2);//(对于两个对象,==的作用是比较他们的地址。)
}
public static int getZ() {
return 2;
}
}
返回结果:
13.4、String、StringBuffer和StringBuilder的区别
StringBuffer和StringBuilder内部也是使用的数组,但是他并没有使用final修饰。也就意味着调用append()、insert()、reverse()、setCharAt()、setLength()等方法实际上是操作的一个对象数组。而相比较String,他并没有这些类似的方法。
底层都是用的数组,那StringBuffer和StringBuilder怎么实现的可变长数组的?
数组一旦初始化之后不可以修改长度的,而StringBuffer和StringBuilder给我们的印象却是他可以无限拼接字符串,答案他真的可以无限拼接,只不过他是当数组长度不够的时候再创建一个新的数组,然后将新数组的每个下标指向老数组的每个下标。可以理解为浅克隆。
使用的是Arrays类的copyOf方法,而copyOf方法实际上调用的是System.arraycopy来完成数组的复制。
StringBuffer和StringBuilder的区别
StringBuilder类也代表可变字符串对象。实际上,StringBuilder和StringBuffer基本相似,两个类的构造器和方法也基本相同。不同的是:StringBuffer是线程安全的,而StringBuilder则没有实现线程安全功能,所以性能略高。
为什么StringBuffer是安全的?
他的所有的方法全是使用的synchronized来修饰的。
由此可以得出,我们遇到字符串拼接,一般使用StringBuilder就可以了。除非真的是涉及到多线程了。
13.5、StringBuilder扩容机制
- new StringBuilder()的时候会初始化数组长度为16
- 拿append()举例,当append的时候,他会将(当前占有的数组长度+append传参的字符串长度)求和 然后来和 初始化数组的长度做比较。由此得出是否需要扩容。
- 如果不够存储就将数组的长度进行2倍扩容。2倍扩容的长度如果还不够,那就将扩容的数组长度直接设置成(当前数组占用的长度+参数字符串的长度) 两个的和。
十四、数值字面量
Java中支持如下形式的数值字面量
- 十进制:默认的
- 八进制:整数之前加数字0来表示
- 十六进制:整数之前加"0x"或"0X"
- 二进制(新加的):整数之前加"0b"或"0B"
另外在在jdk7中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读。比如:
- 1_500_000
- 5_6.3_4
- 89_3___1
下划线只能出现在数字中间,前后必须是数字。所以“_100”、“0b_101“是不合法的,无法通过编译。
这样限制的动机就是可以降低实现的复杂度。有了这个限制,Java编译器只需在扫描源代码的时候将所发现的数字中间的下划线直接删除就可以了。如果不添加这个限制,编译器需要进行语法分析才能做出判断。比如:_100,可能是一个整数字面量100,也可能是一个变量名称。这就要求编译器的实现做出更复杂的改动。
代码示例:
public class Test {
public static void main(String[] args) {
//十进制
int a = 10;
//二进制
int b = 0B1010;
//八进制
int c = 012;
//十六进制
int d = 0XA;
double e = 12_234_234.23;
System.out.println("a:" + a);
System.out.println("b:" + b);
System.out.println("c:" + c);
System.out.println("d:" + d);
System.out.println("e:" + e);
}
}
反编译过后:

十五、匿名内部类
匿名内部类,就是没有名字的一种嵌套类。它是Java对类的定义方式之一。
匿名内部类可以用在具体类、抽象类、接口上,且对方法个数没有要求。
在实际开发中,我们常常遇到这样的情况:一个接口/类的方法的某个实现方式在程序中只会执行一次,但为了使用它,我们需要创建它的实现类/子类去实现/重写。此时可以使用匿名内部类的方式,可以无需创建新的类,减少代码冗余。
假设当前有一个接口,接口中只有一个方法
public interface Interface01 {
void show();
}
为了使用该接口的show方法,我们需要去创建一个实现类,同时书写show方法的具体实现方式
public class Interface01Impl implements Interface01{
@Override
public void show() {
System.out.println("I'm a impl class...");
}
}
如果实现类Interface01Impl全程只使用一次,那么为了这一次的使用去创建一个类,未免太过麻烦。我们需要一个方式来帮助我们摆脱这个困境。匿名内部类则可以很好的解决这个问题。
我们使用匿名内部类
public class Test {
public static void main(String[] args) {
Interface01 interface01 = new Interface01() {
@Override
public void show() {
System.out.println("这里使用了匿名内部类");
}
};
//调用接口方法
interface01.show();
}
}
通过反编译我们来看看内部类到底是怎么实现的,这里我们就不再使用jad了,直接使用javac编译成class,我们看class文件就可以。
反编译的时候注意:由于内部类使用到接口了,所以我们要同时反编译这两个,不然在编译完接口再编译Test类的时候是会报错的。

至此,我们可以得知,匿名内部类在编译期间,会生成一个名称以$编号结尾的class文件,即它被识别为一个真实的类,仅在编译前(java文件)为匿名的形态。
十六、运算符
16.1、i=i++; 代码分析
这个问题经常在面试的笔试题当中会出现。可能要比下面的复杂的多,但是我们只要明白i=i++;的运行逻辑,他再怎么复杂,我们也能知道。
代码示例:
public class Test {
public static void main(String[] args) {
int i = 1;
i = i++;
System.out.println(i);
}
}
输出结果:1
经过反编译后,我们观察class文件,注意这里不再使用jad来反编译了,jad反编译后结果不是很明显。
反编译过后会发现参数名称发生了变化,这个不是我们要关注的,class文件主要关注的是运行结果和java文件一致,至于名字变不变这都无所谓的。
通过以下反编译结果会发现,实际上i = i++;一行代码变成了三行代码。接下来对着三行代码进行解析。
public static void main(String[] var0) {
byte var1 = 1; // 等同于int i = 1;
byte var10000 = var1; // 将i的值赋值给了一个临时变量var10000
int var2 = var1 + 1; // i++赋值给了var2
var1 = var10000; // 最后将临时变量赋值给了var1(i)
System.out.println(var1); // 最后输出了var1
}
i = i++; 代表的是先运算的i=i 然后再进行的i++,其实这个理解是错误的,通过上面反编译结果得出:实际上是先运算的i++这一点毋庸置疑,i++这个运算实际上是产生了一个新的变量,而新的变量最终并没有赋值给i。并且值得注意的是i=i++;实际上i 重新赋值了一遍 i没有加一之前的值。
注意:只要遇到i = i++; 就记住i实际值根本没变,不管是i++;还是++i;还是i = ++i;他们都会进行+1操作并返回。唯独i = i++; 特殊。
16.2、常见面试题
面试题一:
public static void main(String[] args) {
int a = 0;
for (int i = 0; i < 99; i++) {
a = a ++;
}
System.out.println(a);
}
输出结果为0
面试题二:
public static void main(String[] args) {
int b = 0;
for (int i = 0; i < 99; i++) {
b = ++ b;
}
System.out.println(b);
}
输出结果为99
面试题三:
public static void main(String[] args) {
Integer a = 1; // Integer也是扰乱视线的,换成int结果也不会变
int b = 0;
for (int i = 0; i < 99; i++) {
a = a++; // 这段代码就是扰乱视线用的,其实一点用都没有
b = a++; // 到最后一圈循环的时候b赋值了a没有加一的值,所以输出了98
}
System.out.println(a);
System.out.println(b);
}
输出结果a=99、b=98
十七、Lambda表达式
Lambda表达式虽然看着很先进,但其实Lambda表达式的本质只是一个"语法糖",由编译器推断并帮你转换包装为常规的代码,因此你可以使用更少的代码来实现同样的功能。
Labmda表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个JVM底层提供的lambda相关api。
先来看一个简单的lambda表达式。遍历一个list:
public class Test {
public static void main(String[] args) {
List list = Arrays.asList("张三", "李四", "王五");
list.forEach(s -> System.out.println(s));
}
}
使用jad反编译的时候一直报错。因此引出了另一款反编译工具–CFR。
官网链接:http://www.benf.org/other/cfr/
相较于jad,CFR是复杂的,需要输入多个参数,但是CFR可以编译Java9,10,12中的新功能,甚至可以将其他JVM语言的class文件反编译成Java文件。
注意:从官网下载下来之后他就是一个jar包,然后我们通过下面Java -jar命令来进行反编译class文件。
我们继续反编译文章开头代码的字节码文件,采用CFR命令
java -jar D:/cfr-0.152.jar Test.class --decodelambdas false
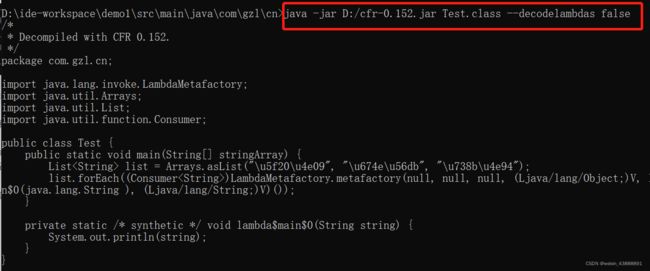
可以看到,在forEach方法中,其实是调用了java.lang.invoke.LambdaMetafactory#metafactory方法,该方法的第四个参数implMethod指定了方法实现。可以看到这里其实是调用了一个
lambda$main$0方法进行了输出。而lambda$main$0方法会发现就是在这个类当中。
所以,lambda表达式的实现其实是依赖了一些底层的api,在编译阶段,编译器会把lambda表达式进行解糖,转换成调用内部api的方式。