【我在异世界学Linux】Linux基本指令 —— 文本相关指令
文章目录
-
- cat命令:查看目标文件的内容
-
- cat -n
- tac命令
- echo命令:显示内容
-
- 输出重定向
- 输入重定向
- more命令:查看文件内容
-
- more -n
- more -数字
- less命令:查看文件内容(更优)
-
- less -N
- less -i
- head命令:提取文件头部内容
- tail命令:提取文件尾部内容
- 如何拿到文件的中间一部分或者一行内容?
-
- 1. 利用临时文件
- 2. 利用管道
- date指令:查看时间
- cal命令:查看日历
- find命令:搜索命令
-
- which命令
- whereis指令
- alias命令:给命令起别名
- grep命令:在文件中搜索字符串(按行显示)
-
- grep -n
- grep -v
- grep -i
- xargs命令:命令行参数
- 压缩/解压缩命令
-
- zip/unzip
- tar
- bc命令:Linux下的计算器
- uname 命令:用来获取电脑和操作系统的相关信息
- 查看历史命令
- 热键
cat命令:查看目标文件的内容
cat 目标文件:查看文件内容
cat -n
cat -n 目标文件:打印文件内容同时打印出行号
tac命令
tac 目标文件:逆序打印文件内容(逆序指的是行),即从最后一行开始打印
echo命令:显示内容
echo "hello world":向屏幕显示"hello world"
echo "hello world" > file.txt:把"hello world"显示到 file.txt文件(如果没有会创建),并且每一次显示(也就是写入)会把之前的内容情况后再写
可以利用cat命令查看文件内容是否改变
echo "hello world" >> file.txt":会把"hello world" 追加写入到file.txt文件,不会覆盖原来的内容
echo $变量名字: 显示变量的值,$可以理解为获取值
输出重定向
echo:打印内容到显示器
> :输出重定向也就是说 把本来应该显示到显示器上的内容,写入文件中
如果目标文件不存在,创建文件。否则直接访问(从文件开始覆盖式的写入)
>> :追加重定向 从文件的结尾开始追加式地写入,不覆盖文件的内容。
(如果目标文件不存在,也会创建文件)
追加重定向和输出重定向 都是写入:可以写入
写入到文件或者写入到显示器
输入重定向
对cat的再理解
当我们敲下cat命令不带任何东西的时候,会发现输入什么就会打印什么
这是因为:cat默认从键盘读取输入
当敲了cat命令后:
数据从键盘输入到键盘缓冲区
然后cat从键盘缓冲区读取输入的数据,输出到显示器
而cat 文件名:就是 cat从文件中读取,输出到显示器
< :输入重定向 即本来应该从键盘中读取,变成从文件中读取
cat < file.c:把file.c文件中的内容输出到屏幕
Attention Please!
cat file.c和cat < file.c作用一样,但是其实内部实现是不一样的
cat file.c 其实相当于 打开file.c文件,然后把内容读入程序,再输出
cat < file.c 其实并没有打开新的文件,因为是重定向,就是从键盘读取数据变成从file.c文件中读取,形象点的例子就如同改变了指针,把指向键盘改为指向文件,并没有打开新的文件
#利用重定向备份文件
cat file.c > bak.c:就是把file.c文件中读取的内容 重定向输出到bak.c文件(如果没有就创建)
或者 cat < fiile.c > bak.c
more命令:查看文件内容
对于长文本,比如生成10000行文本
count=0; while [ $count -le 10000 ]; do echo "hello bit ${count}"; let count++; done > file.txt
利用上面这一行命令可以生成一个 10000行的文本到file.txt中
然后如果直接使用cat file.txt命令,会直接被刷屏,想要查看前面的内容,需要向上滑动很多。
more file.txt:打印出文件内容,但是当文件内容打满了一个屏幕就停止。如果想要继续,就按回车:每一次回车多打印出一行.
按q退出more指令
more -n
more -n file.txt:打印并显示行号
more -数字
more -5 file.txt:打印前五行,回车继续向后打印
#more的缺点
如果翻到后面之后想要查看前面的是不可以的
less命令:查看文件内容(更优)
less file.txt:打印出文件内容,屏幕打满就停止。回车可以继续打印后面的。支持上下键:查看前面的和后面的
退出less也是按q
#less的查找功能
less file.txt后
输入 /99 就可以向下第一个包含99的内容
按n:查找下一个包含99的数字
按N:查找上一个包含99的数字
按g:回到最开头
输入 ?99 就可以向上找出第一个包含99的内容
less -N
less -N file.txt:查找时显示每行的行号
less -i
less -i file.txt:忽略搜索时的大小写
head命令:提取文件头部内容
head file.txt:只打印文件的头部的一些数据,默认前10行
head -20 file.txt:打印文件的前20行
tail命令:提取文件尾部内容
tail file.txt:打印文件的最后10行数据(默认10行)
tail -20 file.txt:打印文件的最后20行数据
如何拿到文件的中间一部分或者一行内容?
比如有一个文本包含从1 ~ 10000的数字,每一个数字占一行
如何拿到 第500行到600行?
1. 利用临时文件
首先利用head 拿到前600行数据 ,放到一个临时文件test.txt中
然后 用tail 从拿到后100行数据
head -600 file.txt > test.txt:拿到前600行数据 重定向到test.txt中
tail -101 test.txt:拿到后101行
输出的就是 [500,600]
2. 利用管道
|:叫做管道
$ 什么是管道?
Linux下一切皆文件,管道是一个内存级别的文件(作用类似于一个临时文件),用于传导资源(主要是数据),管道有入口,有出口。数据经过管道传输出去。
|的左边就是入口,右边就是出口。如图所示:
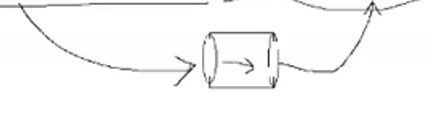
利用管道就可以批量化、流水化处理数据,可以利用wc -l 命令统计文本行的个数
上面利用文件无非就是 把file.txt文件中的前600行 输入到一个临时文件中
然后再把临时文件的后100行输出到屏幕
就可以利用管道来实现: 首先把file.txt的前600行 输入到管道中,然后再从管道中拿出后101行输出到屏幕即可:
head -600 file.txt | tail -101
可以利用wc命令统计输出的行数
head -600 file.txt | tail -101 | wc -l:本来要输出的是[500,600]行的内容,但是再次用管道 就可以统计出 这些要输出的内容的行数 --101行
date指令:查看时间
date:直接显示出时间(不过格式不是很好看)
格式化年月份(中间的格式符用 / 或 : 或其他都可)
date +%Y:显示当前年份
date +%Y/%m:显示年月
date +%Y/%m/%d:显示年月日
date +%Y/%m/%d-%H:显示年月日 + 小时
date +%Y/%m/%d-%H:%m:显示年月日 + 时分
date +%Y/%m/%d-%H:%m:%S:显示年月日 + 时分秒
date +%s:小写s:显示时间戳
#时间戳转化为现在的日期时间
date -d @时间戳:系统默认时间格式
date +%Y/%m/%d-%H:%m:%S -d @时间戳:格式化的时间
date -d @0:计算机诞生的日子:显示是 1970年1月1日 早上八点
这是因为时差问题!
cal命令:查看日历
cal 当月日历
cal -3 最近三月:上个月、本月、下个月
cal 2022:查看2022年的日历
find命令:搜索命令
find 起始路径 -name 查找的文件名:根据文件名在起始路径里面查找所有的叫该名字的文件
如find ~ -name file.txt:在家目录下查找叫file.txt的文件
which命令
其实每一个命令本质都是一个可执行程序
which 指令名:在系统路径中,去查找特定的指令所在的路径,查找的是系统命令。
比如which ls:显示ls指令的路径为/usr/bin/ls
而ls /usr/bin/ls:就会显示 /usr/bin/ls是绿色的,在Linux中绿色文件也就是一个可执行文件
file /usr/bin/ls:显示结果为 executable:可执行程序(其实就是C语言写的)
所以运行一个程序分两步
- 找到文件
- 运行文件
所以如果自己在当前目录写一个执行程序叫 a.out 如果要执行
就必须写./ a.out,因为要先找到
whereis指令
whereis ls:除了找出指令ls的路径,还会找出所有包含ls的所有文件
whereis test.c:只要保护test就会匹配并给出路径,并不是严格匹配后缀名
alias命令:给命令起别名
alias hello='ls -al':hello就是指令ls -al的别名,直接使用hello就可以显示出所有文件的详细信息
which hello:就会发现,hello的路径就是ls -al的路径
起别名只在此次登录中有效
grep命令:在文件中搜索字符串(按行显示)
grep '999' file.txt:从file.txt文件中找出含有 '999’子串的行
双引号单引号都可以
并按行打印出来
grep也叫作:行文本过滤工具
#grep和管道还有head和tail 可以结合使用
grep '999' file.txt | tac:把找出的结果按行逆序打印
grep '999' file.txt | head -3:打印出前三行
grep '999' file.txt | head -3 > bak.txt:把查询到的前三行重定向保存到文件bak.txt中
grep -n
grep -n '999' file.txt:打印时把每一行在原始文本中的行号打印出来
grep -v
grep -v '999' file.txt:找出不含有’999’子串的行
(把包含’999’的行去掉,打印剩下的)
grep -i
grep搜索字符串的时候默认是小写的(大小写敏感)
若忽视大小写搜索,就用 -i 选项
i 即 ignore
grep -i 'abcd' file.txt:从file.txt文件中寻找包含’abcd’子串(大小写都包括)的行
xargs命令:命令行参数
因为管道可以传输,那么可以把某个指令的选项通过管道传递给这个指令吗?
如:echo "-l -a -i" | ls,是想要把"-l -a -i" 这条指令给ls指令。
但是ls并不能读取管道传出的数据,所以上面那条指令的作用就相当于ls
虽然不能读取,但是ls具有命令行参数,只要把"-l -a -i"作为参数传递给ls即可
echo "-l -a -i" | xargs ls:这样就将管道的输出结果作为命令行参数传递给了ls
此时执行的就是 ls -l -a -i
压缩/解压缩命令
zip/unzip
#对一个普通文件压缩
zip file.zip file.txt:把file.txt压缩为file.zip,默认压缩到当前目录
#对于文件夹压缩
zip -r pack.zip pack:把pack文件夹打包程pack.zip,包的名字可以改
#解压
unzip pack.zip:解压到当前目录
unzip pack.zip -d 指定的路径:即可把pack.zip这个包解压到对应路径
tar
tar选项太多太复杂,记住以下几种即可
基本用法:
tar 选项 压缩后的文件名 压缩的文件
选项:
-c:建立一个压缩文件的参数指令(create)
-z:表示采用的压缩算法(gzip)
-x:解开一个压缩文件的参数指令
-f:指定归档文件名(即使用哪一个文件),后面直接跟文件名(要放在最后)
-v:显示压缩过程
-t:查看tarfile类型文件里的文件(后缀为.tar)
ps(tar为只打包而不压缩得到的,.tgz是打包并且压缩得到的)
不使用-z命令(即不采用压缩算法)就可以得到.tar
-C:解压到指定目录 (大写的C)
打包并压缩命令
写法1:
tar -czvf pack.tar.gz pack:tar表示包,gz表示压缩。此时就表示把pack目录打包并压缩成pack.tar.gz的压缩文件
写法2:
tar -czvf pack.tgz pack:tar.gz可以写成tgz
如果不带-v选项,就不会显示压缩过程
tat -czf pack.tgz pack:压缩不显示过程,一般使用不显示过程的
解压命令
只需要把选项中的 c 改为 x 就表示解压
tar -xzvf pack.tgz:默认解压到当前目录
解压不显示过程:
tar -xzf pack.tgz
解压到指定目录
tar -xzvf pack.tgz -C test:把pack.tgz解压到test目录里
得到 .tar文件
tar文件是只打包并没有压缩的
tar -cf pack.tar pack:把pack打包生成pack.tar文件
-t命令的使用:
tar -tf pack.tar:用-t命令查看tar包中的文件
解tar包
tar -xf pack.tar:把pack.tar解压到当前目录
bc命令:Linux下的计算器
bc:进入计算器,从键盘接收输入一行计算式,回车就会得到对应的结果
bc和 管道结合使用
echo "1+2+3+4" | bc:把1+2+3+4通过管道传递给bc,在屏幕上就会输出对应的结果
uname 命令:用来获取电脑和操作系统的相关信息
uname -r:查看Linux的内核版本
uname -a:a即all,输出所有信息,依次为内核名称,主机名,内核版本号,内核版本,硬件名,处理器类型,硬件平台类型,操作系统名称
![]()
其中x86_64就是硬件(CPU)的体系结构
补充知识:
x86也叫(x86_32)
x86_64 也叫 x64
查看历史命令
history
此命令可以结合管道 more 或 less 等命令使用
history | more
或者把历史命令写入一个文件
history > text.txt:把历史命令保存到text.txt
热键
终止异常的命令
ctrl + c:无脑ctrl + c 退出当前的命令
暂停命令
ctrl + z :少用,因为暂停的多了,就容易引起系统卡顿
自动补全命令
tab:比如:输入cle按tab自动补齐为clear
如果不知道以某个字母开头的命令有哪些
比如查看以a开头的命令有哪些,敲下a 然后按两下tab键,就可以显示出所有的以a开头的命令
终止登录
Ctrl + d:退出的快捷键,相当于exit
多按几次 甚至可以退出终端软件
查看历史代码
Ctrl + r:进入历史搜索,只需要敲出代码片段,就显示出历史敲出的代码,左右可以进行选中
关机
halt
shutdown
重启
reboot