MySQL之DQL
DQL是数据查询语言
SELECT语句
语法:
SELECT {*,列名,函数等}
FROM 表名;
SELECT *:表示匹配所有列
FROM :提供数据源
例如:查询student表的所有记录
SELECT * FROM student;
例如:查询学生姓名和地址:
SELECT StudentName,Address FROM student;
例如:查询学号为1001的学生姓名和地址:
SELECT StudentName,Address FROM student WHERE StudentNo=1001;
SELECT语句中的算术表达式
对数值型数据列、变量、常量可以使用算术操作符创建表达式(+ - * /)
**例如:
SELECT 100+80;
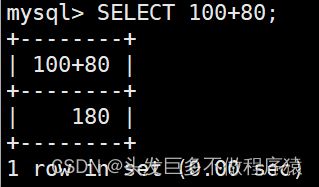
SELECT 100-80;
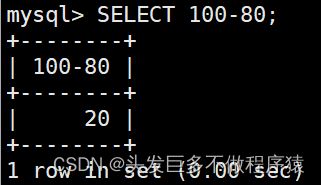
SELECT 100*80;
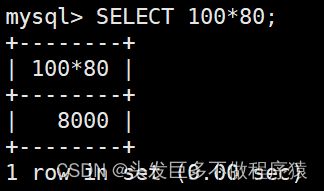
SELECT 100/80;

SELECT "12"+80;
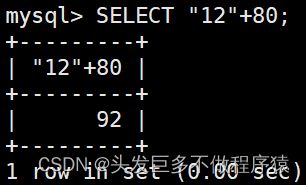
SELECT "ABC"+80;

SELECT "ABC"+"DE";
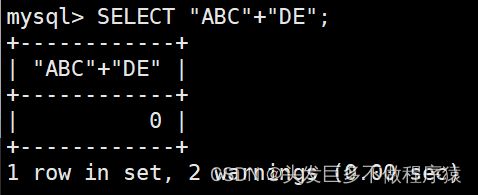
SELECT NULL+80;(只要有一个NULL则全部为NULL)

对日期型数据列、变量、常量可以使用部分算术操作符创建表达式(+ -)
运算符的优先级
乘法和除法的优先级高于加法和减法。
统计运算符的顺序是从左到右。
表达式中使用括号可以强行改变优先级的运算顺序。
定义字段别名
未定义别名
mysql> SELECT StudentNo,StudentName
-> FROM student;
+-----------+--------------+
| StudentNo | StudentName |
+-----------+--------------+
| 1000 | 郭靖 |
| 1001 | 李文才 |
| 1002 | 李斯文 |
| 1003 | 武松 |
| 1004 | 张三 |
| 1005 | 张秋丽 |
| 9527 | 赵尧林 |
| 1007 | 欧阳峻峰 |
| 1008 | 梅超风 |
| 1028 | 赵敏 |
| 8080 | 李寻欢 |
+-----------+--------------+
11 rows in set (0.00 sec)
定义别名1
mysql> SELECT StudentNo "学号",StudentName "学生姓名"
-> FROM student
-> ;
+--------+--------------+
| 学号 | 学生姓名 |
+--------+--------------+
| 1000 | 郭靖 |
| 1001 | 李文才 |
| 1002 | 李斯文 |
| 1003 | 武松 |
| 1004 | 张三 |
| 1005 | 张秋丽 |
| 9527 | 赵尧林 |
| 1007 | 欧阳峻峰 |
| 1008 | 梅超风 |
| 1028 | 赵敏 |
| 8080 | 李寻欢 |
+--------+--------------+
11 rows in set (0.00 sec)
定义别名2
mysql> SELECT StudentNo AS "学号",StudentName AS "学生姓名"
-> FROM student;
+--------+--------------+
| 学号 | 学生姓名 |
+--------+--------------+
| 1000 | 郭靖 |
| 1001 | 李文才 |
| 1002 | 李斯文 |
| 1003 | 武松 |
| 1004 | 张三 |
| 1005 | 张秋丽 |
| 9527 | 赵尧林 |
| 1007 | 欧阳峻峰 |
| 1008 | 梅超风 |
| 1028 | 赵敏 |
| 8080 | 李寻欢 |
+--------+--------------+
11 rows in set (0.00 sec)
关键字
DISTINCT
去除查询出来的重复的记录
例如: 查询学生性别
未去重
mysql> SELECT Sex "性别"
-> FROM student;
+--------+
| 性别 |
+--------+
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 2 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
+--------+
11 rows in set (0.00 sec)
去重
mysql> SELECT DISTINCT Sex "性别"
-> FROM student;
+--------+
| 性别 |
+--------+
| 1 |
| 2 |
+--------+
2 rows in set (0.01 sec)
BETWEEN…AND…
条件介于某两个值之间
例如:查询学号位于1003和1110之间的学生。
SELECT *
FROM student
WHERE StudentNo BETWEEN 1003 AND 1110;
IN
条件在某些值里面
例如:查询班级号为2或者3的学生信息。
SELECT *
FROM student
WHERE GradeId IN (2,3);
LIKE
模糊查询
查询条件可包含文字字符或者占位符:
① % 表示匹配0或任意多个字符。
②_ 表示匹配1个字符。
例如:查询刘姓的学生
SELECT * FROM student WHERE StudentName LIKE "刘%";
逻辑运算符:
AND: 需要满足所有的条件。
例如:查询出生在1987年02月01日之后并且性别为1的学生信息。
SELECT * FROM student WHERE BornDate > '1987-02-01' AND Sex = 1;
OR: 满足任一条件即可。
例如:查询出生在1987年02月01日之后或者性别为1的学生信息。
SELECT * FROM student WHERE BornDate > '1987-02-01' OR Sex = 1;
NOT: 取反。
例如:查询班级号不在2、3的学生信息。
SELECT *
FROM student
WHERE GradeId NOT IN (2,3);
正则表达式: REGEXP
语法:
<语法> REGEXP '表达式'
例如:查询生日在1986年的学生信息。
SELECT *
FROM student
WHERE BornDate REGEXP '^1986';
GROUP BY
数据分组,其真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义: 把该列具有相同值的多条记录,当作一个记录去处理,最终只输出一条记录。且忽略NULL。
语法:
SELECT 列名,分组函数
FROM 表名
[WHERE 条件]
[GROUP BY 分组条件];
例如:查询每个学生的平均分
SELECT StudentNo "学号",AVG(StudentResult) "平均分" FROM result GROUP BY (StudentNo);
例如:查询每个学生的平均分、总分、最高分、最低分。
SELECT StudentNo "学号",AVG(StudentResult) "平均分",SUM(StudentResult) "总分",MAX(StudentResult) "最高分",MIN(StudentResult) "最低分"
FROM result
GROUP BY(StudentNo);
例如:查询个性别人数各占多少?
SELECT COUNT(*)
FROM student
GROUP BY(Sex);
HAVING语句
语法:
SELECT 列名,分组函数
FROM 表名
[WHERE 条件]
[GROUP BY 分组条件]
[HAVING 过滤条件];
多用于分组后的二次过滤。
例如:根据学号得到所有学生的平均分后,过滤掉94分以下的同学。
SELECT StudentNo "学号",AVG(StudentResult) "平均分"
FROM result
GROUP BY(StudentNo)
HAVING AVG(StudentResult) > 94;
ORDER BY
排序
DESC:降序
ASC:升序
默认为ASC。
语法:
SELECT 列名,分组函数
FROM 表名
[WHERE 条件]
[GROUP BY 分组条件]
[HAVING 过滤条件]
[ORDER BY 排序字段] [ASC||DESC||];
例如:根据学号得到所有学生平均分后,过滤掉80分以下的学生后,对成绩进行降序排列。
SELECT StudentNo "学号",AVG(StudentResult) "平均分"
FROM result
GROUP BY(StudentNo)
HAVING AVG(StudentResult) > 80
ORDER BY AVG(StudentResult) DESC;
LIMIT
区间查询
索引从0开始
LIMIT A,B A是起始行的索引位,B是查询的空间值。
语法:
SELECT 列名,分组函数
FROM 表名
[WHERE 条件]
[GROUP BY 分组条件]
[HAVING 过滤条件]
[ORDER BY 排序字段] [ASC||DESC||]
[LIMIT A,B];
例如:根据学号得到所有学生平均分后,过滤掉80分以下的学生后,对成绩进行降序排列并取前三名。
SELECT StudentNo "学号",AVG(StudentResult) "平均分"
FROM result
GROUP BY(StudentNo)
HAVING AVG(StudentResult)>80
ORDER BY AVG(StudentResult) DESC
LIMIT 0,3;
GROUP_CONCAT
多行数据合并
例如:根据班级进行分组,要求查看各班各人姓名和各班人数个数。
SELECT GradeId "班级编号",COUNT(*) "人数",GROUP_CONCAT(StudentName)
FROM student
GROUP BY GradeId;
注意:
①使用GROUP_CONCAT()函数必须对源数据进行分组,否则所有数据就会别合并成一列。
②对结果集排序,查询语句执行的查询结果,数据是按照插入顺序排序。
③实际上需要按照某列的大小值进行排序的话,建议针对于数值类型或日期类型进行排序
多表关联查询
1、交叉连接
不适合用于任何匹配条件,生成笛卡尔积产出的行数。
语法:
SELECT 列名
FROM 表名1、2..;
2、内外连接
①等值连接
等值连接,在我们检索时,可以的将表与表之间的关系,明文的体现在SQL语句内,从而避免了如交叉连接产生的冗余数据。
语法:
SELECT 表一.列名,表二.列名
FROM 表一,表二
WHERE 条件;
例如:查询所有学生+所有班级信息
SELECT student.StudentName "学生姓名",grade.GradeName "班级"
FROM student,grade
WHERE student.GradeId=grade.GradeId;
②内连接
本质上来说和等值无区别,但是内连接会释放WHER关键字,表与表之间的连接语法更加清晰。
语法:
SELECT *
FROM 表1 INNER JOIN 表2 ON 表1.列=表2.列
[INNER JOIN 表3 ON 关系];
例如:查询学生姓名以及班级名
SELECT student.StudentName "姓名",grade.GradeName "班级"
FROM student INNER JOIN grade ON student.GradeId=grade.GradeId;
③外连接
选择了外联关键字指向的表的所有数据+关联数据
语法:
SELECT *
FROM 表1 {LEFT||RIGHT} JOIN 表2 ON 表1.列=表2.列;
例如:查询男学生名以及对应的班级名
SELECT student.StudentName "姓名",grade.GradeName "班级"
FROM student LEFT JOIN grade ON student.GradeId=grade.GradeId
WHERE student.Sex=1;
小结
①INNER JOIN :代表选择的是两个表的交叉部分。
②LEFT JOIN :代表选择的是前面一个表的全部。
③RIGHT JOIN :代表选择的是后面一个表的全部。
3、自连接
自己和自己连接,参与连接表都是同一张表。
例如:
SELECT c1.categoryName "父级目录",c2.categoryName "子目录"
FROM category AS c1 INNER JOIN category AS c2 ON c1.categoryId = c2.pid;
4、子查询
①子查询是将一个查询语句嵌套在另一个查询语句中,内部嵌套其他的SELECT语句的查询。
②内层查询的结果,可以作为外层查询的条件。
③子查询中可以包含的关键字:IN NOT NULL。
④子查询中可以包含的运算符:= != > < 等
例如:查询班级名称是大一,科目是高等数学-1的学生的平均分。
//0-根据大一查到对应的班级编号
SELECT GradeId
FROM grade
WHERE GradeName = "大一";
//1-根据对应的班级编号适配学生的学号
SELECT StudentNo
FROM student
WHERE GradeId = (
SELECT GradeId
FROM grade
WHERE GradeName = "大一"
);
//2-根据高等数学-1查到对应的课程号
SELECT SubjectNo
FROM subject
WHERE subjectName = "高等数学-1";
//前三步完成,我们手里有 一个课程号以及若干个学号
SELECT AVG(result.StudentResult)
FROM result
WHERE result.SubjectNo = (SELECT SubjectNo
FROM subject
WHERE subjectName = "高等数学-1")
AND result.StudentNo IN (SELECT StudentNo
FROM student
WHERE GradeId = (SELECT GradeId
FROM grade
WHERE GradeName = "大一"));
SQL函数
聚合函数
对一组值进行运算,并返回单个值,也叫组合函数。
常见聚合函数:
COUNT():统计行数
AVG():求平均
SUM():求和
MIN():求最小
MAX():求最大
除了COUNT()函数之外,聚合函数都会忽略NULL;
COUNT(*)、COUNT(1)、COUNT(列名)的区别
COUNT(1)和COUNT(*): 当表的数据量大些时,对表分析之后,使用COUNT(1)还要比使用COUNT()用时多了!
从执行计划来看,COUNT(1)和COUNT()的效果是一样的,但是在表做过分析之后,COUNT(1)会比COUNT()的用时少些(1w以内的数据量),不过差不了多少。如果COUNT(1)是聚索引id,那肯定是COUNT(1)快,但是差是很小的。
因为COUNT(),自动会优化指定到那一个字段,所以没必要去COUNT(1),用COUNT(),SQL会帮你完成优化,因此COUNT(1)和COUNT()基本没区别。
COUNT(1)和COUNT(字段):
COUNT(1)会统计表中所有的记录数,包含字段为NULL的记录。
COUNT(字段)会统计该字段在表中出现的次数,忽略了字段为NULL的情况。
三者的区别:
COUNT(*)包含了所有列,相当于所有行,在统计结果时不忽略NULL。
COUNT(1)包含了忽略所有列,用1代表代码行,在统计结果时不忽略NULL。
COUNT(字段)只包含了列名的那一列,在统计结果时忽略NULL。
在执行效率上
如果目标列名是主键:COUNT(列名)>COUNT()||COUNT(1)
如果目标列名非主键:COUNT(列名)
如果表多列都无主键:COUNT(1)>COUNT(*)>COUNT(列名)
因此最优的查行语法为:SELECT COUNT(主键列)
数值型函数
| 函数名称 | 作用 |
|---|---|
| ABS() | 求绝对值 |
| SQRT() | 求平方根 |
| POW()或者POWER() | 返回参数的幂次方 |
| MOD() | 求余数 |
| CEIL()或者CEILING() | 向上取整 |
| ROUND() | 四舍五入 |
| RAND() | 生成一个0-1之间的随机数 |
| FLOOR() | 向下取整 |
| SIGN() | 返回函数的符号 |
例如:随机生成0-99999之间的一个数字
SELECT FLOOR(100000*RAND());
字符串函数
| 函数名称 | 作用 |
|---|---|
| LENGTH | 返回字符串长度 |
| CHAR_LENGTH | 返回字符串的字节长度 |
| CONCAT | 合并字符串长度,返回结果为连接参数产生的字符串,参数可以使用一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT(str,len) | 从左侧进行截取,返回字符串左边若干个长度的字符 |
| RIGHT(str,len) | 从右侧进行截取,返回字符串右边若干个长度的字符串 |
| TRIM | 删除字符串左右两侧空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(s,n,len) | 截取字符串,返回从指定位置指定长度的字符串 |
| REVERSE | 字符串逆序函数返回与原字符串顺序相反的字符串 |
| STRCMP(parem1,parem2) | 比较两个表达式的顺序,如果parem1小于parem2,则返回-1,相等返回0,大于返回1 |
| LOCATE(sub,str) | 返回第一次出现目标字符串的索引位 |
| INSTR(sub,str) | 返回最后一次出现目标字符串的索引位 |
日期和时间函数
| 函数名称 | 作用 |
|---|---|
| CURDATE() CURRENT_DATE() CURRENT_DATE |
返回当前系统的日期 |
| CURTIME() CURRENT_TIME() CURRENT_TIME |
返回当前系统时间的时分秒 |
| NOW() | 返回当前系统的日期和时间值 |
| SYSDATE() | 返回当前系统的日期和时间值 |
| DATE(parem) | 返回指定日期时间的日期部分 |
| TIME(parem) | 返回指定日期时间的时间部分 |
| MONTH(parem) | 返回指定日期的月份 |
| MONTHNAME(parem) | 返回指定日期的月份英文名 |
| DAYNAME(paremr) | 返回指定日期对应的星期几的英文名 |
| YEAR(parem) | 返回年份,返回值范围为1970-2069 |
| DAYOFWEEK(parem) | 返回指定日期对应的一周的索引位,也就是星期数,注意周日时开始日,为1 |
| WEEK(parem) | 返回指定日期是一年中的第几周,返回值的范围是否为0-52或1-53 |
| DAYOFYEAR(parem) | 返回指定日期是一年中的第几天,返回值范围是1-366 |
| DAYOFMONTH(parem) 和 DAY(parem) | 返回指定日期是一个月中第几天,返回值范围为1-31 |
| DATEDIFF(parem,parem) | 返回两个日期之间的天数 |
例如:计算自己出生到现在多久了?
SELECT DATEDIFF(NOW(),'2003-02-27');
例如:计算自己多大了?
SELECT CEIL(DATEDIFF(NOW(),'2003-02-27')/365);
流程控制函数
| 函数名称 | 作用 |
|---|---|
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时返回v1,否则返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果v1不为NULL,则IFNULL函数返回v1,否则返回v2 |
| CASE | 搜索语句 |
例如:使用IF函数进行条件判断
SELECT IF(12,2,3);————2
IF(1<2,'YES','NO');————YES
IF(STRCMP('test','test1'),'NO','YES');————YES
CASE语法:
CASE <表达式>
WHEN<值1> THEN<结果1>
WHEN<值2> THEN<结果2>
WHEN<值3> THEN<结果3>
WHEN<值4> THEN<结果4>
.....
ELSE<结果5>
例如:
SELECT StudentName,
CASE GradeId
WHEN 1 THEN "大一"
WHEN2 THEN "大二"
ELSE "其他"
END AS "班级信息"
FROM student;