kubernetes-工作负载-Deployment
文章目录
- 前言
- Deployment 的作用
- Deployment 语法
- 查看 Deployment 状态
- 管理模式
- DeploymeStatus
- 参考

前言
Kubernetes 提供了几个内置的 API 来声明式管理工作负载及其组件。
最终,你的应用以容器的形式在 Pods 中运行; 但是,直接管理单个 Pod 的工作量将会非常繁琐。例如,如果一个 Pod 失败了,你可能希望运行一个新的 Pod 来替换它。Kubernetes 可以为你完成这些操作。
你可以使用 Kubernetes API 创建工作负载对象, 这些对象所表达的是比 Pod 更高级别的抽象概念,Kubernetes 控制平面根据你定义的工作负载对象规约自动管理 Pod 对象。
Deployment (也间接包括 ReplicaSet) 是在集群上运行应用的最常见方式。Deployment 适合在集群上管理无状态应用工作负载, 其中 Deployment 中的任何 Pod 都是可互换的,可以在需要时进行替换。 (Deployment 替代原来的 ReplicationController API)。
Deployment 的作用
- 定义一组Pod的期望数量:通过配置Deployment的副本数量(Replicas),可以指定期望运行的Pod数量。控制器会确保Pod的数量与期望的数量一致。
- 管理Pod的发布方式:Deployment可以配置Pod的发布策略,例如滚动更新(Rolling Update)和蓝绿部署(Blue-Green Deployment)等。控制器会根据给定的策略更新Pod资源,以确保更新过程中可用的Pod数量和不可用的Pod数量都在限定范围内。
- 回滚操作:Deployment支持回滚操作,可以记录多个前置版本(数量可通过配置设置revisionHistoryLimit)。当更新出现问题时,可以回滚到之前的稳定版本。
- 弹性扩展:通过调整Deployment的副本数量,可以实现Pod的弹性扩展,以满足不同的负载需求。
- 自动化管理:Deployment控制器会自动管理Pod的生命周期,包括创建、更新、删除等。这样可以简化应用程序的部署和管理过程。
Deployment 语法
apiVersion: extensions/v1beta1 # 指定api版本,此值必须在kubectl api-versions中
kind: Deployment # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: demo # 资源的名字,在同一个namespace中必须唯一
namespace: test # 部署在哪个namespace中
labels: # 设定资源的标签
app: nginx
version: v1
spec: # 资源规范字段
replicas: 1 # 声明副本数目
revisionHistoryLimit: 3 # 保留历史版本
selector: # 选择器
matchLabels: # 匹配标签
app: nginx
version: v1
minReadySeconds: 30 #定义新建的 Pod 经过多少秒后才被视为可用
terminationGracePeriodSeconds: 30 #30秒内 (默认 30s) 还未完全停止,就发送 SIGKILL 信号强制杀死进程。
progressDeadlineSeconds: 600 #升级过程中的最大时间(如果升级过程被暂停了,该时间也会同步暂停,时间不会一直增长)
strategy: # 策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 示在更新过程中能够进入不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
type: RollingUpdate # 滚动更新策略
template: # 模版
metadata: # 资源的元数据/属性
annotations: # 自定义注解列表
sidecar.istio.io/inject: "false" # 自定义注解名字
labels: # 设定资源的标签
app: nginx
version: v1
spec: # 资源规范字段
containers:
- name: nginx# 容器的名字
image: nginx:1.17.0 # 容器使用的镜像地址
imagePullPolicy: IfNotPresent # 每次Pod启动拉取镜像策略,三个选择 Always、Never、IfNotPresent
# Always,每次都检查;
# Never,每次都不检查(不管本地是否有);
# IfNotPresent,如果本地有就不检查,如果没有就拉取(手动测试时,已经打好镜像存在docker容器中时,
# 使用存在不检查级别, 默认为每次都检查,然后会进行拉取新镜像,因镜像仓库不存在,导致部署失败)
volumeMounts: #文件挂载目录,容器内配置
- mountPath: /data/ #容器内要挂载的目录
name: share #定义的名字,需要与下面vloume对应
resources: # 资源管理
limits: # 最大使用
cpu: 300m # CPU,1核心 = 1000m
memory: 500Mi # 内存,1G = 1000Mi
requests: # 容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 100m
memory: 100Mi
livenessProbe: # pod 内部健康检查的设置
httpGet: # 通过httpget检查健康,返回200-399之间,则认为容器正常
path: /healthCheck # URI地址
port: 8080 # 端口
scheme: HTTP # 协议
# host: 127.0.0.1 # 主机地址
initialDelaySeconds: 30 # 表明第一次检测在容器启动后多长时间后开始
timeoutSeconds: 5 # 检测的超时时间
periodSeconds: 30 # 检查间隔时间
successThreshold: 1 # 成功门槛
failureThreshold: 5 # 失败门槛,连接失败5次,pod杀掉,重启一个新的pod
readinessProbe: # Pod 准备服务健康检查设置
httpGet:
path: /healthCheck
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
#也可以用这种方法
#exec: 执行命令的方法进行监测,如果其退出码不为0,则认为容器正常
# command:
# - cat
# - /tmp/health
#也可以用这种方法
#tcpSocket: # 通过tcpSocket检查健康
# port: number
ports:
- name: http # 名称
containerPort: 8080 # 容器开发对外的端口
protocol: TCP # 协议
imagePullSecrets: # 镜像仓库拉取密钥
- name: harbor-certification
volumes: #挂载目录在本机的路径
- name: share #对应上面的名字
hostPath:
path: /data #挂载本机的路径
affinity: # 亲和性调试
nodeAffinity: # 节点亲和力
requiredDuringSchedulingIgnoredDuringExecution: # pod 必须部署到满足条件的节点上
nodeSelectorTerms: # 节点满足任何一个条件就可以
- matchExpressions: # 有多个选项,则只有同时满足这些逻辑选项的节点才能运行 pod
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
查看 Deployment 状态
当我们创建出一个 Deployment 的时候,可以通过 kubectl get deployment,看到 Deployment 总体的一个状态。
字段含义
- DESIRED:期望的 Pod 数量;
- CURRENT:当前实际 Pod 数量;
- UP-TO-DATE:其实是到达最新的期望版本的 Pod 数量;
- AVAILABLE:这个其实是运行过程中可用的 Pod 数量。后面会提到,这里 AVAILABLE 并不简单是可用的,也就是 Ready 状态的,它其实包含了一些可用超过一定时间长度的 Pod;
- AGE:deployment 创建的时长,如80m表示80分钟。
管理模式
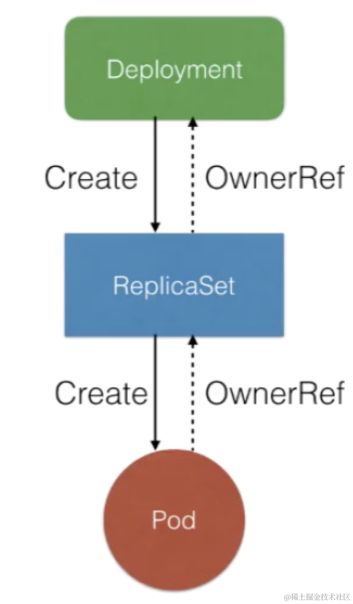
通过kubectl get pods --show-labels查看deployment创建的pod,可以看到类似的内容
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
可以看到最前面一段其实是 Pod 所属 Deployment.name;中间一段:template-hash,这里多个 Pod 是一样的,因为这三个 Pod 其实都是同一个 template 中创建出来的;最后一段,是一个 random 的字符串,我们通过 get.pod 可以看到,Pod 的 ownerReferences 即 Pod 所属的 controller 资源,并不是 Deployment,而是一个 ReplicaSet。这个 ReplicaSet 的 name,其实是 deloyment.name 加上 pod.template-hash。所有的 Pod 都是 ReplicaSet 创建出来的,而 ReplicaSet 它对应的某一个具体的 Deployment.template 版本。
注意 ReplicaSet 的名称格式始终为 [Deployment 名称]-[哈希]。 该名称将成为所创建的 Pod 的命名基础。 其中的哈希字符串与 ReplicaSet 上的 pod-template-hash 标签一致。
Deployment 控制器将 pod-template-hash 标签添加到 Deployment 所创建或收留的每个 ReplicaSet 。
此标签可确保 Deployment 的子 ReplicaSets 不重叠。 标签是通过对 ReplicaSet 的 PodTemplate 进行哈希处理。 所生成的哈希值被添加到 ReplicaSet 选择算符、Pod 模板标签,并存在于在 ReplicaSet 可能拥有的任何现有 Pod 中。
DeploymeStatus
每一个资源都有它的 spec.Status。这里可以看一下,deploymentStatus 中描述的三个其实是它的 conversion 状态,也就是 Processing、Complete 以及 Failed。
以 Processing 为例:Processing 指的是 Deployment 正在处于扩容和发布中。比如说 Processing 状态的 deployment,它所有的 replicas 及 Pod 副本全部达到最新版本,而且是 available,这样的话,就可以进入 complete 状态。而 complete 状态如果发生了一些扩缩容的话,也会进入 processing 这个处理工作状态。
如果在处理过程中遇到一些问题:比如说拉镜像失败了,或者说 readiness probe 检查失败了,就会进入 failed 状态;如果在运行过程中即 complete 状态,中间运行时发生了一些 pod readiness probe 检查失败,这个时候 deployment 也会进入 failed 状态。进入 failed 状态之后,除非所有点 replicas 均变成 available,而且是 updated 最新版本,deployment 才会重新进入 complete 状态。
参考
- https://kubernetes.io/docs/concepts/overview/
- 阿里云——云原生技术公开课