Redis 定长队列的探索和实践
vivo 互联网服务器团队 - Wang Zhi
一、业务背景
从技术的角度来说,技术方案的选型都是受限于实际的业务场景,都以解决实际业务场景为目标。
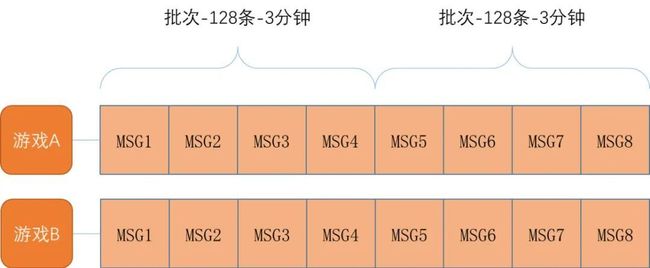
在我们的实际业务场景中,需要以游戏的维度收集和上报行为数据,考虑数据的量级,执行尽最大努力交付且允许数据的部分丢弃。
数据上报支持游戏的维度的批量上报,支持同一款游戏128个行为进行批量上报。
数据上报需要时效控制,上报的数据必须是上报时刻的前3分钟的数据。
整体数据的业务形态如下图所示:
二、技术选型
从业务的角度来说包含数据的收集和数据的上报,我们把数据的收集比作生产者,数据的上报比作消费者,是一个典型的生产消费模型。
生产消费模型在JVM进程内部通过队列+锁或者无锁的Disruptor来实现,在跨进程场景下通过MQ(RocketMQ/kafka)进行处理解耦。
但是细化到具体业务场景来看,消息的消费有诸多限制,包括:游戏维度的批量行为上报,行为上报的时效限制,细化到各个技术方案选型进行对比。
方案一
使用RocketMQ 或者Kafaka等消息队列来存储上报的消息,但是消费侧需要考虑在业务进程中按照游戏维度进行聚合,其中技术细节涉及按照游戏维度进行拆分,在满足消息时效性和批量性的前提下触发上报。在这种方案下消息中间件扮演的角色本质上消息的中转站,没有解决任何业务场景中提及的游戏维度拆分、批量性和时效性。
方案二
在方案一的基础上,寻求一种技术方案来解决游戏维度的消息分组、批量消费 、时效性。通过Redis的list结构来实现队列(进一步要求实现定长队列)来解决游戏维度的消息分组;通过Redis的list支持的Lrange来实现批量消费;通过业务侧的多线程来解决时效问题,针对高频的游戏使用单独的线程池进行处理,上述两个手段能够保证消费速度大于生产速度。
方案对比
对比两种方案后决定使用Redis的实现了一个伪消息中间件:
- 通过List对象实现定长队列来保存游戏维度的行为消息(以游戏作为key的List对象来保存用户行为);
- 通过List来保存所有的存在行为数据的游戏列表;
- 通过Set来进行去重判断来保证2中的List对象的唯一性。
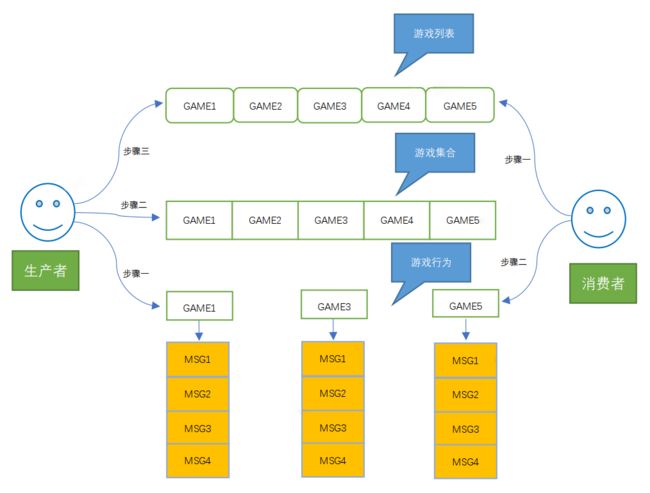
整体的技术方案如下图所示:
生产过程
步骤一:游戏维度的某行为数据PUSH到游戏维度的队列当中。
步骤二:判断游戏是否在游戏的集合Set中,如果在就直接返回,如果不在进行步骤三。
步骤三:往游戏列表中PUSH游戏。
消费过程
步骤一:从游戏对象的列表中循环取出一款游戏。
步骤二:通过步骤一获取的游戏对象去该游戏对象的行为数据队列中批量获取数据处理。
三、技术原理
在Redis的支持命令中,在List和Set的基础命令,结合Lua脚本来实现整个技术方案。
消息数据层面,通过单独的List循环维护待消费的游戏维度的数据,每个游戏维度使用定长的List来保存消息。
消息生产过程中,通过结合List的llen+lpop+rpush来实现游戏维度的定长队列,保证队列的长度可控。
消息消费过程中,通过结合List的lrange+ltrim来实现游戏维度的消息的批量消费。
在整个执行的复杂度层面,需要保证时间复杂度在0(N)常量维度,保证时间可控。
3.1 Lua 脚本
EVAL script numkeys key [key ...] arg [arg ...]
时间复杂度:取决于脚本本身的执行的时间复杂度。
> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"
Redis uses the same Lua interpreter to run all the commands.
Also Redis guarantees that a script is executed in an atomic way:
no other script or Redis command will be executed while a script is being executed.
This semantic is similar to the one of MULTI / EXEC.
From the point of view of all the other clients the effects of a script are either still not visible or already completed.Redis采用相同的Lua解释器去运行所有命令,我们可以保证,脚本的执行是原子性的。作用就类似于加了MULTI/EXEC。
Lua 脚本内多个命令以原子性的方式执行,保证了命令执行的线程安全。
Lua 脚本结合List命令实现定长队列,实现批量消费。
Lua 脚本仅支持单个key的操作,不支持多key的操作。
3.2 List 对象
LLEN key
计算List的长度
时间复杂度:O(1)。
LPOP key [count]
从List的左侧移除元素
时间复杂度:O(N),N为移除元素的个数。
RPUSH key element [element ...]
从List的右侧保存元素
时间复杂度:O(N),N为保存元素的个数。
- List的基础命令包括计算List的长度,移除数据,添加数据,整体命令的复杂度都在O(N)的常量时间。
- 整合上述三个命令,我们能保证实现固定长度的队列,通过判断队列长度是否达到定长结合新增队列元素和移除队列元素来完成。
LRANGE key start end
时间复杂度:O(S+N), S为偏移量start, N为指定区间内元素的数量。
下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。
你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
LTRIM key start stop
时间复杂度:O(N) where N is the number of elements to be removed by the operation.
修剪(trim)一个已存在的 list,这样 list 就会只包含指定范围的指定元素。
- List的基础命令包括批量返回数据和裁剪数据,整体命令的复杂度都在O(N)的常量时间。
- 整合上述两个命令,我们能够批量消费数据并移除队列数据,通过LRANGE批量返回数据并通过LTRIM保留剩余数据。
3.3 Set 对象
SADD key member [member ...]
往Set集合添加数据。
时间复杂度:O(1)。
SISMEMBER key member
判断Set集合是否存在元素。
时间复杂度:O(1)。四、技术应用
4.1 生产消息
定义LUA脚本
CACHE_NPPA_EVENT_LUA =
"local retVal = 0 " +
"local key = KEYS[1] " +
"local num = tonumber(ARGV[1]) " +
"local val = ARGV[2] " +
"local expire = tonumber(ARGV[3]) " +
"if (redis.call('llen', key) < num) then redis.call('rpush', key, val) " +
"else redis.call('lpop', key) redis.call('rpush', key, val) retVal = 1 end " +
"redis.call('expire', key, expire) return retVal";
执行LUA脚本
String data = JSON.toJSONString(nppaBehavior);
Long retVal = (Long)jedisClusterTemplate.eval(CACHE_NPPA_EVENT_LUA, 1, NPPA_PREFIX + nppaBehavior.getGamePackage(), String.valueOf(MAX_GAME_EVENT_PER_GAME), data, String.valueOf(NPPA_TTL_MINUTE * 60));
执行效果
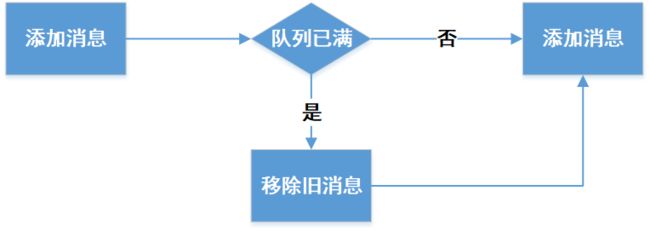
实现固长队列的数据存储并设置过期时间
- 通过整合llen+rpush+lpop三个命令实现定长队列。
- 通过lua脚本保证上述命令的原子性执行。
-
整体的执行流程如上图所示,核心理念通过lua脚本的原子性保证了队列长度计算(llen)、队列数据移除(lpop)、队列数据保存(rpush)的原子性执行。
4.2 消费消息
定义LUA脚本
QUERY_NPPA_EVENT_LUA =
"local data = {} " +
"local key = KEYS[1] " +
"local num = tonumber(ARGV[1]) " +
"data = redis.call('lrange', key, 0, num) redis.call('ltrim', key, num+1, -1) return data";
执行LUA脚本
Integer batchSize = NppaConfigUtils.getInteger("nppa.report.batch.size", 1);
Object result = jedisClusterTemplate.eval(QUERY_NPPA_EVENT_LUA, 1,NPPA_PREFIX + gamePackage, String.valueOf(batchSize));
执行效果
取固定数量的对象,然后保留队列的剩余的消息对象。
- 通过整合lrange+ltrim两个命令实现消息的批量消费。
- 通过lua脚本保证上述命令的原子性执行。

- 整体的执行流程如上图所示,核心理念通过lua脚本的原子性保证了数据获取(Lrange)和数据裁剪(Ltrim)的原子性执行。
- 整体的消费流程选择pull模式,通过多线程循环轮询可消费的队列进行消费。与借助于redis的pub/sub的通知机制实现消费流程的push模式相比,pull模式成本更低效果更佳。
4.3 注意事项
- Redis集群模式下,执行Lua脚本建议传单key,多key会报重定向错误。
- 在不同的Redis版本下,Lua脚本针对null的返回值处理不同,参考官方文档。
- 消费者的消费过程中通过循环遍历游戏列表,然后根据游戏去获取对应的消息对象,但是不同的游戏对应的热度不同,所以在消费端我们通过配置的方式为热门游戏单独开启消费线程进行消费,相当于针对不同游戏配置不同优先级的消费者。
五、线上效果



- 生产和消费的QPS约为1w qps左右,整体上报QPS通过批量上报后会远低于生产的消息生产和消费的QPS。
- 整体数据的使用游戏包名作为key进行存储,性能上不存在热点的问题。
六、适用场景
在描述完方案的原理和实现细节之后,进一步对适用的业务场景进行下总结。整体方案是基于redis的基本数据结构构建一个伪消息队列,用以解决消息的单个生产批量消费的场景,通过多key形式实现消息队列的多Topic模式,重要的是能够借助于redis的原生能力在O(N)的时间复杂度完成批量消费。另外该方案也可以降级作为实现先进先出定长的日志队列。
七、总结
本文主要探索在特定业务场景下通过Redis的原生命令实现类MQ的功能,创新式的通过Lua脚本组合Redis的List的基础命令,实现了消息的分组,消息的定长队列,消息的批量消费功能;整体解决方案在线上环境落地并平稳运行,为特定场景提供了一种通用的解决方案。