Springboot整合ElasticSearch
Springboot整合ElasticSearch
一、安装ES
在window上安装
下载地址 https://www.elastic.co/cn/downloads/elasticsearch
下载的安装包是解压缩就能使用的zip文件,解压缩完毕后会得到如下文件
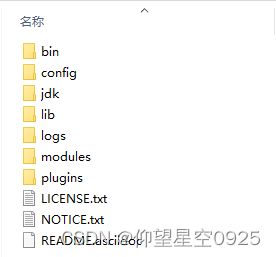
- bin目录:包含所有的可执行命令
- config目录:包含ES服务器使用的配置文件
- jdk目录:此目录中包含了一个完整的jdk工具包,版本17,当ES升级时,使用最新版本的jdk确保不会出现版本支持性不足的问题
- lib目录:包含ES运行的依赖jar文件
- logs目录:包含ES运行后产生的所有日志文件
- modules目录:包含ES软件中所有的功能模块,也是一个一个的jar包。和jar目录不同,jar目录是ES运行期间依赖的jar包,modules是ES软件自己的功能jar包
- plugins目录:包含ES软件安装的插件,默认为空
启动服务器
elasticsearch.bat
双击elasticsearch.bat文件即可启动ES服务器,默认服务端口9200。通过浏览器访问http://localhost:9200看到如下信息视为ES服务器正常启动
{
"name" : "CZBK-**********",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "j137DSswT-0T1Mg",
"version" : {
"number" : "7.16.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "2b937c44140b6559905130a8650c64dbd0879cfb",
"build_date" : "2021-12-18T19:42:46.604893745Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
安装IK分词器
IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
分词器下载后解压到ES安装目录的plugins目录中即可,安装分词器后需要重新启动ES服务器。使用IK分词器创建索引格式:
PUT请求 http://localhost:9200/books
请求参数如下(注意是json格式的参数)
{
"mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性
"properties":{ #定义索引中包含的属性设置
"id":{ #设置索引中包含id属性
"type":"keyword" #当前属性可以被直接搜索
},
"name":{ #设置索引中包含name属性
"type":"text", #当前属性是文本信息,参与分词
"analyzer":"ik_max_word", #使用IK分词器进行分词
"copy_to":"all" #分词结果拷贝到all属性中
},
"type":{
"type":"keyword"
},
"description":{
"type":"text",
"analyzer":"ik_max_word",
"copy_to":"all"
},
"all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
二、Springboot项目整合ES
导入依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
配置yml文件
spring:
elasticsearch:
rest:
uris: http://localhost:9200
ES服务器默认端口为9200
ES配置类
@Configuration
public class EsConfig {
@Value("${elasticSearch.url}")
public String esUrl;
@Bean
public RestHighLevelClient client() {
return new RestHighLevelClient(RestClient.builder(HttpHost.create(esUrl)));
}
}
使用方式
创建索引:
@Resource
private RestHighLevelClient client;
@Test
void testCreateIndexQuestionByIK() throws IOException {
//索引名 questions
CreateIndexRequest request = new CreateIndexRequest("questions");
//索引格式
String json = "{\n" +
"\t\"mappings\":{\n" +
" \t\"questions\":{\n" +
" \"properties\":{\n" +
" \t\t\"id\":{\n" +
" \"type\":\"keyword\"\n" +
" \t\t},\n" +
" \t\t\"questionId\":{\n" +
" \"type\":\"keyword\"\n" +
" \t\t},\n" +
" \t\t\"questionTitle\":{\n" +
" \"type\":\"text\",\n" +
" \t\t\"analyzer\":\"ik_max_word\",\n" +
" \t\t\"copy_to\":\"all\"\n" +
" \t\t},\n" +
" \t\t\"all\":{\n" +
" \"type\":\"text\",\n" +
" \t\t\"analyzer\":\"ik_max_word\"\n" +
" \t\t}\n" +
" }\n" +
" }\n" +
"\t}\n" +
"}";
//设置请求中的参数
request.source(json, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
添加数据库中对应所有元素(批量添加):
@Test
void testCreateQuestionAll() throws IOException {
//获取数据库中元素列表
List<Question> questionList = questionMapper.getQuestionList(null);
BulkRequest bulk = new BulkRequest();
for (Question question : questionList) {
QuestionDTO questionDTO = new QuestionDTO(question.getQuestionId(),question.getQuestionTitle());
//指定id
IndexRequest request = new IndexRequest("questions").id(questionDTO.getQuestionId().toString());
//将对象JSON化
String json = JSON.toJSONString(questionDTO);
request.source(json,XContentType.JSON);
bulk.add(request);
}
client.bulk(bulk,RequestOptions.DEFAULT);
}
添加文档:
@Test
//添加文档
void testCreateDoc() throws IOException {
Book book = bookDao.selectById(1);
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
}
添加文档使用的请求对象是IndexRequest,与创建索引使用的请求对象不同。
按id查询文档:
@Test
//按id查询
void testGet() throws IOException {
GetRequest request = new GetRequest("books","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
System.out.println(json);
}
根据id查询文档使用的请求对象是GetRequest。
按条件查询文档:
@Test
//按条件查询
void testSearch() throws IOException {
SearchRequest request = new SearchRequest("books");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termQuery("all","spring"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
String source = hit.getSourceAsString();
//System.out.println(source);
Book book = JSON.parseObject(source, Book.class);
System.out.println(book);
}
}
按条件查询文档使用的请求对象是SearchRequest,查询时调用SearchRequest对象的termQuery方法,需要给出查询属性名,此处支持使用合并字段,也就是前面定义索引属性时添加的all属性。
高级使用(包括模拟匹配,高亮显示):
@Service
public class Service {
@Resource
private RestHighLevelClient client;
public List<VideoDTO> searchVideo(String name) throws IOException {
List<VideoDTO> list = new ArrayList<>();
//设置查询索引
SearchRequest searchRequest = new SearchRequest("videos");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//模糊匹配
searchSourceBuilder.query(QueryBuilders
.fuzzyQuery("all", name)
.fuzziness(Fuzziness.AUTO));
//高亮显示
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("name")
//若有关键字切可以分词,则可以高亮,写*可以匹配所有字段
.field("introduction")
//因为高亮查询默认是对查询字段即description就行高亮,可以关闭字段匹配,
// 这样就可以对查询到的多个字段(前提是有关键词并且改字段可以分词)进行高亮显示
.requireFieldMatch(false)
//手动前缀标签
.preTags("")
.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
//遍历查询
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
String source = hit.getSourceAsString();
//获取类
VideoDTO videoDTO = JSON.parseObject(source, VideoDTO.class);
//获取高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//如果高亮字段包含在introduction中
if (highlightFields.containsKey("introduction")){
Text[] fragments = highlightFields.get("introduction").getFragments();
for (Text fragment : fragments) {
//改变属性
videoDTO.setIntroduction(fragment.toString());
}
}
//如果高亮字段包含在name中
if (highlightFields.containsKey("name")){
Text[] fragments = highlightFields.get("name").getFragments();
for (Text fragment : fragments) {
videoDTO.setName(fragment.toString());
}
}
//将实体类添加到集合
list.add(videoDTO);
}
return list;
}
}