SG Former论文学习笔记
超越SWin和CSWin Transformer的新模型

代码地址:https://github.com/OliverRensu/SG-Former
论文地址:https://arxiv.org/pdf/2308.12216.pdf
ViT在各种视觉任务中虽然成功,但它的计算成本随着Token序列长度的增加呈二次增长,这在处理大型特征图时大大限制了其性能。为了减轻计算成本,先前的研究依赖于要么限制在局部小区域内的细粒度Self-Attention,要么采用全局Self-Attention,但要缩短序列长度,从而导致粗粒度的问题。
Self-Guided Transformer(SG-Former),以实现具有自适应细粒度的有效全局Self-Attention。本文方法的核心思想是利用一个显著性图,通过混合尺度的Self-Attention估计并在训练过程中自我演化,以根据每个区域的重要性重新分配Token。直观地说,为显著区域分配更多的Token,以实现细粒度的注意力,同时将更少的Token分配给次要区域,以换取效率和全局感知字段。SG-Former在分类,检测和分割任务中都较最先进的模型有提升。

为了在高分辨率特征上计算Self-Attention,一些方法提出了将Self-Attention区域限制在局部窗口而不是整个特征图(即细粒度的局部Self-Attention)。例如,Swin Transformer设计了窗口注意力,而CSWin设计了交叉形状注意力。因此,这些方法牺牲了在每个Self-Attention层中建模全局信息的能力。另一流方法旨在在整个键-值特征映射中聚合Token,以减少全局序列长度(即粗粒度的全局注意力)。例如,金字塔视觉Transformer(PVT)使用大步幅的大核心来均匀聚合整个特征映射上的Token,从而导致整个特征映射上的均匀粗糙信息。
本文的Self-Guided Transformer(SG-Former),通过一种不断演化的Self-Attention设计,实现了具有自适应细粒度的全局关注。SG-Former的核心思想在于,其保留了整个特征图上的远程依赖性,同时根据图像区域的重要性重新分配Token。
也就是说模型会为显著区域分配更多的Token,以便每个Token可以与显著区域以细粒度进行交互,同时为了效率将更少的Token分配给次要区域。SG-Former以高效的全局感知场计算Self-Attention,同时自适应地关注显著区域中的细粒度信息。

如图2所示,SG-Former根据从自身获得的注意力图重新分配Token,例如在狗这样的显著区域分配更多的Token,而在墙这样的次要区域分配更少的Token。 PVT采用了预定义的策略均匀聚合Token。
具体来说,保留了 Query Token,但重新分配了Key和Value Token以实现高效的全局Self-Attention。图像区域的重要性,以得分图的形式,通过混合尺度的Self-Attention本身估计,并进一步用于引导Token的重新分配。
也就是说,给定输入图像,Token的重新分配是通过Self-Guided完成的,这意味着每个图像都经历了一个仅适用于自身的独特的Token重新分配。因此,重新分配的Token受到人类先验的影响较小。
此外,这种Self-Guided会随着训练过程中逐渐精确的注意力图预测而不断演化。注意力图极大地影响了重新分配的有效性,因此提出了一种混合尺度的Self-Attention,该Self-Attention在同一层中具有与Swin相同成本的各种粒度信息。混合尺度Self-Attention通过分组Head和为不同的注意力粒度多样化每个组来实现各种粒度信息。混合尺度Self-Attention还向整个Transformer提供混合尺度信息。
本文有以下贡献:
1、细粒度的局部和全局粗粒度信息在一个Self-Attention层内,通过统一的混合尺度信息提取。具有统一的局部全局混合尺度信息,预测注意力图以识别区域重要性。
2、有了注意力图,可以模拟Self-Guided Attention,自动定位显著区域,并使显著区域提取细粒度信息,而使次要区域提取粗粒度信息以减少计算成本。
3、在分类、目标检测和分割任务中相较最先进的模型有明显提升。
下面结合代码来对论文进行讲解,代码部分以sgformer_s的配置进行分解。
具体的参数配置可见下表

1.1、Overview
SG-Former的总体流程如图3所示。SG-Former与以前的CNN和Transformer模型共享相同的Patch嵌入层和四阶金字塔架构。

首先,图像![]() 通过输入级别的Patch嵌入层进行4倍降采样。两个阶段之间存在一个2倍速率的降采样层。因此,第
通过输入级别的Patch嵌入层进行4倍降采样。两个阶段之间存在一个2倍速率的降采样层。因此,第 个阶段的特征图的大小为
个阶段的特征图的大小为![]() 。除了最后一个阶段,每个阶段都有
。除了最后一个阶段,每个阶段都有 个Transformer Block,由两种类型的块重复组成:
个Transformer Block,由两种类型的块重复组成:
-
混合尺度 Transformer Block
-
Self-Guided Transformer Block。
混合尺度Self-Attention提取混合尺度对象和多粒度信息,引导区域重要性。Self-Guided Self-Attention模型全局信息,同时根据混合尺度 Transformer Block的重要性信息保持显著区域的细粒度;
先来看看SG Former的代码总体结构,代码示例部分省略了部分参数初始化操作。
class SGFormer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4, linear=False):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
self.num_patches = img_size//4
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
if i == 0:
patch_embed = Head(embed_dims[0]) #
else:
patch_embed = PatchMerging(dim=embed_dims[i - 1],
out_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], mask=True if (j%2==1 and i 0 else nn.Identity()
self.apply(self._init_weights)
def forward_features(self, x):
B = x.shape[0]
mask=None
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x) # [N 3136 64] #[N 784 128] #[N 196 256] #[N 49 512]
if i==0:
x+=self.pos_embed # [1 3136 64]
for blk in block:
x, mask = blk(x, H, W, mask)
x = norm(x) # [N 3136 64] [N 784 128] [N 196 256] [N 49 512]
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() # [N 64 56 56] [N 128 28 28] [N 256 14 14]
return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x) # entry
x = self.head(x)
return x 图像![]() 首先经过Patch embedding(代码中为Head)
首先经过Patch embedding(代码中为Head)
class Head(nn.Module):
def __init__(self, n):
super(Head, self).__init__()
self.conv = nn.Sequential(
Conv2d_BN(3, n, 3, 2, 1),
nn.GELU(),
Conv2d_BN(n, n, 3, 1, 1),
nn.GELU(),
Conv2d_BN(n, n, 3, 2, 1),
)
self.norm = nn.LayerNorm(n)
self.apply(self._init_weights)
def forward(self, x):
x = self.conv(x)
_, _, H, W = x.shape # [N 64 56 56]
x = x.flatten(2)#.transpose(1, 2) # [N 64 3136]
x = x.transpose(1, 2)
x = self.norm(x) # [N 3136 64]
return x, H,W其实就是经过三个2d卷积加BN,中间插入两个GELU激活函数,sequential头尾的两个2d卷积stride为2进行降采样,将输入X=[N,3,224,224]进行4倍降采样为[N,64,56,56],之后再进行维度转换加LayerNorm。
第一层会对Patch embedding的输出加上pos embedding(shape为[1,3136,64])。
中间的Down sampling embedding 则是由PatchMerging完成:
class PatchMerging(nn.Module):
def __init__(self, dim, out_dim):
super().__init__()
self.dim = dim
self.out_dim = out_dim
self.act = nn.GELU()
self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
self.conv2 = Conv2d_BN(out_dim, out_dim, 3, 2, 1, groups=out_dim)
self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
def forward(self, x):
# x B C H W
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv3(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
return x, H, W主要是起到一个降采样的功能。
接下来就是本文的重点模块Transformer Block,由两种类型的块重复组成:
-
混合尺度 Transformer Block
-
Self-Guided Transformer Block。
这两个模块包括基本的Transformer Block都由Block函数构建
class Block(nn.Module):
def __init__(self, dim, mask, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1, linear=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, mask,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio, linear=linear)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.apply(self._init_weights)
def forward(self, x, H, W, mask):
x_, mask = self.attn(self.norm1(x), H, W, mask) # x[N 3136 64] mask[[N 3136],[N 3136]]
x = x + self.drop_path(x_)
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x, maskBlock函数中最重要的就是Attention
1.2、 Transformer Block
通过两种自注意机制,相应地设计了两种类型的Transformer Block。这两种Transformer Block只在注意层上有所不同,而其他所有方面都保持相同:

如图3所示,前3个阶段使用我们提出的混合尺度或Self-Guided Transformer Block进行定制,而对于最后一个阶段,使用了一个标准的 Transformer Block,这是根据以前的Transformer 进行的。请注意,前3个阶段(即N1、N2和N3)的 Transformer Block数量是偶数,而最后一个阶段(即N4)可以是偶数或奇数。
1.3、Hybrid-scale Attention
混合尺度注意力有2个目的:
-
提取混合尺度的全局和细粒度信息,而不比Swin Transformer中的窗口注意力多的计算成本
-
为Self-Guided 注意力提供重要性

如图5所示,输入特征X被投影到 Query (Q)、Key(K)和Value(V)。然后,Multi-Head Self-Attention采用H个独立Head。通常,这些H个独立Head在相同的局部区域内执行操作,因此缺乏Head的多样性。
相比之下,本文将H个Head均匀分成h个组,并将混合尺度和多感受野的注意力注入到这些h个组中,每个组中有![]() 个头(从代码上看,分了一半的head做global注意力,一半做local注意力)。在属于第
个头(从代码上看,分了一半的head做global注意力,一半做local注意力)。在属于第 组的第个Head中,使用尺度
组的第个Head中,使用尺度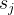 (其中
(其中![]() ),将{K,V}中的每个
),将{K,V}中的每个 ![]() Token 合并为一个 Token 。接下来,将{Q,K,V}分成窗口(和swin一样)。{K,V}的窗口大小设置为M,并在所有组中保持不变。为了使{Q}和{K,V}的窗口大小与{K,V}中的 Token 合并对齐,{Q}的窗口大小选择为
Token 合并为一个 Token 。接下来,将{Q,K,V}分成窗口(和swin一样)。{K,V}的窗口大小设置为M,并在所有组中保持不变。为了使{Q}和{K,V}的窗口大小与{K,V}中的 Token 合并对齐,{Q}的窗口大小选择为![]() ,是{K,V}的窗口大小的倍:
,是{K,V}的窗口大小的倍:

其中![]() 表示将中的每个
表示将中的每个 ![]() Token 合并为一个 Token ,这是通过步长的卷积实现的。特殊情况是当等于1时,不进行 Token 合并,{Q,K,V}具有相同大小的窗口。
Token 合并为一个 Token ,这是通过步长的卷积实现的。特殊情况是当等于1时,不进行 Token 合并,{Q,K,V}具有相同大小的窗口。

其中![]() 表示具有窗口大小
表示具有窗口大小![]() 的窗口划分。
的窗口划分。![]() 是注意力图。有一个特殊情况:
是注意力图。有一个特殊情况:![]() 等于
等于![]() ,不需要窗口分割,{K,V}中的所有 Token 都由{Q}关注,从而实现全局信息提取。
,不需要窗口分割,{K,V}中的所有 Token 都由{Q}关注,从而实现全局信息提取。
Token 的重要性被视为所有 Token 和当前 Token 的乘积之和:

其中S是通过对所有 求和得到的最终注意力图,用于混合尺度引导,提供全局和细粒度信息。对应这部分代码
求和得到的最终注意力图,用于混合尺度引导,提供全局和细粒度信息。对应这部分代码
# global
q1 = self.q1(x).reshape(B, N, self.num_heads//2, C // self.num_heads).permute(0, 2, 1, 3) # [N 1 3136 32] # [N 2 784 32] # [N 4 196 32]
x_ = x.permute(0, 2, 1).reshape(B, C, H, W) # [N 64 56 56] # [N 128 28 28] # [N 256 14 14]
x_1 = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # [N 49 64] sr --> conv2d(64, 64) # [N 49 128] sr --> conv2d(128, 128) # [N 49 256] sr --> conv2d(256, 256)
x_1 = self.act(self.norm(x_1)) # [N 49 64] # [N 49 128] # [N 49 256]
kv1 = self.kv1(x_1).reshape(B, -1, 2, self.num_heads//2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 49 32] # [2 N 2 49 32] # [2 N 4 49 32]
k1, v1 = kv1[0], kv1[1] #B head N C [N 1 49 32] [N 2 49 32] [N 4 49 32]
attn1 = (q1 @ k1.transpose(-2, -1)) * self.scale #B head Nq Nkv [N 1 3136 49] [N 2 784 49] [N 4 196 49]
attn1 = attn1.softmax(dim=-1)
attn1 = self.attn_drop(attn1)
x1 = (attn1 @ v1).transpose(1, 2).reshape(B, N, C//2) # [N 3136 32] [N 784 64] [N 196 128]
global_mask_value = torch.mean(attn1.detach().mean(1), dim=1) # B Nk #max ? mean ? # [N 49]
global_mask_value = F.interpolate(global_mask_value.view(B,1,H//self.sr_ratio,W//self.sr_ratio),
(H, W), mode='nearest')[:, 0] # [N 56 56] [N 28 28] [N 14 14]
# local
q2 = self.q2(x).reshape(B, N, self.num_heads // 2, C // self.num_heads).permute(0, 2, 1, 3) #B head N C # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
kv2 = self.kv2(x_.reshape(B, C, -1).permute(0, 2, 1)).reshape(B, -1, 2, self.num_heads // 2,
C // self.num_heads).permute(2, 0, 3, 1, 4)# [2 N 1 3136 32] [2 N 2 784 32] [2 N 4 196 32]
k2, v2 = kv2[0], kv2[1] # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
q_window = 7
window_size= 7
q2, k2, v2 = window_partition(q2, q_window, H, W), window_partition(k2, window_size, H, W), \
window_partition(v2, window_size, H, W) # [N*64,49,32] [N*32,49,32] [N*16 49 32]
attn2 = (q2 @ k2.transpose(-2, -1)) * self.scale # [N*64 49 49] [N*32 49 49] [N*16 49 49]
# (B*numheads*num_windows, window_size*window_size, window_size*window_size)
attn2 = attn2.softmax(dim=-1)
attn2 = self.attn_drop(attn2)
x2 = (attn2 @ v2) # B*numheads*num_windows, window_size*window_size, C .transpose(1, 2).reshape(B, N, C) # [N*64 49 32] [N*32 49 32] [N*16 49 32]
x2 = window_reverse(x2, q_window, H, W, self.num_heads // 2) # [N 3136 32] [N 784 64] [N 196 128]
local_mask_value = torch.mean(attn2.detach().view(B, self.num_heads//2, H//window_size*W//window_size, window_size*window_size, window_size*window_size).mean(1), dim=2) #[N 64 49]
local_mask_value = local_mask_value.view(B, H // window_size, W // window_size, window_size, window_size) # [N 8 8 7 7]
local_mask_value=local_mask_value.permute(0, 1, 3, 2, 4).contiguous().view(B, H, W) # [N 56 56] [N 28 28] [N 14 14]
# mask B H W
x = torch.cat([x1, x2], dim=-1) # [N 3136 64] [N 784 128] [N 196 256]
x = self.proj(x+lepe) # linear(64,64) # linear(128,128) # linear(256,256)
x = self.proj_drop(x)
# cal mask
mask = local_mask_value+global_mask_value # [N 56 56] [N 28 28] [N 14 14]
mask_1 = mask.view(B, H * W) # [N 3136] [N 784] [N 196]
mask_2 = mask.permute(0, 2, 1).reshape(B, H * W) # [N 3136] [N 784] [N 196]
mask = [mask_1, mask_2]1.4、Self-Guided Attention
尽管Self-Attention模型能够建模广泛的范围信息,但其高计算成本和内存消耗与序列长度的平方成正比,限制了其在各种计算机视觉任务中(如分割和检测)中对大尺寸特征图的适用性。最近的研究建议通过将一些 Token 合并成一个来减小序列长度。然而,这种聚合对待每个 Token 都是平等的,忽视了不同 Token 之间的固有重要性差异。这种聚合面临两个问题:
-
在显著区域,信息可能会丢失或与不相关的信息混合在一起
-
在次要区域或背景区域,大量 Token 对于简单的语义而言是多余的,但需要大量计算
受到这一观察的启发,我们提出了Self-Guided 注意力,它使用重要性作为引导来聚合 Token 。换句话说,在显著区域,保留更多的 Token 以获取细粒度的信息,而在次要区域,保留较少的 Token 以保持Self-Attention的全局视图并同时减少计算成本。

如图4所示,"self-guided"表示Transformer自己在训练期间确定了计算成本降低策略,而不是由人为引入的先验知识,如Swin中的窗口注意力,CSWin中的交叉形状注意力,PVT中的静态空间缩减。
输入特征图![]() 首先投影为 Query (Q),Key(K)和Value(V)。接下来,H个独立的Self-Attention Head并行计算Self-Attention。为了降低计算成本,同时保持Self-Attention之后特征图的大小不变,固定Q的长度,但使用重要性引导聚合模块(IAM)来聚合K和V的 Token 。
首先投影为 Query (Q),Key(K)和Value(V)。接下来,H个独立的Self-Attention Head并行计算Self-Attention。为了降低计算成本,同时保持Self-Attention之后特征图的大小不变,固定Q的长度,但使用重要性引导聚合模块(IAM)来聚合K和V的 Token 。
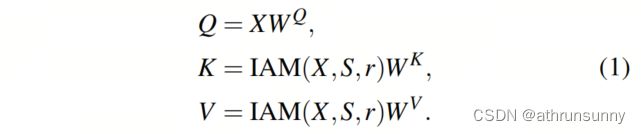
IAM的目标是在显著区域将更少的 Token 聚合为一个(即保留更多的 Token ),在背景区域将更多的 Token 聚合为一个(即保留更少的 Token )。在公式(1)中,注意力图![]() 包含具有多粒度的区域重要性信息。
包含具有多粒度的区域重要性信息。
按升序对注意力图的Value进行排序,并将S均匀分成n个子区域![]() 。因此,
。因此,![]() 和
和![]() 分别是最重要的和次要的区域。同时,根据
分别是最重要的和次要的区域。同时,根据![]() 将
将 中的所有 Token 分组为
中的所有 Token 分组为![]() 。在公式(1)中,
。在公式(1)中, 表示在不同重要性区域的聚合率,以便每个子区域都有一个聚合率,而子区域越重要,聚合率就越小。不同阶段的的具体值列在表1中。因此,IAM通过连接每个组的不同聚合率重新分配了每个组的分组输入特征
表示在不同重要性区域的聚合率,以便每个子区域都有一个聚合率,而子区域越重要,聚合率就越小。不同阶段的的具体值列在表1中。因此,IAM通过连接每个组的不同聚合率重新分配了每个组的分组输入特征![]() 的 Token 。
的 Token 。
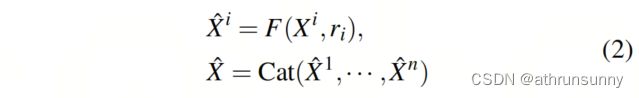
其中![]() 是聚合函数,我们通过具有输入维度r和输出维度1的全连接层来实现它。
是聚合函数,我们通过具有输入维度r和输出维度1的全连接层来实现它。![]() 中的 Token 数量等于
中的 Token 数量等于![]() 中的 Token 数量除以
中的 Token 数量除以 。 对应这部分代码
。 对应这部分代码
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # [N 2 3136 32] [N 4 784 32] [N 8 196 32]
# mask [local_mask global_mask] local_mask [value index] value [B, H, W]
# use mask to fuse
mask_1, mask_2 = mask # [[N 3136],[N 3136]] [[N 784],[N 784]] [[N 196],[N 196]]
mask_sort1, mask_sort_index1 = torch.sort(mask_1, dim=1)
mask_sort2, mask_sort_index2 = torch.sort(mask_2, dim=1)
if self.sr_ratio == 8:
token1, token2, token3 = H * W // (14 * 14), H * W // 56, H * W // 28 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 4:
token1, token2, token3 = H * W // 49, H * W // 14, H * W // 7 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 2:
token1, token2 = H * W // 2, H * W // 1 # [98 196]
token1, token2 = token1 // 2, token2 // 2 # [49 98]
if self.sr_ratio==4 or self.sr_ratio==8:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C # [N 784 64] 根据mask中的index对x[:, :H * W // 4(784)]进行重新排序 [N 196 128]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 64 4 196] # linear(196,1) # [N 128 4 49] # linear(49,1) 次要
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1), # [N 64 28 56] # linear(56,1) # [N 128 28 14] # linear(14,1)
self.f3(p3.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # [N 64 28 28] # linear(28,1) # [N 128 28 7] # linear(7,1) 最重要
# seq1 [N 60 64] # seq1 [N 60 128]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C) # [N 3136 64] [N 784 128]
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 784 64] [N 196 128]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1),
self.f3(p3_.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # seq2 [N 60 64] seq2 [N 60 128]
elif self.sr_ratio==2:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 256 49 2] # linear(2,1)
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C # [N 256 98 1] # linear(1,1)
# seq1 [N 147 256]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C)
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C
# seq2 [N 147 256]
kv1 = self.kv1(seq1).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # kv B heads N C # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv2 = self.kv2(seq2).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv = torch.cat([kv1, kv2], dim=2) # [2 N 2 60 32] # [2 N 4 60 32] # [2 N 8 147 32]
k, v = kv[0], kv[1] # [N 2 60 32] # [N 4 60 32] # [N 8 147 32]
attn = (q @ k.transpose(-2, -1)) * self.scale # [N 2 3136 60] # [N 4 784 60] [N 8 196 147]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [N 3136 64] # [N 784 128] [N 196 256]
x = self.proj(x+lepe)
x = self.proj_drop(x)
mask=None将两部分的合起来看:
class Attention(nn.Module):
def __init__(self, dim, mask, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1, linear=False):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.sr_ratio=sr_ratio
if sr_ratio>1:
if mask:
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv1 = nn.Linear(dim, dim, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias=qkv_bias)
if self.sr_ratio==8:
f1, f2, f3 = 14*14, 56, 28
elif self.sr_ratio==4:
f1, f2, f3 = 49, 14, 7
elif self.sr_ratio==2:
f1, f2, f3 = 2, 1, None
self.f1 = nn.Linear(f1, 1)
self.f2 = nn.Linear(f2, 1)
if f3 is not None:
self.f3 = nn.Linear(f3, 1)
else:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU()
self.q1 = nn.Linear(dim, dim//2, bias=qkv_bias)
self.kv1 = nn.Linear(dim, dim, bias=qkv_bias)
self.q2 = nn.Linear(dim, dim // 2, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias=qkv_bias)
else:
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.lepe_linear = nn.Linear(dim, dim)
self.lepe_conv = local_conv(dim)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.linear = linear
self.apply(self._init_weights)
def forward(self, x, H, W, mask):
B, N, C = x.shape
lepe = self.lepe_conv(
self.lepe_linear(x).transpose(1, 2).view(B, C, H, W)).view(B, C, -1).transpose(-1, -2) # [N 3136 64] #[N 784 128] #[N 196 256] #[N 49 512]
if self.sr_ratio > 1:
if mask is None:
# global
q1 = self.q1(x).reshape(B, N, self.num_heads//2, C // self.num_heads).permute(0, 2, 1, 3) # [N 1 3136 32] # [N 2 784 32] # [N 4 196 32]
x_ = x.permute(0, 2, 1).reshape(B, C, H, W) # [N 64 56 56] # [N 128 28 28] # [N 256 14 14]
x_1 = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # [N 49 64] sr --> conv2d(64, 64) # [N 49 128] sr --> conv2d(128, 128) # [N 49 256] sr --> conv2d(256, 256)
x_1 = self.act(self.norm(x_1)) # [N 49 64] # [N 49 128] # [N 49 256]
kv1 = self.kv1(x_1).reshape(B, -1, 2, self.num_heads//2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 49 32] # [2 N 2 49 32] # [2 N 4 49 32]
k1, v1 = kv1[0], kv1[1] #B head N C [N 1 49 32] [N 2 49 32] [N 4 49 32]
attn1 = (q1 @ k1.transpose(-2, -1)) * self.scale #B head Nq Nkv [N 1 3136 49] [N 2 784 49] [N 4 196 49]
attn1 = attn1.softmax(dim=-1)
attn1 = self.attn_drop(attn1)
x1 = (attn1 @ v1).transpose(1, 2).reshape(B, N, C//2) # [N 3136 32] [N 784 64] [N 196 128]
global_mask_value = torch.mean(attn1.detach().mean(1), dim=1) # B Nk #max ? mean ? # [N 49]
global_mask_value = F.interpolate(global_mask_value.view(B,1,H//self.sr_ratio,W//self.sr_ratio),
(H, W), mode='nearest')[:, 0] # [N 56 56] [N 28 28] [N 14 14]
# local
q2 = self.q2(x).reshape(B, N, self.num_heads // 2, C // self.num_heads).permute(0, 2, 1, 3) #B head N C # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
kv2 = self.kv2(x_.reshape(B, C, -1).permute(0, 2, 1)).reshape(B, -1, 2, self.num_heads // 2,
C // self.num_heads).permute(2, 0, 3, 1, 4)# [2 N 1 3136 32] [2 N 2 784 32] [2 N 4 196 32]
k2, v2 = kv2[0], kv2[1] # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
q_window = 7
window_size= 7
q2, k2, v2 = window_partition(q2, q_window, H, W), window_partition(k2, window_size, H, W), \
window_partition(v2, window_size, H, W) # [N*64,49,32] [N*32,49,32] [N*16 49 32]
attn2 = (q2 @ k2.transpose(-2, -1)) * self.scale # [N*64 49 49] [N*32 49 49] [N*16 49 49]
# (B*numheads*num_windows, window_size*window_size, window_size*window_size)
attn2 = attn2.softmax(dim=-1)
attn2 = self.attn_drop(attn2)
x2 = (attn2 @ v2) # B*numheads*num_windows, window_size*window_size, C .transpose(1, 2).reshape(B, N, C) # [N*64 49 32] [N*32 49 32] [N*16 49 32]
x2 = window_reverse(x2, q_window, H, W, self.num_heads // 2) # [N 3136 32] [N 784 64] [N 196 128]
local_mask_value = torch.mean(attn2.detach().view(B, self.num_heads//2, H//window_size*W//window_size, window_size*window_size, window_size*window_size).mean(1), dim=2) #[N 64 49]
local_mask_value = local_mask_value.view(B, H // window_size, W // window_size, window_size, window_size) # [N 8 8 7 7]
local_mask_value=local_mask_value.permute(0, 1, 3, 2, 4).contiguous().view(B, H, W) # [N 56 56] [N 28 28] [N 14 14]
# mask B H W
x = torch.cat([x1, x2], dim=-1) # [N 3136 64] [N 784 128] [N 196 256]
x = self.proj(x+lepe) # linear(64,64) # linear(128,128) # linear(256,256)
x = self.proj_drop(x)
# cal mask
mask = local_mask_value+global_mask_value # [N 56 56] [N 28 28] [N 14 14]
mask_1 = mask.view(B, H * W) # [N 3136] [N 784] [N 196]
mask_2 = mask.permute(0, 2, 1).reshape(B, H * W) # [N 3136] [N 784] [N 196]
mask = [mask_1, mask_2]
else:
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # [N 2 3136 32] [N 4 784 32] [N 8 196 32]
# mask [local_mask global_mask] local_mask [value index] value [B, H, W]
# use mask to fuse
mask_1, mask_2 = mask # [[N 3136],[N 3136]] [[N 784],[N 784]] [[N 196],[N 196]]
mask_sort1, mask_sort_index1 = torch.sort(mask_1, dim=1)
mask_sort2, mask_sort_index2 = torch.sort(mask_2, dim=1)
if self.sr_ratio == 8:
token1, token2, token3 = H * W // (14 * 14), H * W // 56, H * W // 28 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 4:
token1, token2, token3 = H * W // 49, H * W // 14, H * W // 7 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 2:
token1, token2 = H * W // 2, H * W // 1 # [98 196]
token1, token2 = token1 // 2, token2 // 2 # [49 98]
if self.sr_ratio==4 or self.sr_ratio==8:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C # [N 784 64] 根据mask中的index对x[:, :H * W // 4(784)]进行重新排序 [N 196 128]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 64 4 196] # linear(196,1) # [N 128 4 49] # linear(49,1) 次要
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1), # [N 64 28 56] # linear(56,1) # [N 128 28 14] # linear(14,1)
self.f3(p3.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # [N 64 28 28] # linear(28,1) # [N 128 28 7] # linear(7,1) 最重要
# seq1 [N 60 64] # seq1 [N 60 128]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C) # [N 3136 64] [N 784 128]
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 784 64] [N 196 128]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1),
self.f3(p3_.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # seq2 [N 60 64] seq2 [N 60 128]
elif self.sr_ratio==2:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 256 49 2] # linear(2,1)
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C # [N 256 98 1] # linear(1,1)
# seq1 [N 147 256]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C)
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C
# seq2 [N 147 256]
kv1 = self.kv1(seq1).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # kv B heads N C # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv2 = self.kv2(seq2).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv = torch.cat([kv1, kv2], dim=2) # [2 N 2 60 32] # [2 N 4 60 32] # [2 N 8 147 32]
k, v = kv[0], kv[1] # [N 2 60 32] # [N 4 60 32] # [N 8 147 32]
attn = (q @ k.transpose(-2, -1)) * self.scale # [N 2 3136 60] # [N 4 784 60] [N 8 196 147]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [N 3136 64] # [N 784 128] [N 196 256]
x = self.proj(x+lepe)
x = self.proj_drop(x)
mask=None
else:
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # [N 16 49 32]
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) #[2 N 16 49 32]
k, v = kv[0], kv[1] # [N 16 49 32]
attn = (q @ k.transpose(-2, -1)) * self.scale # [N 16 49 49]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [N 49 512]
x = self.proj(x+lepe) # linear(512,512)
x = self.proj_drop(x)
mask=None
return x, mask其中分窗和swin transformer是一样的。
在分类上的表现:


在相似的参数下,SG-Former在性能上明显优于其竞争对手。具体来说,基础模型优于Swin-B 1.6。SG-Former-S/M/B相对于先前的最先进的CSWin分别实现了+0.4、+0.3、+0.4的性能提升。
作者也测了在各类任务中表现,均优于当前最先进的模型。